









背景
基于AC网络的CTDE:
分布式执行actor网络采集数据以及模型推理,中心化critic网络训练actor网络。缺点:难以扩展到大规模agent环境中,原因:MADDPG(a)论文中证明随着agent数量增加,集中式critic网络会积累高方差问题,值函数很难收敛。当所有智能体都共用一个系统奖励时,每个智能体所学习的critic实际上是全局critic,评估的是所有智能体的整体观测-动作对的好坏,因此单个智能体无法从中判断自身观测-动作对整个系统的影响,这也就是所谓的信用分配(credit assignment)问题。
独立训练:
另外一个多agent训练思路,每个agent单独训练,将其他agent视为环境,例如IQL(b),对于这种同构的agent可以用参数共享的形式训练一个网络解决agent数量增加所带来的训练模型负担问题,缺点:忽略其他agent策略联合,对于合作型比较强的环境中很难获得较好训练结果。
奖励设计问题:
每个agent的奖励函数在大规模agent环境中较难设计。而共用一个系统全局团队回报的TD更新,在上述两种训练方式中无法体现出来agent之间的信用分配。

值函数分解
具体描述
介于两种极端训练方式以及解决多agent之间的信用分配问题的方法——值函数分解,如下图所示:

在值函数分解方法中,每个agent都有自己的“行为值函数”,中心式的行为值函数可以分解为每个行为值函数的某种组合。在这里我们把个体的行为值函数打了引号,是因为并非真正的行为值函数。为了区分行为值函数,我们这里称个体“行为值函数”为效用函数。行为值函数的分解可以表示为每个agent效用函数的组合。关于效用函数的引入,有以下几个方面的作用:
(1)效用函数细化了值函数的结构形式,使得联合行为-值函数的训练更方便和有针对性。
(2)该分解式的结构可以用于集中式训练,因此克服了多agent中动态环境的问题。
(3)效用函数用于从集中式值函数中构造和提取每个agent的局部策略,从而可以使得该算法用于大规模多agent系统中。例如,每个agent的贪婪策略为:。这一点很关键,也是值函数分解的精华。
值函数分解的条件IGM(Individual-Global-Max),即局部最优即为联合最优的某个组合:
近年经典论文
VDN(2018)
分解方式:,对效用函数进行简单加和,即
,显而易见其为IGM的充分条件。
缺点:线性分解值函数对于复杂协作任务你和能力较差。
QMIX(2018)
分解方式:
qmix使用超网络给出了更一般、非线性的值函数分解方式:
,
这样保证了局部最优就是联合最优,适合具有单调非线性收益的合作问题。
缺点:不适合具有非单调收益的合作问题。

