







Python 爬虫(Spider)基础
- 爬虫(Spider)
- 1、Python 基础
- 2、Urllib
- 3、解析
- 4、Selenium
- 5、Requests
- 6、scrapy 框架
爬虫(Spider)
1、Python 基础
声明:本文仅用于兴趣学习,文明学习,仅供参考,不承担任何责任。
1.Python 环境安装
1.1 下载 Python
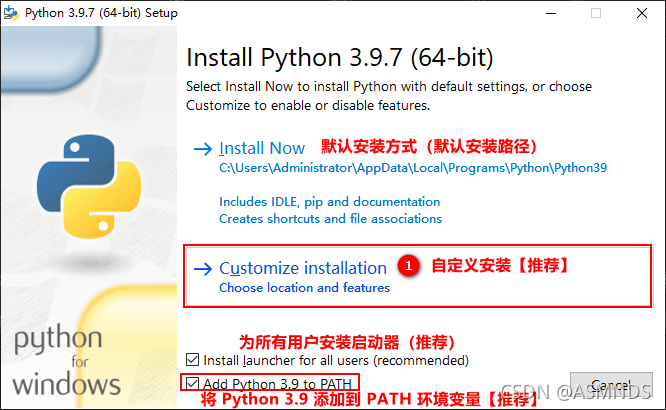
1.2 安装 Python
一路傻瓜式安装
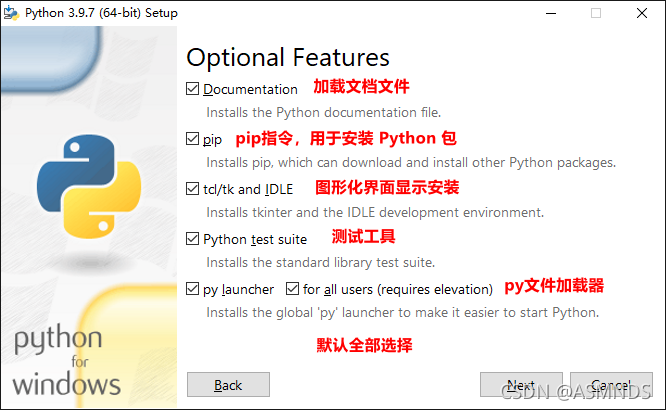
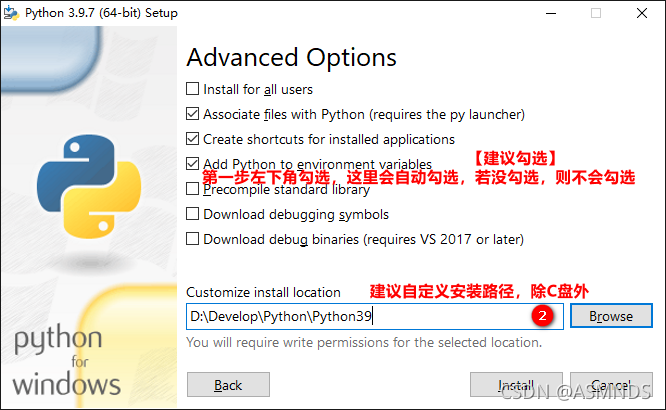
1.3 测试是否安装成功
Win + R,输入 cmd,回车
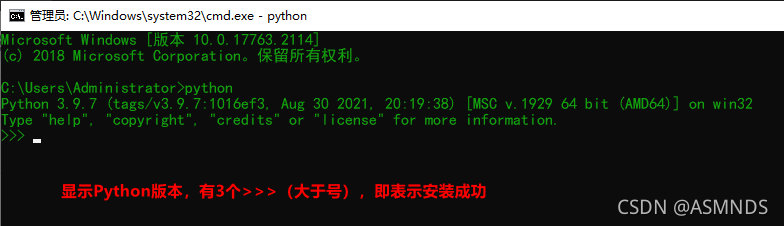
若出现错误:'python',不是内部命令或外部命令,也不是可运行的程序或批处理文件。
原因:环境变量的问题,可能是因为在安装 Python 的过程中没有勾选 Add Python 3.x to PATH 选项,此时需要手动对 Python 进行配置。
1.4 配置 Python 环境变量
注意:如果在安装过程中,已经勾选了 Add Python 3.x to PATH 选项,并且在 cmd 命令模式下,输入 python 指令显示版本信息等不报错,就不需要再手动的配置 Python。(跳过手动配置环境变量这一步)
右键此电脑,选择属性,
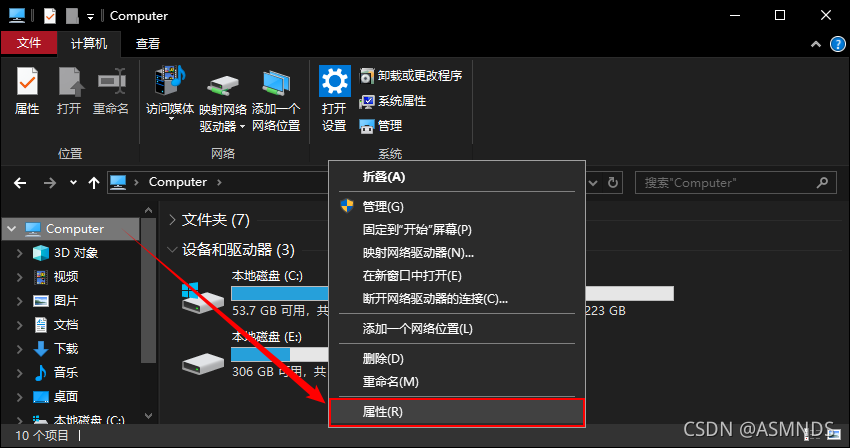
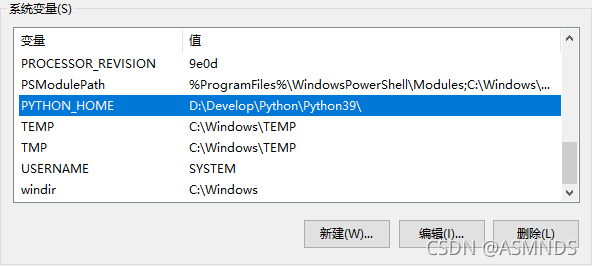
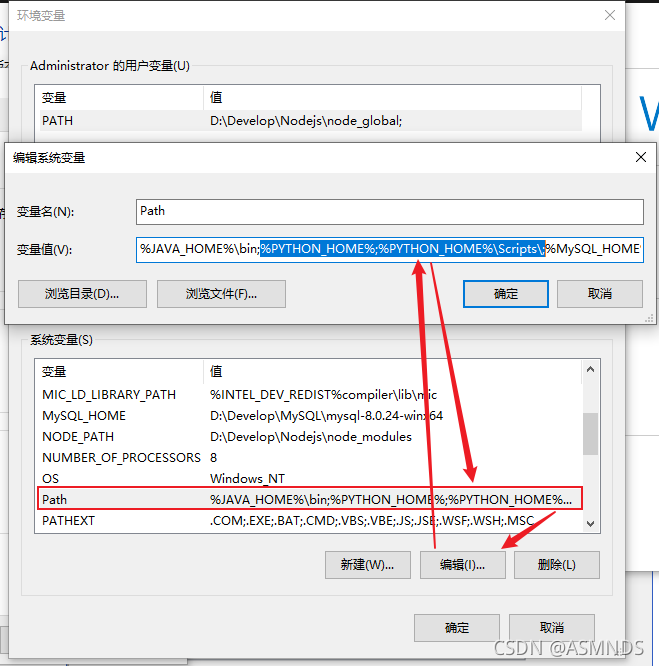
选择 高级系统设置 --> 环境变量 -->找到并且双击 Path
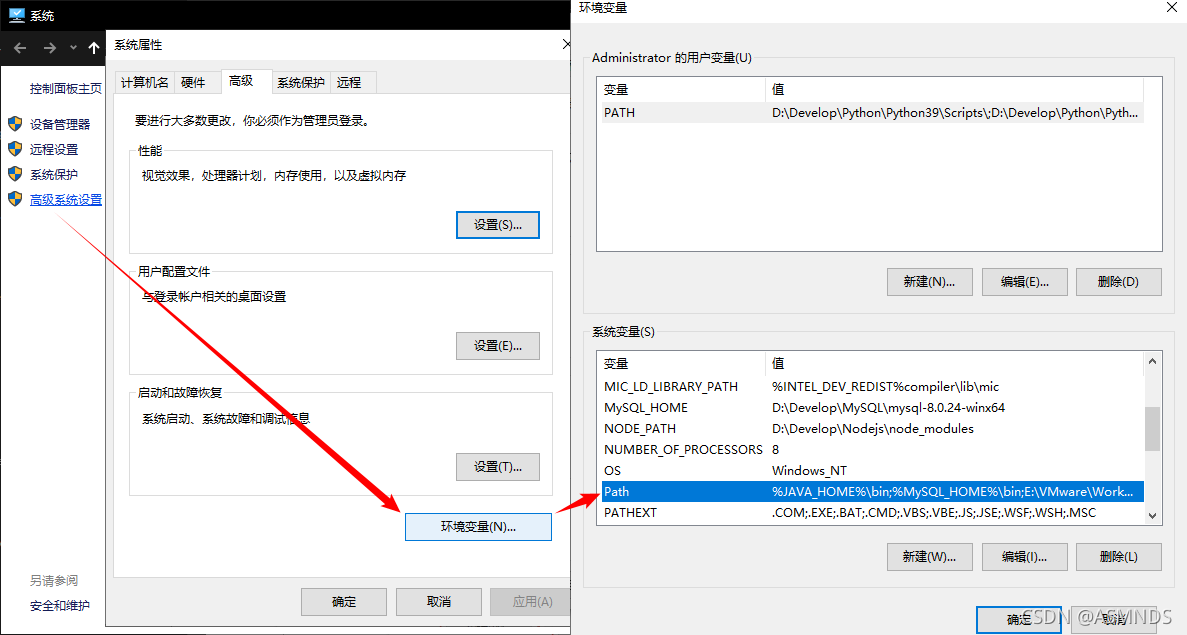
双击 Path ,在弹框里点击 新建,添加 Python 的安装目录,把路径添加进去,然后到 Path 里 编辑 环境变量,用% %来读取python的安装路径即可
2.pip 的使用
pip 是一个现代的,通用的Python包管理工具。提供了对 Python 包的查找、下载、安装、卸载的功能,便于我们对Python的资源包进行管理。
2.1 安装
在安装 Python 时,会自动下载并且安装 pip.
