







这几天在看
Leetcode的时候逐步开始留意SQL题目,不做不知道,一做才感觉自己的SQL太弱了,因此将一道经典题目:求第N高的薪水的解法进行汇总(MySQL)。相关解法的原文链接已标注在文末~题目的链接为:第N高的薪水
一、题干
第N高的薪水:编写一个 SQL 查询,获取 Employee 表中第 n 高的薪水(Salary)。
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
例如上述 Employee 表,n = 2 时,应返回第二高的薪水 200。如果不存在第 n 高的薪水,那么查询应返回 null。
+------------------------+
| getNthHighestSalary(2) |
+------------------------+
| 200 |
+------------------------+
初始化代码片段。
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
);
END
二、前置知识碎片
简单总结,有时间再详细补充知识点~
1. limit用法
limit子句用于限制查询结果返回的数量。
用法:[select * from tableName limit i,n]
参数:
tableName: 为数据表;i: 为查询结果的索引值(默认从0开始);n: 为查询结果返回的数量
2. order by
order by为排序,ASC(默认升序)和DESC`(降序)
适用于单列升序、单列降序和多列排序,示例:
SELECT * FROM Websites
ORDER BY alexa DESC;
3. declare 和 set
[declare 字段名 字段类型]
[set 赋值表达式]
4. if和ifnull
f(true,a,b),if(false,a,b) 这个就是第一个如果是true,就等于a,false就等于b,有点像三元表达式;
ifnull(a, b) ifnull里有两个值,如果a不是null,则返回a, 如果a=null,则返回b。
5. 窗口函数
实际上,在mysql8.0中有相关的内置函数,而且考虑了各种排名问题:
row_number(): 同薪不同名,相当于行号,例如3000、2000、2000、1000排名后为1、2、3、4rank(): 同薪同名,有跳级,例如3000、2000、2000、1000排名后为1、2、2、4dense_rank(): 同薪同名,无跳级,例如3000、2000、2000、1000排名后为1、2、2、3ntile(): 分桶排名,即首先按桶的个数分出第一二三桶,然后各桶内从1排名,实际不是很常用
显然,本题是要用第三个函数。另外这三个函数必须要要与其搭档over()配套使用,over()中的参数常见的有两个,分别是
partition by,按某字段切分order by,与常规order by用法一致,也区分ASC(默认升序)和DESC(降序)
三、解法
1. 解法一:set赋值+distinct去重+limit取值的单表查询
题目要求:
显示没有固定的N高薪水,N的确定由自定义函数传入。
解题思路:
- 使用
limit limit start,count。其中start的显示值是从start+1开始的。但limit后面输入不能是计算式,比如:N-1- 第N高的N,是通过自定义函数
getNthHighestSalary的(N INT)中N传入。start必须是从N-1开始,才能显示符合题目要求的结果。比如第N=2高,如果直接用N值到limit,limit 2,1,意为从第3行开始,显示一行。所以要用N-1=1,才能表示从第二行开始。 - 这时,应通过一个替代参数实现。
MySQL自定函数中的参数是静态参数,即要先定义后使用。先用declare定义类型,后通过set进行赋值。
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
declare m INT;
set m=N-1;
RETURN (
# Write your MySQL query statement below.
select ifnull(
(
select distinct Salary
from Employee
order by Salary
desc limit m,1
),
null
)
);
END
注意:此处的set,可以直接set N=N-1,而不用declare m,但声明m会更加明晰一些~
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
set N=N-1;
RETURN (
# Write your MySQL query statement below.
select ifnull(
(
select distinct Salary
from Employee
order by Salary
desc limit N,1
),
null
)
);
END
2. 解法二:set赋值+group by去重 + limit取值
主体思路同方法一,group by同样可以起到分组去重的效果,用以代替distinct
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
set N=N-1;
