







 本文介绍QMIX,一种新型多智能体强化学习方法,可在集中式环境下训练分散式策略,通过复杂的非线性组合确保全局最优解与局部决策一致。实验结果表明,在星际争霸2微观管理任务上,QMIX明显优于现有方法。
本文介绍QMIX,一种新型多智能体强化学习方法,可在集中式环境下训练分散式策略,通过复杂的非线性组合确保全局最优解与局部决策一致。实验结果表明,在星际争霸2微观管理任务上,QMIX明显优于现有方法。
摘要
在许多现实环境中,一组代理人必须协调他们的行为,同时以分散的方式行事。同时,通常有可能在模拟或实验室环境中以集中的方式训练代理,其中全局状态信息可用并且通信约束被解除。学习联合行动以额外的全局信息为条件的价值观是利用集中学习的一种有吸引力的方式,但提取分散政策的最佳策略尚不清楚。我们的解决方案是QMIX,这是一种基于价值的新方法,可以以集中的端到端方式训练分散的策略。QMIX采用了一个网络,该网络将联合行动值估计为每个代理值的复杂非线性组合,该组合仅基于本地观察。我们在结构上强制联合行动值在每个代理的值中是单调的,这允许在非策略学习中联合行动值的可处理最大化,并保证集中和分散策略之间的一致性。我们在一组具有挑战性的星际争霸2微观管理任务上对QMIX进行了评估,结果表明QMIX明显优于现有的基于价值的多智能体强化学习方法。
引语
分散式必要性
- 部分可观测性和/或通信约束使得分散策略的学习成为必要,这仅取决于每个代理的本地动作观测历史。分散的策略也自然地减弱了联合行动空间随代理数量呈指数增长的问题
挑战和解决办法
-
这些挑战之一是如何表示和使用大多数RL方法学习的动作值函数。一方面,正确捕捉代理人行为的影响需要一个集中的行为价值函数,该函数决定全局状态和联合行为的条件。另一方面,当有许多代理时,这种函数很难学习,即使可以学习,也没有明显的方法提取分散的策略,允许每个代理根据单个观察只选择单个操作。
-
最简单的选择是放弃一个集中的行为价值函数,让每个代理独立地学习一个单独的行为价值函数,就像独立Q学习一样。然而,这种方法不能明确表示代理之间的交互,并且可能不会收敛,因为每个代理的学习都被其他代理的学习和探索所混淆。
-
在另一个极端,我们可以学习一个完全集中的状态动作值函数Qtotand,然后用它来指导在行动者-批评者框架中分散策略的优化,这是反事实多主体(COMA)策略梯度采取的方法(Foerster等人,2018年),以及Gupta等人(2017年)的工作。然而,这需要政策学习,这可能是样本效率低下的,当代理人超过少数时,培训完全集中的批评家变得不切实际。
-
在这篇文章中,我们提出了一种新的方法,叫做QMIX,它和VDN一样,位于IQL和COMA的极端之间,但是可以代表一类更丰富的actionvalue函数。我们的方法的关键是洞察到,VDN的完全分解对于提取分散的政策是不必要的。相反,我们只需要确保在Qott上执行的全局argmax产生与在每个Qa上执行的一组单独argmax操作相同的结果。为此,对Qtotand和每个Qa之间的关系实施单调性约束就足够了:
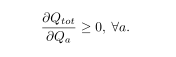
-
QMIX由代表每个Qa的代理网络和将它们组合成Qtot的混合网络组成,不是像VDN那样简单的总和,而是以复杂的非线性方式,确保集中和分散策略之间的一致性。同时,它通过限制混合网络具有正权重来实施(1)的约束。因此,QMIX可以表示复杂的集中式动作值函数,并带有因子表示,可以很好地扩展代理数量,并允许通过线性时间的单个argmax操作轻松提取分散的策略。
-
我们在星际争霸II1中构建的一系列单位微观管理任务上评估QMIX。(Vinyals等人,2017年)。我们的实验表明,QMIX在绝对性能和学习速度方面都优于IQL和VDN。特别是,我们的方法在具有异构代理的任务上显示出可观的性能提升。此外,我们的消融显示了调节状态信息和非线性混合剂Q值的必要性,以实现跨任务的一致性能。
相关工作
- 最近在多智能体RL方面的工作已经开始从表格方法转移(杨和顾,2004;Busoniu等人,2008年)到可以处理高维状态和动作空间的深度学习方法(Tampuu等人,2017年;Foerster等人,2018年;彭等,2017)。在本文中,我们将重点放在合作设置上。
- 一方面,为多主体系统寻找策略的自然方法是直接学习分散的价值函数或策略。独立的Q学习(Tan,1993)使用Q学习为每个主体训练独立的行为价值函数(Watkins,1989)。(Tampuu等人,2017)使用DQN将这种方法扩展到深度神经网络(Mnih等人,2015)。虽然这些方法很容易实现去中心化,但是由于同时学习和探索代理所导致的环境的非平稳性,它们很容易产生不稳定性。Omidshafiei等人(2017)和Foerster等人(2017)在一定程度上解决了学习稳定性问题,但仍然学习分散的值函数,并且不允许在训练过程中包含额外的状态信息。
- 另一方面,联合行动的集中学习可以自然地处理协调问题,避免非平稳性,但很难扩展,因为联合行动空间的代理数量呈指数级增长。可扩展集中式学习的经典方法包括协调图(Guestrin等人,2002),该方法通过将全局奖励函数分解为代理局部项的总和来利用代理之间的条件独立性。稀疏合作Q学习(Kok & Vlassis,2006)是一种表格Q学习算法,它只在需要协调的状态下学习协调一组合作代理的动作,并将这些依赖关系编码在一个协调图中。这些方法需要预先提供代理之间的依赖关系,而我们不需要这样的先验知识。相反,我们假设每个代理总是对全局奖励做出贡献,并了解其在每个州的贡献大小。

















 4219
4219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









