







前面文章我们介绍了模型的微调实践和模型本地部署,巩固了模型微调的基础知识和基本原理,为微调实战奠定了基础。
相比之前微调实践中的笼统介绍,今天就重点拆开介绍chatGLM-6b微调和Baichuan-13B微调的详细步骤和口令。把经验总结整理成手册也是小马的乐趣之一。
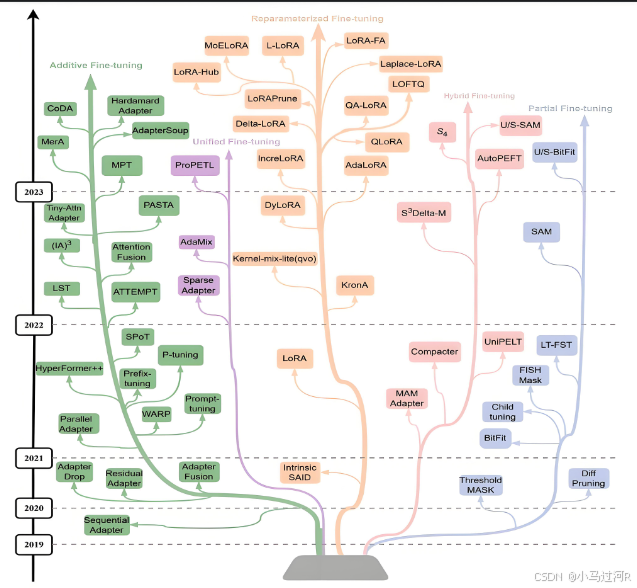
一、chatGLM-6b P-Tuning v2微调
说起chatGLM-6b的微调(这是早期的,现在都GLM4了),直接可以参考官网的教程。具体使用方法详见 ptuning/README.md,这个教程的步骤和命令介绍得相当详细了,照着敲就可以了。(早期小马主要实践是基于 P-tuning v2 的高效参数微调)
教程步骤总结为:
- 先准备好基座模型环境和代码并安装微调需要的依赖;
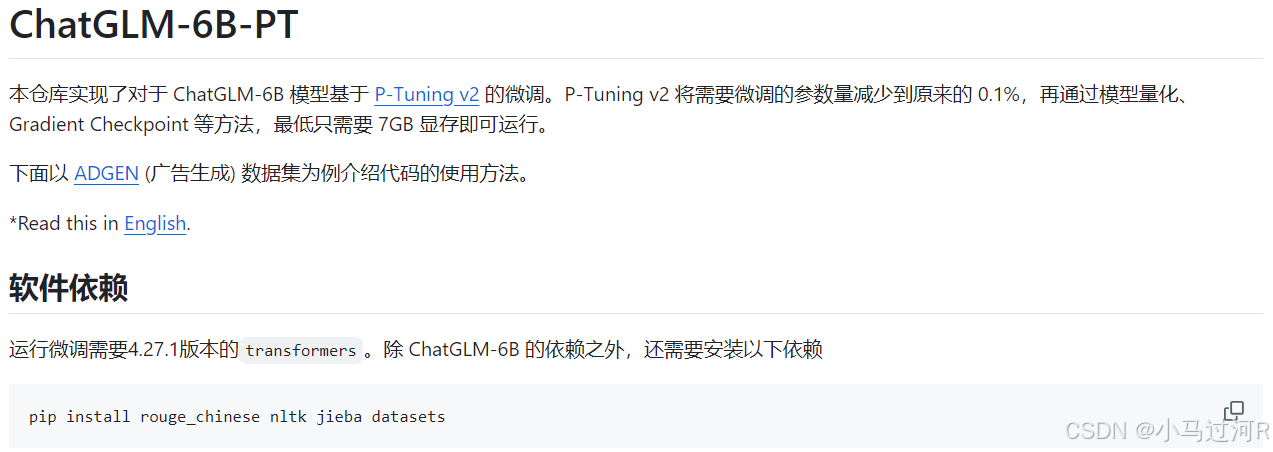
- 按照模型指定的规范整理数据集;
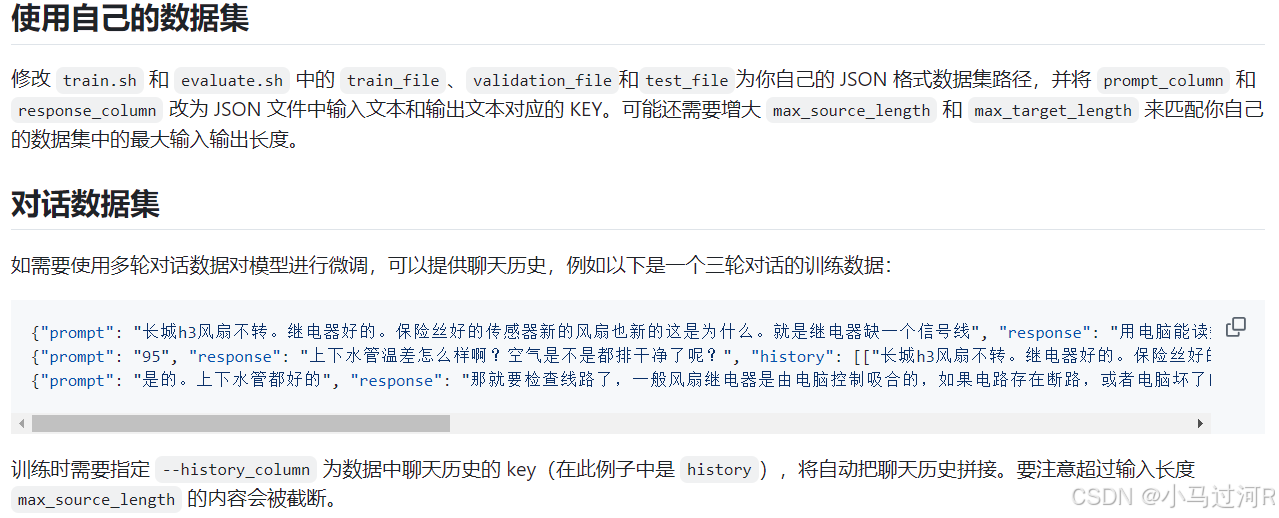
- 将数据集自己分好训练集、验证集或测试集,并对数据使用脚本进行格式规范转换(一般是.json文件);
