







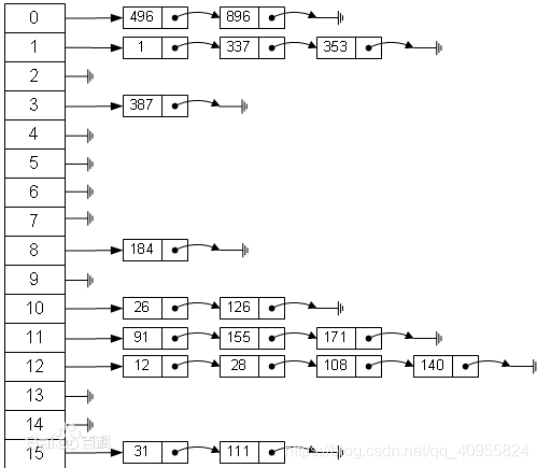
哈希表概念
哈希表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码散值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表
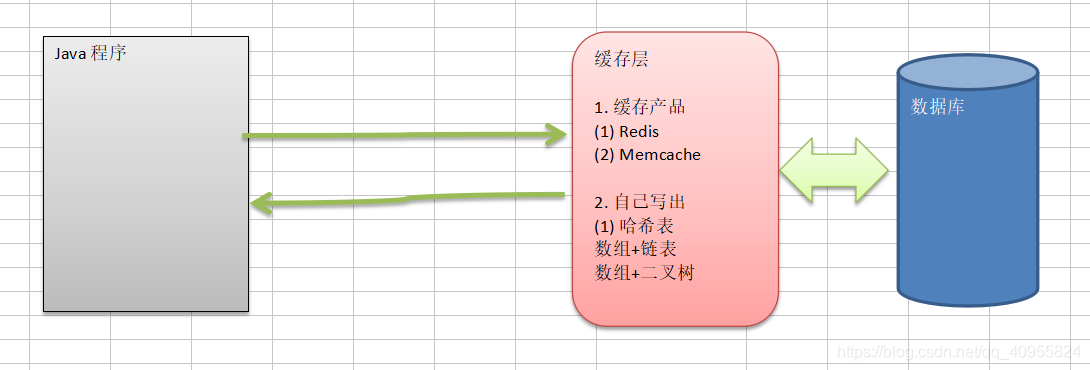
Java程序在访问数据库时候如果频繁的访问数据库,但是有的数据不用每次都查询数据库,这里可以采用缓存解决这个问题。
- 利用缓存的产品:Redis,Memcache
- 自己写一个哈希表(数组+链表,数组+二叉树)
哈希表的实现思路
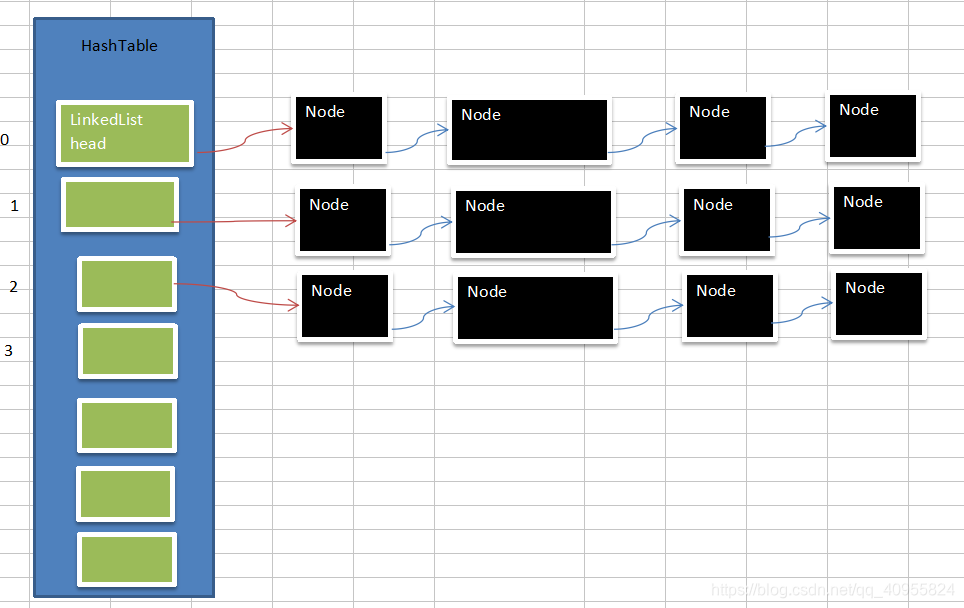
由图可知:哈希表的实现需要三个类:
//哈希表
class HashTab {
linkedList []
LinkedListArr
//add
//list
//find
//del
//散列函数 绝对id 对应到哪个链表
}
//链表
class LinkedList {
Node head = null; //头指针,
指向当前链表的第一个雇员
//相关对雇员的操作
//add
//list
//find
//del
}
//数据节点
class Node{
id;
name;
address;
}
代码的实现
思路在代码的备注里面
public class HashtableDemo {
public static void main(String[] args) {
//穿件哈希表
Hashtab hash=new Hashtab(8);
Node node1=new Node(1,"zhangsan");
Node node2=new Node(2,"zhang");
Node node3=new Node(3,"san");
Node node4=new Node(4,"1234");
hash.add(node1);
hash.add(node2);
hash.add(node3);
hash.add(node4);
hash.print();
hash.findNodeById(3);
}
}
//Node节点
class Node{
public int id;
public String name;
public Node next;//默认为null
public Node(int id, String name) {
super();
this.id = id;
this.name = name;
}
}
//创建哈希表
class Hashtab{
private LinkedList[] LinkedListArray;
private int size;
//构造器
public Hashtab(int size){
this.size=size;
//初始化LinkedListArray
LinkedListArray =new LinkedList[size];
//坑!!!! 这是要分别初始化每一个链表
for (int i = 0; i <size ; i++) {
LinkedListArray[i]=new LinkedList();
}
}
//添加雇员
public void add(Node node){
//根据原的id得到,应该添加到那一条链表
int linkedListNo=hashFun(node.id);
//把node节点添加到对应的链表中,
LinkedListArray[linkedListNo].add(node);
}
