










**注意:**地图创建要使用标准地图,那个有2901个区县,而county0907只有2900个区县。
步骤:
1、百度——查找距离最近的点
或者链接:传送门
2、打开arcgis导入空的区县的中心点以及包含中国的大的点文件,如下图

zxd:区县的中心点文件
111Export_Output:nc提取数值后展示的点
3、分析工具——领域分析——生成近邻表
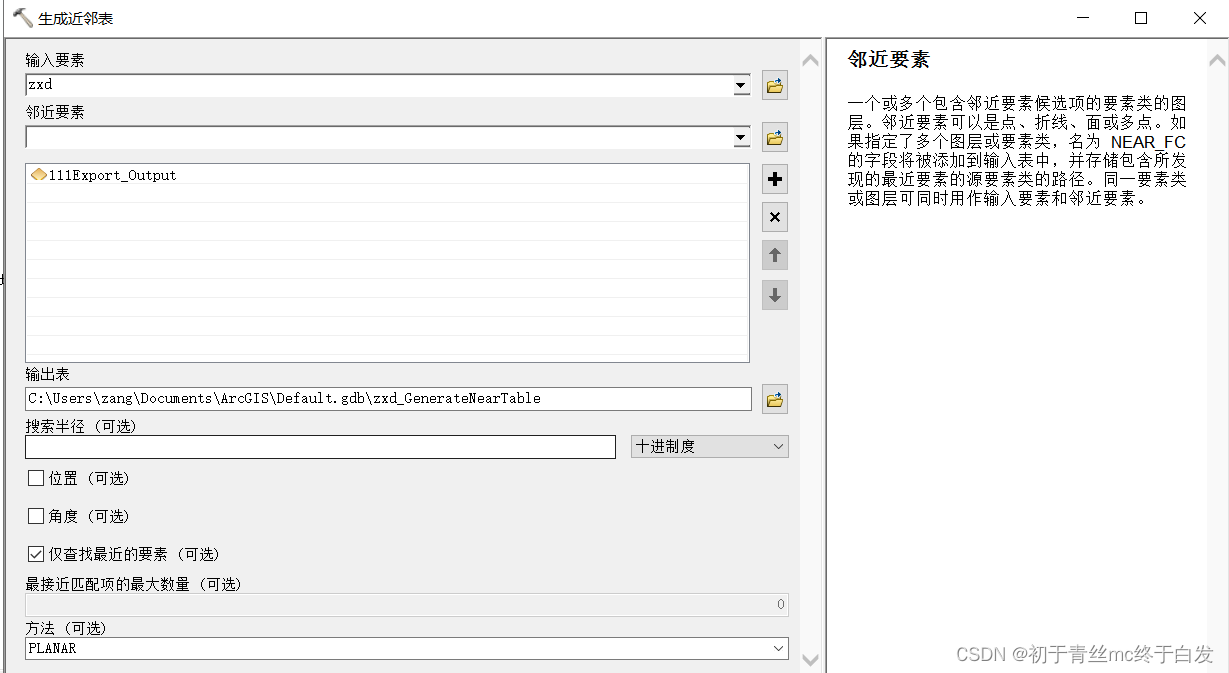
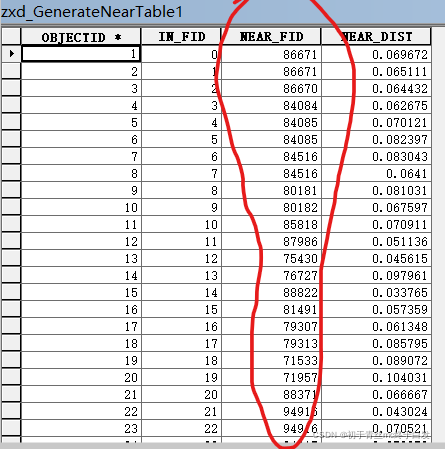
其中NEAR_FID就是离空的区县中心点最近的点了,如何查看
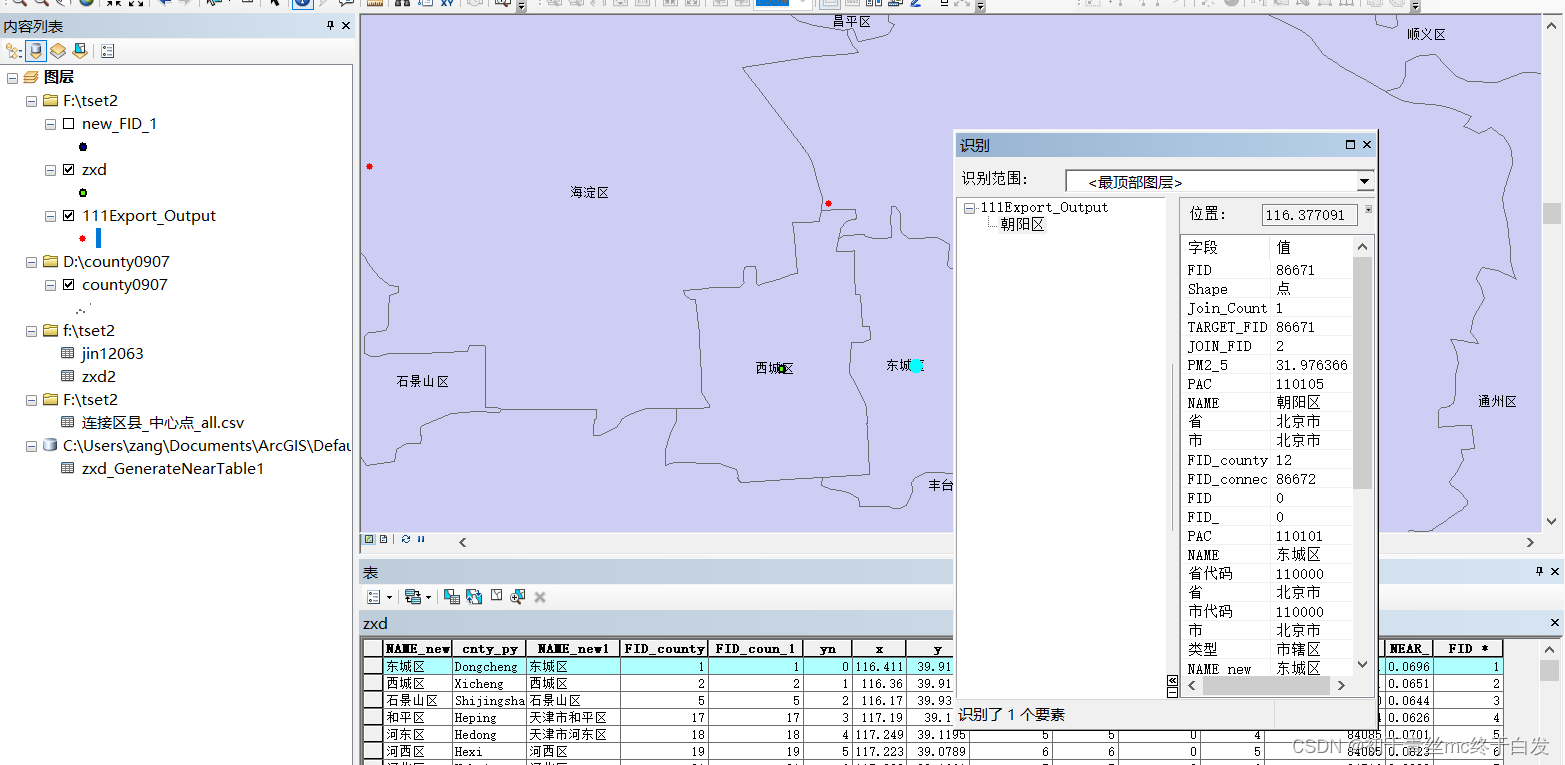
如图,86671就是朝阳区,离东城区和西城区最近的点
注意:
(1)输入要素是中心点;邻近要素是大的点文件(nc提取展示的点),选择近查找最近的要素,选择反的话就是大的文件了,注意
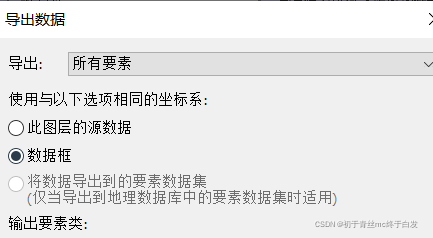
(2)注意的是这儿坐标系要一致,如何保持一致,只需要图层右击——导出数据——导出数据框,这样的话坐标系就保持一致了,如图
4、找到最近的点后,然后就是进行连接了,此处连接步骤是:
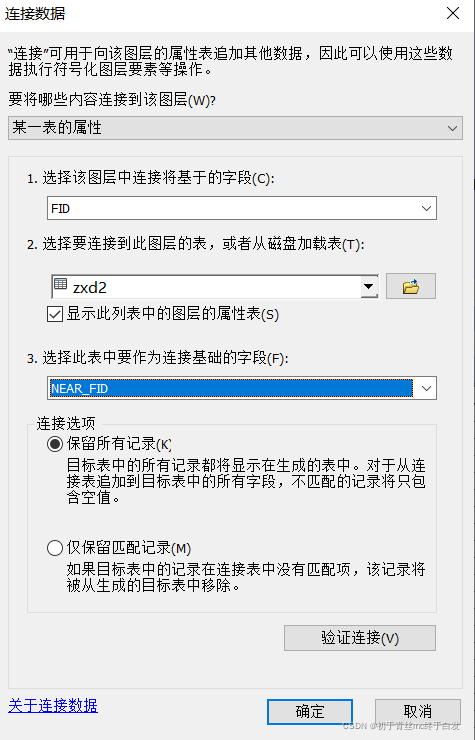
(1)中心点(zxd)、查找的最近距离的csv(jin1263)都新建一个字段,记得要FID+1,这一步是为了获得FID_county(空的区县的)。在zxd上通过FID(FID+1字段)连接jin1263,此时,就有了区县信息以及FID_county(用于分组合区县,之前不缺的区县的合并分组字段)
ps:其实也可以直接近领分析,这样就直接区县和市等几个字段和NEAR_FID匹配在一块了,就是没有FID_county(空的区县的)
然后打开属性表把该文件导出为csv数据(如kong_county.csv)。
