







yarn的出现
Hadoop1.x只由hdfs和mapreduce组成,其中MapReduce由一个JobTracker和多个TaskTracker组成。JobTracker负责资源管理和所有作业的控制,TaskTracker负责接收来自JobTracker的命令并执行它。
后来Hadoop升级,Hadoop2.x框架包括三个模块:
- hdfs:分布式文件存储系统
- mapreduce:分布式计算框架
- yarn:资源调度系统
其中yarn就是将第一代的MapReduce中的JobTracker分离出来做成的资源管理框架。JobTracker中的资源管理发展成yarn的ResourceManager(RM 资源管理器),作业控制发展成yarn的ApplicationMaster(AM 程序管理员)。
同时,yarn作为Hadoop2.x中的资源管理系统,是一个通用的资源管理模块,可以为各类应用程序进行资源管理和调度,不仅限于MapReduce一种框架,也可以为其他框架所使用,比如Tez、Spark、Storm等。
主要组件
- ResourceManager
RM:资源管理器。负责整个集群资源的协调和调度。 - NodeManager
NM:节点管理器。是每个节点上的资源和任务管理器,定时向RM汇报本节点上的资源使用情况和各个Container的运行状态,同时会接收并处理来自AM的Container的启动/停止等请求。 - ApplicationMaster
AM:程序管理器。是一个单独进程,在其中一个子节点上运行。负责应用的监控,跟踪应用执行状态,重启失败任务等。 - Container
资源。封装了某节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源是用Container表示的。yarn会为每个任务分配一个Container且该任务只能用Container中描述的资源。
简单讲述一下Yarn Application生命周期
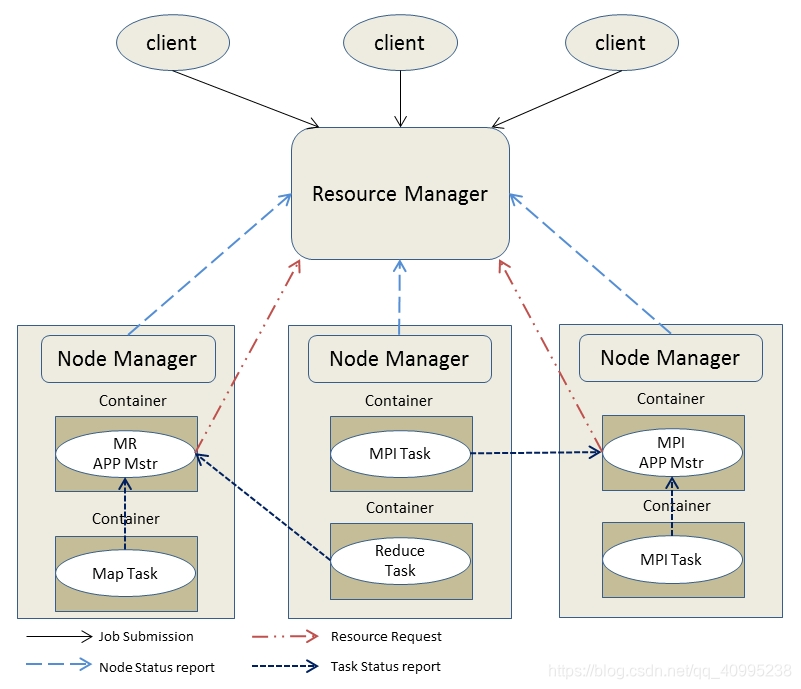
图中客户端向yarn提交了两个application:MR、MPI(随便起的名)。图中的MR APP Mstr 和 MPI APP Mstr分别是两个application的AM。
- 用户通过client向YARN提交application,如mr、spark任务,ResourceManager(资源管理器)接收到客户端程序的运行请求。
- ResourceManager分配一个Container(资源)给一个NodeManager(节点管理器),用来启动ApplicationMaster(程序管理器),并告知这个NodeManager,要求它在这个Container下启动ApplicationMaster。
- ApplicationMaster启动后,向ResourceManager发起注册请求。这样用户可以通过ResourceManager来查看应用程序的运行状态,然后ApplicationMaster将为各个任务申请资源,并监控任务的运行状态,直到运行结束,即重复步骤4~7。
- ApplicationMaster通过轮询的方式向ResourceManager申请资源。
- 一旦取得资源后,ApplicationMaster便向对应的NodeManager通信,要求其启动任务。
- NodeManager为任务设置好运行环境后,如环境变量、jar包等,便启动各个任务。
- 各个任务不断汇报状态和进展给ApplicationMaster,以让ApplicationMaster随时掌握其运行状态,从而可以在任务失败时重启任务。
- 当任务全部完成时,ApplicationMaster向ResourceManager汇报任务完成,并注销关闭自己。
总结:
RM,NM相当于写字楼的管理者,RM总管,NM区域管理,它们提供container(办公室);AM相当于项目经理,向写字楼管理者申请办公室,在它们提供的container上执行task,完成客户提交的job。
MapReduce在yarn上提交job的流程

