






今天探索高性能网络编程,但是我觉得在谈系统API之前可以先讲一些Linux底层的收发包过程,如下这是一个简单的socket编程代码:
int main() {
...
fd = socket(AF_INET, SOCKET_STREAM, 0);
bind(fd, ...);
listen(fd, ...);
// 如何建立连接
...
afd = accept(fd, ...);
// 如何接收数据
...
read(afd, ...);
// 如何发送数据
...
send(afd, ...);
// 如何关闭连接
...
close(fd);
...
}第一部分:如何建立连接
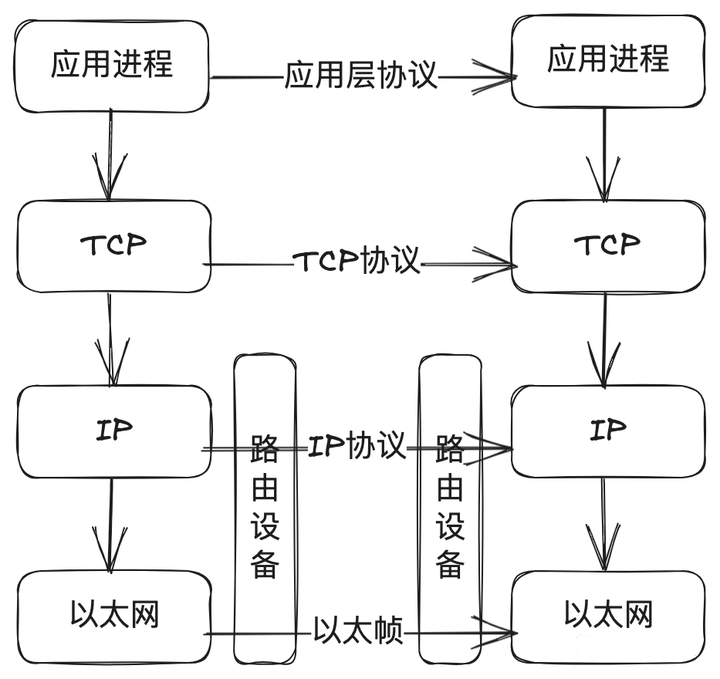
我们知道TCP/IP协议族划分了应用层、TCP传输层、IP网络层、链路层(以太层驱动)。
如上图看应用层,通常在网络编程中我们需要调用accept的API建立TCP连接,那TCP如何做的呢?

从上图的流程可以看到:
(1)client端发起TCP握手,发送syn包;
(2)内核收到包以后先将当前连接的信息插入到网络的SYN队列;
(3)插入成功后会返回握手确认(SYN+ACK);
(4)client端如果继续完成TCP握手,回复ACK确认;
(5)内核会将TCP握手完成的包,先将对应的连接信息从SYN队列取出;
(6)将连接信息丢入到ACCEPT队列;
(7)应用层sever通过系统调用accept就能拿到这个连接,整个网络套接字连接完成;
那基于这个图,我想问问读者这里会有什么问题么? 细心的读者应该可以看出:
1、这里有两个队列,必然会有满的情况,那如果遇到这种情况内核是怎么处理的呢?
(1)如果SYN队列满了,内核就会丢弃连接;
(2)如果ACCEPT队列满了,那内核不会继续将SYN队列的连接丢到ACCEPT队列,如果SYN队列足够大,client端后续收发包就会超时;
(3)如果SYN队列满了,就会和(1)一样丢弃连接;
2、如何控制SYN队列和ACCEPT队列的大小?
(1)内核2.2版本之前通过listen的backlog可以设置SYN队列(半连接状态SYN_REVD)和ACCEPT队列(完全连接状态ESTABLISHED)的上限;
(2)内核2.2版本以后backlog只是表示ACCEPT队列上限,SYN队列的上限可以通过/proc/sys/net/ipv4/tcp_max_syn_backlog设置;
3、server端通过accept一直等,岂不是会卡住收包的线程?