- 根据实际情况,可以选择全参数微调Finetune或者高效参数微调P-Tuning v2/LoRA;小马实践用的是P-Tuning v2微调,所以这块的详细命令教程还需参见这里,微调参数配置文件是run_script/run_rte_roberta.sh,具体各个参数代表的含义可以回头参阅之前的文章微调实践。
- 根据理论分析配置好微调参数(参考如下);
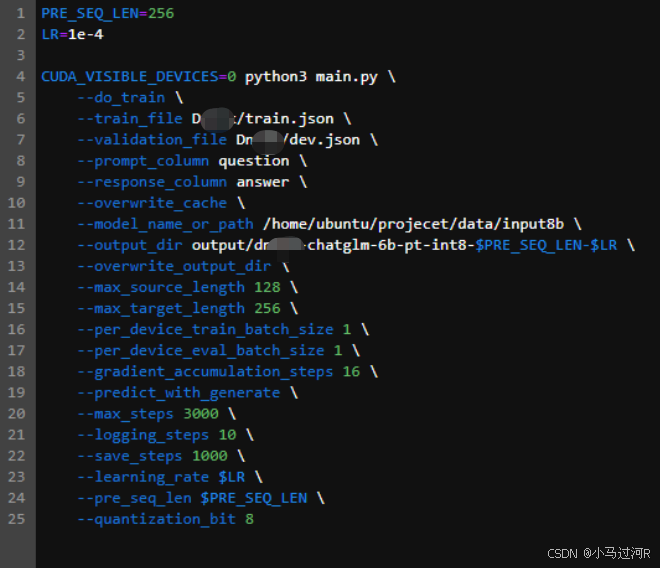
- 运行微调命令等待微调完成,微调结束将会输出一个微调训练结果情况如下图。我们可以看到训练中每次epoch的loss值变化和最终的loss值等;
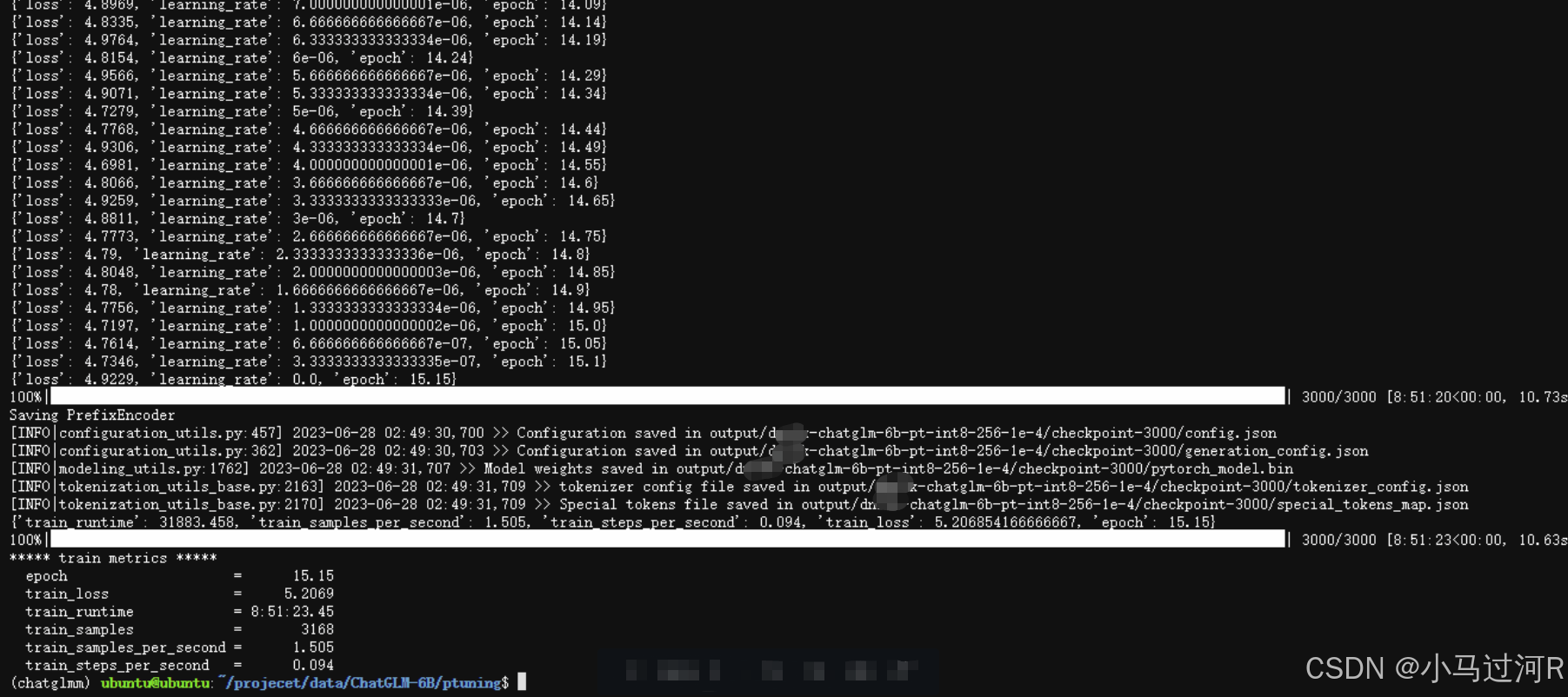
- 使用微调模型的部署启动命令即可启动微调后的模型服务;

- 评估模型效果性能表现,分析准备下一轮的数据和微调参数。此时我们可以使用代码自带的跑分脚本对微调完的checkpoint模型进行rouge、bleu等跑分评估(注意,跑分动作不需要在启动模型服务之后也可以进行)。 执行评估脚本的配置文件如下:
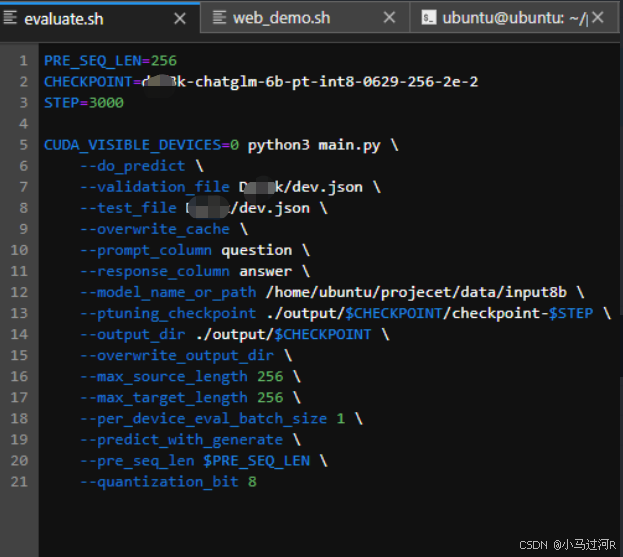
配置文件修改完后需运行脚本,最终我们将得到的分数大概如下图。