2.2 配置
在windows命令行里,输入 pip -V 可以查看 pip 的版本。
# 查看pip版本(大写V)
pip -V
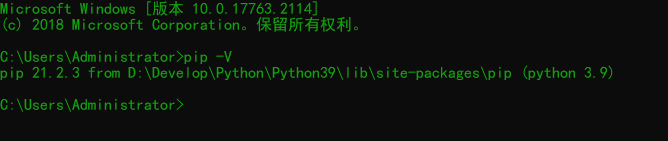
如果在命令行里,运行 pip -V ,出现如下提示:'pip',不是内部命令或外部命令,也不是可运行的程序或批处理文件。
原因:环境变量的问题,可能是因为在安装 Python 的过程中没有勾选 Add Python 3.x to PATH 选项,此时需要手动对 Python 进行配置。
右键 此电脑 --> 环境变量 -->找到并且双击 Path -->在弹窗里点击 编辑–>找到pip的安装目录(也就是python安装目录下Scripts的路径),把路径添加进去。
配置环境变量(已配请跳过,方式有很多种,随便怎么配都可以)
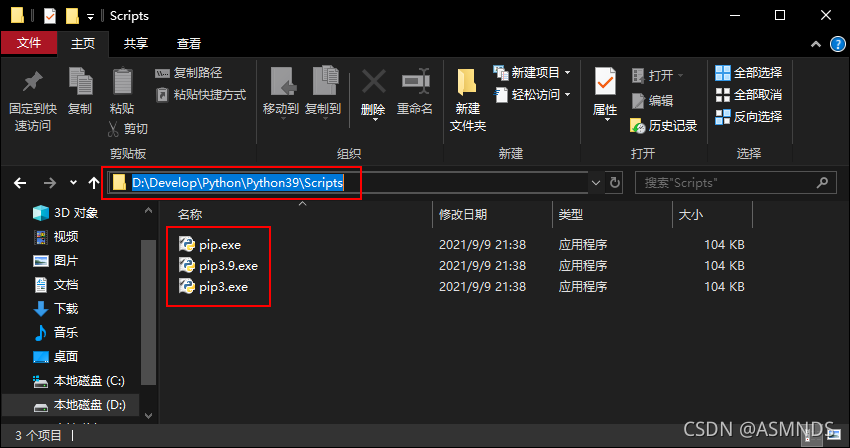
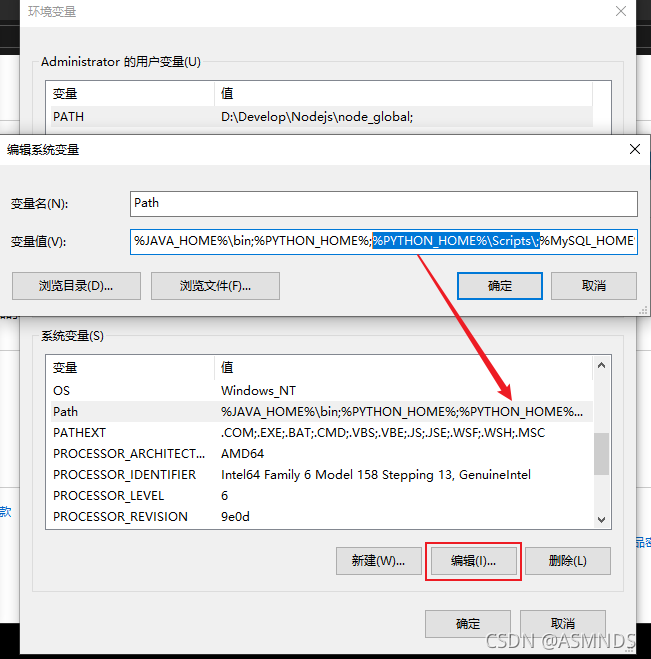
2.3 使用 pip 管理 Python 包
pip install <包名> # 安装指定的包
pip uninstall <包名> # 删除指定的包
pip list # 显示已经安装的包
pip freeze # 显示已经安装的包,并且以指定的格式显示
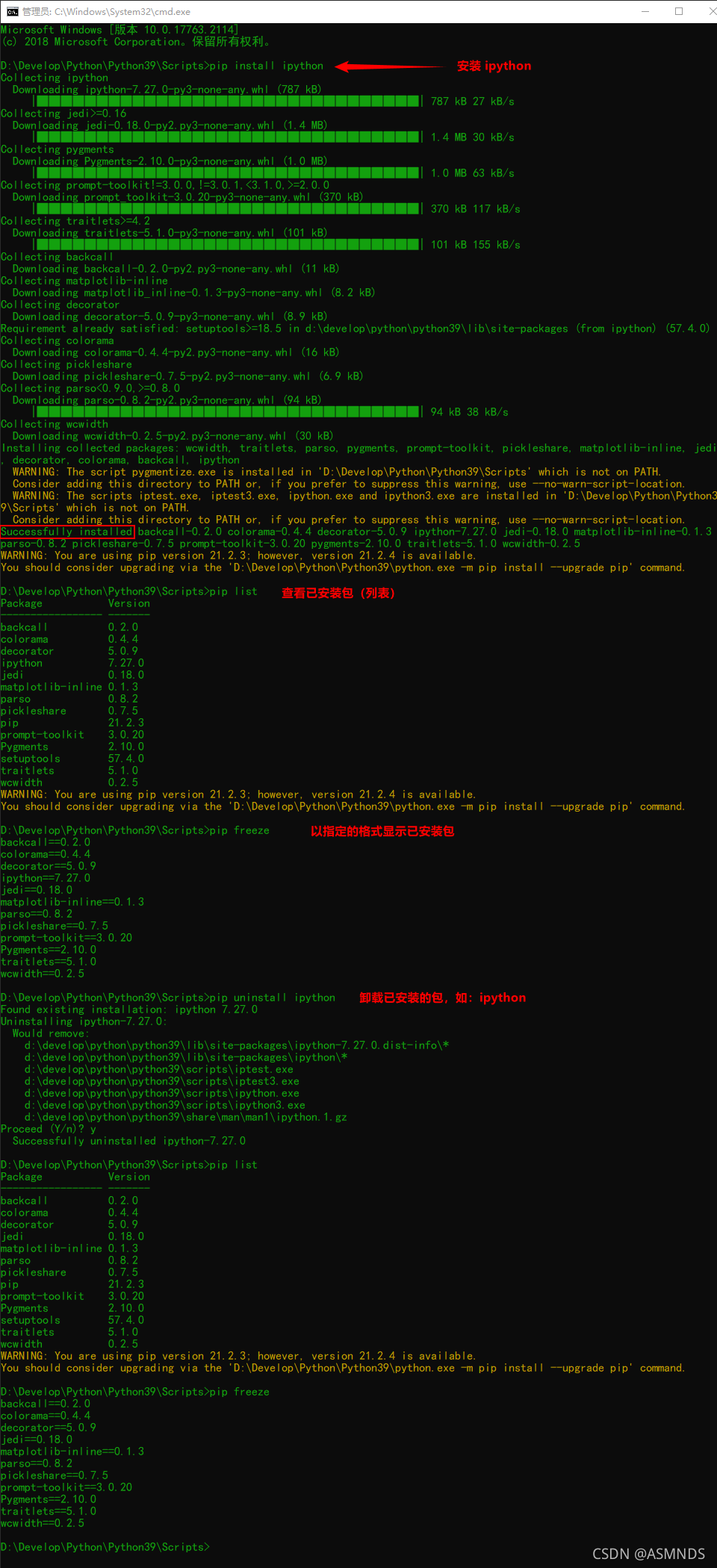
2.4 修改 pip 下载源
- 运行
pip install命令会从网站上下载指定的python包,默认是从 https://files.pythonhosted.org/ 网站上下载。这是个国外的网站,遇到网络情况不好的时候,可能会下载失败,我们可以通过命令,修改pip现在软件时的源。 - 格式:
pip install 包名 -i 国内源地址 - 示例:
pip install ipython -i https://pypi.mirrors.ustc.edu.cn/simple/就是从中国科技大学(ustc)的服务器上下载requests(基于python的第三方web框架)
国内常用的pip下载源列表:
- 阿里云:http://mirrors.aliyun.com/pypi/simple/
- 中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
- 豆瓣(douban):http://pypi.douban.com/simple/
- 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
- 中国科学技术大学:http://pypi.mirrors.ustc.edu.cn/simple/
2.4.1 临时修改
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/
2.4.2 永久修改
Linux下,修改~/.pip/pip.conf(或者创建一个),将index-url变量修改为所要更换的源地址:
[global]
index-url = https://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host = mirrors.ustc.edu.cn
windows下,在 user 目录中创建一个 pip 目录,如:C:\Users\xxx\pip,新建文件 pip.ini,内容如下:
3.运行 Python 程序
3.1 终端运行
-
直接在python解释器中书写代码
# 退出python环境 exit() Ctrl+Z,Enter -
使用ipython解释器编写代码
使用pip命令,可以快速的安装IPython.
# 安装ipython pip install ipython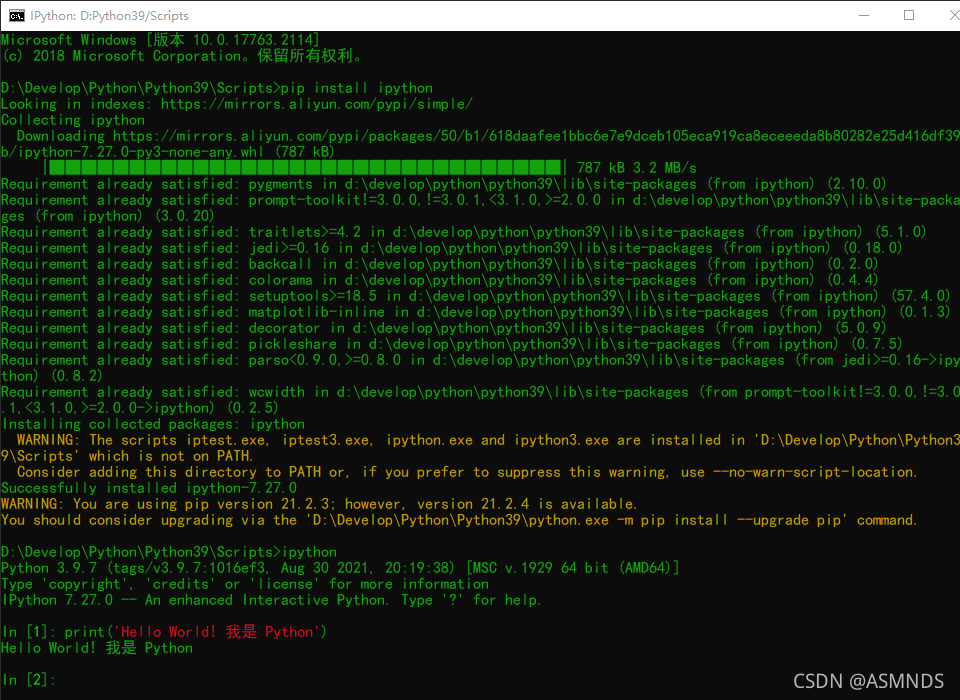
3.2 运行 Python 文件
使用python指令运行后缀为.py的python文件
python 文件路径\xxx.py
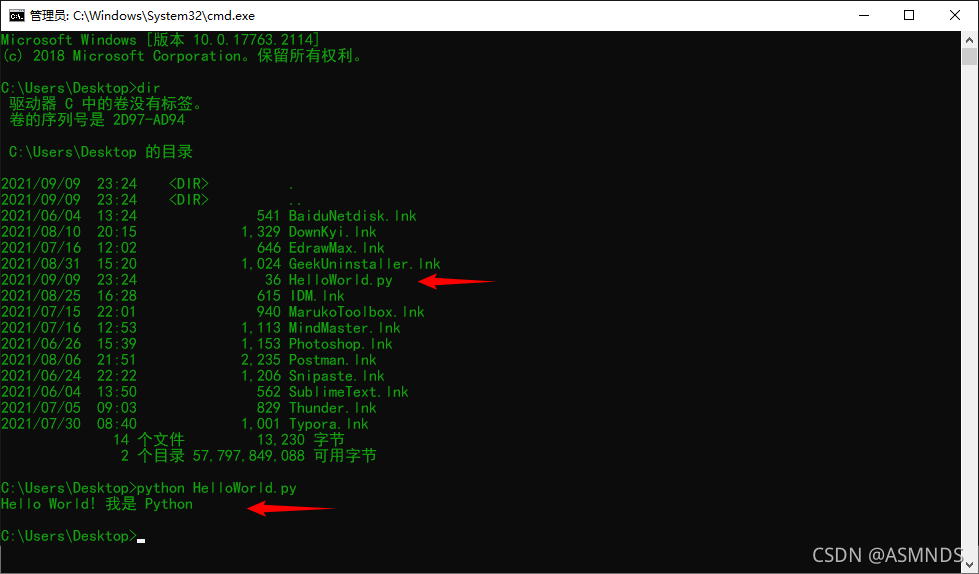
3.3 Pycharm(IDE 集成开发环境)
IDE的概念
IDE(Integrated Development Environment)又被称为集成开发环境。说白了,就是有一款图形化界面的软件,它集成了编辑代码,编译代码,分析代码,执行代码以及调试代码等功能。在Python开发中,常用的IDE是Pycharm.