//遍历所有的链表,遍历HashTable
public void print(){
for (int i = 0; i <size ; i++) {//遍历哈希表的每一个链表
LinkedListArray[i].print(i);
}
}
//编写散列函数,使用简单的取模方法
public int hashFun(int id){
return id%size;//取模
}
//根据id查找节点
public void findNodeById(int id){
//使用哈希散列确定到哪个链表下查找该节点
int num=hashFun(id);
//在链表中查找
Node node =LinkedListArray[num].findNodeById(id);
if(node!=null){
System.out.printf("在%d条链表找到了Node id=%d",(num+1),id);
}else {
System.out.println("没有找到");
}
}
}
//创建一个LinkedList,表示链表
class LinkedList{
//头指针,指向第一个Node,因此这个head指向第一个第一个Node节点
private Node head;//默认为null
/*
添加Node到链表
说明:
1.假设:添加雇员时,id是自增长的,即id的分配是从小到大的
所以我们直接把Node接天添加到链表最后就行
*/
public void add(Node node ){
//如果是第一个Node,直接加入链表就行
if(head==null){
head=node;
return;
}
//不是第一个node,则需要一个辅助的节点,遍历到链表的租后
Node cur=head;
while(true){
if(cur.next==null){//说明到达链表的休后一个节点
break;
}
//把当前接地那继续向后移动
cur=cur.next;
}
//退出时直接把node节点加入到链表
cur.next=node;
}
//遍历链表
public void print(int no ){
if(head==null){
System.out.println("第"+no+"链表为null");
return;
}
System.out.print ("第"+no+"链表信息为");
Node cur=head;//辅助指针
while(true){
System.out.printf("=> id=%d name=%s\t",cur.id,cur.name);
if(cur.next==null){//说明为最后一个节点
break;
}
cur=cur.next;//遍历喜爱个节点
}
System.out.println();
}
//根据id查找雇员
public Node findNodeById(int id){
//判断链表是否为空
if(head==null){
System.out.println("链表为null");
return null;
}
//不为空,借助辅助指针查找
Node cur=head;
while(true){
if(cur.id==id){
break;//此时的cur就会要找的节点
}
//退出
if(cur.next==null){//说明遍历完当前节点没有找到该节点
cur=null;
}
cur=cur.next;//向后移动找节点
}
return cur;
}
}














 2213
2213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