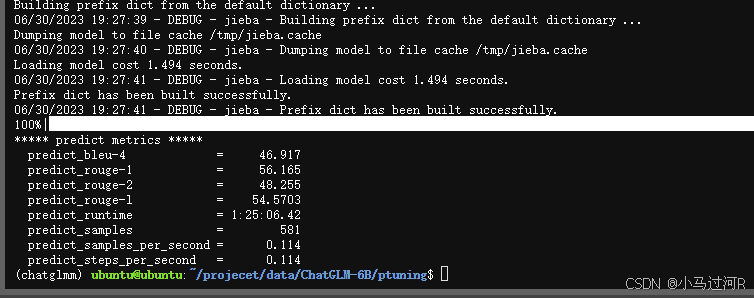
经验总结区:
- 这套PT微调代码出得比较早,似乎没有直接的可视化loss曲线输出,需要自己对loss数据进行处理再自己输出曲线。
- 微调数据集一般千条可见效果。
- 千条数据一般8小时不等,数据越多一般时间会越长。
- 不同微调方式,部署微调后的模型方式是有所不同的。在 P-tuning v2 训练时模型只保存 PrefixEncoder 部分的参数,所以在推理时需要同时加载原 ChatGLM-6B 模型以及 PrefixEncoder 的权重。如果需要加载的是旧 Checkpoint(包含 ChatGLM-6B 以及 PrefixEncoder 参数),或者进行的是全参数微调,则直接加载整个 Checkpoint;参考百川2的微调,Qlora微调需要将微调完的Checkpoint与基础模型进行命令模型融合之后才能部署。
- 10G显存的GPU,当max_source_length 从256设置 512后机器的显存就会溢出而后停止本次训练。
- 调低了学习率1e-4。或因学习率过低,无法rouge等评估跑分(出现报错)。体验效果也不行,回答的基本都是错误的。
