






正则表达式
概述:正则是匹配模式,要么匹配字符,要么匹配位置。从而实现搜索和替换功能
下面分七个步骤真正去了解正则的使用:
- 正则基础结构
- 有关使用的API
- 各种字符的作用
- []、分组和分支结构
- 修饰符
- 匹配原理
- 提升效率
- 应用场景
1. 正则基础结构
/.../
例如:/delete/,但是只能匹配字符串中的"delete"这个子串,所以正则只有精确匹配是没多大意义的。
var regex = /delete/;
2. 有关正则使用的API
2.1 表达式API
- test,对于表达式对象的test方法,检查字符串是否与给出的正则表达式模式相匹配,如果是则返回 true,否则就返回 false。
var regex = /dev/;
regex.test("dev");
regex.test("evd");
regex.test("devd");
// => true
// => false
// => true
- exec,对于表达式对象的exec方法,检索字符串中的正则表达式的匹配,返回一个数组,其中存放匹配的结果。如果未找到匹配,则返回值为 null。
var str="dev";
var regex=/ev/;
regex.exec(str);
// => ["ev", index: 1, input: "dev", groups: undefined]
2.2 字符串API
- match,对于String对象的match方法,在字符串内检索指定的值,或找到一个或多个正则表达式的匹配(这个超纲举一个例子,后面会讲到)。
var str="dev vde";
var reg=/de/;
str.match(reg);
// => ["de", index: 0, input: "dev vde", groups: undefined]
var string = "JavaScript";
var reg=/.{4}(.+)/;
string.match(/.{4}(.+)/);
// => ['JavaScript', 'Script', index: 0, input: 'JavaScript', groups: undefined]
- replace,对于String对象的replace方法,用指定的字符串替换与字符串中正则表达式匹配的子字符串,返回字符串。
var str = "dev";
var reg = /e/;
str.replace(reg, '#');
// => d#v
- spilt,对于String对象的split方法,用指定正则表达式匹配的字符来分割字符串,\,返回一个数组。
var str = "2020-10-15";
var reg = /\-/;
str.split(reg);
// => ["2020", "10", "15"]
- search,对于String对象的search方法,检索与正则表达式相匹配的子字符串。返回第一个与正则表达式相匹配的子字符串的起始位置,位置是从0开始计算的。如果没有找到返回-1。
var str = "dev";
var reg = /v/;
str.search(reg);
// => 2
3 各种字符的作用

3.1 单个字符
有了字符组的概念后,一些常见的符号我们也就理解了。因为它们都是系统自带的简写形式。
\d就是[0-9]。表示是一位数字。记忆方式:其英文是digit(数字)。
\D就是[^0-9]。表示除数字外的任意字符。
\w就是[0-9a-zA-Z_]。表示数字、大小写字母和下划线。记忆方式:w是word的简写,也称单词字符。
\W是[^0-9a-zA-Z_]。非单词字符。
\s是[ \t\v\n\r\f]。表示空白符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页符。记忆方式:s是space character的首字母。
\S是[^ \t\v\n\r\f]。 非空白符。
.就是[^\n\r\u2028\u2029]。通配符,表示几乎任意字符。换行符、回车符、行分隔符和段分隔符除外。记忆方式:想想省略号…中的每个点,都可以理解成占位符,表示任何类似的东西。
var regex = /\d{6,12}/;
'14578789090000'.match(regex);
// => ["145787890900", index: 0, input: "14578789090000", groups: undefined]
var regex = /\w{6,12}/g;
'abcdefABC2'.match(regex);
// => ["abcdefABC2"]
var regex = /\s/g;
'abcdef ABC 2'.replace(regex, '*');
// => abcdef*ABC*2
如果要匹配任意字符怎么办?可以使用[\d\D]、[\w\W]和[\s\S]中任何的一个。
3.2 量词
*等价于{0,},表示出现任意次,有可能不出现。
+等价于{1,},表示出现至少一次。
?等价于{0,1},表示出现或者不出现。
{n, m}至少出现n次,至多出现m次。
{n}等价于{n,n},表示出现n次。
{n,}表示至少出现n次.