注意: 这一步非常重要,因为有的区县最近点是一个(如东城区、西城区最近点是86671),此时连接数据的时候,只会连接第一个区县(如东城区),这样的点不是很多也就会遗漏20多个。所以此时要用代码进行查找匹配,在R中用merge函数来做这个匹配查找NEAR_FID 所对应的pm2.5的值
5、merge()函数 匹配空的区县所对应的PM2.5值(nc中提取的值)
步骤:
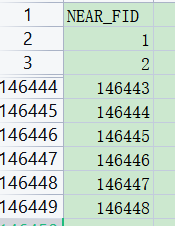
(1)首先新建一个NEAR_FID(要和提取的PM2.5一样多),回头在代码中用于和PM2.5值合并做后续merge匹配合并
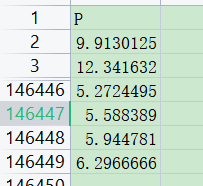
这个p就是PM2.5的值(nc中提取的经纬度所对应的值)
在给定一个中心点所对应的缺的区县的NEAR_FID ,在这里我同时给出了空区县的FID_county,
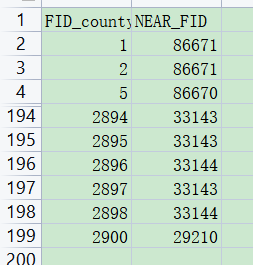
下面就是敲代码运行了,如下:
代码:
fun <- function(input,output){
bb <- dir(input)
cd <- paste(input,bb,sep = "")
NEAR_FID1 <- read.csv("路径/NEAR_FID.csv",header = T)
zxd_NEAR_FID_county <- read.csv("路径/zxd_NEAR_FID_model.csv",header = T)
for (i in 1:length(cd)){
#先读取NEAR_FID并合并PM2.5值
pm_25 <- read.csv(cd[i],header = T)
#合并NEAR_FID和pm2.5
NEAR_FID1_pm25 <- cbind(NEAR_FID1,pm_25)
#使用merge函数合并并提取空的区县所对应的PM2.5值
merge_result <- merge(zxd_NEAR_FID_county,NEAR_FID1_pm25,all = F)
#修改文件名
dd <- substring(cd[i],nchar(cd[i])-13)
