







问题一:线程安全问题的由来?
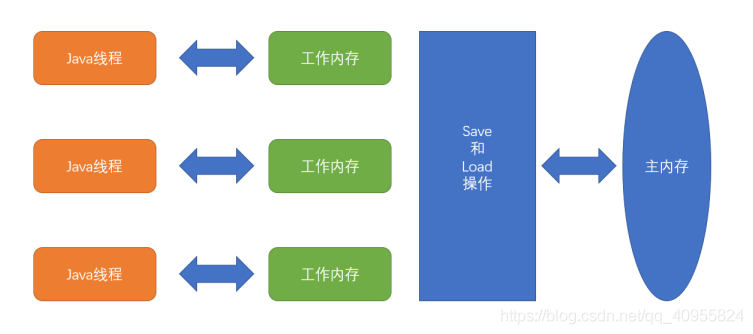
在JVM里面有一个工作内存和主内存,而每个线程都有自己的工作内存,当一个线程在对一个变量进行操作的时候,都要在自己的工作内存里对主内存进行拷贝一份(Load),然后再工作内存里对变量进行操作,操作完在把东西写回主内存(Save)。所以在多个线程对同一个变量进行操作时,就会出现线程安全问题,但是加上Synchronized关键字实际上就是建立一个monitor,然后通过monitor加锁来实现线程安全,只有当一个线程拿到这个monitor的时候才可以对这个变量或者方法进行操作。操作完后再加载到工作内存,然后再写回主内存,只有写回到主内存时才会释放锁。
问题二:线程安全对象和线程不安全对象有哪些?
线程安全:Vector,HashTable,StringBuffer
线程不安全:ArrayList,LinkedList,HashMap,HashSet,TreeMap,TreeSet,StringBuilder
问题三:如何保证容器是线程安全的?
在早期线程安全的集合是Vector和HashTable
Vector:他是长度可变的数组,和ArrayList一样。但是与ArrayList不一样的是,Vector是线程安全的。因为Vector几乎给所有的public方法上都加了synchronized关键字,因此由于加锁导致性能降低,在不需要并发访问时这种同步机制就显得多余。
HashTable:HashTable 与HashMap类似,但是HashTable是线程安全的它几乎给所有的public方法上都加了Synchronized关键字,而且hashTable 的key和value的值都不能为空
因为使用Synchronized加锁,粒度比较粗所以:,更加普遍的选择是利用并发包提供的线程安全容器类,它提供了:
- 各种并发容器,比如 ConcurrentHashMap、CopyOnWriteArrayList。
- 各种线程安全队列(Queue/Deque),如 ArrayBlockingQueue、SynchronousQueue。
- 各种有序容器的线程安全版本
具体保证线程安全的方式,包括有从简单的 synchronized 方式,到基于更加精细化的,比如基于分离锁实现的 ConcurrentHashMap 等并发实现等。具体选择要看开发的场景需求,总体来说,并发包内提供的容器通用场景,远优于早期的简单同步实现
ConcurrentHashMap
1.为什么需要ConcurrentHashMap?
Hashtable :
- 本身比较低效,因为它的实现基本就是将 put,get,size 等各种方法加上“synchronized”.,锁的是当前Hashtable对象,即整个哈希表。
- 当所有并发操作都要竞争同一把锁,获得当前table对象,所以当访问一个桶时就会把真个哈希表锁住。即一个线程在进行同步操作时,其他线程只能等待,大大降低了并发操作的效率
HashMap
- 多线程下:在竞争激烈的场景下使用HashMap会造成CPU飙到100%,
解决:使用ConcurrentHashMap来代替HashMap
- 性能主要开销 : resize()后的rehash过程
解决: 在能预估存放元素个数的前提下传入适当的初始化参数来尽量避免resize()
小tips:在resize过程中若发现桶下的红黑树节点<=UNTREEIFY_THRESHOLD,会将红黑树解除树化还原为链表结构。
2.1JDK8之前的ConcurrentHashMap:
- 分离锁,也就是将内部进行分段(Segment),里面则是 HashEntry 的数组,和 HashMap 类似,哈希相同的条目也是以链表形式存放.
- HashEntry 内部使用 volatile 的 value 字段来保证可见性
- JDK1.7concurrentHashMap底层是两个哈希表的嵌套
-
线程安全:使用ReentrantLock保证相应Segment下的线程安全
思路:通过锁细粒度化,将整表锁拆分为多个锁进行优化。
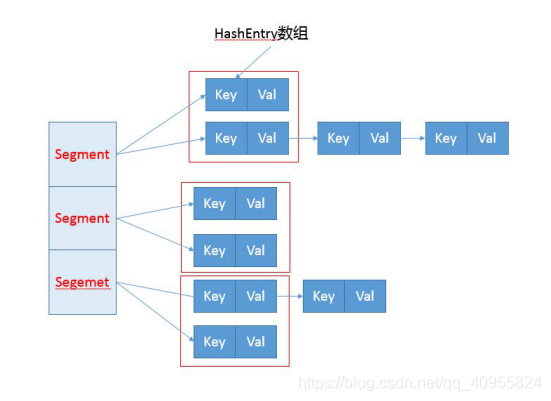
实现思路:
JDK7的ConcurrentHashMap:哈希表
将原先的16个桶设计改为16个Segment,每个Segment都有独立的一把锁。拆分后的每个Segment都相当于原先的一个HashMap(double-hash设计).并且Segment在初始化后无法扩容,每个Segment对应的哈希表可以扩容,扩容只扩容相应Segment下面的哈希表。Segment之间相互不影响
过程:先判断我在哪个segment下面,然后再hash一次判断我在哪个segment的哪个具体的桶里面,然后进行链表存储。
1.ConcurrentHashMap 会获入锁,以保证数据一致性,Segment 本身就是基于ReentrantLock 的扩展实现,所以,在并发修改期间,相应 Segment 是被锁定的
2.在最初阶段,进行重复性的扫描,以确定相应 key 值是否已经在数组里面,进而决定是更新还是放置操作。重复扫描、检测冲突是ConcurrentHashMap 的常见技巧
3.在 ConcurrentHashMap中扩容同样存在.不过有一个明显区别,就是它进行的不是整体的扩容,而是单独对 Segment 进行扩容
2.2JDK8下的ConcurrentHashMap:
- 整体结构与HashMap别无二致,都是使用哈希表+红黑树结构
- 线程安全:使用内建锁Sychronized+CAS锁每个桶的头结点,使得锁进一步细粒度化
- ConcurrentHashMap不允许键值对为空
3.JDK7与JDK8 ConcurrentHashMap的变化:
1.结构上的变化:
- 取消原先的Segment设计,取而代之的是使用与HashMap同样的数据结构,但其内部仍然有 Segment 定义,但仅仅是为了保证序列化时的兼容性而已,不再有任何结构上的用处
- 即哈希表+红黑树,并且引入了懒加载机制。(JDK1.7一上来就初始化,JDK1.8 在第一次put时才初始化)
2.线程安全:
- 锁粒度更细:由原来的锁Segment一片区域到锁桶的头结点
- 由原先的ReentrantLock替换为Sychronized+CAS:
现版本的sychronized已经经过不断优化,性能上与ReentrantLock基本没有差异,
并且相对于ReentrantLock,使用Sychronized可以节省大量内存空间(原来ReentrantLock下的segment都得加入同步队列,都得继承AQS下的Node,而synchronized只是锁住头结点,头结点下边的节点都不会加入同步队列里,所以 节省了空间),这是非常大的优势所在。
4.ConcurrentHashMap的源码分析














 138
138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