在linux网络编程中我们都会追求高性能,accept如果卡住接收线程,性能会上不去,所以socket编程中就会有阻塞和非阻塞模式。
(1)阻塞模式下的accept就会卡住,当前线程什么事情都干不了;
(2)非阻塞模式下,可以通过轮询accept去处理其他的事情,如果返回EAGAIN,就是ACCEPT队列为空,如果返回连接信息,就是可以处理当前连接;
相关视频推荐
tcpip,accept,11个状态,细枝末节的秘密,还有哪些你不知道
dpdk从tcp/ip协议栈开始,准备好linux环境一起开始
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

第二部分:接收数据
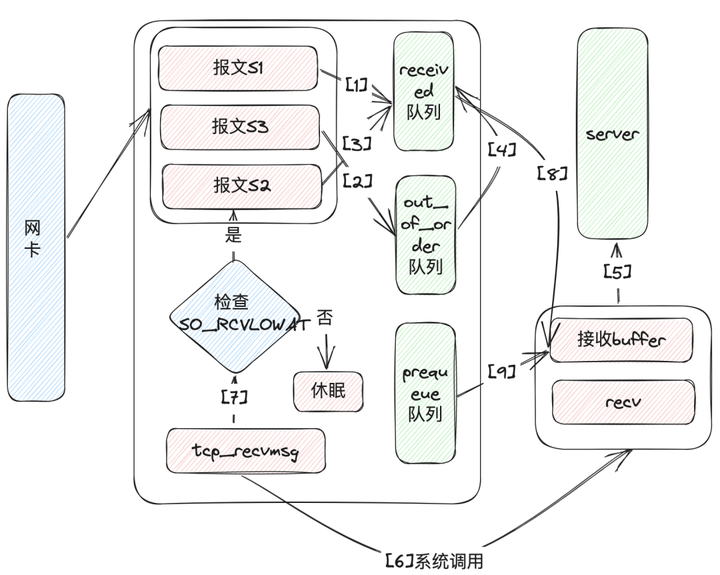
(1)当网卡接收到报文并判断为TCP协议后,将会调用到内核的tcp_v4_rcv方法,如果数据按顺序收到S1数据包,则直接插入receive队列中;
(2)当收到了S3数据包,在第1步结束后,应该收到S2序号,但是报文是乱序进来的,则将S3插入out_of_order队列(这个队列存储乱序报文);
(3)接下来收到S2数据包,如第1步直接进入receive队列,由于此时out_of_order队列不像第1步是空的,所以引发了接来的第4步;
(4)每次向receive队列插入报文时都会检查out_of_order队列,如果遇到期待的序号S3,则从out_of_order队列摘除,写入到receive队列;
(5)现在应用程序开始调用recv方法;
(6)经过层层封装调用,接收TCP消息最终会走到tcp_recvmsg方法;
(7)现在需要拷贝数据从内核态到用户态,如果receive队列为空,会先检查SO_RCVLOWAT这个阀值(0表示收到指定的数据返回,1表示只要读取到数据就返回,系统默认是1),如果已经拷贝的字节数到现在还小于它,那么可能导致进程会休眠,等待拷贝更多的数据;
(8)将数据从内核态拷贝到用户态,recv返回拷贝数据的大小;
(9)为了选择降低网络包延时或者提升吞吐量,系统提供了tcp_low_latency参数,如果为0值,用户暂时没有读数据则数据包进入prequeue队列,提升吞吐量,否则不使用prequeue队列,进入tcp_v4_do_rcv,降低延时;
第三部分:发送数据
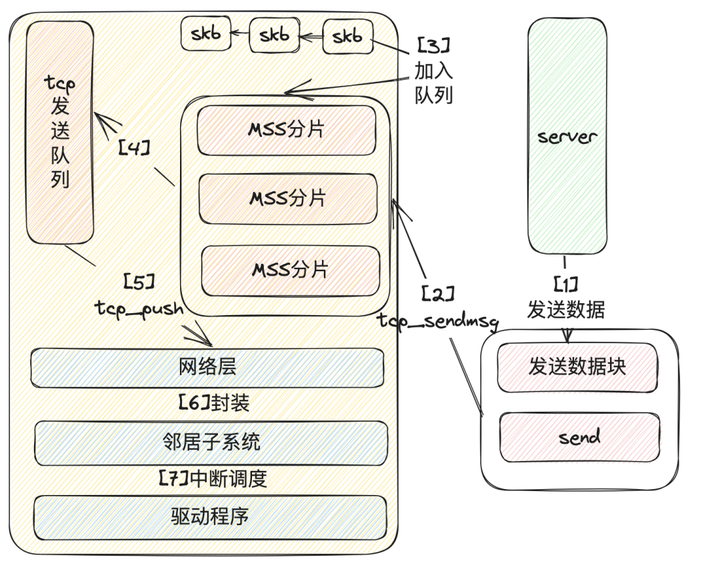
(1)假设调用send方法来发送大于一个MSS(比如2K)的数据;
(2)内核调用tcp_sendmsg,实现复制数据,写入队列和组装tcp协议头;
