







一,设置文件夹
1,安装上传下载工具lrzsz
在root权限下使用yum进行在线安装# yum install lrzsz
安装完成后如图所示
上传用 rz 下载用 sz

2,进入Opt目录下,创建几个文件夹,方便区分文件(文件夹目录可自己设置)
Moduels software datas tools
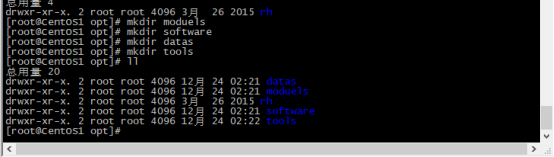
3,这里设置software为存放压缩包的文件夹
使用cd命令进入该文件夹
将jdk和hadoop压缩包上传到该文件夹
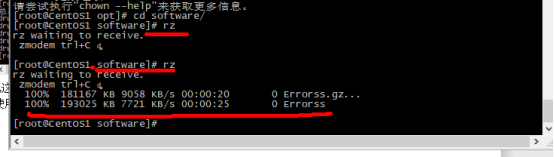
如下图所示上传成功

4,接着禁用这俩个功能(需要root权限) 关闭Linux中的防火墙和selinux安全系统
否则一般会影响我们的正常使用
关闭selinux(如果不关会阻止我们与外网的访问)
vi /etc/sysconfig/selinux
修改为 SELINUX=disabled 禁用

二,关闭防火墙(控制我们的访问)
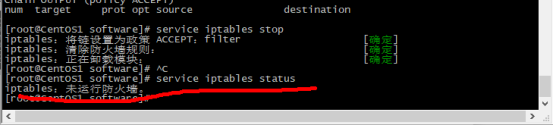
使用命令# service iptables status 查看防火请状态 (该办法为临时性关闭)
如果是下图所示状态说明是启动的

使用命令# service iptables stop 关闭

接着再次运行查询防火墙命令,如下图所示,已经关闭
使用命令# chkconfig 如下图所示并没有完全关闭

使用命令 # chkconfig iptables off 关闭防火墙
再次使用# chkconfig 查看 如下图所示已关闭

三,安装jdk
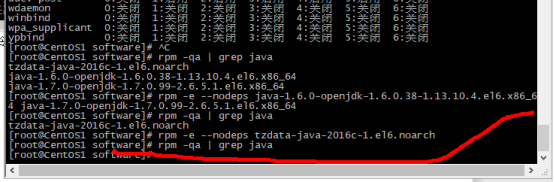
查JDKk是否安装,也就是open jdk 因为我们装的是oreck 为了防止产生冲突 如果已经安装了需要进行卸载
使用命令 # rpm -qa | grep java 发现已经安装了

在管理员权限下使用命令# rpm -e --nodeps [被卸载内容] 进行卸载
如果有多个可空格 进行删除 接着使用 rpm -qa | grep java 查看是否还有未卸载
安装自己的jdk
使用命令 # tar -zxf jdk-8u144-linux-x64.tar.gz -C /opt/moduels/
解压到/opt/moduels/ 该目录下 如下图所示

移动到/opt/moduels/ 该目录下 发现jdk和hadoop已经解压成功

管理员权限下 配置全局生效的环境变量:
使用命令[root@CentOS1 moduels]# vi /etc/profile 进入到该文件,如下图所示

配置如下图
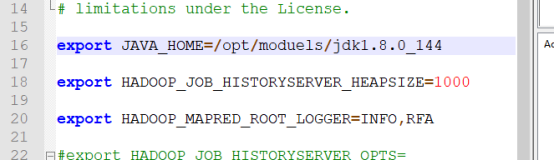
##JAVA_HOME
export JAVA_HOME=/opt/moduels/jdk1.8.0_144
export PATH=
P
A
T
H
:
PATH:
PATH:JAVA_HOME/bin
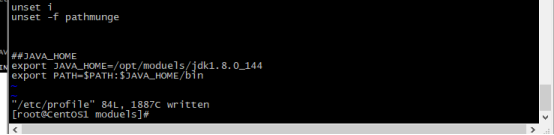
生效文件# source /etc/profile
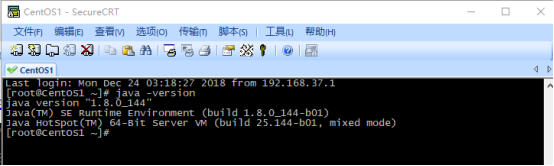
使用exit退出后使用# java -version 如下图 说明配置成功
(如果没有出现下图所示有可能是没有使用exit退出进行重新登陆或者是配置有问题)
四:配置hadoop
进入到hadoop文件夹
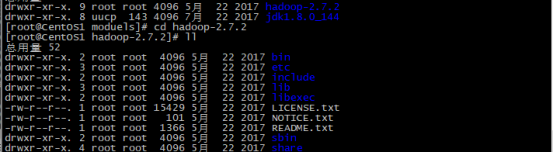
进入到share文件夹讲doc文件夹删除 使用命令# rm -rf doc/
(该文夹内容很多,我们用不到,后面会整体拷贝到另一台机器,所以这里先删除)

