







这是一个简单的小技巧
实现逻辑:
进入到boss直聘的网页版 , 按下F12
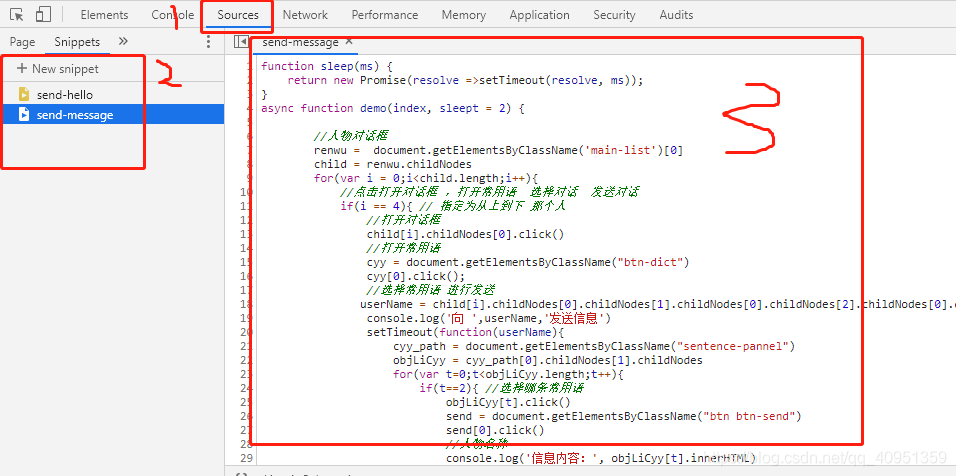 在这张图上就是如何在这个网页上插入js 的代码,通过触发按键的点击 实现触发,t贴上代码
在这张图上就是如何在这个网页上插入js 的代码,通过触发按键的点击 实现触发,t贴上代码
function sleep(ms) {
return new Promise(resolve =>setTimeout(resolve, ms));
}
async function demo(index, sleept = 2) {
//人物对话框
renwu = document.getElementsByClassName('main-list')[0]
child = renwu.childNodes
for(var i = 0;i<child.length;i++){
//点击打开对话框 ,打开常用语 选择对话 发送对话
if(i == 4){ // 指定为从上到下 那个人
//打开对话框
child[i].childNodes[0].click()
//打开常用语
cyy = document.getElementsByClassName("btn-dict")
cyy[0].click();
//选择常用语 进行发送
userName = child[i].childNodes[0].childNodes[1].childNodes[0].childNodes[2].childNodes[0].data
console.log('向 ',userName,'发送信息')
setTimeout(function(userName){
cyy_path = document.getElementsByClassName("sentence-pannel")
objLiCyy = cyy_path[0].childNodes[1].childNodes
for(var t=0;t<objLiCyy.length;t++){
if(t==2){ //选择哪条常用语
objLiCyy[t].click()
send = document.getElementsByClassName("btn btn-send")
send[0].click()
//人物名称
console.log('信息内容:', objLiCyy[t].innerHTML)
}
}
},2000);
}
}
}
demo()

















 1702
1702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