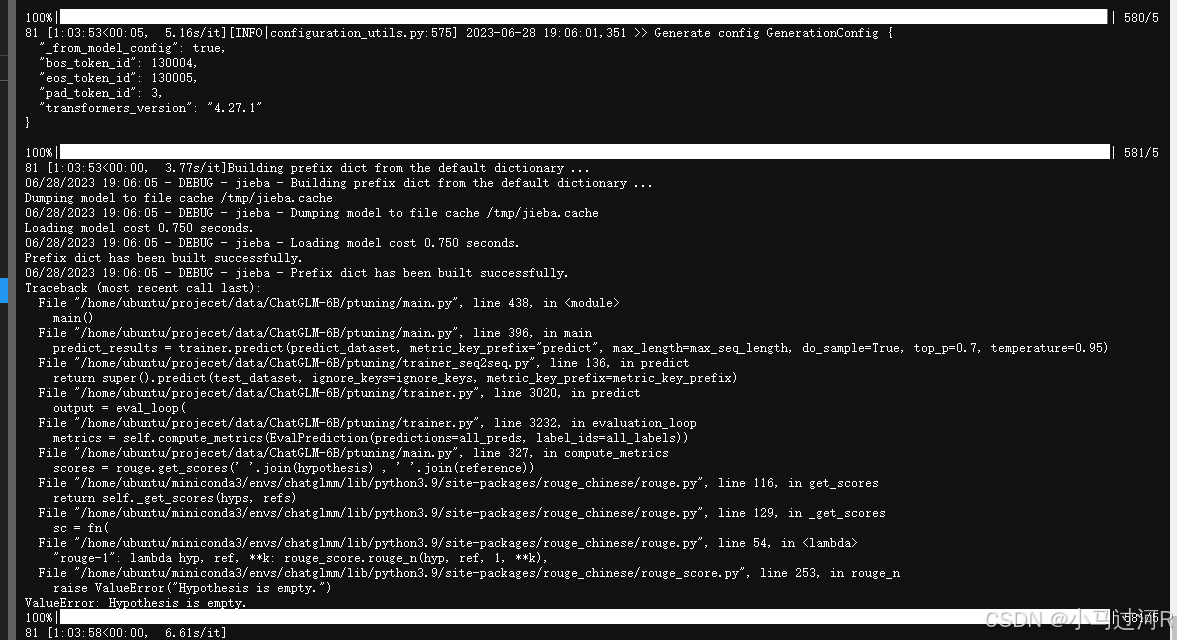
- 小马个人认为,相比Baichuan-13B的Qlora微调,chatGLM-6b P-Tuning v2微调更容易出效果,俗称“比较好调”。
二、Baichuan2 QLoRA微调
其实各个大模型的微调在原理上相同自然在方法上也大同小异。百川的微调其实基本和上面介绍的chatGLM-6b微调差不多。
相对于Baichuan-13B我们是对Baichuan2-13b-Chat进行微调。(注意不是Baichuan2-13b base,因为base基座本身并没不具有很好的对话能力)
我们按照github官方教程进行微调尝试,结果出现各种不可预想的报错,可能是因为环境问题。于是我们寻找到一个框架Firefly,借助框架来辅助进行微调工作。官方的教程似乎对步骤描述得并不是足够清晰,于是我们可以参考这个Baichuan-13B教程来进行微调。
我们可以看到,主要步骤基本和上文chatGLM的差不多。
使用Firefly对Baichuan进行训练和推理,主要步骤如下:
- 安装环境。
- 准备训练集。
- 配置训练参数。
- 启动训练。
- 合并权重。
- 模型推理。
值得注意的是倒是有几点与上面chatGLM的区别需要拿出来讨论一下。