pycharm由捷克公司JetBrains开发的一款IDE,提供代码分析、图形化调试器,集成测试器、集成版本控制系统等,主要用来编写Python代码。
3.3.1 下载 Pycharm
官网下载地址:http://www.jetbrains.com/pycharm/download


3.3.2 安装 Pycharm
一路傻瓜式安装
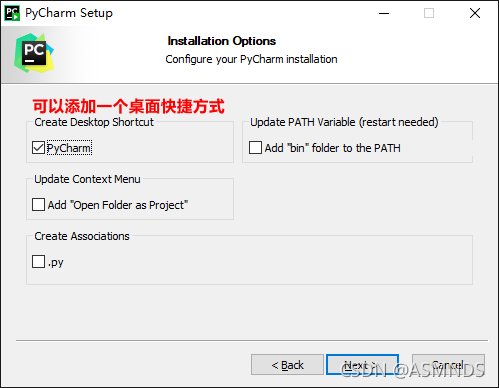
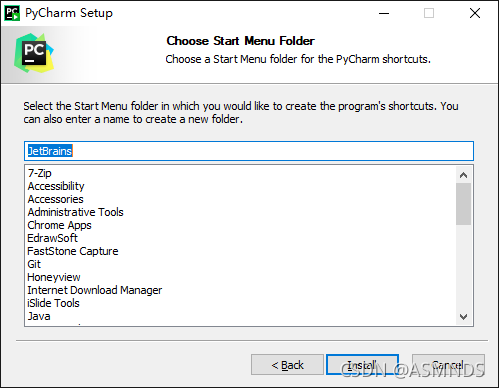
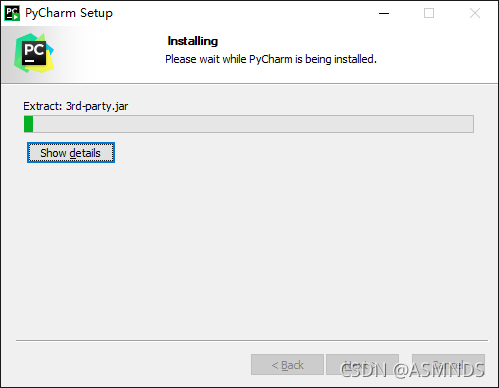
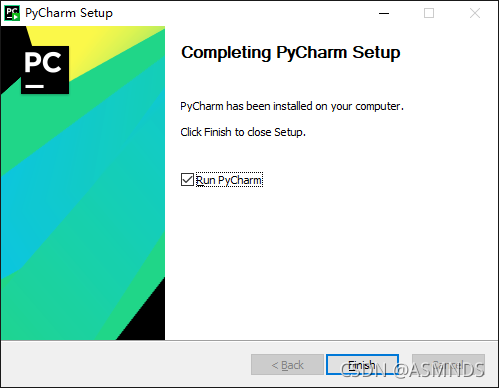

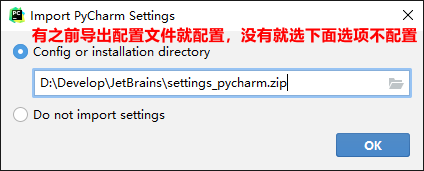
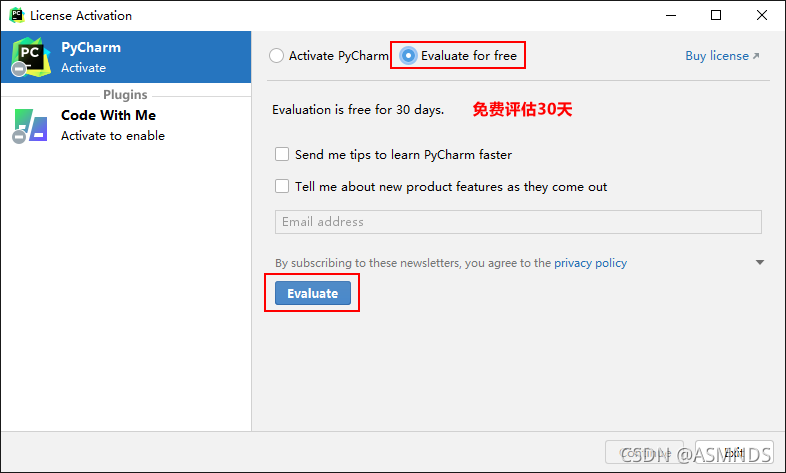
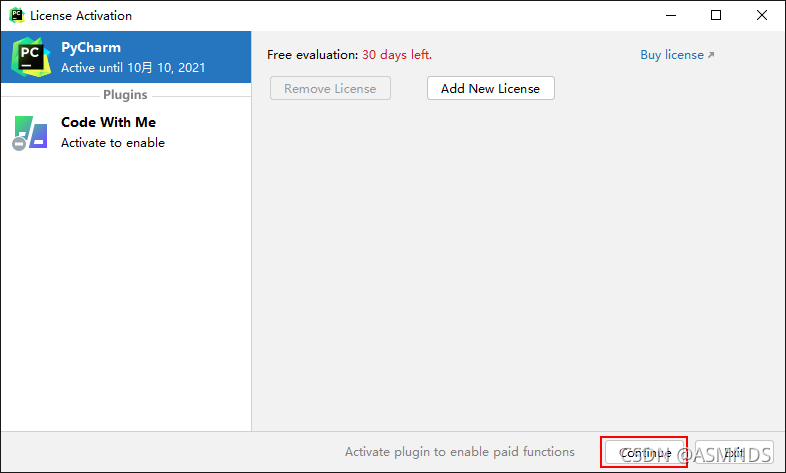
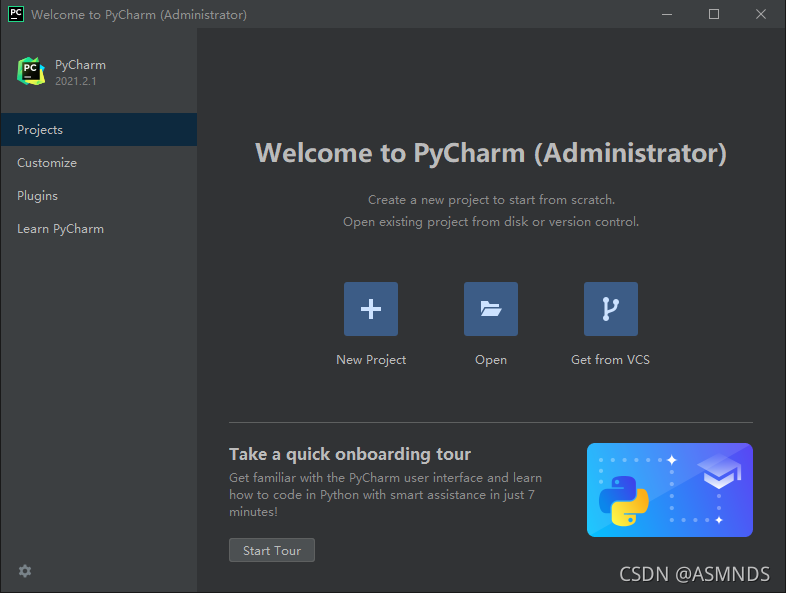
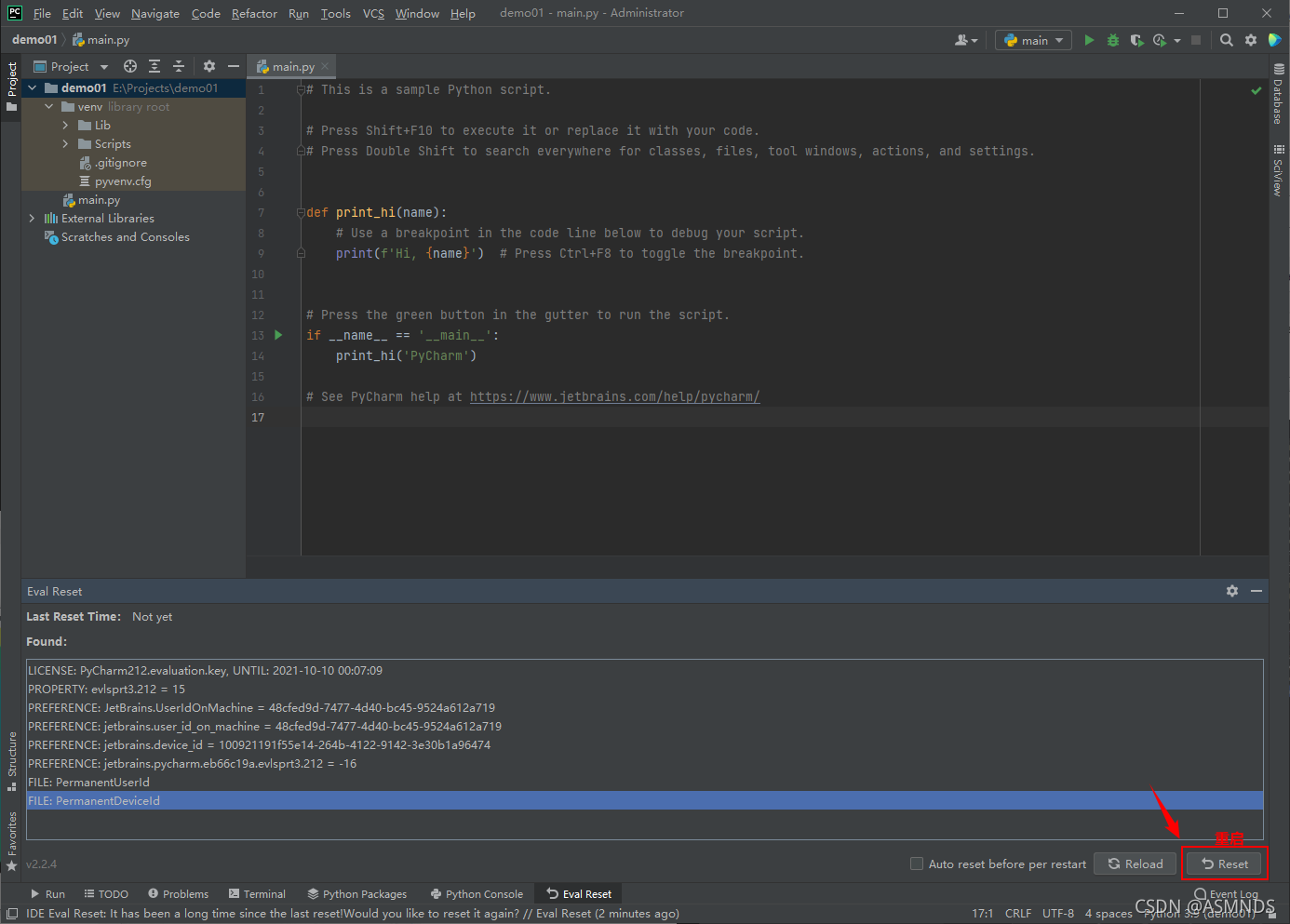


目前已更新到 2021.2.2 版本,可以到 官网下载 使用,官网更新时间:2021.09.15
3.3.3 使用 Pycharm
新建一个项目
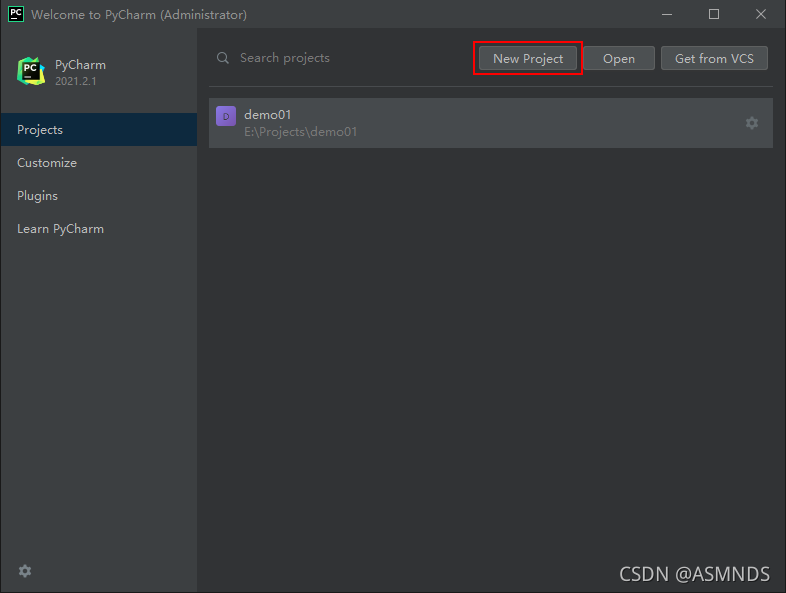
可以选择已存在的解释器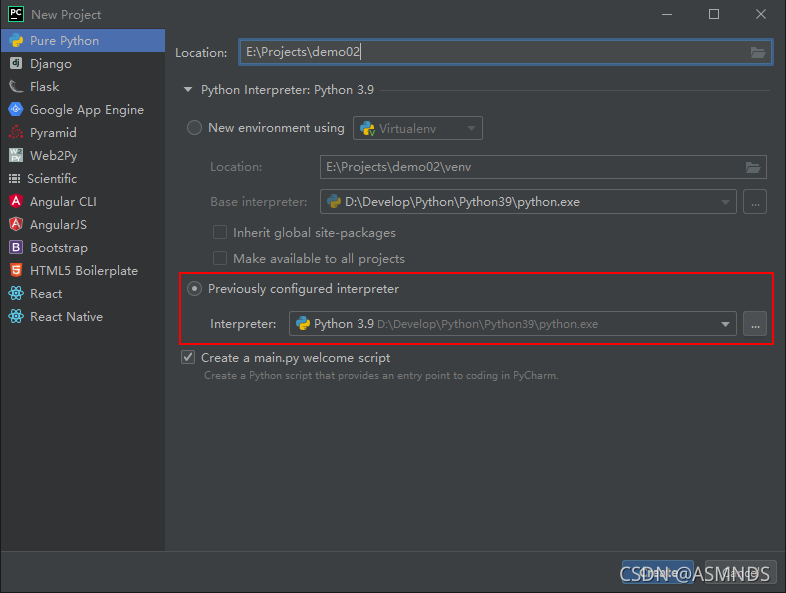
运行测试
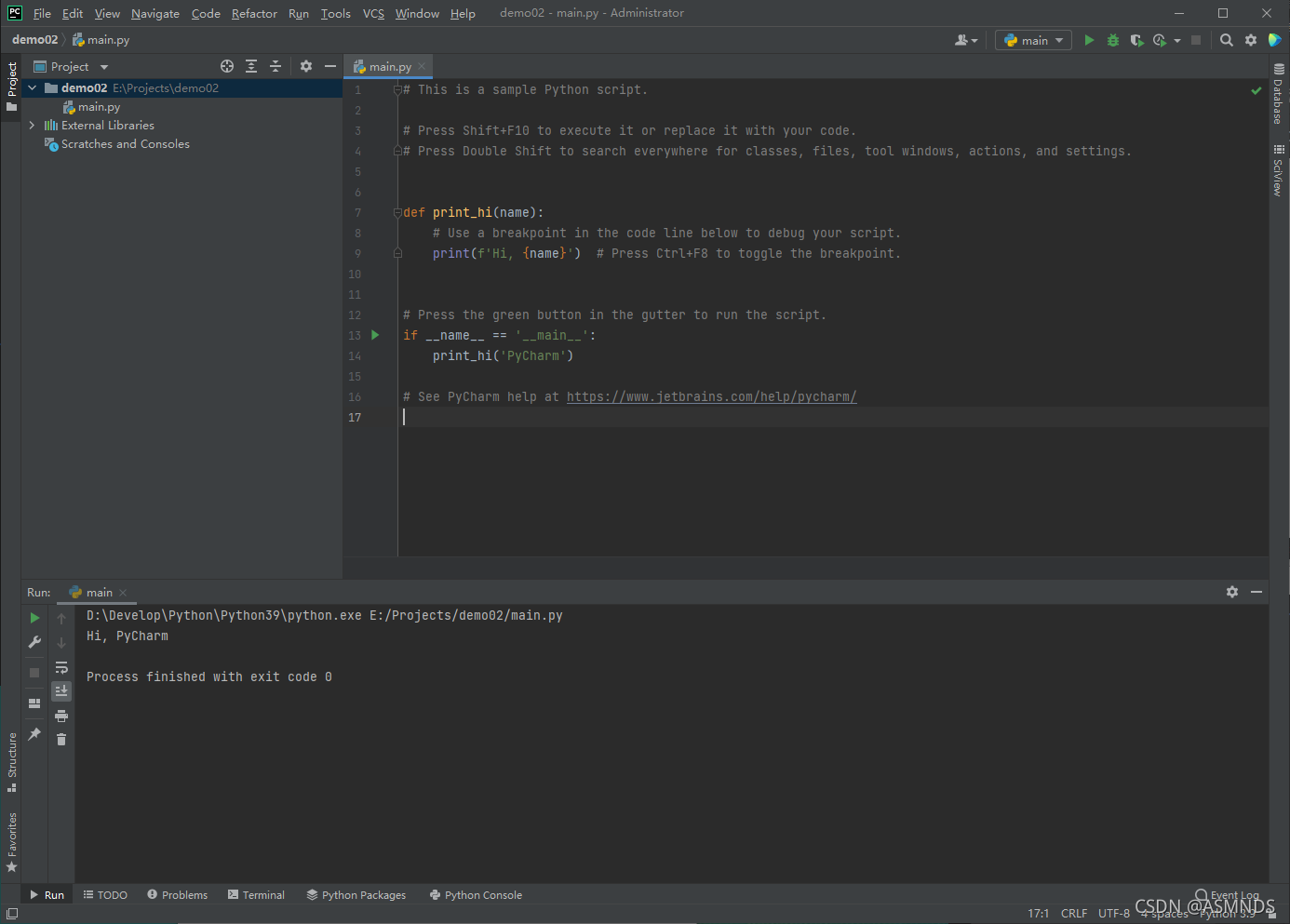
4.注释
注释是给程序员看的,为了让程序员方便阅读代码,解释器会忽略注释。使用自己熟悉的语言,适当的对代码进行注释说明是一种良好的编码习惯。
4.1 注释的分类
在Python中支持单行注释和多行注释。
单行注释
以 # 开头。
多行注释
以 ''' 开始,并以 ''' 结束,为多行注释。
5.变量及数据类型
5.1 变量的定义
对于重复使用,并且经常需要修改的数据,可以定义为变量,来提高编程效率。
变量即是可以变化的量,可以随时进行修改。
程序就是用来处理数据的,而变量就是用来存储数据的。
5.2 变量的语法
变量名 = 变量值 。(这里的 = 作用是赋值。)
5.3 变量的访问
定义变量后可以使用变量名来访问变量值。
5.4 变量的数据类型
在 Python 里为了应对不同的业务需求,也把数据分为不同的类型。
变量没有类型,数据才有类型
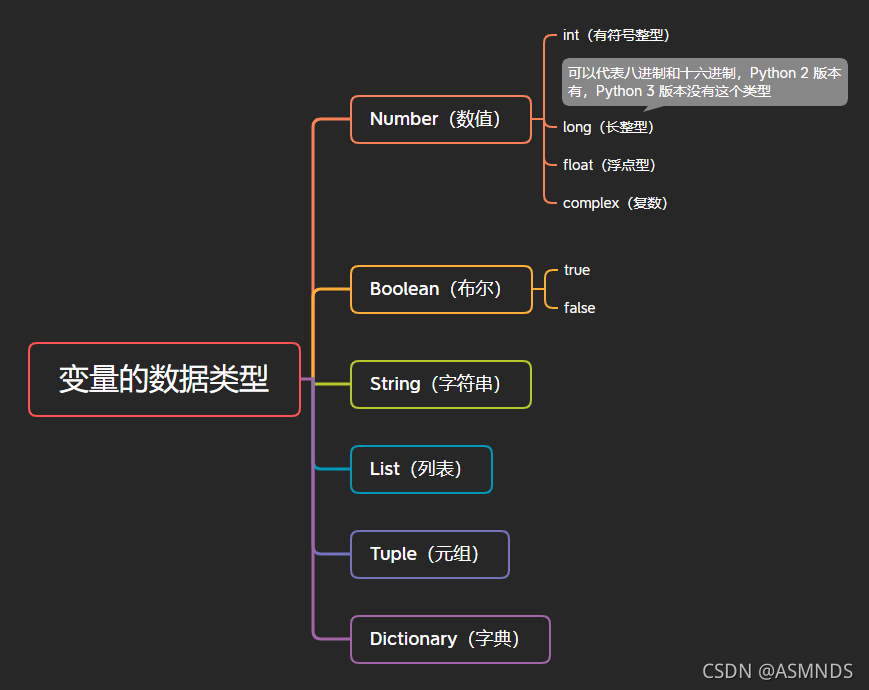
5.5 查看数据类型
在python中,只要定义了一个变量,而且它有数据,那么它的类型就已经确定了,不需要开发者主动的去说明它的类型,系统会自动辨别。也就是说在使用的时候 “变量没有类型,数据才有类型”。
查看一个变量存储的数据类型,可以使用 type(变量的名字),来查看变量存储的数据类型。
# 变量的数据类型
# 数值
money = 100000
print(type(money)) # <class 'int'>
# 布尔
gender = True
sex = False
print(type(gender)) # <class 'bool'>
# 字符串
s = '字符串'
s1 = "字符串1"
s2 = '"单双引号交叉嵌套"'
s3 = "'单双引号交叉嵌套'"
print(s2)
print(type(s)) # <class 'str'>
# 列表
name_list = ['Tomcat', 'Java']
print(type(name_list)) # <class 'list'>
# tuple 元组
age_tuple = (16, 17, 18)
print(type(age_tuple)) # <class 'tuple'>
# dictionary 字典 变量名 = {key:value,key:value,...}
person = {
'name': 'admin', 'age': 18}
print(type(person)) # <class 'dict'>
6.标识符与关键字
计算机编程语言中,标识符是用户编程时使用的名字,用于给变量、常量、函数、语句块等命名,以建立起名称与使用之间的关系。
- 标识符由
字母、下划线和数字组成,且数字不能开头。 - 严格
区分大小写。 - 不能使用关键字。
6.1 命名规范
标识符命名要做到顾名思义(见名知意)。
遵守一定的命名规范。
-
驼峰命名法,又分为
大驼峰命名法和小驼峰命名法。- 小驼峰式命名法(lower camel case): 第一个单词以小写字母开始;第二个单词的首字母大写,例如:myName、aDog
- 大驼峰式命名法(upper camel case): 每一个单字的首字母都采用大写字母,例如:FirstName、LastName.
-
还有一种命名法是用下划线“_”来连接所有的单词,比如send_buf. Python的命令规则遵循PEP8标准
6.2 关键字
关键字:一些具有特殊功能的标识符。
关键字,已经被python官方使用了,所以不允许开发者自己定义和关键字相同名字的标识符。
| False | None | True | and | as | assert | break | class | continue | def | del |
|---|---|---|---|---|---|---|---|---|---|---|
| elif | else | except | finally | for | from | global | if | import | in | is |
| lambda | nonlocal | not | or | pass | raise | return | try | while | with | yield |
7.类型转换
| 函数 | 说明 |
|---|---|
| int(x) | 将 x 转换为一个整数 |
| float(x) | 将 x 转换为一个浮点数 |
| str(x) | 将对象 x 转换为字符串 |
| bool(x) | 将对象 x 转换成为布尔值 |
转换为整数
print(int("10")) # 10 将字符串转换成为整数
print(int(10.98)) # 10 将浮点数转换成为整数
print(int(True)) # 1 布尔值True转换成为整数是 1
print(int(False)) # 0 布尔值False转换成为整数是 0
# 以下两种情况将会转换失败
'''
123.456 和 12ab 字符串,都包含非法字符,不能被转换成为整数,会报错
print(int("123.456"))
print(int("12ab"))
'''
转换成为浮点数
f1 = float("12.34")
print(f1) # 12.34
print(type(f1)) # float 将字符串的 "12.34" 转换成为浮点数 12.34
f2 = float(23)
print(f2) # 23.0
print(type(f2)) # float 将整数转换成为了浮点数
转换成为字符串
str1 = str(45)
str2 = str(34.56)
str3 = str(True)
print(type(str1),type(str2),type(str3))
转换成为布尔值
print(bool('')) # False
print(bool("")) # False
print(bool(0)) # False
print(bool({
})) # False
print(bool([])) # False
print(bool(())) # False
8.运算符
8.1 算术运算符
| 算术运算符 | 描述 | 示例(a=10 ,b=20) |
|---|---|---|
| + | 加 | 两个对象相加 a + b 输出结果 30 |
| - | 减 | 得到负数或是一个数减去另一个数 a - b 输出结果 -10 |
| * | 乘 | 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200 |
| / | 除 | b / a 输出结果 2 |
| // | 整除 | 返回商的整数部分 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 |
| % | 取余 | 返回除法的余数 b % a 输出结果 0 |
| ** | 指数 | a**b 为10的20次方 |
| () | 小括号 | 提高运算优先级,比如: (1+2) * 3 |
# 注意:混合运算时,优先级顺序为: ** 高于 * / % // 高于 + - ,为了避免歧义,建议使用 () 来处理运算符优先级。 并且,不同类型的数字在进行混合运算时,整数将会转换成浮点数进行运算。
>>> 10 + 5.5 * 2
21.0
>>> (10 + 5.5) * 2
31.0
# 如果是两个字符串做加法运算,会直接把这两个字符串拼接成一个字符串。
In [1]: str1 ='hello'
In [2]: str2 = ' world'
In [3]: str1+str2
Out[3]: 'hello world'
# 如果是数字和字符串做加法运算,会直接报错。
In [1]: str1 = 'hello'
In [2]: a = 2
In [3]: a+str1
---------------------------------------------------------------------------
TypeError Traceback (most recent call last) <ipython-input-3-993727a2aa69> in <module>
----> 1 a+str1
TypeError: unsupported operand type(s) for +: 'int' and 'str'
# 如果是数字和字符串做乘法运算,会将这个字符串重复多次。
In [4]: str1 = 'hello'
In [5]: str1*10
Out[5]: 'hellohellohellohellohellohellohellohellohellohello'
8.2 赋值运算符
| 赋值运算符 | 描述 | 示例 |
|---|---|---|
| = | 赋值运算符 | 把 = 号右边的结果 赋给 左边的变量,如 num = 1 + 2 * 3,结果num的值为7 |