var string0 = 'ev';
var string1 = 'dev';
var string2 = ' dd e v d '
var regex = /d*/g;
string0.match(regex);
// ["", "", ""]
string1.match(regex);
// ["d", "", "", ""]
string2.match(regex);
// ["", "dd", "", "", "d", "", ""]
var string0 = 'ev';
var string1 = 'dev';
var string2 = 'ddevd'
var regex = /d+/g;
string0.match(regex);
// => null
string1.match(regex);
// => ["d"]
string2.match(regex);
// => ["dd", "d"]
var string0 = 'ev';
var string1 = 'dev';
var string2 = 'ddevd'
var regex = /d?/g;
string0.match(regex);
// ["", "", ""]
string1.match(regex);
// ["d", "", "", ""]
string2.match(regex);
// ["d", "d", "", "", "d", ""]
var string0 = 'ev';
var string1 = 'dev';
var string2 = 'ddevd'
var string3 = 'ddevddd'
var regex = /d{1,2}/g;
string0.match(regex);
// => null
string1.match(regex);
// ["d"]
string2.match(regex);
// ["dd", "d"]
string3.match(regex);
// ["dd", "dd", "d"]
3.3 位置
^(脱字符)匹配开头,在多行匹配中匹配行开头。在[]中表示取反
$(美元符号)匹配结尾,在多行匹配中匹配行结尾。
\b是单词边界,具体就是\w和\W之间的位置,包括\w和^之间的位置,也包括\w和$之间的位置。
\B就是\b的反面的意思,非单词边界。具体说来就是\w与\w、\W与\W、^与\W,\W与$之间的位置。
(?=p),其中p是一个子模式,即p前面的位置。前瞻
(?!p)就是(?=p)的反面意思,反前瞻
(?<=p)即p后面的位置,后顾
(?<!p)就是(?<=p)的反面意思,反后顾
var result = "dev".replace(/^|$/g, '#');
result;
// => #dev#
而且,^在不同情况下所代表的意义是不一样的
首先:做一个小实验
var regex = /^d/;
regex.test("de");
regex.test("ev");
regex.test("evd");
// => true
// => false
// => false
在这个实验中,我们可以发现,/^d/会匹配"de"中的"d",但是不会匹配"evd"中的"d",此时^d的意思是“匹配开头的d”。起到限定开头的作用。
var regex = /[^a]/g;
var string = "have";
string.match(regex);
// => ["h", "v", "e"]
在这个实验中,'^‘的意思是字符类的否定,上面的正则表达式的意思是匹配不是 a 的字符。起到取反的作用。
因此,只要是’^‘这个字符是在中括号’[]'中被使用的话就是表示字符类的否定,如果不是的话就是表示限定开头。
var result = "dev[1]".replace(/\b/g, '#');
var result1 = "dev[1]".replace(/\B/g, '*');
result;
// => #dev#[#1#]
result1;
// => d*e*v[1]*
var result = "dev".replace(/(?=v)/g, '#'); // 其中`p`是一个子模式,即`p`前面的位置。前瞻
var result2 = "dev".replace(/(?!v)/g, '#'); // (?=p)`的反面意思,反前瞻
result;
// => de#v
result2;
// => #d#ev#
var result = "dev".replace(/(?<=v)/g, '#'); // 即`p`后面的位置,后顾
var result2 = "dev".replace(/(?<!v)/g, '#'); // (?<=p)的反面意思,反后顾
result;
// => dev#
result2;
// => #d#e#v
4 []、分组和分支结构
4.1 []
[],具体到某一位字符时,它可以不是某个确定的字符,可以有多种可能。
var regex = /a[123]b/g;
var string = "a0b a1b a2b a3b a4b";
string.match(regex);
// => ["a1b", "a2b", "a3b"]
4.2 分组
所谓分组,即(),把括号内的看成一个整体。
var regex = /(ab)+/g;
var string = "ababa abbb ababab";
string.match(regex);
// => ["abab", "ab", "ababab"]
4.2.1 引用分组
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2020-10-15";
string.match(regex);
// => ["2020-10-15", "2020", "10", "15", index: 0, input: "2020-10-15", groups: undefined]
同时,也可以使用构造函数的全局属性$1至$9来获取,$是拿到小括号里的东西,$1是第一个小括号里的,$2是第二个小括号里的。
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2020-10-15";
string.match(regex);
RegExp.$1; // "2020"
RegExp.$2; // "10"
RegExp.$3; // "15"
比如,想把yyyy-mm-dd格式,替换成mm/dd/yyyy怎么做?