- 这套框架倒是可以输出loss曲线的面板,集成了tensorboard,但是遗憾的是目前只有训练集loss曲线没有验证集的loss曲线,对判断过拟合等仍然不是很方便。(但是也是有法子判断的,可以回头参看文章模型微调(Fine-tuning)实践,里面有详细的介绍,这里不再赘述。)
- 与上面不同的是,该项目微调后的checkpoint文件需要经过与基座模型文件合并权重后成为一个新的模型文件才能部署推理。不能像chatGLM pt微调直接.join checkpoint文件到基座即可部署。
- 这套框架并没有跑分脚本。于是我们经过分析后决定还是直接参考chatGLM的rouge、bleu的跑分方法,自己实现了一个脚本,对训练集和验证集进行跑分。原理即只要具备了问题和答案的数据集均可以通过这个算法脚本调用微调后的模型推理来跑出来分数,本质上就是在算模型答案和预期答案的召回率(关于rouge、bleu的理解也可以参看文章模型评估)。
我们来看一下Flyfire-qlora微调详细的步骤:
-
进入conda环境(假设我们的训练conda环境为BaiCTrain)。
conda activate BaiCTrain -
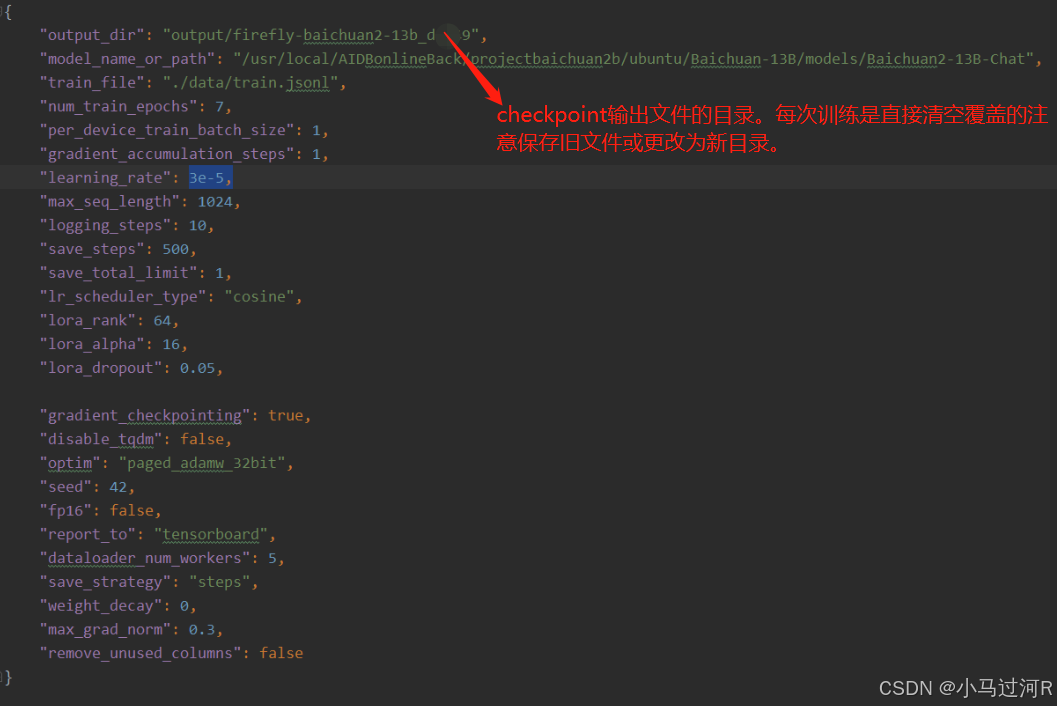