| 复合赋值运算符 | 描述 | 示例 |
|---|---|---|
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| //= | 整除赋值运算符 | c //= a 等效于 c = c // a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
# 单个变量赋值
>>> num = 10
>>> num
10
# 同时为多个变量赋值(使用等号连接)
>>> a = b = 4
>>> a
4
>>> b
4
>>>
# 多个变量赋值(使用逗号分隔)
>>> num1, f1, str1 = 100, 3.14, "hello"
>>> num1
100
>>> f1
3.14
>>> str1
"hello"
# 示例:+=
>>> a = 100
>>> a += 1 # 相当于执行 a = a + 1
>>> a
101
# 示例:*=
>>> a = 100
>>> a *= 2 # 相当于执行 a = a * 2
>>> a
200
# 示例:*=,运算时,符号右侧的表达式先计算出结果,再与左边变量的值运算
>>> a = 100
>>> a *= 1 + 2 # 相当于执行 a = a * (1+2)
>>> a
300
8.3 比较运算符
<>:Python version 3.x does not support <>, use != instead,Python 2 版本支持 <> ,Python 3 版本不再支持 <>,用 != 代替。
所有比较运算符,返回1表示真,返回0表示假,这分别与特殊的变量True和False等价。
| 比较运算符 | 描述 | 示例(a=10,b=20) |
|---|---|---|
| == | 等于:比较对象是否相等 | (a == b) 返回 False |
| != | 不等于:比较两个对象是否不相等 | (a != b) 返回 True |
| > | 大于:返回x是否大于y | (a > b) 返回 False |
| >= | 大于等于:返回x是否大于等于y | (a >= b) 返回 False |
| < | 小于:返回x是否小于y | (a < b) 返回 True |
| <= | 小于等于:返回x是否小于等于y | (a <= b) 返回 True |
8.4 逻辑运算符
| 逻辑运算符 | 表达式 | 描述 | 示例 |
|---|---|---|---|
| and | x and y | 只要有一个运算数是False,结果就是False; 只有所有的运算数都为True时,结果才是True 若前面为False,后面不执行(短路与) |
True and True and False–>结果为False True and True and True–>结果为True |
| or | x or y | 只要有一个运算数是True,结果就是True; 只有所有的运算数都为False时,结果才是False 若前面为True,后面不执行(短路或) |
False or False or True–>结果为True False or False or False–>结果为False |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not True --> False |
9.输入输出
9.1 输出
普通输出:
print('xxx')
格式化输出:
# %s:代表字符串 %d:代表数值
age = 18
name = "admin"
print("我的姓名是%s, 年龄是%d" % (name, age))
9.2 输入
在Python中,获取键盘输入的数据的方法是采用 input 函数
- input()的小括号中放入的是提示信息,用来在获取数据之前给用户的一个简单提示
- input()在从键盘获取了数据以后,会存放到等号右边的变量中
- input()会把用户输入的任何值都作为字符串来对待
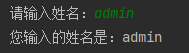
name = input("请输入姓名:")
print('您输入的姓名是:%s' % name)
10.流程控制语句
10.1 if 条件判断语句
# ① 单if语句
if 判断条件:
当条件成立时,执行语句
# 如:
age = 16
if age >= 18:
print("长大了")
# ② if-else 语句
if 判断条件:
条件成立,执行语句
else:
条件不成立,执行语句
# 如:
height = input('请输入您的身高(cm):\n')
if int(height) <= 150:
print('科技园免票')
else:
print('需要买票哦')
# ③ elif 语句
if 判断条件1:
条件1成立,执行语句
elif 判断条件2:
条件2成立,执行语句
elif 判断条件3:
条件3成立,执行语句
elif 判断条件n:
条件n成立,执行语句
# 如:
score = 77
if score>=140:
print('成绩为A')
elif score>=130:
print('成绩为B')
elif score>=120:
print('成绩为C')
elif score>=100:
print('成绩为D')
elif score<90:
print('成绩为E')
10.2 for 循环
# for 循环
for 临时变量 in 列表、字符串等可迭代对象:
循环体
# 如:
name = 'admin'
for i in name:
print(i)
# range(x)的范围:[0,x)
for i in range(3):
print(i) # 0 1 2
# range(a,b)的范围:[a,b)
for i in range(2, 5):
print(i) # 2 3 4
# range(a,b,c)的范围:[a,b),c为步长,在这个范围内按步长值增幅
for i in range(2, 10, 3):
print(i) # 2 5 8
11.数据类型
11.1 字符串
字符串中常见的方法/函数
| 方法/函数 | 描述 |
|---|---|
| len() | 获取字符串的长度 |
| find() | 查找指定内容在字符串中是否存在,如果存在,就返回该内容在字符串中第一次出现的开始位置索引值,如果不存在,则返回-1 |
| startswith()/endswith | 判断字符串是不是以谁谁谁开头/结尾 |
| count() | 返回 subStr 在 start 和 end 之间 在 objectStr 里面出现的次数 |
| replace() | 替换字符串中指定的内容,如果指定次数count,则替换不会超过count次 |
| split() | 通过参数的内容切割字符串 |
| upper()/lower() | 转换大小写 |
| strip() | 去除字符串两边空格 |
| join() | 字符串拼接 |
str1 = ' Administrators '
print(len(str1)) # 18
print(str1.find('d')) # 3
print(str1.startswith('a')) # False
print(str1.endswith('s')) # False
print(str1.count('s')) # 2
print(str1.replace('s', '', 1)) # Adminitrators
print(str1.split('n')) # [' Admi', 'istrators ']
print(str1.upper()) # ADMINISTRATORS
print(str1.lower()) # administrators
print(str1.strip()) # Administrators
print(str1.join('admin')) # a Administrators d Administrators m Administrators i Administrators n
11.2 列表
列表的增删改查
| 添加元素 | 描述 |
|---|---|
| append() | 在列表末尾追加一个新元素 |
| insert() | 在指定索引位置处插入新元素 |
| extend() | 在列表末尾追加一个新列表的所有元素 |
# 添加元素
name_list = ['zhang', 'cheng', 'wang', 'li', 'liu']
print(name_list) # ['zhang', 'cheng', 'wang', 'li', 'liu']
name_list.append('tang')
print(name_list) # ['zhang', 'cheng', 'wang', 'li', 'liu', 'tang']
name_list.insert(2, 'su')
print(name_list) # ['zhang', 'cheng', 'su', 'wang', 'li', 'liu', 'tang']
subName = ['lin', 'qing', 'xue']
name_list.extend(subName)
print(name_list) # ['zhang', 'cheng', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing', 'xue']'xue']
| 修改元素 | 描述 |
|---|---|
| list[index] = modifyValue | 通过指定下标赋值,来修改列表元素 |
# 修改元素name_list[0] = 'zhao'
print(name_list) # ['zhao', 'cheng', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing', 'xue']
| 查找元素 | 描述 |
|---|---|
| in | 判断存在,若存在,结果为true,否则为false |
| not in | 判断不存在,若不存在,结果为true,否则false |
# 查找元素
findName = 'li'
# 在列表 ['zhao', 'cheng', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing', 'xue'] 中,查到了姓氏:li
if findName in nameList:
