







Abstract
句子中的关系事实通常很复杂,不同的关系三元组在句子中存有实体重叠。根据三元组重叠度将句子分为三种类型,包括Normal,EntityPairOverlap 和 SingleEntiyOverlap。 现有方法主要集中在Normal类上,无法准确地提取关系三元组。 本文提出了一种基于具有复制机制的序列到序列学习的端到端模型,该模型可以从任何这些类的句子中联合提取相关事实。 在解码过程中,采用两种不同的策略:仅使用一个联合解码器或应用多个分离解码器。
Introduction
句子中的关系事实常常很复杂,不同的关系三元组在句子中可能有重叠。如果一个句子的三元组都没有重叠的实体,则该句子属于Normal类;如果一个句子的某些三元组中的某些实体对重叠,则该句子属于EntityPairOverlap(EPO)类;如果一个句子的某些三元组中有一个重叠的实体,而这些三元组中没有重叠的实体对,则该句子属于SingleEntityOverlap(SEO)类。

为了处理三元组重叠的问题,必须允许一个实体自由地参与多个三元组,对此论文提出一种基于复制机制的序列到序列学习的端到端模型,该模型可以从包含这些类别的句子中联合提取相关事实。此模型的主要组件包括两部分:编码器和解码器。编码器将自然语言句子(源句子)转换为固定长度的语义向量,然后解码器读入此向量并直接生成三元组。为了生成一个三元组,首先解码器生成关系;其次通过采用复制机制,解码器从源句子复制第一个实体(头实体);最后解码器从源句子中复制第二个实体(尾实体),以此来提取多个三元组。解码过程中采用两种不同的策略:仅使用一个统一解码器(OneDecoder)生成所有三元组,应用多个分离解码器(MultiDecoder)其每个解码器生成一个三元组。
Model
OneDecoder Model

Figure 2: The overall structure of OneDecoder model. A bi-directional RNN is used to encode the source sentence and then a decoder is used to generate triples directly. The relation is predicted and the entity is copied from source sentence.
Encoder 首先将源句子转换为矩阵,矩阵向量表示各个词嵌入,依序将矩阵传入Bi-RNN生成时间步 t 时刻的结果和隐藏状态。输出结果为 ,隐藏状态的表示类似。
Decoder 首先解码器生成三元组的关系,其次解码器从源句子中复制一个实体作为三元组的第一个实体,最后解码器从源句子中复制第二个实体。重复此过程,解码器可以生成多个三元组。当生成所有有效的三元组,解码器将生成NA三元组,即意味着“停止”。NA三元组由NA关系和NA实体对组成。

Figure 3: The inputs and outputs of the decoder(s) of OneDecoder model and MultiDecoder model. (a) is the decoder of OneDecoder model. As we can see, only one decoder (the green rectangle with shadows) is used and this encoder is initialized with the sentence representation s. (b) is the decoders of MultiDecoder model. There are two decoders (the green rectangle and blue rectangle with shadows). The first decoder is initialized with s;Other decoder(s) are initialized with s and previous decoder’s state.
解码计算:,其中
为源句子的初始化表示,
,
是注意力向量,
是复制实体或者前一时刻预测关系的嵌入。

在获得时间步 t 时得解码结果 后,如果 t 能除以3余1则进行一次关系预测,如果余2则从源句子中复制第一个实体,整除则复制第二个实体。
Predict Relation 假设有m个有效关系,使用一个全连接层来计算所有有效关系的置信向量,。在生成NA三元组时,NA关系的置信值计算为:
。然后获得概率分布表示:
,选择最高概率的关系并将其嵌入作为下一步的输入。
Copy the First Entity 实体的选择跟关系预测的计算相似,选择概率分布中的最高概率作为预测实体,同样使用其嵌入作为下一步的输入。概率分布表示为:;置信向量为:
。
Copy the Second Entity 第二个实体的复制必须避开已复制的第一个实体,对此,假设第一个实体为k-th,引入一个长度为源句子长度n的掩码向量M,。然后计算概率分布,
,⊗是逐个元素相乘。
MultiDecoder Model
MultiDecoder模型是所提出的OneDecoder模型的扩展。主要区别在于解码三元组时,MultiDecoder模型使用几个分离的解码器进行解码。图3(b)显示了MultiDecoder模型的解码器的输入和输出,有两个解码器(带阴影的绿色和蓝色矩形),解码器按顺序工作:第一个解码器生成第一个三元组,然后第二个解码器生成第二个三元组。
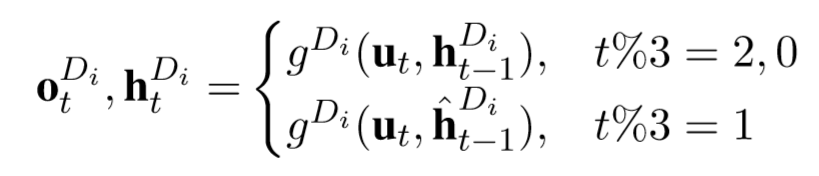
表示第 i 个解码器,ut 计算跟之前一样,初始化隐藏状态计算如下:
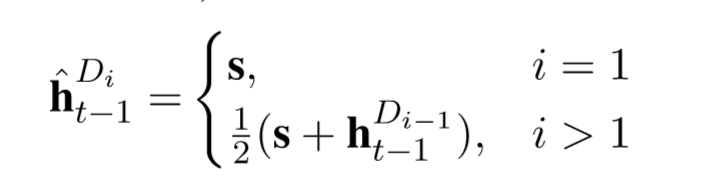















 3304
3304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