对微调配置文件/home/Firefly/train_args/qlora/baichuan2-13b-sft-qlora.json进行修改,参考如下图。至于各个微调参数的含义以及如何配置还是推荐回头看下文章微调实践。
-
启动微调训练,静待微调完成。当然期间还可以随时查看当前loss曲线的面板(前提是需要启动一下面板服务)。
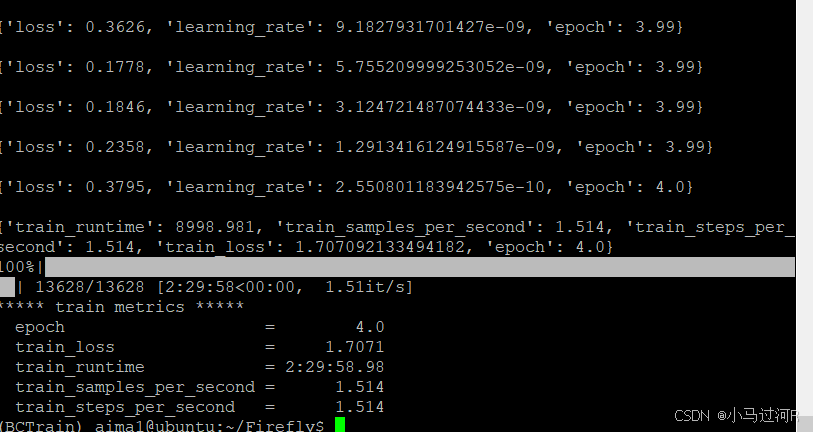
执行 “tmux a -t train”, 进入tmux后台。如果需退出tmux后台,使用(ctrl+b -> d); 进入项目代码/home/Firefly目录下; 然后执行命令: python3.10 train_qlora.py --train_args_file /home/Firefly/train_args/qlora/baichuan2-13b-sft-qlora.json微调结果输出如下。
-
合并模型。
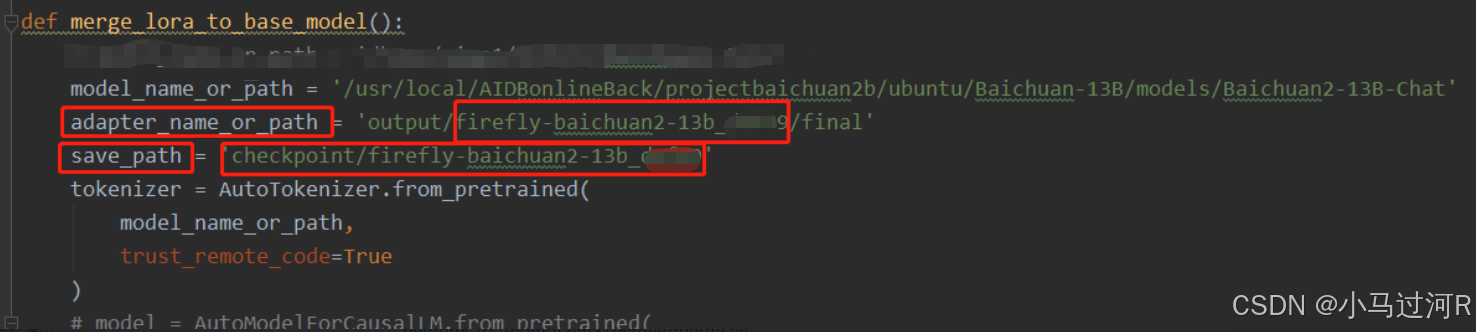
同样的我们需要保证进入在conda环境BaiCTrain,如果不是则需要先执行第一步的步骤。