







一、背景介绍
简单地说,hnswlib算法可以实现对给定一批数据中的每个数据在这批数据中的K近邻计算。
在Python中使用hnswlib算法,需要导入hnswlib包,具体导入方式可以参考我之前的博客:Python中安装hnswlib。
导入成功,就可以结合我下面的demo使用hnswlib算法了。
二、实例讲解
代码如下:
import hnswlib
import numpy as np
data = np.array([[1,2,3],[2,4,6],[2,2,3],[4,5,6],[1,2,3]]) # <class 'numpy.ndarray'>
num_elements = data.shape[0]
dim = data.shape[1]
data_labels = np.arange(num_elements) # <class 'numpy.ndarray'>
# 构建索引
index = hnswlib.Index(space='l2',dim=dim)
index.init_index(max_elements=num_elements,ef_construction=200,M=16)
# 添加向量
index.add_items(data,data_labels)
# 临近索引
index.set_ef(50)
labels,distances = index.knn_query(data,4) # K=4
print(labels) #<class 'numpy.ndarray'>
print(distances) # <class 'numpy.ndarray'>
运行结果:
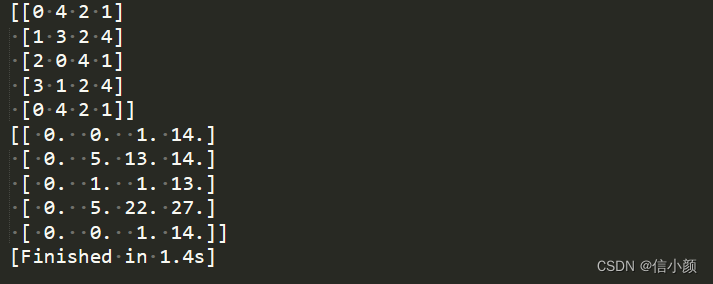
结果分析:hnswlib算法在求解某个数据的K近邻时,返回的是K近邻数据的索引。根据结果,可以看出,hnswlib在求解某个数据的K近邻时,是对本批数据从头到尾进行对比,并且是包括自己本身的。比如,前4个数据([1,2,3], [2,4,6] ,[2,2,3], [4,5,6])的K近邻都是以自己开头的,而最后一个数据([1,2,3])是以第一个数据(索引为0)开始,然后是自己本身。
以上就是所有内容了,如果大家有什么问题,欢迎在评论区留言。

















 4247
4247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











