






题目描述

这个题目要用到一种新的数据结构——堆。首先了解一下大根堆,小根堆的概念以及其使用。
堆概念介绍
堆是用数组表示的二叉树,分为大根堆和小根堆,大根堆堆顶为最大的结点,小根堆是对堆顶为最小结点。
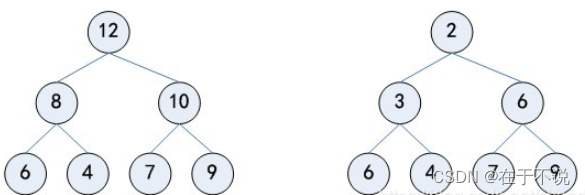
堆的作用是能迅速的找到数组中的最大结点或者最小节点。但是要注意的是,python中的heappush自动建立的是小根堆,没有针对大根堆写的方法。因此,在需要构建大根堆的时候,我们通常会将节点的值取负号,转换为求最小节点的问题,即可以构建小根堆来解决大根堆的构建问题。
import heapq
helper = [] # 创建一个优先级队列
heapq.heappush(helper, item) # 将item添加到堆中,并且自动构建小根堆
val = heapq.heappop(helper) # 将堆顶元素弹出
解题方法
本题可以分为三种方法,第一种分治法,第二种优先级队列,第三种重写富比较方法
方法一:分治法
class Solution(object):
def mergeKLists(self, lists):
"""
:type lists: List[ListNode]
:rtype: ListNode
"""
'''方法一:分而治之'''
if not lists: return
n = len(lists)
return self.merge(lists, 0, n-1)
def merge(self, lists, left, right):
if left == right: # 这里就是说只有一个链表,所以直接返回
return lists[left]
mid = left + (right - left) // 2
l1 = self.merge(lists, left, mid)
l2 = self.merge(lists, mid + 1, right)
return self.mergeTwoLists(l1, l2)
def mergeTwoLists(self, l1, l2):
if not l1: return l2
if not l2: return l1
if l1.val < l2.val: # 这是比不同链表第一个结点,然后选择最小的那个,不断的使用递归,使得两两合并
l1.next = self.mergeTwoLists(l1.next, l2)
return l1
else:
l2.next = self.mergeTwoLists(l1, l2.next)
return l2
觉得这个方法太牛了,一直从列表中弹出两个链表进行合并升序然后又加入队列中,直到队列中只剩下一个链表。主要是通过两两链表合并的手段,来完成所有链表结点的一个排序问题。完整代码如下:
'''给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。'''
import heapq
# Definition for singly-linked list.
class ListNode(object):
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class LinkList(object):
def __init__(self):
self.head = None
def linklist(self, data):
head = ListNode(data[0])
p = head
for i in data[1:]:
node = ListNode(i)
p.next = node
p = p.next
return head
class Solution(object):
def mergeKLists(self, lists):
"""
:type lists: List[ListNode]
:rtype: ListNode
"""
'''方法一:分治法'''
if not lists: return
n = len(lists)
return self.merge(lists, 0, n-1)
def merge(self, lists, left, right):
if left == right: # 这里就是说只有一个链表,所以直接返回
return lists[left]
mid = left + (right - left) // 2
l1 = self.merge(lists, left, mid)
l2 = self.merge(lists, mid + 1, right)
return self.mergeTwoLists(l1, l2)
def mergeTwoLists(self, l1, l2):
if not l1: return l2
if not l2: return l1
if l1.val < l2.val: # 这是比不同链表第一个结点,然后选择最小的那个,不断的使用递归,使得两两合并
l1.next = self.mergeTwoLists(l1.next, l2)
return l1
else:
l2.next = self.mergeTwoLists(l1, l2.next)
return l2
if __name__ == '__main__':
lists = [[1, 4, 5], [1, 3, 4], [2, 6]]
aa = LinkList()
bb = Solution()
lists1 = []
i = 0
while(i<lists.__len__()):
list = aa.linklist(lists[i])
lists1.append(list)
i = i+1
result = bb.mergeKLists(lists1)
print(result)
方法二:利用优先级队列
这个方法主要是利用小根堆的构建。因为三个链表都是有序链表,因此我们先将每个链表的第一个结点值取出来并将链表的头节点往后移,对取出的三个结点构建小根堆。然后弹出堆顶最小元素,利用哑结点来链接弹出的最小节点。接着将弹出堆的链表的后续结点重新加入堆中,代码如下:
class Solution(object):
def mergeKLists(self, lists):
"""
:type lists: List[ListNode]
:rtype: ListNode
"""
'''方法二:优先级队列'''
if not lists: return
dummy = ListNode(-1)
p = dummy
helper = []
n = len(lists)
for i in range(n): # 把三个链表中的第一个结点拿出来
if lists[i]: # 一定要注意,要先判断链表是否有值再push到堆中,不然会出现错误
heapq.heappush(helper,(lists[i].val, i))
lists[i] = lists[i].next # 一定要记得将链表的指针后移
while helper:
value, index = heapq.heappop(helper)
p.next = ListNode(value)
p = p.next
if lists[index]:
heapq.heappush(helper,(lists[index].val, index))
lists[index] = lists[index].next
return dummy.next
注意,这里重点是对链表头节点的val值进行小根堆的构建,因此在后续的链接的时候,需要重新构建一个结点来链接。方法三的重写富比较方法的方法则无需重新构建结点。下面是方法二的完整代码实现:
'''给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。'''