- 客户端向resourcemanager提交job运行的请求(hadoop jar xxxx.jar)
- Resourcemanager进行检查,没有问题的时候,向客户端返回一个HDFS共享资源路径以及JobID
- 客户端将共享资源放入共享路径下:(/tmp/hadoop-yarn/staging/hadoop/.staging/job_1539740094604_0002/),包括:
- Job.jar 需要运行的jar包,重命名为job.jar
- Job.split 切片信息 (FlieInputFormat—getSplits List)
- Job.xml 配置文件信息 (一些列的job.setxxxx())
- 客户端向resourcemanager反馈共享资源放置完毕,进行job的真正提交
- resourceManager为这个job分配一个节点
- resourceManager到该节点启动一个container,然后在container中启动MRAPPmaster任务(AM 程序管理器)
- MRappmaster去共享资源路径中下载资源(主要是切片信息)
- MRappmater对job进行初始化,生成一个job工作簿,job的工作薄记录着maptask和reducetask的运行进度和状态
- MRappmaster向resourcemanager申请maptask和reducetask的运行的资源,先发maptask然后发reducetask
- resourcemanager向MRAPPmaster返回maptask和reducetask的资源节点(返回节点时,有就近原则,优先返回当前的maptask所处理切片的实际节点,数据处理的时候可以做到数据的本地化处理。如果是多副本的时候就在多副本的任意节点。而reduce任务在任意不忙的节点上启动)
- MRAPPmaster到对应的节点上启动一个container,然后在container中启动map任务
- map任务到对应的共享资源路径下载相应的资源(运行的jar包)
- map任务启动,并且定时向MRAPPmaster汇报自己的运行状态和进度
- 当有一个map任务完成之后,就启动container然后再启动reduce任务,但是这里的reducetask只做数据拉取的工作,不会进行计算
- Reduce任务到对应的共享资源路径下载相应的资源(运行的jar包),当所有的map任务运行完成后,启动reduce任务进行计算
- 当maptask或者是reducetask任务运行完成之后,就会向MRAPPmaster申请注销自己,释放资源
- 当application任务完成之后,MRAPPmaster会向resourcemanager申请注销自己,释放资源
Spark On YARN
基于YARN的两种提交模式的深度剖析:
yarn-cluster
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
/path/to/examples.jar \
yarn-client
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \ # can be client for cluster mode
/path/to/examples.jar \

yarn-cluster
基于YARN集群的cluster模式:
- 使用spark-submit提交程序以后,首先发送请求到ResourceManager,请求启动ApplicationMaster
- ResourceManager接收到请求后,分配一个container到其中一个NodeManager,然后在这个NodeManager上启动ApplicationMaster,这个ApplicationMaster就相当于Driver
- ApplicationMaster启动后,会找到ResourceManager,请求container,用来启动executer
- ResourceManager给ApplicationMaster分配一批container,用于启动executuer
- AppllicationMaster连接这批container所在的NodeManager,让这些NodeManager使用container启动executer
- executer启动后,向ApplicationMaster反向注册
- ApplicationMaster监控executer运行任务的情况,失败重启
- executer完成任务后向ApplicationMaster申请注销自己,释放资源
- ApplicationMaster向ResourceManager汇报任务完成,并注销关闭自己,释放资源
在上面的一系列执行过程中,其实ResourceManager就相当于Standalone运行模式下的Master,ApplicationMaster相当于Driver,NodeManager相当于worker。
yarn-client
基于YARN的yarn-client模式:
- 步骤是和cluster模式一样的。不同点是在这个模式下的ApplicationMaster它的功能很有限,只会申请和启动资源。而真正的Driver是启动在本地提交spark-submit的客户端上的。
对于yarn-cluster和yarn-client两种提交模式,两者的优缺点各是什么?
- yarn-client用于测试,因为driver运行在本地客户端,负责调度application,会与yarn集群产生超大量的网络通信,从而导致网卡流量激增。好处在于,直接执行时,本地可以看到所有的log,方便调试。
- yarn-cluster,用于生产环境,因为driver运行在nodemanager,没有网卡流量激增的问题,缺点在于,调试不方便,本地用spark-submit提交后,看不到log。只能通过yarn application - logs application_id 这种命令来查看,很是麻烦。















 8466
8466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