print('在列表 %s 中,查到了姓氏:%s' % (nameList, findName))
else:
print('在列表 %s 中,没查到姓氏:%s' % (nameList, findName))
findName1 = 'qian'
# 在列表 ['zhao', 'cheng', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing', 'xue'] 中,没查到姓氏:qian
if findName1 not in nameList:
print('在列表 %s 中,没查到姓氏:%s' % (nameList, findName1))
else:
print('在列表 %s 中,查到了姓氏:%s' % (nameList, findName1))
| 删除元素 | 描述 |
|---|---|
| del | 根据下标进行删除 |
| pop() | 默认删除最后一个元素 |
| remove | 根据元素的值进行删除 |
# 删除元素
print(nameList) # ['zhao', 'cheng', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing', 'xue']
# del nameList[1] # 删除指定索引的元素
# print(nameList) # ['zhao', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing', 'xue']
# nameList.pop() # 默认输出最后一个元素
# print(nameList) # ['zhao', 'cheng', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing']
# nameList.pop(3) # 删除指定索引的元素
# print(nameList) # ['zhao', 'cheng', 'su', 'li', 'liu', 'tang', 'lin', 'qing', 'xue']
nameList.remove('zhao') # 删除指定元素值的元素
print(nameList) # ['cheng', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing', 'xue']
11.3 元组
Python的元组与列表类似,不同之处在于元组的元素数据不能修改,而列表的元素数据是可以修改的,元组使用小括号,列表使用中括号。
# 元组
nameTuple = ('zhang', 'cheng', 'wang', 'li', 'liu')
print(nameTuple) # ('zhang', 'cheng', 'wang', 'li', 'liu')
# nameTuple[3] = 'su' # 元组不可以修改里面元素的值
# print(nameTuple) # TypeError: 'tuple' object does not support item assignment
ageInt = (16) # 若不写逗号,则是int类型
print(ageInt, type(ageInt)) # 16 <class 'int'>
ageTuple = (17,) # 定义只有一个元素的元组,需要在唯一的元素后写一个逗号
print(ageTuple, type(ageTuple)) # (17,) <class 'tuple'>
11.4 切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法
# 切片的区间[起始索引,结束索引),步长表示切片间隔,切片跟截取没啥区别,注意是左闭右开区间
[起始索引:结束索引:步长] # 按指定步长,从起始索引到结束索引截取
[起始索引:结束索引] # 默认步长1,可以简化不写
# 切片
str_slice = 'Hello World!'
# 切片遵循左闭右开区间,切左不切右
print(str_slice[2:]) # llo World!
print(str_slice[0:5]) # Hello
print(str_slice[2:9:2]) # loWr
print(str_slice[:8]) # Hello Wo
11.5 字典
字典的增删改查
使用key查找数据和使用get()来获取数据
| 查看元素 | 描述 |
|---|---|
| dictionaryName[‘key’] | 指定key查找对应的value值,访问不存在的key,报错 |
| dictionaryName.get(‘key’) | 使用其get(‘key’)方法来获取key对应的value值,访问不存在的key,返回None |
# 查看元素
personDictionary = {
'name': '王者', 'age': 16}
print(personDictionary) # {'name': '王者', 'age': 16}
print(personDictionary['name'], personDictionary['age']) # 王者 16
# print(personDictionary['noExistKey']) # KeyError: 'noExistKey',以中括号指定key的形式,访问不存在的key,会报错
print(personDictionary.get('name')) # 王者
print(personDictionary.get('noExistKey')) # None,以get()的形式,访问不存在的key,会返回 None,不报错
| 修改元素 | 描述 |
|---|---|
| dictionaryName[‘key’] = modifiedValue | 将新值赋值给需要修改的key的值 |
# 修改元素
petDictionary = {
'name': '荣耀', 'age': 17}
print(petDictionary) # {'name': '荣耀', 'age': 17}
petDictionary['age'] = 18
print(petDictionary) # {'name': '荣耀', 'age': 18}
| 添加元素 | 描述 |
|---|---|
| dictionaryName[‘key’] = newValue | 使用 变量名[‘键’] = 数据 时,这个“键”在字典中,不存在,就新增这个元素 |
# 添加元素
musicDictionary = {
'name': '网易', 'age': 19}
print(musicDictionary) # {'name': '网易', 'age': 19}
# musicDictionary['music'] = 'xxx' # key 不存在时,新增元素
# print(musicDictionary) # {'name': '网易', 'age': 19, 'music': 'xxx'}
musicDictionary['age'] = '20' # key 存在时,覆盖元素
print(musicDictionary) # {'name': '网易', 'age': '20'}
| 删除元素 | 描述 |
|---|---|
| del | 删除指定的某一个元素或整个字典 |
| clear() | 清空字典,保留字典对象 |
# 删除元素
carDictionary = {
'name': '宝马', 'age': 20}
print(carDictionary) # {'name': '宝马', 'age': 20}
# del carDictionary['age'] # 删除指定key的元素
# print(carDictionary) # {'name': '宝马'}
# del carDictionary # 删除整个字典
# print(carDictionary) # NameError: name 'xxx' is not defined,字典已删,所以会报未定义
carDictionary.clear() # 清空字典
print(carDictionary) # {}
| 遍历元素 | 描述 |
|---|---|
| for key in dict.keys(): print(key) |
遍历字典的key(键) |
| for value in dict.values(): print(value) |
遍历字典的value(值) |
| for key,value in dict.items(): print(key,value) |
遍历字典的key-value(键值对) |
| for item in dict.items(): print(item) |
遍历字典的element/item(元素/项) |
# 遍历元素
airDictionary = {
'name': '航空', 'age': 21}
# 遍历字典的key
# for key in airDictionary.keys():
# print(key) # name age
# 遍历字典的value
# for value in airDictionary.values():
# print(value) # 航空 21
# 遍历字典的key-value
# for key, value in airDictionary.items():
# print(key, value) # name 航空 age 21
# 遍历字典的item/element
for item in airDictionary.items():
print(item) # ('name', '航空') ('age', 21)
12.函数
12.1 定义函数
格式
# 定义函数,定义完函数后,函数是不会自动执行的,需要调用它才可以
def 函数名():
方法体
代码
# 定义函数
def f1():
print('定义完函数后,函数是不会自动执行的,需要调用它才可以')
12.2 调用函数
格式
# 调用函数
函数名()
代码
# 调用函数
f1()
12.3 函数参数
形参:定义函数中小括号的参数,用来接收于调用函数的参数。
实参:调用函数中小括号的参数,用来传递给定义函数的参数。
12.3.1 位置传参(顺序传参)
按照参数位置顺序一一对应的关系来传递参数
格式
# 定义带参的函数
def 函数名(arg1,arg2,...):
方法体
# 调用带参的函数
函数名(arg1,arg2,...)