RETURN (
# Write your MySQL query statement below.
select ifnull(
(
select Salary
from Employee
group by Salary
order by Salary
desc limit N,1
),
null
)
);
END
解法一和解法二最为简洁直观,但仅适用于查询全局排名问题,如果要求各分组的每个第N名,则该方法不适用;而且也不能处理存在重复值的情况。
3. 解法三:连续排名解法
- 计算出每一个薪水的连续排名
- 找到排名等于N的薪水,并输出
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
select min(a.salary)
from employee a
where (
select count(*)+1
from (select distinct salary from employee) b
where b.salary>a.salary
)=N
);
END
4. 解法四:使用子查询&笛卡尔积
- 排名第N的薪水意味着该表中存在
N-1个比其更高的薪水 - 注意这里的
N-1个更高的薪水是指去重后的N-1个,实际对应人数可能不止N-1个 - 最后返回的薪水也应该去重,因为可能不止一个薪水排名第N
- 由于对于每个薪水的
where条件都要执行一遍子查询,注定其效率低下
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
SELECT DISTINCT e.salary
FROM employee e
WHERE (
SELECT count(DISTINCT salary)
FROM employee
WHERE salary>e.salary
) = N-1
);
END
当然,可以很容易将上面的代码改为笛卡尔积连接形式,其执行过程实际上一致的,甚至MySQL执行时可能会优化成相同的查询语句。
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
SELECT e1.salary
FROM employee e1, employee e2
WHERE e1.salary <= e2.salary
GROUP BY e1.salary
HAVING count(DISTINCT e2.salary) = N
);
END
5. 解法五:使用自连接
一般来说,能用子查询解决的问题也能用连接解决。具体到本题:
- 两表自连接,连接条件设定为表1的
salary小于表2的salary - 以表1的
salary分组,统计表1中每个salary分组后对应表2中salary唯一值个数,即去重 - 限定步骤2中
having计数个数为N-1,即实现了该分组中表1salary排名为第N个 - 考虑
N=1的特殊情形(特殊是因为N-1=0,计数要求为0),此时不存在满足条件的记录数,但仍需返回结果,所以连接用left join - 如果仅查询薪水这一项值,那么不用
left join当然也是可以的,只需把连接条件放宽至小于等于、同时查询个数设置为N即可。因为连接条件含等号,所以一定不为空,用join即可。 - 注:个人认为无需考虑
N<=0的情形,毕竟无实际意义。
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
SELECT e1.salary
FROM employee e1 JOIN employee e2
ON e1.salary <= e2.salary
GROUP BY e1.salary
HAVING count(DISTINCT e2.salary) = N
);
END
但需要注意的是在题目测试时候,这种解法户报错,因为是自连接两个数比较。如果求第一个数,其中有一个必为空,会出错 ~
6. 解法六:使用窗口函数
窗口函数用法具体见2.5
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
SELECT DISTINCT salary
FROM (
SELECT salary, dense_rank() over(ORDER BY salary DESC) AS rnk
FROM employee
) tmp
WHERE rnk = N
);
END
四、总结
至此,可以总结MySQL查询的一般性思路是:
- 能用单表优先用单表,即便是需要用
group by、order by、limit等,效率一般也比多表高 - 不能用单表时优先用连接,连接是
SQL中非常强大的用法,小表驱动大表+建立合适索引+合理运用连接条件,基本上连接可以解决绝大部分问题。但join级数不宜过多,毕竟是一个接近指数级增长的关联效果 - 能不用子查询、笛卡尔积尽量不用,虽然很多情况下
MySQL优化器会将其优化成连接方式的执行过程,但效率仍然难以保证 - 如果
MySQL版本允许,某些带聚合功能的查询需求应用窗口函数是一个最优选择。除了经典的获取3种排名信息,还有聚合函数、向前向后取值、百分位等,具体可参考官方指南。以下是官方给出的几个窗口函数的介绍:
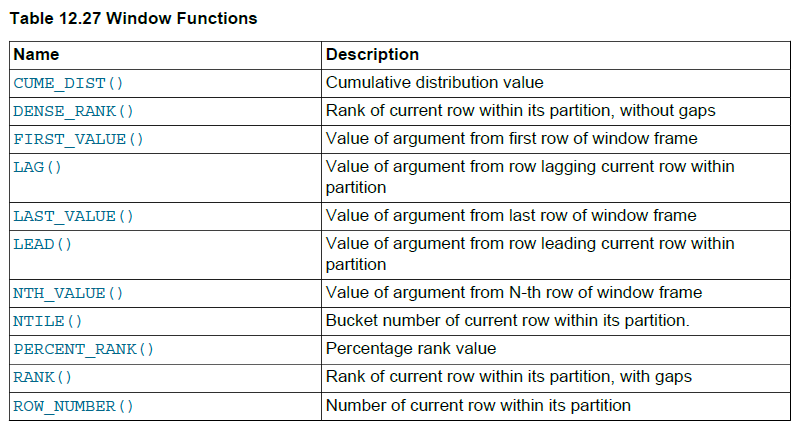
五、参考链接
- https://leetcode-cn.com/problems/nth-highest-salary/solution/177-di-ngao-xin-shui-by-cloudwaterbears/
- https://leetcode-cn.com/problems/nth-highest-salary/solution/mysql-zi-ding-yi-bian-liang-by-luanz/
- https://leetcode-cn.com/problems/nth-highest-salary/solution/dan-biao-cha-xun-zi-cha-xun-by-zhouzihon-v98v/
- https://leetcode-cn.com/problems/nth-highest-salary/solution/lian-xu-pai-ming-densejie-fa-by-xi-feng-f96ns/















 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











