






1. pandas作用和定义
Pandas 是 Python 的一个开源数据分析库,它提供了高性能、易于使用的数据结构和数据分析工具。Pandas 专为处理表格和混合数据集设计,而 Python 原生的数据结构更适合处理统计数据集。
1.2 Pandas 的主要作用:
- 数据清洗:Pandas 提供了一系列功能强大的方法来清理、筛选和准备数据。
- 数据转换:例如,从一种形状转换成另一种形状、生成衍生变量等。
- 数据分析:Pandas 提供了丰富的功能来对数据集进行描述性统计、聚合和计算。
- 数据可视化:虽然 Pandas 本身主要用于数据处理,但它也可以与其他库(如 Matplotlib)结合使用,进行数据可视化。
- 时间序列分析:Pandas 提供了专门的功能来处理时间序列数据。
- 文件读写:Pandas 支持多种文件格式的读写,如 CSV、Excel、SQL、HDF5、Parquet 等。
1.2 Pandas 的两个主要数据结构:
- **Series:**一维标记数组,可以容纳任何数据类型(整数、字符串、浮点数、Python 对象等)。其基本可以被看作是一个一维的数组与一个与之相关的数据标签(称为 index)的组合。
- **DataFrame:**二维标记数据结构,具有列和行的概念,可以看作是多个 Series 结构的组合。DataFrame 是最常用的 Pandas 对象, 可以容纳多种数据类型。
简而言之,Pandas 提供了 Python 在数据分析和处理方面的强大功能,使得 Python 成为数据科学和分析的首选语言。
2. Series
Series可以理解为一个一维的数组,只是index名称可以自己改动。类似于定长的有序字典,有Index和 value。
2.1 Series的创建
#Serise中有两套缩引:位置索引、标签索引
# 从ndarray创建一个Series
data = np.array([100,98,66,23])
s=pd.Series(data,index=['zs','ls','ww','sl'])
print(s)
# 从字典创建一个Series
data={'zs':100,'ls':98,'ww':66,'sl':23}
s2=pd.Series(data)
print(s)
# 从标量创建一个Series
s3=pd.Series(5,index=np.arange(5))
print(s3)
输出:
# 从ndarray创建一个Series
zs 100
ls 98
ww 66
sl 23
dtype: int64
# 从字典创建一个Series
zs 100
ls 98
ww 66
sl 23
dtype: int64
# 从标量创建一个Series
0 5
1 5
2 5
3 5
4 5
5 5
2.2 位置索引
#位置索引
#Series只有正向索引,没有反向索引
print(s[3]) #对于 s[3]:它使用隐式的位置索引来返回第四个元素,即 23。
print(s[:2]) #对于 s[:2]:它使用显式的位置索引来返回从开始到 ls 的所有元素,即 zs: 100 和 ls: 98。
print(s[[0,1,3]]) #基于多个位置的索引
输出:
#隐式的位置索引
23
#显式的位置索引
zs 100
ls 98
dtype: int64
#基于多个位置的索引
zs 100
ls 98
sl 23
dtype: int32
2.3 标签索引
#标签索引:索引,切片,掩码
print(s['sl']) #隐式的标签索引
print(s['zs':'ww']) #显式的标签索引 标签索引切片,与位置索引不同,包含终止位置
print(s[['zs','ls','sl']]) #基于多个标签的索引
输出:
#隐式的标签索引
23
#显式的标签索引
zs 100
ls 98
ww 66
dtype: int32
#基于多个标签的索引
zs 100
ls 98
sl 23
dtype: int32
PS:print(s[[‘zs’,‘ls’,‘sl’]])与print(s[[0,1,3]])为什么有两个中括号,每一个括号代表的意义是什么
外层的中括号是用来索引 Series 的。
内层的中括号是用来创建一个整数位置或者标签列表的。
2. dataframe
DataFrame是一个类似于表格(有行有列)的数据类型,可以理解为一个二维数组,索引有两个维度(行级索引,
列级索引),可更改。DataFrame具有以下特点:
- 列和列之间可以是不同的类型 :不同的列的数据类型可以不同
- 大小可变 (扩容)
- 标记轴(行级索引 和 列级索引)
- 针对行与列进行轴向统计(水平,垂直)
2.1 dataframe的创建
使用列表创建
import pandas as pd
#一维列表
data=[100,90,80,70]
df1=pd.DataFrame(data)
print(df1)
#二维列表
data2=[['Tom',18],
['Jerry',18],
['Jack',20],
['Rose',20]]
print(data2)
df2=pd.DataFrame(data2,index=['s01','s02','s03','s04'],
columns=['Name','Age'])
print(df2)
输出:
#一维列表
0
0 100
1 90
2 80
3 70
#二维列表
[['Tom', 18], ['Jerry', 18], ['Jack', 20], ['Rose', 20]]
Name Age
s01 Tom 18
s02 Jerry 18
s03 Jack 20
s04 Rose 20
ps:给定的 data2 是一个 Python 列表,其中的每个元素也是一个列表。这种结构可以被视为一个2维列表或者说是一个嵌套列表。每个内部列表代表一行,而每行的元素代表列的值。在这种情况下,data 可以被看作是一个4×2 的矩阵,有4行和2列。这种结构在数据处理中非常常见,尤其是在表示表格数据时。
使用字典创建
data={'Name':['Tom','Jerry','Jack','Rose'],
'Age':[18,18,20,20]}
df3=pd.DataFrame(data)
print(df3)
data={'Name':pd.Series(['Tom','Jerry','Jack','Rose'],
index=['s01','s02','s03','s04']),
'Age':pd.Series([18,18,20],
index=['s01','s02','s03'])}
df4=pd.DataFrame(data)
print(df4)
输出:
Name Age
0 Tom 18
1 Jerry 18
2 Jack 20
3 Rose 20
Name Age
s01 Tom 18.0
s02 Jerry 18.0
s03 Jack 20.0
s04 Rose NaN
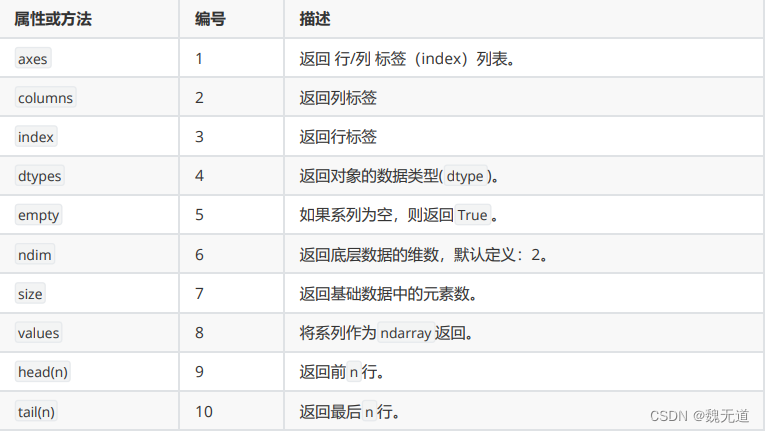
各种转态输出:
#这将输出 DataFrame 的轴标签。对于一个二维 DataFrame,
# 这将返回一个列表,其中第一个元素是行索引,第二个元素是列标签。
print(df4.axes)
#这将输出每一列的数据类型。例如,如果某一列是整数类型,它将显示为 int64。
# 如果是字符串,它将显示为 object。
print(df4.dtypes)
#这将输出 DataFrame 的列标签。
print(df4.columns)
#这将输出 DataFrame 的维度数。
# 对于所有的 DataFrame,这都是 2,因为它们都是二维的。
print(df4.ndim)
#这将输出一个元组,表示 DataFrame 的形状(行数, 列数)
print(df4.shape)
#这将输出 DataFrame 的前两行。head() 方法默认显示前五行,
# 但你可以通过传递一个整数来指定要显示的行数。
print(df4.head(2))
#这将输出 DataFrame 的最后两行。tail() 方法默认显示最后五行,
# 但你可以传递一个整数来指定要显示的行数。
print(df4.tail(2))
#这将输出 DataFrame 中的总元素数(行数 x 列数)。
# 请注意,这包括任何 NaN 值。
print(df4.size)
输出:
[Index(['s01', 's02', 's03', 's04'], dtype='object'), Index(['Name', 'Age'], dtype='object')]
Name object
Age float64
dtype: object
Index(['Name', 'Age'], dtype='object')
2
(4,2)
Name Age
s01 Tom 18.0
s02 Jerry 18.0
Name Age
s03 Jack 20.0