进入项目代码/home/Firefly目录下,修改该目录下的 merge.py 文件中adapter_name_or_path变量下的训练完的模型目录对应为我们之前的checkpoint输出目录以及 save_path变量值为 模型合并后保存的目录(自定义)。参考如下。
之后我们运行该脚本文件即可完成合并。如果未作量化,此时合并完的文件为全量文件。python3.10 /home/Firefly/merge.py -
部署模型推理。
同样的我们需要保证进入在conda环境BaiCTrain,如果不是则需要先执行第一步的步骤。进入项目代码/home/Firefly目录下,我们需要修改运行api的文件api.py。修改init_model方法里的 quant8_saved_dir 变量改为对应我们上面模型合并保存的目录。参考如下。
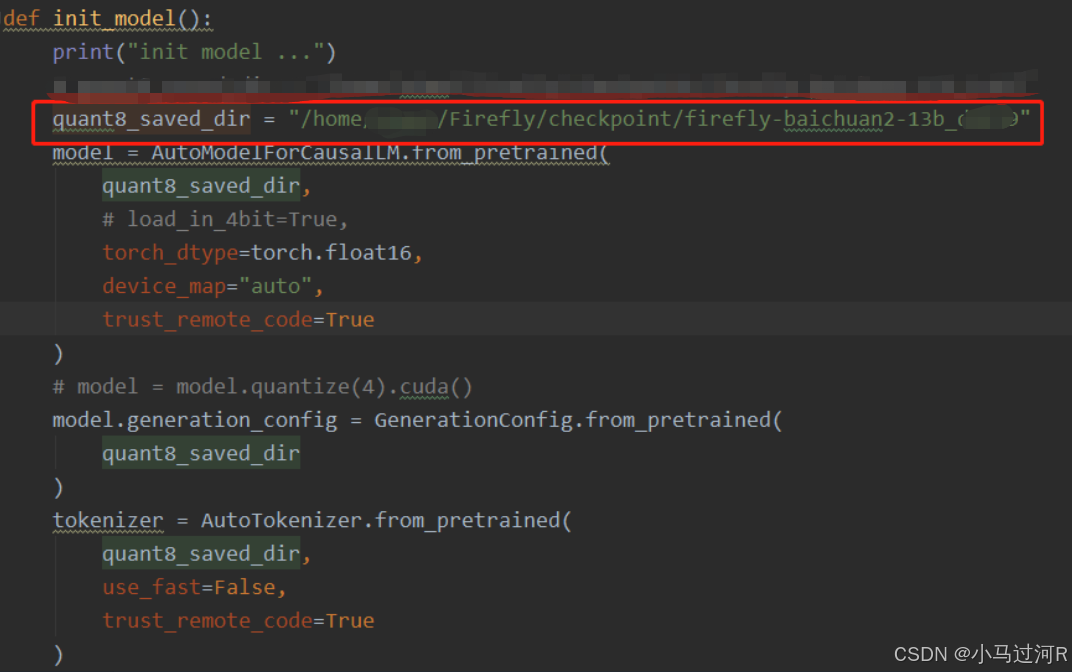
最后运行脚本api.py。python3.10 /home/Firefly/api.py -
可以访问api接口了。
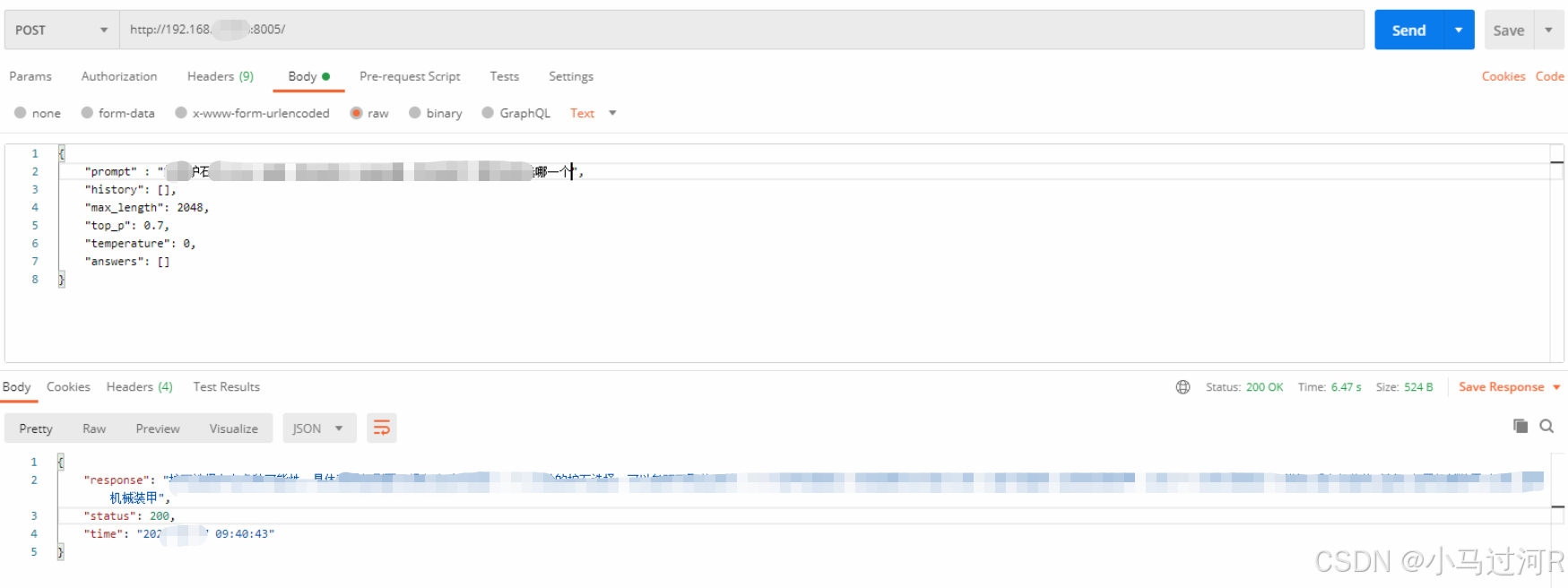
-
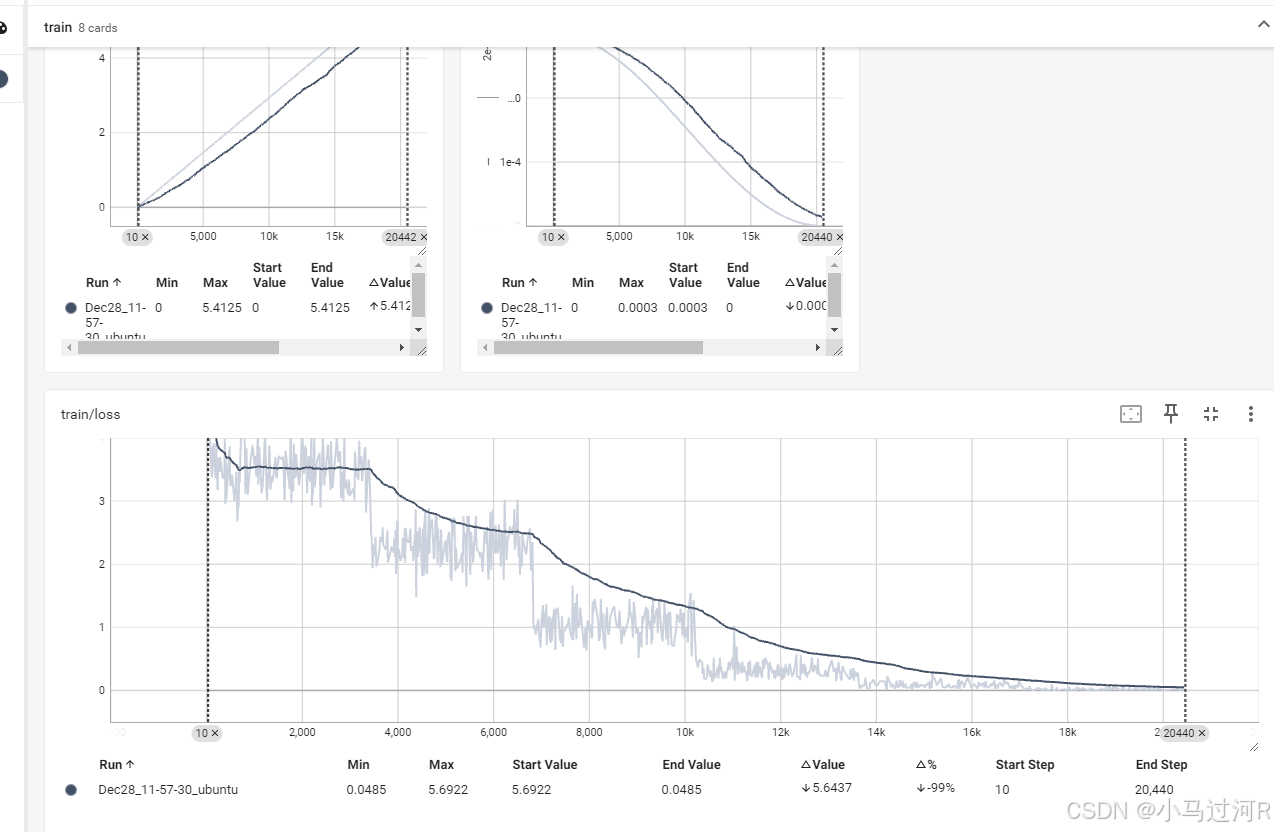
如何查看loss面板。