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, "$2/$3/$1");
result;
// => 06/12/2017
4.2.2 反向引用
除了使用相应API来引用分组,也可以在正则本身里引用分组。但只能引用之前出现的分组,即反向引用。
还是以日期为例。
比如要写一个正则支持匹配如下三种格式:
2020-06-12
2020/06/12
2020.06.12
最先可能想到的正则是:
var regex = /\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/;
var string1 = "2020-06-12";
var string2 = "2020/06/12";
var string3 = "2020.06.12";
var string4 = "2020-06/12";
regex.test(string1); // true
regex.test(string2); // true
regex.test(string3); // true
regex.test(string4); // true
其中/和.需要转义。虽然匹配了要求的情况,但也匹配"2016-06/12"这样的数据。
假设我们想要求分割符前后一致怎么办?此时需要使用反向引用:
var regex = /\d{4}(-|\/|\.)\d{2}\1\d{2}/;
var string1 = "2020-06-12";
var string2 = "2020/06/12";
var string3 = "2020.06.12";
var string4 = "2020-06/12";
regex.test(string1); // true
regex.test(string2); // true
regex.test(string3); // true
regex.test(string4); // false
注意里面的\1,表示的引用之前的那个分组(-|\/|\.)。不管它匹配到什么(比如-),\1都匹配那个同样的具体某个字符。因此要和()一起用。
\1表示重复正则第一个圆括号内匹配到的内容。
\2表示重复正则第二个圆括号内匹配到的内容。
但是如果不是单个括号而是嵌套分组呢?
以左括号(开括号)为准。比如:
var regex = /^((\d)(\d(\d)))\1\2\3\4$/;
var string = "1231231233";
RegExp.$1; // 123
RegExp.$2; // 1
RegExp.$3; // 23
RegExp.$4; // 3
regex.test(string); // true
我们可以看看这个正则匹配模式:
在上面例子中:
- 接下来的是
\1,是第一个分组内容,那么看第一个开括号对应的分组是什么,是123, - 接下来的是
\2,找到第2个开括号,对应的分组,匹配的内容是1, - 接下来的是
\3,找到第3个开括号,对应的分组,匹配的内容是23, - 最后的是
\4,找到第3个开括号,对应的分组,匹配的内容是3。
4.2.3 非捕获分组
之前文中出现的分组,都会捕获它们匹配到的数据,以便后续引用,因此也称他们是捕获型分组。
如果只想要括号最原始的功能,但不会引用它,即,既不在API里引用,也不在正则里反向引用。此时可以使用非捕获分组(?:p),例如:
//先看用捕获性分组匹配会返回什么
var str1 = '000aaa111';
var pattern1 = /([a-z]+)(\d+)/; //捕获性分组匹配
var arr1 = pattern1.exec(str1);
arr1
//['aaa111','aaa','111'] 结果子串也获取到了,这并不是我们想要的结果
//非捕获性分组
var str2 = '000aaa111';
var pattern2 = /(?:[a-z]+)(?:\d+)/; //非捕获性分组匹配
var arr2 = pattern2.exec(str2);
arr2
//['aaa111'] 结果正确
4.3 分支结构
多选分支可以支持多个子模式任选其一。但有个事实我们应该注意,比如我用/java|javascript/,去匹配"javascript"字符串时,结果是"java":
var regex = /java|javascript/g;
var string = "javascript";
string.match(regex);
// => ["java"]
而把正则改成/javascript|java/,结果是:
var regex = /javascript|java/g;
var string = "javascript";
string.match(regex);
// => ["javascript"]
也就是说,分支结构也是惰性的,即当前面的匹配上了,后面的就不再尝试了。
5 修饰符
1 ES5中修饰符,共3个:
g 全局匹配,即找到所有匹配的i 忽略字母大小写m 多行匹配,只影响^和$,二者变成行的概念,即行开头和行结尾。
对于上面几种正则API,加不加g的表现形式是不一样的。
var str="Dedv";
var reg=/d/;
str.match(/d/);
str.match(/d/g);
str.match(/d/gi);
// => ['d']
// => ['d']