WQMIX(2020)
本质上就是:限制学习率或者更新步长,解决以非单调值函数作为target,避免qmix算法陷入局部最优,同时保证了qmix的输出满足单调性约束。,
其中论文中提供两种赋权方式。
中心赋权:,目的减少次优策略的权重进行更新(稳定收入)。
乐观赋权:,目的使得次优动作成为最优动作(潜力股)。
不足之处:论文中权重函数设计比较简单;并且由于各种近似关系,部分实验场景中会导致整体性能下降。
QTRAN(2019)
给出了IGM可分解的更为广泛的充分条件。但定理给出的条件约束太多;负样本采集不足会导致算法陷入局部最优;算法方面做了很多的近似工作,实际算法性能在很多实验任务中并不如qmix的表现。
Qatten(2020)
优点:从理论上分析了多头注意力机制的设计灵感来源。
具体做法:
根据多元泰勒展开式:
其中
对于 效用函数在极值点处展开得:,将效用函数局部展开式带入上式联合值函数多元泰勒展开式中,忽略高阶项,将联合值函数$Q_{tot}$近似为效用函数$Q^i$的一阶线性组合,如下式所示:
其中,进而使用多头attention机制拟合
系数,此时attention head个数表示近似多少阶,每个头的注意力权重表示每阶的智能体系数。
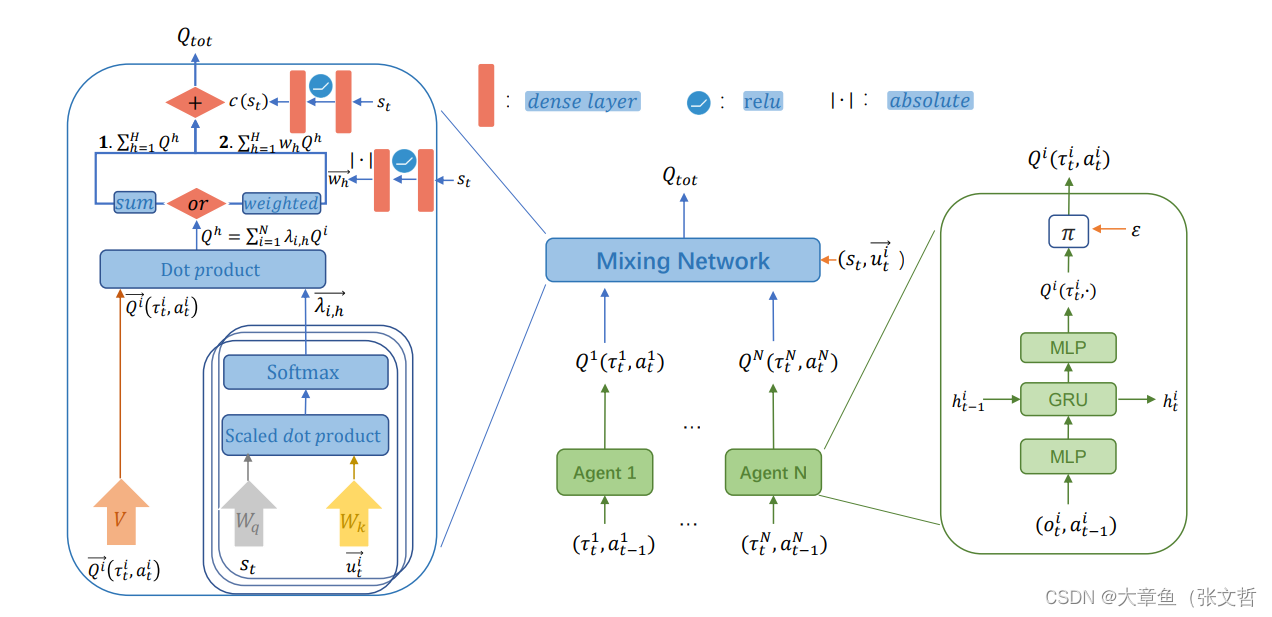
上图中weighted超网结构是为了应对更加复杂的环境,Qatten提出的权重头Q值,以捕获复杂的效用函数之间的关系:。
QPLEX(2020)
Dueling DQN:
普通的DQN只学习状态state下动作action的Q值,而Dueling DQN将Q函数拆成了state的Value和每个动作的Advantage之和:进行分解。这种分解的好处是让Q值的学习更稳健一点,因为它区分了状态的价值和动作的价值。即究竟是 s 是一个好的状态,无论做什么都会得到很高的回报,还是说这个动作a很好,可以解燃眉之急。
具体做法:
QPLEX利用advantage IGM 与IGM 为等价的条件,对效用函数进行单调分解,区分了状态的价值和动作的价值,使得QPLEX对IGM具有完全的表达能力。

Transformation网络:将局部的值函数与优势函数 与全局信息
(或联合观测历史 τ )结合,获得基于全局观测信息的局部值函数
。具体实现方式是:
。其中
是正权值,保证了局部函数和全局函数之间的单调性。
Duplex Dueling网络:类似于QMIX中的Mixing网络,通过 获得联合函数
:
最后使用两个联合函数生成联合动作值函数:
实际上前半部分与VDN保持一致,后半部分
修正了
与真实的联合Q值之间的误差。
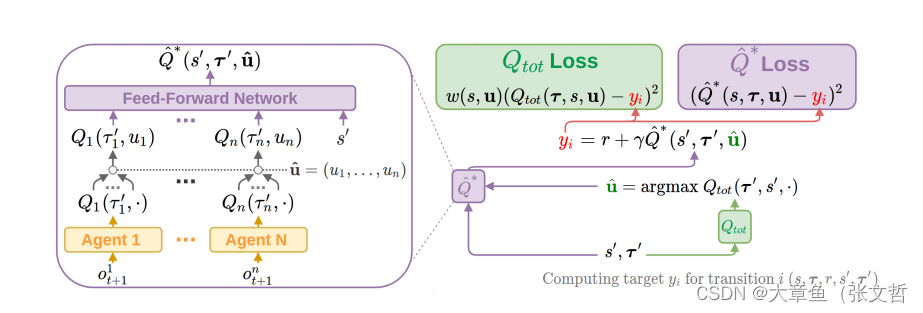
FACMAC(2022)
集大成者:
将值函数分解(QMIX)与集中式critic(MADDPG)相结合,使得值函数分解可以应用于多agent适用于连续任务(MPE)之中。

critic更新:对于采用TD更新方式(与QMIX保持一致):
其中,
actor更新:对于策略网络采用集中式的critic策略梯度更新的方式:
其中 是所有智能体策略的集合
优点:实验对比了QMIX和MADDPG两类多agent算法,表明了QMIX的优势。
缺点:论文实验结果同时也表明FACMAC效果可能还不如直接使用QMIX















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











