







前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
开发工具
- Python
- Pycharm
import requests
from bs4 import BeautifulSoup相关模块可用pip命令安装
网页数据分析
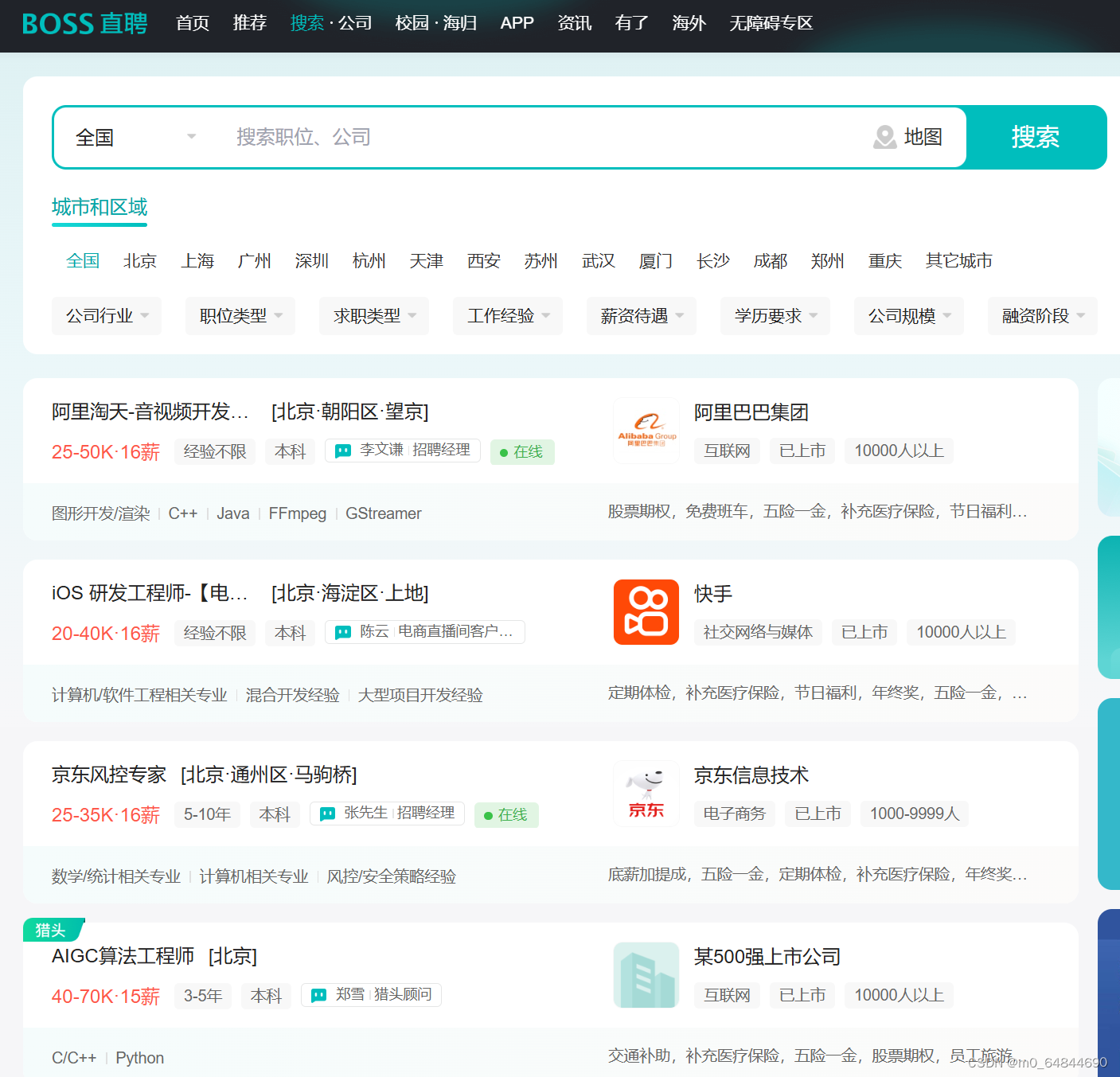

如图所示,这些数据都是今天要获取的内容
一、打开开发者工具
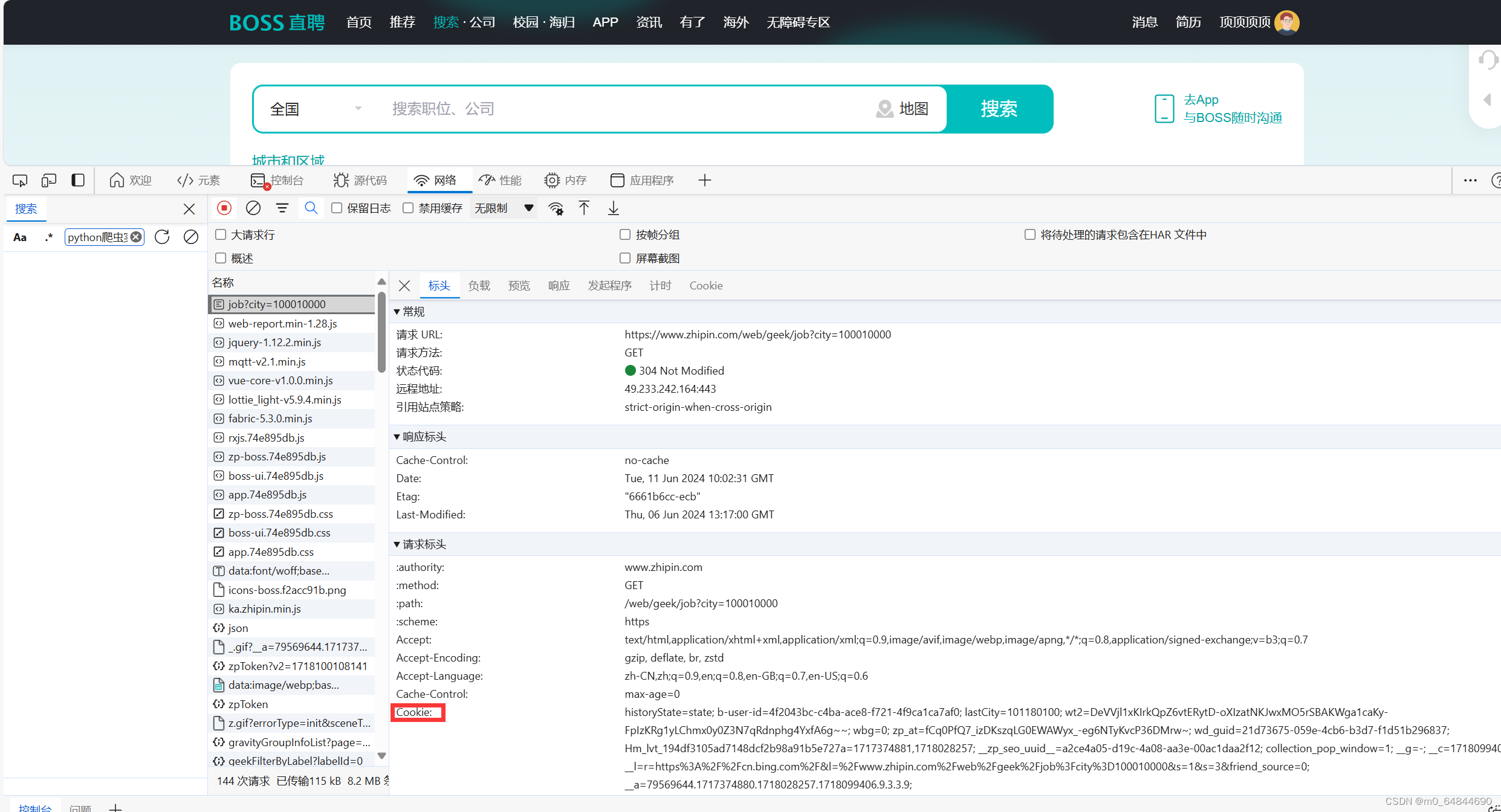
得到登录信息
二、分析网页数据结构
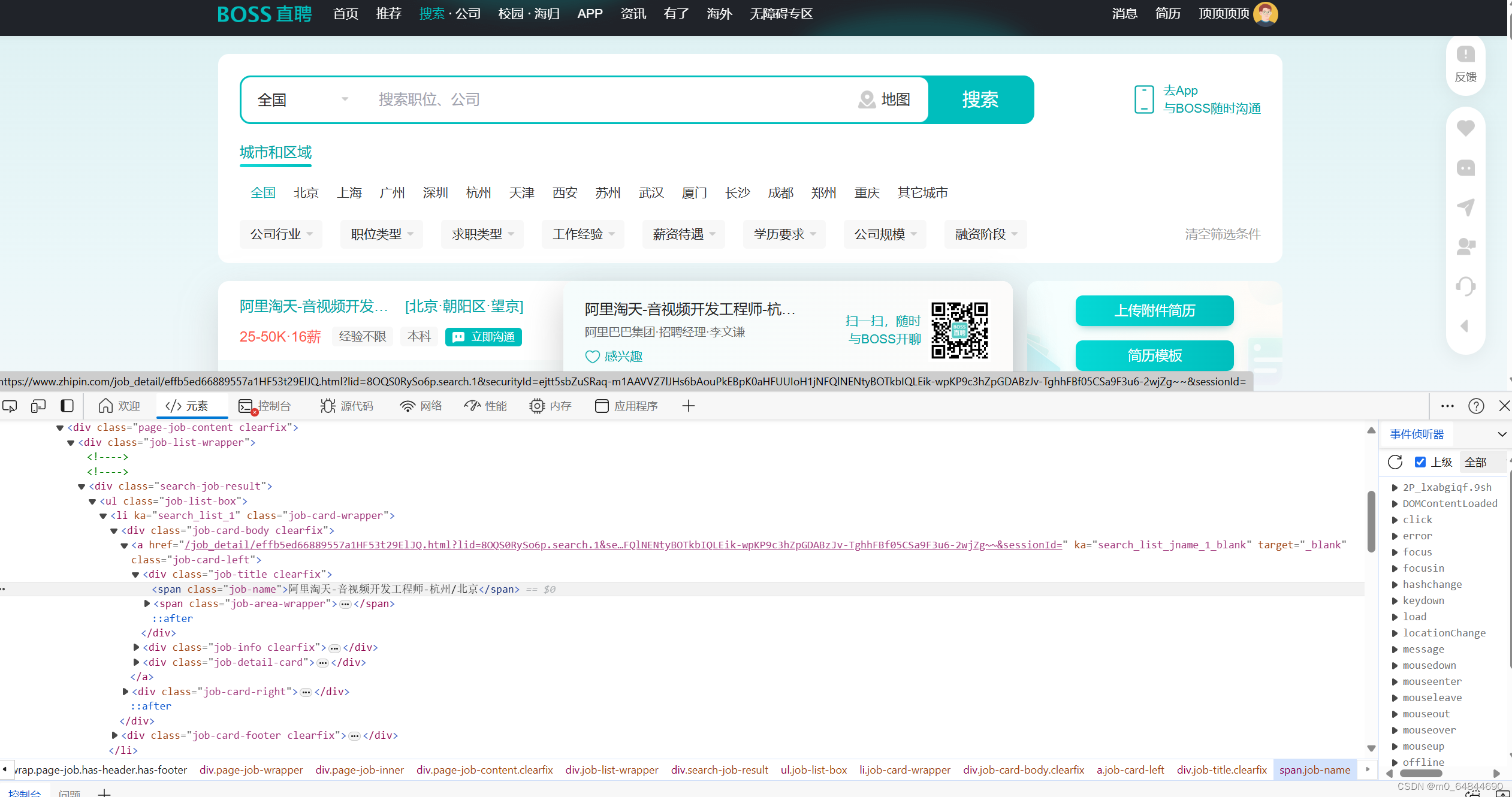
选择开发者工具中的 Elements 选择箭头 选择网页的数据,会自动跳转到网页标签中,告诉你这个数据是在网页标签里面的哪个位置。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2113
2113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