// => ['D', 'd']
var string = "first line \n second line \n third line";
var pattern1 = /^s.*e$/;
var pattern2 = /^s.*e$/m;
string.match(pattern1); // null
string.match(pattern2); // ["second line"]
test,加不加g是一样的。
var str="Dev";
var reg=/[a-z]/;
reg.test(str);
reg.test(str);
reg.test(str);
// => true
// => true
// => true
var str="Dev";
var reg=/[a-z]/g;
reg.test(str);
reg.test(str);
reg.test(str);
// => true
// => true
// => true
exec,不加入g,则只返回第一个匹配,无论执行多少次均是如此,如果加入g,则第一次执行也返回第一个匹配,再执行返回第二个匹配,依次类推
var str="Dev";
var reg=/[a-z]/;
reg.exec(str);
reg.exec(str);
reg.exec(str);
// => ['e', index: 1, input: 'Dev', groups: undefined]
// => ['e', index: 1, input: 'Dev', groups: undefined]
// => ['e', index: 1, input: 'Dev', groups: undefined]
var str="Dev";
var reg=/[a-z]/g;
reg.exec(str);
reg.exec(str);
reg.exec(str);
// => ['e', index: 1, input: 'Dev', groups: undefined]
// => ['v', index: 2, input: 'Dev', groups: undefined]
// => null
match,不加入g,也只是返回第一个匹配,一直执行match方法也总是返回第一个匹配,加入g,则一次返回所有的匹配(注意这与表达式对象的exec方法不同,对于exec而言,表达式即使加上了g,也不会一次返回所有的匹配)。
var str="dev12ad";
var reg=/[a-z]/;
str.match(reg);
// => ["d", index: 0, input: "dev12ad", groups: undefined]
var str="dev12ad";
var reg=/[a-z]/g;
str.match(reg);
// => ["d", "e", "v", "a", "d"]
replace,表达式不加入g,则只替换第一个匹配,如果加入g,则替换所有匹配。
var str = "d1e23v";
var reg = /[a-zA-Z]/;
str.replace(reg, '');
// => ^1e23v
var str = "d1e23v";
var reg = /[a-zA-Z]/g;
str.replace(reg, '^');
// => ^1^23^
spilt,加不加g是一样的。
var str = "2020-10-15";
var reg = /\-/;
str.split(reg);
// => ["2020", "10", "15"]
var str = "2020-10-15";
var reg = /\-/g;
str.split(reg);
// => ["2020", "10", "15"]
search,对于String对象的search方法串。返回第一个与正则表达式相匹配的子字符串的起始位置,位置是从0开始计算的。如果没有找到返回-1。加不加g是一样的。
var str = "d1ev";
var reg = /1/;
str.search(reg);
// => 1
var str = "d1ev";
var reg = /1/g;
str.search(reg);
// => 1
2 ES6新增修饰符 y , u
1. y修饰符
y :也是全局匹配,首次匹配和g修饰符效果一样,但是第二次往后就不一样了
y 修饰符是规定要求匹配下标紧接着上一次匹配的开始 去匹配,不合适条件就为匹配失败为null。而g修饰符不一定要求匹配下标紧接着上一次开始匹配的去找,只要找到了就行
var string = 'bbb_bb';
var regex1 = /b{1,2}/g;
var regex2 = /b{1,2}/y;
regex1.exec(string);
regex1.exec(string);
// => ['bb', index: 0, input: 'bbb_bb', groups: undefined]
// => ['b', index: 2, input: 'bbb_bb', groups: undefined]
// => ['bb', index: 4, input: 'bbb_bb', groups: undefined]
// => null
regex2.exec(string);
regex2.exec(string);
// => ['bb', index: 0, input: 'bbb_bb', groups: undefined]
