







DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning
0 总结
| 名称 | 项目 |
|---|---|
| 题目 | DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning |
| 中文 | 深度路径:知识图推理的强化学习方法 |
| 来源 | EMNLP 2017 |
| 作者 | Xiong, Wenhan and Hoang, Thien and Wang, William Yang |
| 代码 | https://hub.fastgit.org/xwhan/DeepPath |
| 摘要 | We study the problem of learning to reason in large scale knowledge graphs (KGs). More specifically, we describe a novel reinforcement learning framework for learning multi-hop relational paths: we use a policy-based agent with continuous states based on knowledge graph embeddings, which reasons in a KG vector space by sampling the most promising relation to extend its path. In contrast to prior work, our approach includes a reward function that takes the accuracy,diversity, and efficiency into consideration. Experimentally, we show that our proposed method outperforms a path-ranking based algorithm and knowledge graph embedding methods on Freebase and Never-Ending Language Learning datasets. (我们研究了大规模知识图中的推理问题。更具体地说,我们描述了一种新的用于学习多跳关系路径的强化学习框架:我们使用基于知识图嵌入的连续状态的基于策略的智能体,它通过抽样最有希望的关系来扩展其路径,在KG向量空间中进行推理。与之前的工作不同,我们的方法包括一个考虑准确性、多样性和效率的奖励。在Freebase和NELL数据集上,我们的实验表明,我们提出的方法优于基于路径排名的算法和知识图嵌入方法) |
1 背景
~~~~~~~ 近年来,深度学习技术在各种分类和识别问题上取得了许多最新的成果。然而,复杂的自然语言处理问题往往需要多个相互关联的决策,使深度学习模型具有学习推理的能力仍然是一个具有挑战性的问题。为了处理没有明显答案的复杂查询,智能机器必须能够利用现有资源进行推理,并学会推断一个未知的答案。
~~~~~~~ 更具体地说,我们把我们的研究放在多跳推理的背景下,给定较大的KG,学习显式推理公式;
例如,如果KG包括内马尔为巴塞罗那效力,而巴塞罗那在英甲联赛,那么机器应该能够学习以下公式:
p l a y e r P l a y s F o r T e a m ( P , T ) ∧ t e a m P l a y s I n L e a g u e ( T , L ) ⇒ p l a y e r P l a y s I n L e a g u e ( P , L ) playerPlaysForTeam(P ,T)∧teamPlaysInLeague(T,L)⇒playerPlaysInLeague(P ,L) playerPlaysForTeam(P,T)∧teamPlaysInLeague(T,L)⇒playerPlaysInLeague(P,L)
在测试的时候,通过输入学到的公式,系统应该能够自动推断出一对实体之间缺失的链接。这种推理机可能会成为复杂QA系统的重要组成部分。
~~~~~~~ 近年来,路径排序算法(PRA) (Lao et al.,2010,2011a)作为一种很有前途的方法能够在大型KGs中学习推理路径。PRA采用基于重启的推理机制的随机行走,执行多个有界深度优先搜索过程来查找关系路径。再加上基于弹性网(elastic-net)的学习,PRA使用监督学习选择更合理的路径。然而,PRA操作在一个完全离散的空间中,这使得评估和比较KG中相似的实体和关系变得困难。