代码
# 定义带参的函数
def sum_number(a, b):
c = a + b
print(c)
# 调用带参的函数
sum_number(10, 6)
12.3.2 关键字传参(非顺序传参)
按照指定的参数顺序传参
格式
# 定义带参的函数
def 函数名(arg1,arg2,...):
方法体
# 调用带参的函数
函数名(arg2=xxx,arg1=xxx,...)
代码
# 定义带参的函数
def sum_number(a, b):
c = a + b
print(c)
# 调用带参的函数
sum_number(b=6, a=10)
12.4 函数返回值
返回值:程序中函数完成一件事情后,最后返回给调用者的结果
格式
# 定义带有返回值的函数
def 函数名():
return 返回值
# 接收带有返回值的函数
接收者 = 函数名()
# 使用结果
print(接收者)
代码
# 定义带有返回值的函数
def pay_salary(salary, bonus):
return salary + bonus * 16
# 接收带有返回值的函数
receive_salary = pay_salary(1000000, 100000)
print(receive_salary)
13.局部变量与全局变量
13.1 局部变量
局部变量:函数内部、函数形参上定义的变量。
局部变量的作用域:函数内部使用(函数外部不可以使用)。
# 局部变量
def partial_variable(var1, var2):
var3 = var1 + var2
var4 = 15
return var3 + var4
local_variable = partial_variable(12, 13)
print(local_variable)
13.2 全局变量
全局变量:函数外部定义的变量。
全局变量的作用域:函数内部、外部都可以使用
# 全局变量
globalVariable = 100
def global_variable(var1, var2):
return var1 + var2 + globalVariable
global_var = global_variable(10, 20)
print(global_var, globalVariable)
14.文件
14.1 文件的打开与关闭
打开/创建文件:在python中,使用open()函数,可以打开一个已经存在的文件,或者创建一个新文件 open(文件路径,访问模式)
关闭文件:close()函数
绝对路径:绝对位置,完整描述目标所在地,所有目录层级关系一目了然。
相对路径:相对位置,从当前文件所在文件夹(目录)开始的路径。
访问模式:r、w、a
| 访问模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针放在文件开头。如果文件不存在,则报错。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab+ | 以二进制格式打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
# 创建一个文件 open(文件路径,访问模式)
testFile = open('file/test.txt', 'w', encoding='utf-8')
testFile.write('写入文件内容')
# 关闭文件【建议】
testFile.close()
14.2 文件的读写
14.2.1 写数据
写数据:write()可以向文件写入数据。如果文件不存在,那么创建;如果存在,就先清空文件,然后写入数据
# 写数据
writeFile = open('file/write.txt', 'w', encoding='utf-8')
writeFile.write('写入文件数据\n' * 5)
writeFile.close()
14.2.2 读数据
读数据:read(num) 可以从文件中读取数据,num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
# 读数据
readFile = open('file/write.txt', 'r', encoding='utf-8')
# readFileCount = readFile.read() # 默认一字节一字节读,读取文件所有数据
# readFileCount1 = readFile.readline() # 一行一行的读,只能读取文件的一行数据
readFileCount2 = readFile.readlines() # 按行读取,读取文件所有数据,以一个列表的形式返回所有数据,列表的元素是一行一行的数据
print(readFileCount2)
readFile.close()
14.3 文件的序列化与反序列化
通过文件操作,我们可以将字符串写入到一个本地文件。但是,如果是一个对象(例如:列表、字典、元组等),就无法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里。
序列化:把内存中的数据(对象)转换为字节序列,从而保存到文件或网络传输。(对象–>字节序列)
反序列化:把字节序列恢复到内存中,重建对象。(字节序列–>对象)
序列化与反序列化的核心:对象状态的保存与重建。
Python中提供了 JSON 模块来实现数据的序列化和反序列化。
JSON模块
JSON(JavaScriptObjectNotation, JS对象简谱)是一种轻量级的数据交换标准。JSON的本质是字符串。
使用JSON实现序列化
JSON提供了dumps和dump方法,将一个对象进行序列化。
使用JSON实现反序列化
使用loads和load方法,可以将一个JSON字符串反序列化成为一个Python对象。
14.3.1 序列化
dumps():把对象转换成为字符串,它本身不具备将数据写入到文件的功能。
import json
# 序列化① dumps()
serializationFile = open('file/serialization1.txt', 'w', encoding='utf-8')
name_list = ['admin', 'administrator', 'administrators']
names = json.dumps(name_list)
serializationFile.write(names)
serializationFile.close()
dump():在将对象转换成为字符串的同时,指定一个文件对象,把转换后的字符串写入到这个文件里。
import json
# 序列化② dump()
serializationFile = open('file/serialization2.txt', 'w', encoding='utf-8')
name_list = ['admin', 'administrator', 'administrators']
json.dump(name_list, serializationFile) # 相当于合并的dumps()和write()的两个步骤
serializationFile.close()
14.3.2 反序列化
loads():需要一个字符串参数,用来将一个字符串加载成为Python对象。
import json
# 反序列化① loads()
serializationFile = open('file/serialization1.txt', 'r', encoding='utf-8')
serializationFileContent = serializationFile.read()
deserialization = json.loads(serializationFileContent)
print(deserialization, type(serializationFileContent), type(deserialization))
serializationFile.close()
load():可以传入一个文件对象,用来将一个文件对象里的数据加载成为Python对象。
import json
# 反序列化② load()
serializationFile = open('file/serialization2.txt', 'r', encoding='utf-8')
deserialization = json.load(serializationFile) # 相当于合并的loads()和read()的两个步骤
print(deserialization, type(deserialization))
serializationFile.close()
15.异常
程序在运行过程中,由于我们的编码不规范,或者其他原因一些客观原因,导致我们的程序无法继续运行,此时,程序就会出现异常。如果我们不对异常进行处理,程序可能会由于异常直接中断掉。为了保证程序的健壮性,在程序设计里提出了异常处理这个概念。
15.1 try…except 语句
try…except语句可以对代码运行过程中可能出现的异常进行处理。
语法结构:
try:
可能会出现异常的代码块except
异常的类型:
出现异常以后的处理语句
# 示例:
try:
fileNotFound = open('file/fileNotFound.txt', 'r', encoding='utf-8')
fileNotFound.read()
except FileNotFoundError:
print('系统正在升级,请稍后再试...')
2、Urllib
1.互联网爬虫
1.1 爬虫简介
如果把互联网比作一张大的Spiders网,那一台计算机上的数据便是Spiders网上的一个猎物,而爬虫程序就是一只小Spiders,沿着Spiders网抓取自己想要的数据。
解释1:通过一个程序,根据Url(如:http://www.taobao.com)进行爬取网页,获取有用信息。
解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息

1.2 爬虫核心
爬取网页:爬取整个网页,包含网页中所有内容解析数据:将网页中你得到的数据进行解析难点:爬虫和反爬虫之间的博弈
1.3 爬虫的用途
-
数据分析/人工数据集
-
社交软件冷启动
-
舆情监控
-
竞争对手监控等
-
List item
1.4 爬虫的分类
1.4.1 通用爬虫
示例:百度、360、google、sougou等搜索引擎—伯乐在线
功能:访问网页->抓取数据->数据存储->数据处理->提供检索服务
robots协议:一个约定俗成的协议,添加robots.txt文件,来说明本网站哪些内容不可以被抓取,起不到限制作用 自己写的爬虫无需遵守。
网站排名(SEO):
- 根据pagerank算法值进行排名(参考个网站流量、点击率等指标)
- 竞价排名(谁给钱多,排名就靠前)
缺点:
- 抓取的数据大多是
无用的 - 不能根据用户的需求来精准获取数据
1.4.2 聚焦爬虫
功能:根据需求,实现爬虫程序,抓取需要的数据
设计思路:
- 确定要爬取的url (如何获取Url)
- 模拟浏览器通过http协议访问url,获取服务器返回的html代码 (如何访问)
- 解析html字符串(根据一定规则提取需要的数据) (如何解析)
1.5 反-反爬手段
1.5.1 User-Agent
User Agent 中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
1.5.2 代理 IP
-
西次代理
-
快代理
匿名、高匿名、透明代理及它们之间的区别
-
使用透明代理,对方服务器可以知道你使用了代理,并且也知道你的真实IP。
-
使用匿名代理,对方服务器可以知道你使用了代理,但不知道你的真实IP。
-
使用高匿名代理,对方服务器不知道你使用了代理,更不知道你的真实IP。
1.5.3 验证码访问
- 打码平台
- 云打码平台
- 超级🦅
1.5.4 动态加载网页
网站返回的是其它 js 数据,并不是网页的真实数据
selenium 驱动真实的浏览器发送请求
1.5.5 数据加密
分析 js 代码
2.urllib 库的使用
urllib.request.urlopen():模拟浏览器向服务器发送请求
1个类型和6个方法
response:服务器返回的数据,response 的数据类型是HttpResponse解码 decode: 字节–>字符串编码 encode:字符串–>字节
read():字节形式读取二进制,rede(num):返回前 num 个字节readline():读取一行readlines():一行一行读取,直至结束getcode():获取状态码geturl():获取urlgetheaders():获取headers
import urllib.request
url = "http://www.baidu.com"
response = urllib.request.urlopen(url)
# 1个类型和6个方法
# ① response 的数据类型是 HttpResponse
# print(type(response)) # <class 'http.client.HTTPResponse'>
# ① read():一个字节一个字节去读
# content = response.read() # 效率低
# content = response.read(10) # 返回前 10 个字节
# print(content)
# ② readline():读取一行
# content = response.readline() # 读取一行
# print(content)
# ③ readlines():一行一行读取,直至结束
# content = response.readlines() # 一行一行读取,直至结束
# print(content)
# ④ getcode():获取状态码
# statusCode = response.getcode() # 返回 200 ,就是 OK!
# print(statusCode)
# ⑤ geturl():返回访问的 url 地址
# urlAddress = response.geturl()
# print(urlAddress)
# ⑥ getheaders():获取请求头
getHeaders = response.getheaders()
print(getHeaders)
urllib.request.urlretrieve():将URL表示的网络对象复制(下载)到本地文件
- 请求网页
- 请求图片
- 请求视频
import urllib.request
url_page = 'http://www.baidu.com'
# url:下载的路径,filename:文件名
# 请求网页
# urllib.request.urlretrieve(url_page, 'image.baidu.html')
# 下载图片
# url_img = 'https://img2.baidu.com/it/u=3331290673,4293610403&fm=26&fmt=auto&gp=0.jpg'
# urllib.request.urlretrieve(url_img, '0.jpg')
# 下载视频
url_video = 'https://vd4.bdstatic.com/mda-kev64a3rn81zh6nu/hd/mda-kev64a3rn81zh6nu.mp4?v_from_s=hkapp-haokan-hna&auth_key=1631450481-0-0-e86278b3dbe23f6324c929891a9d47cc&bcevod_channel=searchbox_feed&pd=1&pt=3&abtest=3000185_2'
urllib.request.urlretrieve(url_video, '冰雪奇缘.mp4')
3.请求对象的定制
目的:为了解决反爬的第一种方法,若爬取的请求信息不完整,就使用请求对象的定制
UA介绍:User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本。浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等。
语法:request = urllib.request.Request()
import urllib.request
url = 'https://www.baidu.com'
# url 的组成
# 如:https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=鼠来宝&rsv_pq=a1dbf18f0000558d&rsv_t=076ebVS%2BfOJbuqzKTEC4L%2FtOXZ5BxqzbgdFwHDGl8vEpGmeM5%2BKSr6Owpjk&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=13&rsv_sug1=11&rsv_sug7=100&rsv_sug2=0&rsv_btype=t&inputT=3568&rsv_sug4=3568