在etc/hadoop/hadoop-env.sh文件修改指定java的安装路径

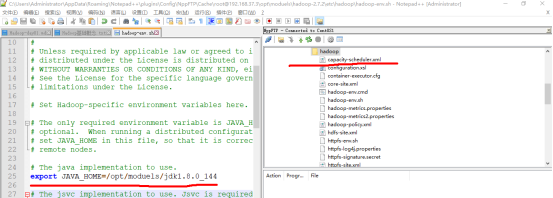
其次将文件mapred-env.sh 和文件yarn-env.sh文件同样修改

https://hadoop.apache.org/docs/r2.8.5/hadoop-project-dist/hadoop-common/SingleCluster.html
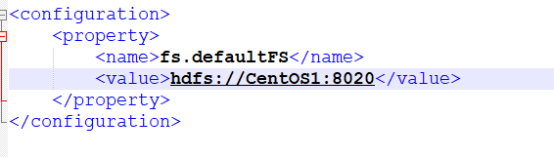
1,配置 etc/hadoop/core-site.xml: 文件
修改主机名以及端口号
1,配置 etc/hadoop/core-site.xml: 文件

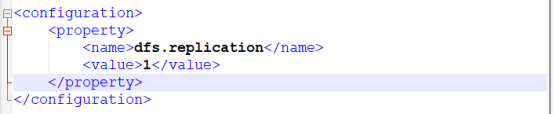
2,修改hdfs-site.xml文件,指定副本数的个数
(这里的1表示为一台机器,默认值为3,正好为3时不用写)
3,修改slaves文件
->添加datanode的所在机器位置主机名

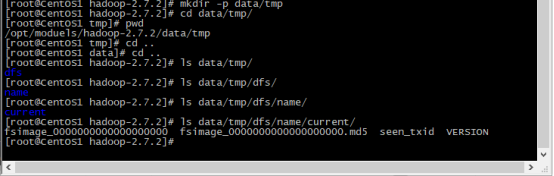
4,格式化namenode主节点,需要生成初始的元数据文件
(1)在hadoop文件夹下 查看bin/目录下文件的hdfs

(2)使用该命令查看如下图所示[root@CentOS1 hadoop-2.7.2]# bin/hdfs
(3)格式化namenode-format文件

进行格式化命令# bin/hdfs namenode -format 如下图所示

如下图查看初始的元数据
(切记不要格式化多次,如需要格式化需要将/tmp/dfs/name/current/删除,否则反复生成,覆盖,会出问题)
五,启动namenode和datanode
在hadoop文件夹下
其中start为启动 关闭为stop
启动namenode # sbin/hadoop-daemon.sh start namenode
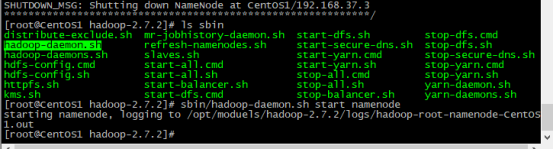
启动datanode # sbin/hadoop-daemon.sh start datanode

使用jps查看java进程

6,通过浏览器访问HDFS的外部UI界面,加上外部交互端口号50070
(主机名换成ip地址+端口号同样也可以访问)
http://centos1:50070
出现无法访问的情况可能是防火墙导致的,也可能是selinux导致的
还有可能是本地windows的hosts文件网络映射没有设置

五,YARN&MapReduce
1,修改mapred-site.xml.template的.template后缀
template代表默认不生效该文件
->代表MapReduce运行在yarn在之上
2,—添加一个MapReduce运行的服务
yarn.nodemanager.aux-services
mapreduce_shuffle
3,—[可配置项]指定resourcemanager主节点的机器位置,可配可不配
yarn.resourcemanager.hostname
CentOS1

启动resourcemanager # sbin/yarn-daemon.sh start resourcemanager
启动nodemanager # sbin/yarn-daemon.sh start nodemanager
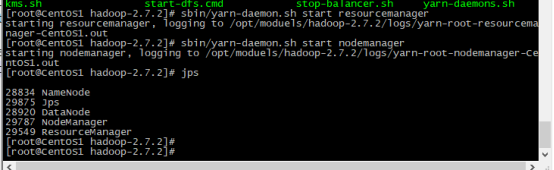
伪分布式模式配置差不多到此结束
外部访问UI界面,加上外部交互端口号
http://centos1:8088
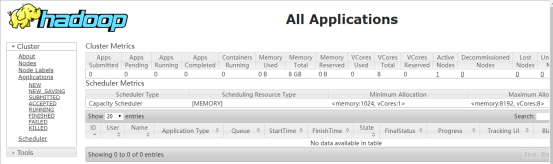
七,运行一个wordcount单次统计程序测试
->在HDFS上创建对应的路径# bin/hdfs dfs -mkdir -p mapreduce/input
->在MapReduce中output输出路径是不需要提前存在的(不能提前存在,不然会造成结果的覆盖)
->在yarn上运行job时候都必须要打jar包
执行wordcount程序
#bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar
wordcount /user/root/mapreduce/input /user/root/mapreduce/output
part-r-00000其中r代表reduce的输出结果
下图中的_SUCCESS代表运行成功才会有的文件
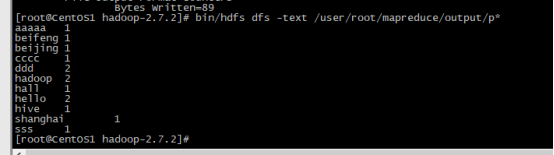
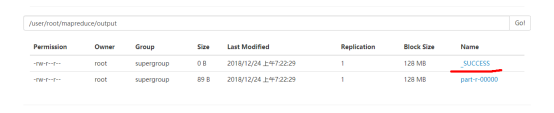 # bin/hdfs dfs -text /user/root/mapreduce/output/p*
# bin/hdfs dfs -text /user/root/mapreduce/output/p*
统计单次结果,且自动进行排序 *号带边所有















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