tensorboard使用如下命令执行, --logdir值替换为微调模型的输出保存目录,即output_dir的值。需要注意的是该命令需要等微调训练执行一小段时间后再运行才能看到曲线数据,因为要等微调数据先生成。tensorboard --logdir=/home/Firefly/output/firefly-baichuan2-13b_xx/runs启动之后使用,http://ip:8081即可访问曲线的web页面,参考如下。至于曲线如何分析同样可以回头参考文章微调实践。更多的分析经验看看后面有机会再作个更详细的专题介绍。
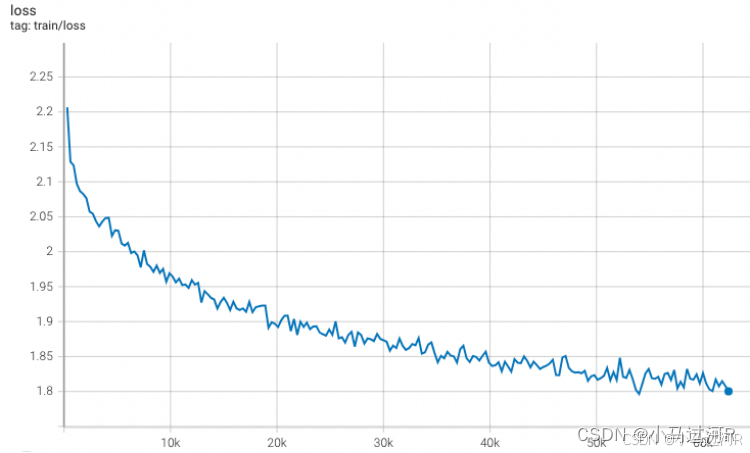
官方提供的理想微调曲线参考:
三、总结
大模型的微调操作步骤都大相径庭,本文对chatGLM-6b P-Tuning v2和Baichuan2 QLoRA的详细微调步骤进行介绍,希望能抛砖引玉,供大家学习借鉴。感谢品阅。
更多AI落地资料还可以参看这里AI应用落地。还有疑问可以来公众号【贝可林】私信我,我骑共享单车到你家探讨。


















 8119
8119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