// => null
2. u修饰符
u修饰符就是拿来处理Unicode字符的。
正则表达式中的 . 在es5中是用来匹配任意字符的,其实严格来说是匹配不大于(0xFFFF)两个字节的任意字符,如果大于的话就会匹配不到,此时需要加上u修饰符才能匹配到。
要匹配的字符串中存在某个字符大于两个字节的,那么一定要加修饰符u,不然会匹配错误。
console.log(`\u{20BB7}`);
var string = '𠮷';
/^.$/.test(string); // => false
/^.$/u.test(string); // => true
6 匹配原理
正则表达式匹配字符串的这种方式,叫回溯法。
回溯法也称试探法,它的基本思想是:从问题的某一种状态(初始状态)出发,搜索从这种状态出发所能达到的所有“状态”,当一条路走到“尽头”的时候(不能再前进),再后退一步或若干步,从另一种可能“状态”出发,继续搜索,直到所有的“路径”(状态)都试探过。这种不断“前进”、不断“回溯”寻找解的方法,就称作“回溯法”。
本质上就是深度优先搜索算法。其中退到之前的某一步这一过程,我们称为“回溯”。从上面的描述过程中,可以看出,路走不通时,就会发生“回溯”。即,尝试匹配失败时,接下来的一步通常就是回溯。
写在前面
用 /nfa|nfa not/ 去匹配 “nfa not”。
如果匹配结果是 ‘nfa’,那这个就是传统型NFA(Thompson)了。
如果是 ‘nfa not’,那有可能是非传统性NFA(POSIX)。
那我们先来试试这个正则吧。
var regex = /nfa|nfa not/;
var string = 'nfa';
string.match(regex);
// => ["nfa", index: 0, input: "nfa", groups: undefined]
得到的结果是 nfa,那么可以确定 js 的引擎是 传统型NFA 了。也就是根据正则表达式来匹配文本的。
6.1 没有发生回溯的匹配
假设我们的正则是/ab{1,3}c/,其可视化形式是:
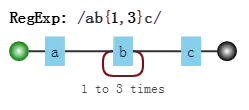
而当目标字符串是"abbbc"时,就没有所谓的“回溯”。其匹配过程是:
其中子表达式b{1,3}表示“b”字符连续出现1到3次。
6.2 发生回溯的匹配
假设我们的正则是/ab{1,3}c/,目标字符串是"abbc",中间就有回溯。
-
b{1,3}匹配到了2个字符“b”,一切正常 -
当第5步拿第三个表达式
b去匹配时,结果发现接下来的字符是“c”。那么就认为b{1,3}就已经匹配完毕,即b{2}。即状态回到之前的状态4 -
然后再用子表达式
c,去匹配字符“c”。整个表达式匹配成功了。
图中的第6步,就是“回溯”。你可能对此没有感觉,这里我们再举一个例子。正则是: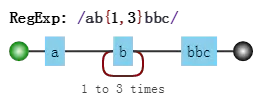
目标字符串是"abbbc",匹配过程是:
-
b{1,3}匹配到了3个字符“b”,一切正常 -
第6步拿表达式
b去匹配时,结果发现是c,就认为b{1,3}已经匹配完毕,即b{2},回到之前的状态4 -
继续匹配,然后第9步拿
b去匹配时,又是c,就认为b{1,3}已经匹配完毕,即b{1},回到之前的状态3 -
继续匹配,直到13匹配成功
6.3 常见的回溯形式
那么JS中正则表达式会产生回溯的地方都有哪些呢?
6.3.1 贪婪量词
之前的例子都是贪婪量词相关的。比如b{1,3},因为其是贪婪的,尝试可能的顺序是从多往少的方向去尝试。首先会尝试"bbb",然后再看整个正则是否能匹配。不能匹配时,吐出一个"b",即在"bb"的基础上,再继续尝试。如果还不行,再吐出一个,再试。如果还不行呢?只能说明匹配失败了。
虽然局部匹配是贪婪的,但也要满足整体能正确匹配。
此时我们不禁会问,如果当多个贪婪量词挨着存在,并相互有冲突时,此时会是怎样?
答案是,先下手为强!因为深度优先搜索。测试如下:
var string = "12345";
var regex = /(\d{1,3})(\d{1,3})/;
string.match(regex);
// => ["12345", "123", "45", index: 0, input: "12345"]
其中,前面的\d{1,3}匹配的是"123",后面的\d{1,3}匹配的是"45"。
6.3.2 惰性量词
惰性量词就是在贪婪量词后面加个问号。表示尽可能少的匹配,比如:
var string = "12345";
var regex = /(\d{1,3}?)(\d{1,3})/;
string.match(regex) ;
// => ["1234", "1", "234", index: 0, input: "12345"]
其中\d{1,3}?只匹配到一个字符"1",而后面的\d{1,3}匹配了"234"。
虽然惰性量词不贪,但也会有回溯的现象。比如正则是:
目标字符串是"12345",匹配过程是:
知道你不贪、很知足,但是为了整体匹配成,没办法,也只能给你多塞点了。因此最后\d{1,3}?匹配的字符是"12",是两个数字,而不是一个。
var string = "12345";
var regex = /^(\d{1,3}?)(\d{1,3})$/;
string.match(regex);