(3)在调用tcp_sendmsg先需要在内核获取skb,将用户态数据拷贝到内核态,内核真正执行报文的发送,与send方法的调用并不是同步的,即send方法返回成功,也不一定把IP报文都发送到网络中了。因此,需要把用户需要发送的用户态内存中的数据,拷贝到内核态内存中,不依赖于用户态内存,也使得进程可以快速释放发送数据占用的用户态内存。但这个拷贝操作并不是简单的复制,而是把待发送数据,按照MSS来划分成多个尽量达到MSS大小的分片报文段,复制到内核中的sk_buff结构来存放;
(4)将数据拷贝到发送队列中tcp_write_queue;
(5)调用tcp_push发送数据到IP层,这里主要滑动窗口,慢启动,拥塞窗口的控制和判断是否使用Nagle算法合并小报文(上一篇已经有介绍);
(6)组装IP报文头,通过经过iptables或者tcpdump等netfilter模块过滤,将数据交给邻居子系统(主要功能是查找需要发送的MAC地址,发送arp请求,封装MAC头等);
(7)调用网卡驱动程序将数据发送出去;
第四部分:关闭连接
关闭连接就是TCP挥手过程,我们都知道TCP连接是一种可靠的连接,那如何才能完整可靠的完成关闭连接呢?linux系统提供了两个函数:
-
close对应tcp_close方法,通过减少socket的引用次数实现关闭,仅当引用计数为0时才会触发tcp_close;
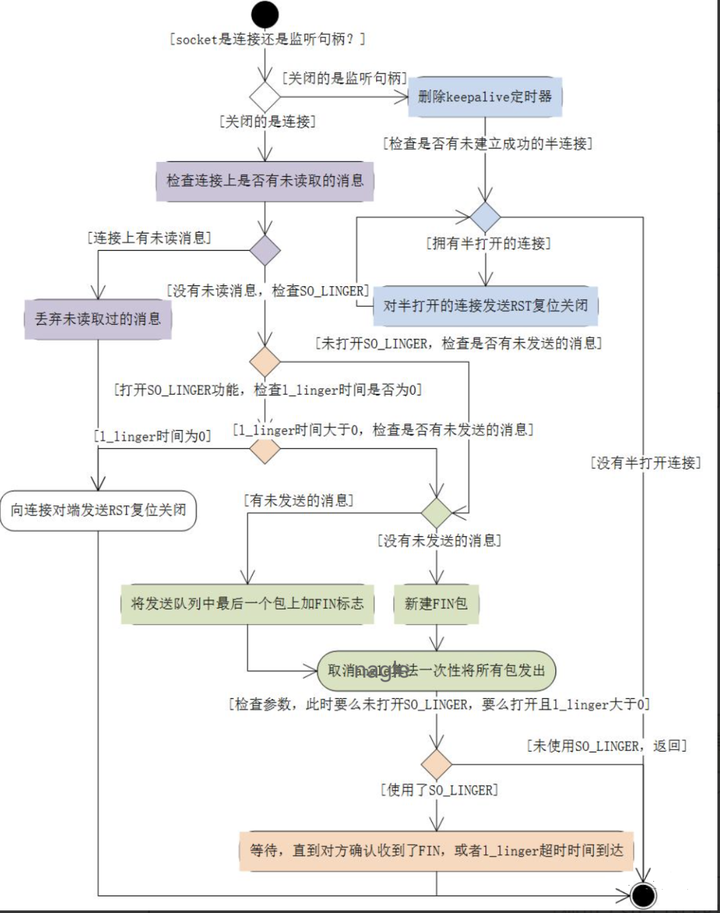
- shutdown对应tcp_shutdown方法,不关心socket被引用次数,直接关闭对应的连接;
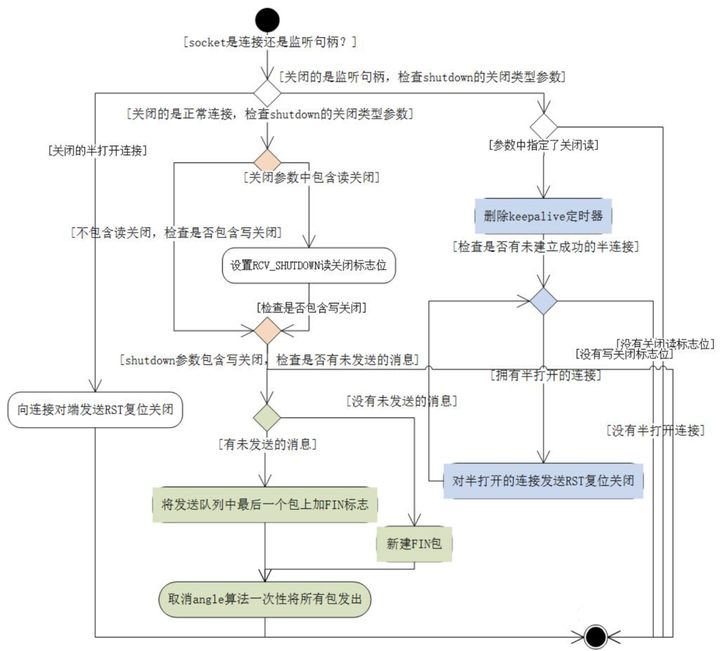
(1)shutdown可携带一个参数,取值有3个,分别意味着:只关闭读、只关闭写、同时关闭读写;
(2)若shutdown的是半打开的连接,则发出RST来关闭连接;
(3)若shutdown的是正常连接,那么关闭读其实与对端是没有关系的;
(4)若参数中有标志位为关闭写,那么下面做的事与close是一致的,发出FIN包,告诉对方本机不会再发消息了;
第五部分:思考题
基于本文留几个思考题。
(1)发送方法返回成功后,数据一定发送到了TCP的对端么? (调用了IP层的方法返回后,也未必就保证此时数据一定发送成功)
(2)1个socket套接字可能被多个进程在使用,出现并发访问时,内核是怎么处理这种状况的?
(3)若socket为默认的阻塞套接字,调用recv方法传入的len参数,如果网络包的数据小于len,recv会返回么?
(4)当socket被多进程或者多线程共享时,关闭连接时有何区别?















 1986
1986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