filename <- paste(output,dd,sep="")
write.csv(merge_result,filename,row.names = F)
print(i)
}
}
通过上述代码就可以跑出来198个空的区县所对应的PM2.5值了,结果见下图
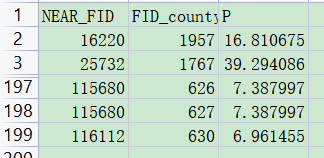
在下面就是这些小时值文件跑到日均上面,跑完日均后就可以将2703个区县和198个区县合并并排序输出了。
合并并排序的代码:
fun <- function(input1,input2,output){
bb <- dir(input1)
cd <- paste(input1,bb,sep="")
cc <- dir(input2)
cdd <- paste(input2,cc,sep = "")
for (i in 1:length(cd)){
Nokong_county <- read.csv(cd[i],header = T)
kong_county <- read.csv(cdd[i],header = T)
#合并成2901个区县
hb <- rbind(Nokong_county,kong_county)
#将合并后的2901个区县按照FID_county排序输出
hb_order <- hb[order(hb$FID_county),]
dd <- substring(cd[i],nchar(cd[i])-11)
#写入文件
filename = paste(output,dd,sep="")
write.csv(hb_order,filename,row.names = F)
print(i)
}
print("successful!")
}
这样的话一个空气污染数据集就做完了。以后也可以这样来提取,但是还是直接是R里面那个定义坐标系的代码跑效果最好。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











