







 博客介绍了ddddocr,一个用于验证码识别的Python库,特别适用于中、英文、数字混合的单行文字识别。提供了环境要求、快速安装、代码示例和识别效果展示。虽然在多行数据识别上表现一般,但对单行数据的识别效果良好。
博客介绍了ddddocr,一个用于验证码识别的Python库,特别适用于中、英文、数字混合的单行文字识别。提供了环境要求、快速安装、代码示例和识别效果展示。虽然在多行数据识别上表现一般,但对单行数据的识别效果良好。
最近有位大神分享了一个验证码库,试用一下发现非常实用,特做个分享记录。
Github地址:GitHub - sml2h3/ddddocr: 带带弟弟 通用验证码识别OCR pypi版
Pip地址:ddddocr · PyPI
主要应用场景:
验证码识别,中、英文、数字混合的单行文字识别等
1.1 环境要求
python >= 3.6
Windows/Linux..
1.2 快速安装
使用pip命令安装:pip install ddddocr
1.3 识别代码
import ddddocr
ocr = ddddocr.DdddOcr()
with open('test.png', 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
print(res)参数说明
DdddOcr 接受两个参数
| 参数名 | 默认值 | 说明 |
| use_gpu | False | Bool 是否使用gpu进行推理,如果该值为False则device_id不生效 |
| device_id | 0 | int cuda设备号,目前仅支持单张显卡 |
classification
| 参数名 | 默认值 | 说明 |
| img | 0 | bytes 图片的bytes格式 |
1.4 效果展示
代码:
import ddddocr
lists=[]
ocr = ddddocr.DdddOcr()
for i in range(1,9):
with open('D:\\test\\%s.png'%i, 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
lists.append(res)
print(lists)截图:
识别效果:
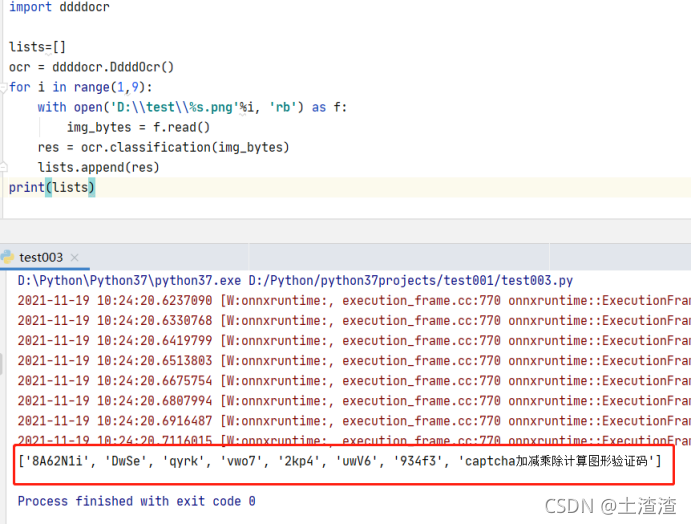
说明:单行数据效果确实不错,多行数据识别效果不尽人意

















 3022
3022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