// => ["12345", "12", "345", index: 0, input: "12345", groups: undefined]
6.3.3 分支结构
我们知道分支也是惰性的,比如/can|candy/,去匹配字符串"candy",得到的结果是"can",因为分支会一个一个尝试,如果前面的满足了,后面就不会再试验了。
分支结构,可能前面的子模式会形成了局部匹配,如果接下来表达式整体不匹配时,仍会继续尝试剩下的分支。这种尝试也可以看成一种回溯。
比如正则: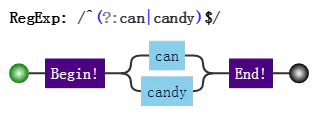
目标字符串是"candy",匹配过程:
上面第5步,虽然没有回到之前的状态,但仍然回到了分支结构,尝试下一种可能。所以,可以认为它是一种回溯的。
- 贪婪量词“试”的策略是:买衣服砍价。价钱太高了,便宜点,不行,再便宜点。
- 惰性量词“试”的策略是:卖东西加价。给少了,再多给点行不,还有点少啊,再给点。
- 分支结构“试”的策略是:货比三家。这家不行,换一家吧,还不行,再换。
7 提升效率
7.1 使用具体型字符组来代替通配符,来消除回溯
而在第3阶段,最大的问题就是回溯。
例如,匹配双引用号之间的字符。如,匹配字符串123"abc"456中的"abc"。
如果正则用的是:/".*"/,,会在第3阶段产生4次回溯(粉色表示.*匹配的内容):
如果正则用的是:/".*?"/,会产生2次回溯(粉色表示.*?匹配的内容):
因为回溯的存在,需要引擎保存多种可能中未尝试过的状态,以便后续回溯时使用。注定要占用一定的内存。
此时要使用具体化的字符组,来代替通配符.,以便消除不必要的字符,此时使用正则/"[^"]*"/,即可。
7.2 使用非捕获型分组
因为括号的作用之一是,可以捕获分组和分支里的数据。那么就需要内存来保存它们。
当我们不需要使用分组引用和反向引用时,此时可以使用非捕获分组。例如:/^[+-]?(\d+\.\d+|\d+|\.\d+)$/
可以修改成:/^[+-]?(?:\d+\.\d+|\d+|\.\d+)$/
或者:/^[+-]?\d+\.\d+|\d+|\.\d+$/
7.3 独立出确定字符
例如/a+/,可以修改成/aa*/。
因为后者能比前者多确定了字符a。这样会加快判断是否匹配失败,进而加快移位的速度。
7.4 提取分支公共部分
比如/^abc|^def/,修改成/^(?:abc|def)/。
又比如/this|that/,修改成/th(?:is|at)/。
这样做,可以减少匹配过程中可消除的重复。
7.5 减少分支的数量,缩小它们的范围
/red|read/,可以修改成/rea?d/。此时分支和量词产生的回溯的成本是不一样的。但这样优化后,可读性会降低的。
8 应用场景
// 一、 4到16位(字母,数字,下划线,减号)
var regex1 = /^[a-zA-Z0-9_-]{4,16}$/;
'abwc'.match(regex1);
// 二、 密码强度正则,最少6位,包括至少1个大写字母,1个小写字母,1个数字,1个特殊字符
var regex2 = /^(?=.*?[A-Z])(?=.*?[a-z])(?=.*[0-9])(?=.*[!@#$%^&*()-]).{6,}$/;
'Ad2-@jb'.match(regex2);
// 三、整数正则,分正负
// 正整数原则
var regex3 = /^\d+$/;
'23'.match(regex3);
// 负整数原则
var regex4 = /^-\d+$/;
'-23'.match(regex4);
// 整数原则
var regex5 = /^-?\d+$/;
'23'.match(regex5);
// 四、小数正则,分正负
// 正小数原则
var regex6 = /^\d+\.\d+$/;
'23.67'.match(regex6);
// 负小数原则
var regex7 = /^-\d+\.\d+$/;
'-23.78'.match(regex7);
// 小数原则
var regex8 = /^-?\d+\.\d+$/;
'23.89'.match(regex8);
// 五、邮箱
var regex9 = /^([A-Za-z0-9_\-\.])+\@([A-Za-z0-9_\-\.])+\.([A-Za-z]{2,4})$/;
'153522217@qq.com'.match(regex9);
// 六、手机号
var regex10 = /^(13[0-9])|(14[57])|(15[0-35-9])|(17[78])|(18[0-9])\d{8}$/;
'14578789090'.match(regex10);
// 七、身份证号(18位)
var regex11 = /^(\d{15}|\d{17}[\dxX])$/;
'12345619900909889x'.match(regex11);
// 八、车牌号正则
var regex12 = /^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9]{1}$/;
'京K39006'.match(regex12);
// 九、匹配中文
var regex13 = /[\u4E00-\u9FA5]+/;
'中'.match(regex13);
















 108
108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