s04 Rose NaN
8
2.2 dataframe的列级操作
定义datafram
import pandas as pd
data={'one':pd.Series([1,2,3],index=['a','b','c']),
'two':pd.Series([1,2,3,4],index=['a','b','c','d']),
'three':pd.Series([1,3,4],index=['a','c','d'])}
df=pd.DataFrame(data)
print(df)
输出:
one two three
a 1.0 1 1.0
b 2.0 2 NaN
c 3.0 3 3.0
d NaN 4 4.0
列的访问
#列的访问
#列级没有位置索引,只有标签索引
#访问一列用索引,访问多列用掩码
print(df['one']) #输出标签为'one'的列
print(df[['one','two']]) #输出标签为'one'和标签为'two'的列
print(df[df['one'] > 1]) #会返回一个新的 DataFrame,其中只包含那些 'one' 列的值大于 3 的行。
print(df[df.columns[:-1]])#不要最后一列
输出:
#输出标签为'one'的列
a 1.0
b 2.0
c 3.0
d NaN
Name: one, dtype: float64
#输出标签为'one'和标签为'two'的列
one three
a 1.0 1.0
b 2.0 NaN
c 3.0 3.0
d NaN 4.0
#输出只包含 'one' 列的值大于 3 的行
one two three
b 2.0 2 NaN
c 3.0 3 3.0
#不要最后一列
one two
a 1.0 1
b 2.0 2
c 3.0 3
d NaN 4
PS:
1. df[df[‘one’] > 3] 请详细解释内部的df以及外部的df:
- 内部的 df[‘one’] > 3: 这会对上述 Series 对象中的每个元素进行比较,检查它是否大于 3。结果是一个布尔值 Series(即,它包含 True 或 False 的值),其中 True 表示原始值大于 3,而 False 表示原始值小于或等于 3。
- 外部的 df[…]:当你用一个布尔值 Series 作为 DataFrame 的索引时,pandas 会选择那些对应于 True 值的行。换句话说,只有那些在内部表达式 df[‘one’] > 3 中被评估为 True 的行会被选中。所以,df[df[‘one’] > 3] 会返回一个新的 DataFrame,其中只包含那些 ‘one’ 列的值大于 3 的行。
总结:这个表达式用于从 DataFrame df 中选择那些 ‘one’ 列的值大于 3 的行。
2. print(df[df.columns[:-1]]) 请详细解释内部的df以及外部的df - 内部的 df.columns[:-1]: df.columns: 这会返回一个 Index 对象,它包含 DataFrame df 的所有列名。
df.columns[:-1]: 使用 Python 的切片语法,这会返回除了最后一列外的所有列名。具体来说,[:-1] 获取所有元素,除了最后一个。这个内部的 df 只是提供上下文,告诉我们从哪个 DataFrame 获取列名。
2. 外部的 df[…] :在 pandas 中,您可以使用列名列表来选择 DataFrame 中的特定列。当您将列名列表(在这里是 df.columns[:-1] 的结果)传递给 DataFrame 时,它会返回一个新的 DataFrame,该 DataFrame 只包含指定的列。
所以,df[df.columns[:-1]] 返回的是一个新的 DataFrame,其中只包含 df 的前 n-1 列的值,其中 n 是 df 的总列数。
列的添加
#列的添加
#字典[键]=值
#df[列名]=当前列的数据
#值为列表,列表的元素个数要和index的个数相等
df['four']=[1,2,3,4]
print(df)
#值为Series,指定Series中的元素的索引为df的index
df['five']=pd.Series(['1','2','3'],
index=['a','b','c'])
print(df)
输出:
#值为列表,列表的元素个数要和index的个数相等
one two three four
a 1.0 1 1.0 1
