







上一篇博客介绍了如何在eclipse中添加本地hadoop依赖
这一次是老师布置的作业,我也是在B战上看到了基础教学视频,视频2是接着视频1的。现在来做个总结
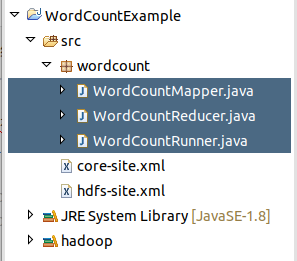
目录结构如下
代码下载
密码: 0uwj
在eclipse中打开是这样的:
准备工作
- hdfs开启
/hadoop安装目录/sbin/start-dfs.sh
- yarn开启
/hadoop安装目录/sbin/start-yarn.sh
- jps测试
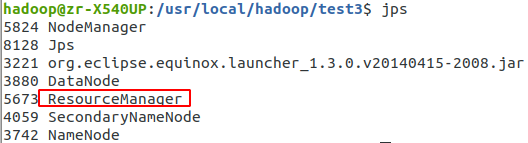
- 数据准备
- 创建目录 /test3/input
hdfs dfs -mkdir /test3
hdfs dfs -mkdir /test3/input
- 本地编辑一个文件 input.txt
随便写点内容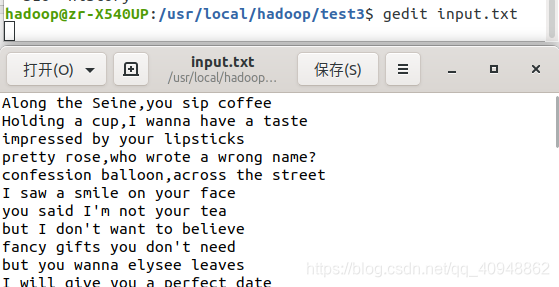
- 将input.txt上传至/test3/input
hadoop fs -put input.txt /test3/input
运行
- 在eclipse中,将项目导出jar包 wordcount.jar
- 执行命令
hadoop jar wordcount.jar wordcount.WordCountRunner
- 过程
等待即可

- 结果
- success标志为0,代表map-reduce成功

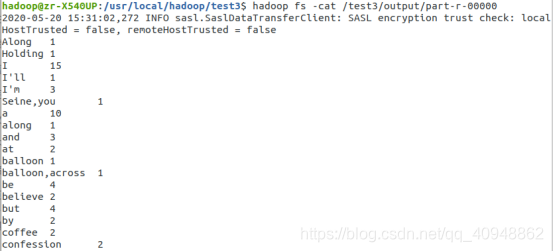
- 查看文件内容
hadoop fs -cat /test3/output/part-r-00000

















 7505
7505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