import heapq
# Definition for singly-linked list.
class ListNode(object):
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class LinkList(object):
def __init__(self):
self.head = None
def linklist(self, data):
head = ListNode(data[0])
p = head
for i in data[1:]:
node = ListNode(i)
p.next = node
p = p.next
return head
class Solution(object):
def mergeKLists(self, lists):
"""
:type lists: List[ListNode]
:rtype: ListNode
"""
'''方法二:优先级队列'''
if not lists: return
dummy = ListNode(-1)
p = dummy
helper = []
n = len(lists)
for i in range(n): # 把三个链表中的第一个结点拿出来
if lists[i]:
heapq.heappush(helper,(lists[i].val, i))
lists[i] = lists[i].next
while helper:
value, index = heapq.heappop(helper)
p.next = ListNode(value)
p = p.next
if lists[index]:
heapq.heappush(helper,(lists[index].val, index))
lists[index] = lists[index].next
return dummy.next
if __name__ == '__main__':
lists = [[1, 4, 5], [1, 3, 4], [2, 6]]
aa = LinkList()
bb = Solution()
lists1 = []
i = 0
while(i<lists.__len__()):
list = aa.linklist(lists[i])
lists1.append(list)
i = i+1
result = bb.mergeKLists(lists1)
print(result)
方法三:重写__lt__方法
__lt__方法类内置的一个比较方法,Solution中的内置方法如下:
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'mergeKLists']
因为该方法是将整个结点添加到堆中,因此我们要重新写一个比较器,告诉程序该如何比较节点中的值,代码如下:
class Solution(object):
# def __init__(self):
'''重写lt富比较方法'''
setattr(ListNode, '__lt__', lambda self, other: self.val < other.val)
def mergeKLists(self, lists):
"""
:type lists: List[ListNode]
:rtype: ListNode
"""
'''方法三:猴子补丁'''
if not lists:
return lists
dummy = ListNode(-1)
p = dummy
helper = []
# 设置优先级队列
pq = []
for head in lists: # 这里其实是将几条链表的第一个结点都放进来,然后比较
if head: # 要判断是否为空,否则会报出head没有val属性的错误的报告
heapq.heappush(pq, (head.val, head)) # 构建小根堆
while pq:
# 获取最小结点,连接到结果链表中
node = heapq.heappop(pq)[1] # 这是取出最小节点的地址,也就是(head.val, head)中的head
p.next = node
if node.next:
heapq.heappush(pq, (node.next.val, node.next))
# p指针不断的前进
p = p.next
return dummy.next
算法的基本思路跟方法二差不多,只不过这里直接push的是一个结点,重写了一个比较器来表示节点该如何比较大小。完整代码如下:
'''给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。'''
import heapq
# Definition for singly-linked list.
class ListNode(object):
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class LinkList(object):
def __init__(self):
self.head = None
def linklist(self, data):
head = ListNode(data[0])
p = head
for i in data[1:]:
node = ListNode(i)
p.next = node
p = p.next
return head
class Solution(object):
# def __init__(self):
'''重写lt富比较方法'''
setattr(ListNode, '__lt__', lambda self, other: self.val < other.val)
def mergeKLists(self, lists):
"""
:type lists: List[ListNode]
:rtype: ListNode
"""
'''方法一:猴子补丁'''
if not lists:
return lists
dummy = ListNode(-1)
p = dummy
helper = []
# 设置优先级队列
pq = []
for head in lists: # 这里其实是将几条链表的第一个结点都放进来,然后比较
if head: # 要判断是否为空,否则会报出head没有val属性的错误的报告
heapq.heappush(pq, (head.val, head)) # 构建小根堆
while pq:
# 获取最小结点,连接到结果链表中
node = heapq.heappop(pq)[1] # 这是取出最小节点的地址,也就是(head.val, head)中的head
p.next = node
if node.next:
heapq.heappush(pq, (node.next.val, node.next))
# p指针不断的前进
p = p.next
return dummy.next
if __name__ == '__main__':
lists = [[1, 4, 5], [1, 3, 4], [2, 6]]
aa = LinkList()
bb = Solution()
lists1 = []
i = 0
while(i<lists.__len__()):
list = aa.linklist(lists[i])
lists1.append(list)
i = i+1
result = bb.mergeKLists(lists1)
print(result)














 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