# 协议:http/https (https加了SSL,更加安全)
# 主机(域名):www.baidu.com
# 端口号(默认):http(80)、https(443)、mysql(3306)、oracle(1521)、redis(6379)、mongodb(27017)...
# 路径:s
# 参数:ie=utf-8、f=8、wd=鼠来宝...
# 锚点:#
# 问题:请求的信息不完整--UA反爬
# 解决方法--伪装完整的请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}
# 因为urlopen()中不能存储字典,所以headers不能传递进去
# 请求对象的定制
# 查看Request()源码:因为传递的参数顺序问题,不能直接写url和headers,中间还有个data参数,所以需要使用关键字传参的方式传参
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
编码集的演变
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如:大写字母A的编码是65,小写字母z的编码是122。但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
试想一下,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
4.编解码
4.1 get请求方式
4.1.1 urllib.parse.quote()
import urllib.request
# 需要访问的url
url = 'https://www.baidu.com/s?ie=UTF-8&wd='
# 请求对象的定制是为了解决反爬的第一种方法
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}
# 将汉字 冰雪奇缘 解析为unicode编码格式,需要依赖于 urllib.parse
words = urllib.parse.quote('冰雪奇缘')
# 此时的url应当拼接
url = url + words
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的内容
content = response.read().decode('utf-8')
# 打印数据
print(content)
4.1.2 urllib.parse.urlencode()
import urllib.parse
import urllib.request
# urlencode()应用场景:url带有多个参数时
# url源码:https://www.baidu.com/s?ie=UTF-8&wd=%E5%86%B0%E9%9B%AA%E5%A5%87%E7%BC%98&type=%E7%94%B5%E5%BD%B1
# url解码:https://www.baidu.com/s?ie=UTF-8&wd=冰雪奇缘&type=电影
base_url = 'https://www.baidu.com/s?ie=UTF-8&'
data = {
'wd': '冰雪奇缘', 'type': '电影'}
urlEncode = urllib.parse.urlencode(data)
url = base_url + urlEncode
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
4.2 post请求方式
1.post请求百度翻译
import json
import urllib.parse
import urllib.request
# post请求百度翻译
# 浏览器 General-->Request URL:
# url = 'https://translate.google.cn/_/TranslateWebserverUi/data/batchexecute?rpcids=MkEWBc&f.sid=2416072318234288891&bl=boq_translate-webserver_20210908.10_p0&hl=zh-CN&soc-app=1&soc-platform=1&soc-device=1&_reqid=981856&rt=c'
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
# 浏览器 Request Headers-->user-agent:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}
# 浏览器 From Data(key-value形式的数据,注意:若浏览器data里面有:如:\ 字符,复制到Pycharm时,需要转义一下,记得多添加一个\)
# 示例:浏览器 From Data:f.req: [[["MkEWBc","[[\"Spider\",\"auto\",\"zh-CN\",true],[null]]",null,"generic"]]]
# data = {'f.req': '[[["MkEWBc","[[\\"Spider\\",\\"auto\\",\\"zh-CN\\",true],[null]]",null,"generic"]]]'}
data = {
'query': 'Spider'}
# post请求的参数,必须要进行解码 data = urllib.parse.urlencode(data)
# 编码之后,必须调用encode()方法 data = urllib.parse.urlencode(data).encode('utf-8')
data = urllib.parse.urlencode(data).encode('utf-8')
# 参数放在请求对象定制的方法中 request = urllib.request.Request(url=url, data=data, headers=headers)
request = urllib.request.Request(url=url, data=data, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# # 打印数据
print(content)
# 字符串 --> json对象
jsonObjContent = json.loads(content)
print(jsonObjContent)
小结:
post和get区别
- get请求方式的参数必须编码,参数是拼接到url后面,编码之后不需要调用encode方法
- post请求方式的参数必须编码,参数是放在请求对象定制的方法中,编码之后需要调用encode方法
2.post请求百度详细翻译,反爬–>Cookie(起决定性作用)解决
import json
import urllib.parse
import urllib.request
# post请求百度翻译之反爬Cookie(起决定性作用)
# 浏览器 General-->Request URL:
# url = 'https://translate.google.cn/_/TranslateWebserverUi/data/batchexecute?rpcids=MkEWBc&f.sid=2416072318234288891&bl=boq_translate-webserver_20210908.10_p0&hl=zh-CN&soc-app=1&soc-platform=1&soc-device=1&_reqid=981856&rt=c'
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
# 浏览器 Request Headers-->user-agent:
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
# }
headers = {
# 'Accept': '*/*',
# 'Accept-Encoding': 'gzip, deflate, br', # 一定要注释这句话
# 'Accept-Language': 'en-GB,en-US;q=0.9,en;q=0.8,zh-CN;q=0.7,zh;q=0.6',
# 'Connection': 'keep-alive',
# 'Content-Length': '137',
# 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'BIDUPSID=7881F5C444234A44A8A135144C7277E2; PSTM=1631452046; BAIDUID=7881F5C444234A44B6D4E05D781C0A89:FG=1; H_PS_PSSID=34442_34144_34552_33848_34524_34584_34092_34576_26350_34427_34557; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; delPer=0; PSINO=6; BAIDUID_BFESS=7881F5C444234A44B6D4E05D781C0A89:FG=1; BA_HECTOR=0k0h2h8g040l8hag8k1gjs8h50q; BCLID=7244537998497862517; BDSFRCVID=XrFOJexroG0YyvRHhm4AMZOfDuweG7bTDYLEOwXPsp3LGJLVJeC6EG0Pts1-dEu-EHtdogKK3gOTH4DF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tR3aQ5rtKRTffjrnhPF3KJ0fXP6-hnjy3bRkX4nvWnnVMhjEWxntQbLWbttf5q3RymJJ2-39LPO2hpRjyxv4y4Ldj4oxJpOJ-bCL0p5aHl51fbbvbURvDP-g3-AJ0U5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIEoCvt-5rDHJTg5DTjhPrMWh5lWMT-MTryKKJwM4QCObnzjMQYWx4EQhofKx-fKHnRhlRNB-3iV-OxDUvnyxAZyxomtfQxtNRJQKDE5p5hKq5S5-OobUPUDUJ9LUkJ3gcdot5yBbc8eIna5hjkbfJBQttjQn3hfIkj2CKLK-oj-D8RDjA23e; BCLID_BFESS=7244537998497862517; BDSFRCVID_BFESS=XrFOJexroG0YyvRHhm4AMZOfDuweG7bTDYLEOwXPsp3LGJLVJeC6EG0Pts1-dEu-EHtdogKK3gOTH4DF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF_BFESS=tR3aQ5rtKRTffjrnhPF3KJ0fXP6-hnjy3bRkX4nvWnnVMhjEWxntQbLWbttf5q3RymJJ2-39LPO2hpRjyxv4y4Ldj4oxJpOJ-bCL0p5aHl51fbbvbURvDP-g3-AJ0U5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIEoCvt-5rDHJTg5DTjhPrMWh5lWMT-MTryKKJwM4QCObnzjMQYWx4EQhofKx-fKHnRhlRNB-3iV-OxDUvnyxAZyxomtfQxtNRJQKDE5p5hKq5S5-OobUPUDUJ9LUkJ3gcdot5yBbc8eIna5hjkbfJBQttjQn3hfIkj2CKLK-oj-D8RDjA23e; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1631461937; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1631461937; __yjs_duid=1_9333541ca3b081bff2fb5ea3b217edc41631461934213; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; ab_sr=1.0.1_MTZhNGI2ZDNjYmUzYTFjZjMxMmI4YWM3OGU1MTM1Nzc4M2JiN2M0OTE3ZDcyNmEwMzY0MTA3MzI2NzZjMDBjNzczMzExMmQyZGMyOGQ5MjIyYjAyYWIzNjMxMmYzMGVmNWNmNTFkODc5ZTVmZTQzZWFhOGM5YjdmNGVhMzE2OGI3ZDFkMjhjNzAwMDgxMWVjMmYzMmE5ZjAzOTA0NWI4Nw==; __yjs_st=2_ZTZkODNlNThkYTFhZDgwNGQxYjE1Y2VmZTFkMzYxYzIyMzQ3Mjk4ZGM0NWViM2Y0ZDRkMjFiODkxNjQxZDhmMWNjMDA0OTQ0N2I2N2U4ZDdkZDdjNzAxZTZhYWNkYjI5NWIwMWVkMWZlYTMxNzA2ZjI0NjU3MDhjNjU5NDgzYjNjNDRiMDA1ODQ4YTg4NTg0MGJmY2VmNTE0YmEzN2FiMGVkZjUxZDMzY2U3YjIzM2RmNTQ4YThjMzU4NzMxOTBkZmJiMDgzZTIxYjdlMzIxY2M3MjhiNTQ4MGI2ZTI0ODRhMDI4NWI3ZDhhOGFkN2RhNjk2NjI3YzdkN2M5ZmQyN183XzI5ODZkODEz',
# 'Host': 'fanyi.baidu.com',
# 'Origin': 'https://fanyi.baidu.com',
# 'Referer': 'https://fanyi.baidu.com/translate?aldtype=16047&query=Spider&keyfrom=baidu&smartresult=dict&lang=auto2zh',
# 'sec-ch-ua': '"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"',
# 'sec-ch-ua-mobile': '?0',
# 'sec-ch-ua-platform': '"Windows"',
# 'Sec-Fetch-Dest': 'empty',
# 'Sec-Fetch-Mode': 'cors',
# 'Sec-Fetch-Site': 'same-origin',
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36',
# 'X-Requested-With': 'XMLHttpRequest',
}
# 浏览器 From Data(key-value形式的数据,注意:若浏览器data里面有:如:\ 字符,复制到Pycharm时,需要转义一下,记得多添加一个\)
# 示例:浏览器 From Data:f.req: [[["MkEWBc","[[\"Spider\",\"auto\",\"zh-CN\",true],[null]]",null,"generic"]]]
# data = {'f.req': '[[["MkEWBc","[[\\"Spider\\",\\"auto\\",\\"zh-CN\\",true],[null]]",null,"generic"]]]'}
data = {
'from': 'en', 'to': 'zh', 'query': 'Spider', 'transtype': 'realtime', 'simple_means_flag': '3',
'sign': '579526.799991', 'token': 'e2d3a39e217e299caa519ed2b4c7fcd8', 'domain': 'common'}
# post请求的参数,必须要进行解码 data = urllib.parse.urlencode(data)
# 编码之后,必须调用encode()方法 data = urllib.parse.urlencode(data).encode('utf-8')
data = urllib.parse.urlencode(data).encode('utf-8')
# 参数放在请求对象定制的方法中 request = urllib.request.Request(url=url, data=data, headers=headers)
request = urllib.request.Request(url=url, data=data, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# # 打印数据
print(content)
# 字符串 --> json对象
jsonObjContent = json.loads(content)
print(jsonObjContent)
5.ajax 的 get 请求
示例:豆瓣电影
爬取豆瓣电影-排行榜-古装-第一页的数据,并保存起来
# 爬取豆瓣电影-排行榜-古装-第一页的数据,并保存起来
# 这是一个get请求
import urllib.request
url = 'https://movie.douban.com/j/chart/top_list?type=30&interval_id=100%3A90&action=&start=0&limit=20'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 获取响应数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# 将数据下载到本地
# open()默认情况下使用的是gbk编码,若需要保存中文,想要在open()中指定为utf-8编码格式 encoding='utf-8'
# downloadFile = open('file/douban.json', 'w', encoding='utf-8')
# downloadFile.write(content)
# 这种写法是一样的效果
with open('file/douban1.json', 'w', encoding='utf-8') as downloadFile:
downloadFile.write(content)
爬取豆瓣电影-排行榜-古装-前10页的数据,并保存起来(古装数据没那么多,大概4页的样子,后面没有,爬下来数据就是空)
import urllib.parse
import urllib.request
# 爬取豆瓣电影-排行榜-古装-前10页的数据,并保存起来
# 这是一个get请求
# 找规律 top_list?type=30&interval_id=100%3A90&action=&start=40&limit=20
# 第1页:https://movie.douban.com/j/chart/top_list?type=30&interval_id=100%3A90&action=&start=0&limit=20
# 第2页:https://movie.douban.com/j/chart/top_list?type=30&interval_id=100%3A90&action=&start=20&limit=20
# 第3页:https://movie.douban.com/j/chart/top_list?type=30&interval_id=100%3A90&action=&start=40&limit=20
# 第n页:start=(n - 1) * 20
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=30&interval_id=100%3A90&action=&'
data = {
'start': (page - 1) * 20,
'limit': 20
}
data = urllib.parse.urlencode(data)
url = base_url + data
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def download(content, page):
# downloadFile = open('file/douban.json', 'w', encoding='utf-8')
# downloadFile.write(content)
# 这种写法是一样的效果
with open('file/douban_古装_' + str(page) + '.json', 'w', encoding='utf-8') as downloadFile:
downloadFile.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始的页码: '))
end_page = int(input('请输入结束的页码: '))
for page in range(start_page, end_page + 1):
# 每一页都有对自己请求对象的定制
request = create_request(page)
# 获取响应的数据
content = get_content(request)
# 下载
download(content, page)
6.ajax 的 post 请求
示例:KFC 官网,爬取肯德基官网-餐厅查询-城市:北京-前10页数据,并保存起来
import urllib.parse
import urllib.request
# 爬取肯德基官网-餐厅查询-城市:北京-前10页数据,并保存起来
# 这是一个post请求
# 找规律 GetStoreList.ashx?op=cname
# 请求地址:http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# Form Data
# 第1页
# cname: 北京
# pid:
# pageIndex: 1
# pageSize: 10
# 第2页
# cname: 北京
# pid:
# pageIndex: 2
# pageSize: 10
# 第n页
# cname: 北京
# pid:
# pageIndex: n
# pageSize: 10
def create_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '北京',
'pid': '',
'pageIndex': page,
'pageSize': 10,
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
request = urllib.request.Request(url=base_url, data=data, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def download(content, page):
# downloadFile = open('file/douban.json', 'w', encoding='utf-8')
# downloadFile.write(content)
# 这种写法是一样的效果
with open('file/KFC_city_beijing_' + str(page) + '.json', 'w', encoding='utf-8') as downloadFile:
downloadFile.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始的页码: '))
end_page = int(input('请输入结束的页码: '))
for page in range(start_page, end_page + 1):
# 每一页都有对自己请求对象的定制
request = create_request(page)
# 获取响应的数据
content = get_content(request)
# 下载
download(content, page)
7.URLError/HTTPError
简介
- HTTPError类是URLError类的子类
- 导入的包urllib.error.HTTPError, urllib.error.URLError
- http错误:http错误是针对浏览器无法连接到服务器而增加出来的错误提示。引导并告诉浏览者该页是哪里出了问题。
- 通过urllib发送请求的时候,有可能会发送失败,这个时候如果想让你的代码更加的健壮,可以通过try-except进行捕获异常,异常有两类,URLError\HTTPError
import urllib.request
import urllib.error
# url = 'https://blog.csdn.net/sjp11/article/details/120236636'
url = 'https://假设url写错,url会报错'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
try:
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级,请稍后再试...')
except urllib.error.URLError:
print('我都说了,系统正在升级,请稍后再试...')