b 2.0 2 NaN 2
c 3.0 3 3.0 3
d NaN 4 4.0 4
#值为Series,指定Series中的元素的索引为df的index
one two three four five
a 1.0 1 1.0 1 1
b 2.0 2 NaN 2 2
c 3.0 3 3.0 3 3
d NaN 4 4.0 4 NaN
列的删除:
#列的删除:
#显示已经删除了 'five' 列的 DataFrame
del (df['five'])
print(df)
a=df.pop('four')
print(df) #显示已经删除了 'four' 列的 DataFrame
print(a) #显示删除的列
#显示已经删除了 'a' 和 'b' 行的名称为a的新 DataFrame,原始df保持不变
a=df.drop(['a','b'],axis=0,inplace=False)
print(a)
df['one']=[1,2,3,4] #替换原始标签索引为'one'的值,其他保持不变
print(df)
输出:
#显示已经删除了 'five' 列的 DataFrame
one two three four
a 1.0 1 1.0 1
b 2.0 2 NaN 2
c 3.0 3 3.0 3
d NaN 4 4.0 4
#显示已经删除了 'four' 列的 DataFrame
one two three
a 1.0 1 1.0
b 2.0 2 NaN
c 3.0 3 3.0
d NaN 4 4.0
#显示已经删除了 'a' 和 'b' 行的名称为a的新 DataFrame,原始df保持不变
one two three
c 3.0 3 3.0
d NaN 4 4.0
#替换原始标签索引为'one'的值,其他保持不变
one two three
a 1 1 1.0
b 2 2 NaN
c 3 3 3.0
d 4 4 4.0
ps:del、pop以及drop的作用和定义是什么,以及上述三行代码的意思:
- del (df[‘five’])
- df.pop(‘four’)
- a=df.drop([‘a’,‘b’],axis=0,inplace=False)
1. del df[‘five’]:
这行代码使用 Python 的 del 语句从 DataFrame 中删除名为 ‘five’ 的列。
它会直接在原地修改 DataFrame,即直接更改原始 df。
之后的 print(df) 会显示已经删除了 ‘five’ 列的 DataFrame。
2. a=df.pop(‘four’):
pop 方法移除指定的列并返回这个被移除的列。
与 del 语句一样,它也是原地操作,会直接修改原始 df。
print(df) 会显示已经删除了 ‘four’ 列的 DataFrame
print(a)会显示这个被移除的列
3. a = df.drop([‘a’, ‘b’], axis=0, inplace=False):
df.drop 方法用于删除指定的行或列。
[‘a’, ‘b’] 是要删除的行标签的列表。
axis=0 指定我们要删除的是行。如果我们想删除列,可以使用 axis=1。
inplace=False 指定这个操作不是原地操作,这意味着原始 df 不会被修改。而是返回一个新的 DataFrame,其中已经删除了指定的行或列。这个新的 DataFrame 被赋值给变量 a。
print(a) 会显示已经删除了 ‘a’ 和 ‘b’ 行的新 DataFrame。
2.3 dataframe的行级操作
** 定义datafram**
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
data={'one':pd.Series([1,2,3],index=['a','b','c']),
'two':pd.Series([1,2,3,4],index=['a','b','c','d']),
'three':pd.Series([1,3,4],index=['a','c','d'])}
df=pd.DataFrame(data)
print(df)
输出:
one two three
a 1.0 1 1.0
b 2.0 2 NaN
c 3.0 3 3.0
d NaN 4 4.0
** 行的访问**














 745
745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









