







图片分类器
图片在计算机眼中就是一个巨大的矩阵,每一个像素点通过几个数字表示,比如RGB
语义鸿沟:语义概念和计算机中的巨大矩阵有着非常大的区别
视角、光照、物体不同形状、遮挡、图片背景混乱、种内差异的变化为计算机能够把同类的物体识别出来带来了巨大挑战。
最早的数据驱动图片分类算法
nearest neighbor 分类器
记录所有的学习资源,然后搜索与现有学习到的资源最相近的图片,并输出它的标签
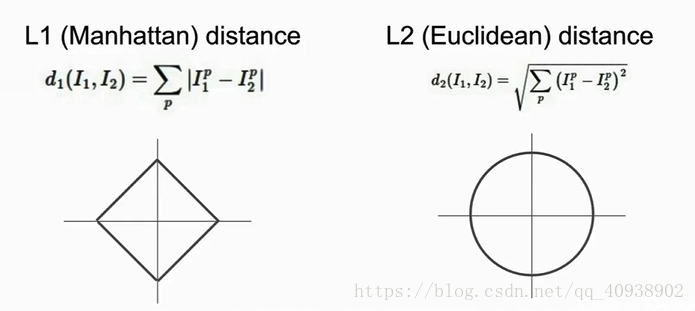
L1 distance (Manhattan distance):
比较图片中的单个像素
Numpy是一个非常有用的工具
问题:
(1)Train O(1) while Test O(N)
(2)色中色
(3)伸出的手指
K-Nearest Neighbors
找到K(K>1)个最近的点,进行投票(可以有权重,但最简单的方式是多数投票),得出答案
事实证明,此种方法可以使边缘更加光滑,从而减少错误率
两种不同的观点
在平面上的高维点概念
看具体图像的像素点
L2 Distance (欧氏距离)
L1 Distance 和 L2 Distance 的比较
L1 是一个与所建立的坐标系有关的距离。
L2 则与坐标轴无关,是一个确定的距离。
L1 和 L2 就是距离的度量方法
根据以上的特点,如果你知道你建立的这个坐标系中一些向量的具体含义,比较适合用L1,但如果你并不清楚这些响亮的具体含义,推荐用L2。
超参数 :像K和距离度量这样的参数叫做超参数。它们不能在训练中直接学到。它们的值和具体的问题有关。需要你预先指定一个值。
!误区:
(1) 选择使训练集错误率最小的超参数
过拟合问题
(2) 把训练集分为两部分,train 和 test,利用train来训练,然后选择一组在test上表现最好的超参数
这组测试集的表现无法代表在从未见过的其他数据集上的表现
正确的做法是,将数据集分为三部分,train、validation、test
在训练集上使用不同的超参数来训练,使用验证集进行评估,选择在验证集上表现最好的,利用测试集才能最终得出该分类器在完全未知的数据集上的表现
注意分离验证集和测试集,只在最后一刻才会接触到测试集
另一种做法是交叉验证:
将训练数据分为很多份,对不同份循环验证
但由于需要耗费大量的计算力,所以该法不常用
数据相互独立,并服从同一分布
一定保证训练集、验证集、测试集的数据打乱后再行分配,保证测试集数据的代表性
以上介绍的KNN分类器并不常用,原因是:
(1)测试时间长
(2)L1距离和L2距离用在图片的比较上并不合适
(3)维度灾难,若希望分类器有好的效果,则需要数据密集的分布在空间中,这意味着我们需要指数倍的增加训练数据
以上介绍了图像分类的基本思路














 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