8.cookie 登录
示例:weibo登陆
作业:qq空间的爬取
(暂缺代码)
9.Handler 处理器
学习 handler 处理器的原因:
urllib.request.urlopen(url):不能定制请求头
urllib.request.Request(url,headers,data):可以定制请求头
Handler:定制更高级的请求头。随着业务逻辑的复杂,请求对象的定制已经满足不了我们的需求(动态cookie和代理不能使用请求对象的定制)。
import urllib.request
# 使用handler来访问百度,获取网页源码
url = 'http://www.baidu.com'
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
# }
headers = {
'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.169Safari / 537.36'
}
request = urllib.request.Request(url=url, headers=headers)
# handler、build_opener、open
# 获取handler对象
handler = urllib.request.HTTPHandler()
# 获取opener对象
opener = urllib.request.build_opener(handler)
# 调用open方法
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)
10.代理服务器
-
代理的常用功能
-
突破自身IP访问限制,访问国外站点。
-
访问一些单位或团体内部资源
如:某大学FTP(前提是该代理地址在该资源的允许访问范围之内),使用教育网内地址段免费代理服务器,就可以用于对教育网开放的各类FTP下载上传,以及各类资料查询共享等服务。
-
提高访问速度
如:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时, 则直接由缓冲区中取出信息,传给用户,以提高访问速度。
-
隐藏真实IP
如:上网者也可以通过这种方法隐藏自己的IP,免受攻击。
-
-
代码配置代理
- 创建Reuqest对象
- 创建ProxyHandler对象
- 用handler对象创建opener对象
- 使用opener.open函数发送请求
代理
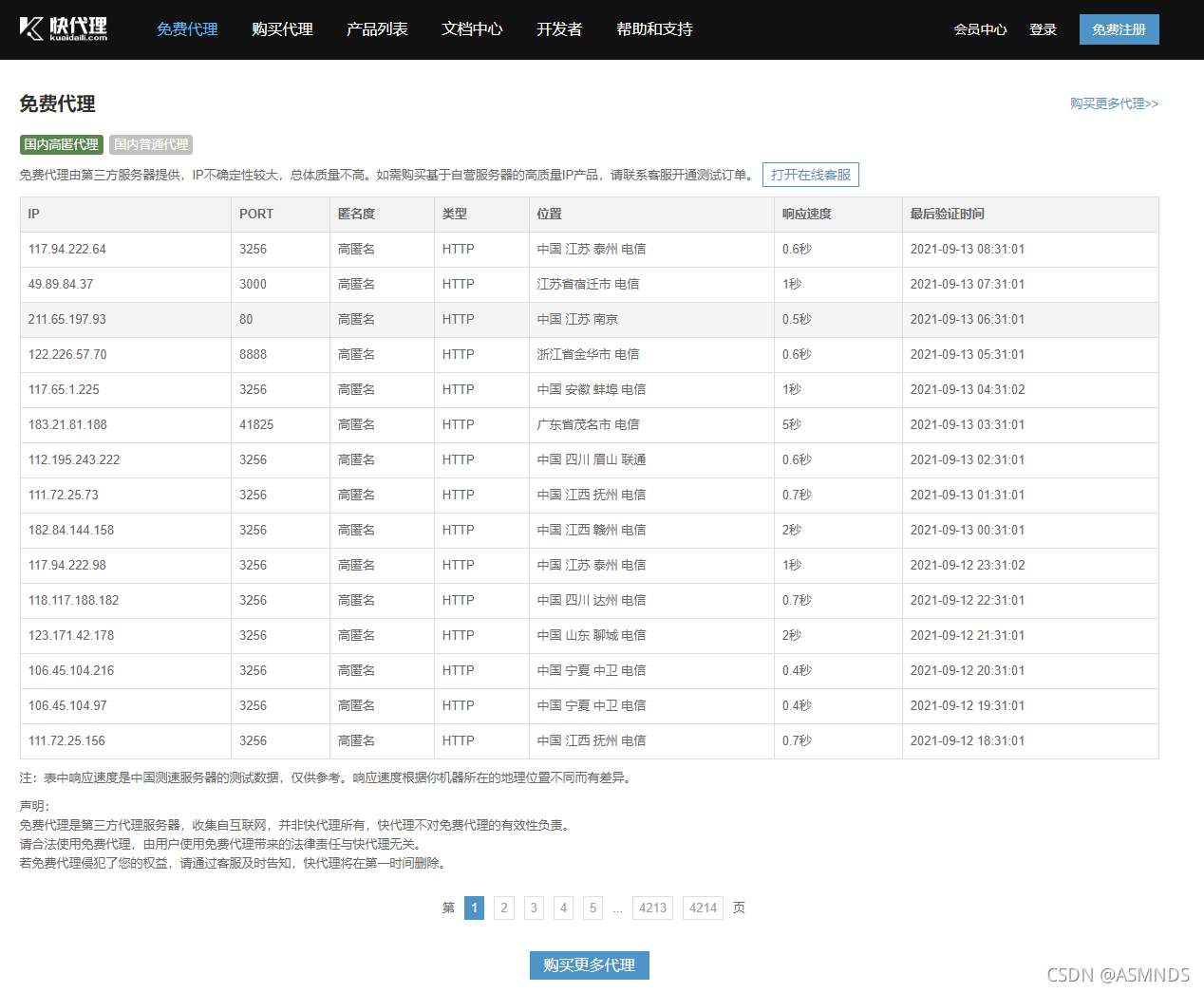
快代理-免费代理:https://www.kuaidaili.com/free/
也可以购买代理 IP:生成API连接-返回高匿的 ip 和 port,但是若高频次访问,还是会被封 ip,所以,需要代理池,就是指代理池里面有一堆高匿的 ip,不会暴露自己真实的 ip。
单个代理
import urllib.request
url = 'http://www.baidu.com/s?ie=UTF-8&wd=ip'
headers = {
'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.169Safari / 537.36'
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# 代理ip可以取这个网站找:https://www.kuaidaili.com/free/
proxies = {
'http': '211.65.197.93:80'}
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
# 模拟浏览器访问服务器
response = opener.open(request)
# 获取响应的信息
content = response.read().decode('utf-8')
# 保存到本地
with open('file/proxy.html', 'w', encoding='utf-8') as downloadFile:
downloadFile.write(content)
代理池
import random
import urllib.request
url = 'http://www.baidu.com/s?ie=UTF-8&wd=ip'
headers = {
'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.169Safari / 537.36'
}
# https://www.kuaidaili.com/free/
proxies_pool = [
{
'http': '118.24.219.151:16817'},
{
'http': '118.24.219.151:16817'},
{
'http': '117.94.222.64:3256'},
{
'http': '49.89.84.37:3000'},
{
'http': '211.65.197.93:80'},
{
'http': '122.226.57.70:8888'},
{
'http': '117.65.1.225:3256'},
{
'http': '183.21.81.188:41825'},
{
'http': '112.195.243.222:3256'},
{
'http': '111.72.25.73:3256'},
{
'http': '182.84.144.158:3256'},
{
'http': '117.94.222.98:3256'},
{
'http': '118.117.188.182:3256'},
{
'http': '123.171.42.178:3256'},
{
'http': '106.45.104.216:3256'},
{
'http': '106.45.104.97:3256'},
{
'http': '111.72.25.156:3256'},
{
'http': '111.72.25.156:3256'},
{
'http': '163.125.29.37:8118'},
{
'http': '163.125.29.202:8118'},
{
'http': '175.7.199.119:3256'},
{
'http': '211.65.197.93:80'},
{
'http': '113.254.178.224:8197'},
{
'http': '117.94.222.106:3256'},
{
'http': '117.94.222.52:3256'},
{
'http': '121.232.194.229:9000'},
{
'http': '121.232.148.113:3256'},
{
'http': '113.254.178.224:8380'},
{
'http': '163.125.29.202:8118'},
{
'http': '113.254.178.224:8383'},
{
'http': '123.171.42.178:3256'},
{
'http': '113.254.178.224:8382'},
]
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
proxies = random.choice(proxies_pool)
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
# 模拟浏览器访问服务器
response = opener.open(request)
# 获取响应的信息
content = response.read().decode('utf-8')
# 保存到本地
with open('file/proxies_poor.html', 'w', encoding='utf-8') as downloadFile:
downloadFile.write(content)
3、解析
1.xpath
1.1 xpath 的使用
安装 xpath 插件
打开 Chrome 浏览器 --> 点击右上角小圆点 --> 更多工具 --> 扩展程序 --> 拖拽xpath插件到扩展程序中 --> 如果crx文件失效,需要 将.crx文件后缀修改为.zip或.rar压缩文件 --> 再次拖拽 --> 关闭浏览器,重新打开 --> 随便打开一个网页,按 Ctrl + Shift + X --> 出现 小黑框,说明 xpath 插件 已生效
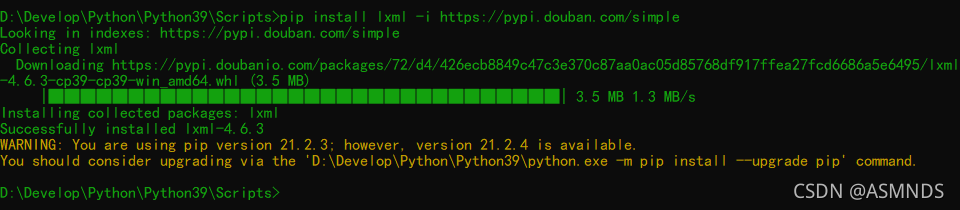
安装 lxml 库
注:安装路径与 Python 自带的库路径(Scripts目录路径)一致,如:D:\Develop\Python\Python39\Scripts
# 1.安装 lxml 库
pip install lxml -i https://pypi.douban.com/simple
# 2.导入lxml.etree
from lxml import etree
# 3.etree.parse() 解析本地文件
html_tree = etree.parse('XX.html')
# 4.etree.HTML() 服务器响应文件
html_tree = etree.HTML(response.read().decode('utf-8')
# 4.html_tree.xpath(xpath路径)
xpath 基本语法
# xpath 基本语法
# 1.路径查询
//:查找所有子孙节点,不考虑层级关系
/ :找直接子节点
# 2.谓词查询
//div[@id]
//div[@id="maincontent"]
# 3.属性查询
//@class
# 4.模糊查询
//div[contains(@id, "he")]
//div[starts‐with(@id, "he")]
# 5.内容查询
//div/h1/text()
# 6.逻辑运算
//div[@id="head" and @class="s_down"]
//title | //price
本地html文件:1905.html
<!DOCTYPE html>
<html lang="zh-cmn-Hans">
<head>
<meta charset="utf-8"/>
<title>电影网_1905.com</title>
<meta property="og:image" content="https://static.m1905.cn/144x144.png"/>
<link rel="dns-prefetch" href="//image14.m1905.cn"/>
<style>
.index-carousel .index-carousel-screenshot {
background: none;
}
</style>
</head>
<body>
<!-- 电影号 -->
<div class="layout-wrapper depth-report moive-number">
<div class="layerout1200">
<h3>
<span class="fl">电影号</span>
<a href="https://www.1905.com/dianyinghao/" class="fr" target="_blank">更多</a>
</h3>
<ul class="clearfix">
<li id="1">
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