~~~~~~~ 在这项工作中,我们提出了一种新的可控多跳推理方法:我们为路径学习过程建立了一个强化学习(RL)框架。与PRA相比,我们使用基于平移的基于知识的嵌入方法(Bordes et al.,2013)来编码我们的RL智能体的连续状态,这是在知识图的向量空间环境中推理的。智能体通过对一个关系进行抽样来扩展它的路径,从而采取增量步骤。为了更好地指导RL 智能体学习关系路径,我们使用了策略梯度训练(Mnih等人,2015)和一个新的奖励函数,共同鼓励准确性、多样性和效率。实验结果表明,该方法优于PRA算法和基于嵌入的算法。2018年7月7日在Freebase和一个NELL(Carlson et al.,2010a)数据集上的方法。我们的贡献有三:
- 我们首先考虑强化学习(RL)方法来学习知识图中的关系路径;
- 我们的学习方法使用了一个复杂的奖励函数,同时考虑了准确性、效率和路径多样性,在寻径过程中提供了更好的控制和更大的灵活性;
- 我们表明,我们的方法可以扩展到大规模的知识图,在两个任务中优于PRA和KG嵌入方法。
2 相关工作
~~~~~~~ 路径排序算法(PRA)方法(Lao et al.,2011b)是一种主要的寻路方法,采用带重启策略的随机行走进行多跳推理。Gardner等人(2013;2014)对PRA提出了一种改进,在向量空间中计算特征相似度。Wang和Cohen(2015)提出了一种将背景KG和文本相结合的递归随机行走方法,该方法同时进行逻辑程序的结构学习和文本中的信息提取。随机游走推理的一个潜在瓶颈是,连接大量公式的超级节点将创建巨大的扇出区域,显著降低推理速度并影响精度。
~~~~~~~ Toutanova等人(2015)为多跳推理提供了一种卷积神经网络解决方案。他们建立了一个基于词汇化依赖路径的CNN模型,该模型由于解析错误而存在错误传播问题。Guu等人(2015)使用KG嵌入来回答路径查询。Zeng et al.(2014)描述了一个用于关系抽取的CNN模型,但它没有明确地建模关系路径。Neelakantan等人(2015)提出了一种用于知识库完成(KBC)中关系路径建模的递归神经网络模型,但它训练了太多的独立模型,并且因此,它不能规模化。注意,许多最近的KG推理方法(Neelakantan等人,2015;Das等人,2017)仍然依赖于首次学习PRA路径,这只在离散空间中操作。与PRA相比,我们的方法在连续空间中进行推理,并且通过在奖励函数中引入各种标准,我们的强化学习(RL)框架对寻径过程具有更好的控制和更大的灵活性。
~~~~~~~ 神经符号机(Liang et al.,2016)是KG推理的最新成果,它也应用了强化学习,但与我们的工作有不同的风格。NSM学习编写可以找到自然语言问题答案的程序,而我们的RL模型试图通过对已有的KG三元组进行推理,将新的事实添加到知识图(KG)中。为了得到答案,NSM学会生成一系列动作,这些动作可以组合成一个可执行程序。NSM中的操作空间是一组预定义的令牌。在我们的框架中,目标是寻找推理路径,因此动作空间就是KG中的关系空间。类似的框架(Johnson et al.,2017)也被应用于视觉推理任务。
~~~~~~~
3 具体方法模型介绍
~~~~~~~ 在本节中,我们将详细描述基于rl的多跳关系推理框架。关系推理的具体任务是在实体对之间寻找可靠的预测路径。我们将寻路问题表述为一个可以用RL智能体解决的顺序决策问题。我们首先描述环境和基于策略的RL智能体。通过与围绕KG设计的环境交互,智能体学会选择有希望的推理路径。然后描述了RL模型的训练过程。在此基础上,提出了一种有效的路径约束搜索算法,利用RL智能体找到的路径进行关系推理。
3.1 关系推理的强化学习
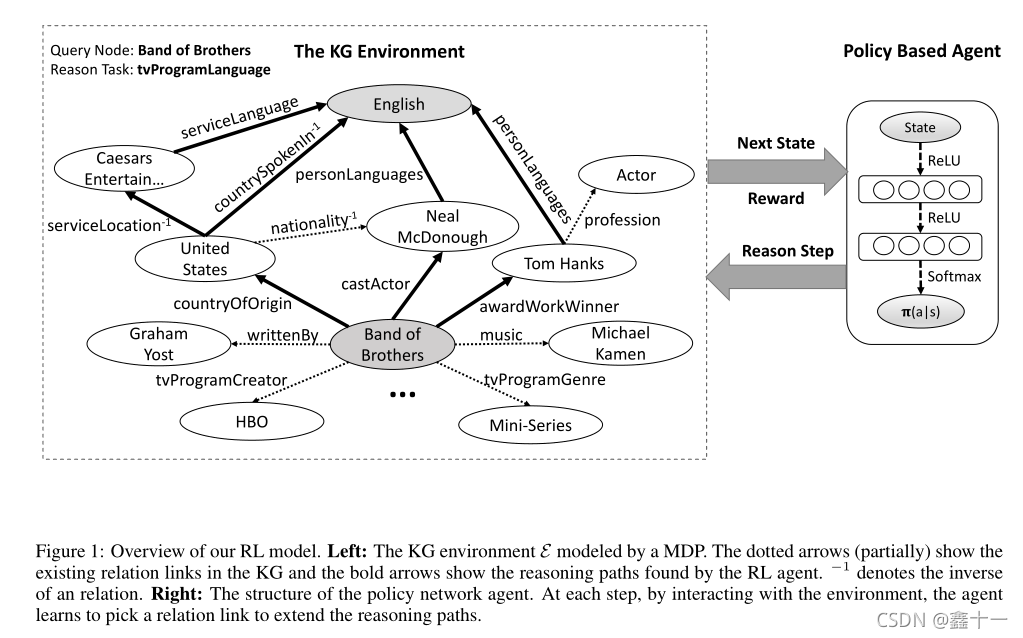
~~~~~~~ RL系统由两部分组成(参见图1)。
~~~~~~~ 第一部分是外部环境 E \mathcal{E} E,它描述了智能体与KG之间相互作用的过程。这个环境被建模为马尔可夫决策过程(MDP)。定义一个元组 < S , A , P , R > \mathcal{<S,A,P,R>} <S,A,P,R>表示MDP,其中连续状态空间A={a1, a2,…, an}是所有可用动作的集合, P ( S t + 1 = s 0 ∣ S t = s , A t = a ) \mathcal{P(St+1=s0|St=s, At=a) } P(St+1=s0∣St=s,At=a)为转移概率矩阵, R ( s , a ) \mathcal{R(s, a)} R(s,a)是每个 ( s , a ) \mathcal{(s, a)} (s,a)对的奖励函数。
~~~~~~~ 系统的第二部分是RL智能体,它由一个策略网络 π θ ( s , a ) = p ( a ∣ s ; θ ) \mathcal{πθ(s, a) =p(a|s;θ)} πθ(s,a)=p(a∣s;θ)表示,该网络将状态向量映射为随机策略。采用随机梯度下降法更新θ的神经网络参数。与Deep Q Network (DQN) (Mnih等人,2013)相比,基于策略的RL方法更适合我们的知识图场景。原因:
- KG中的寻径问题,由于关系图的复杂性,行动空间可能非常大。这会导致DQN的收敛性较差。
- 此外,该策略网络可以学习随机策略,避免agent在中间状态卡死,而不是像DQN等基于值的方法中常见的贪婪策略。
~~~~~~~ 在描述我们的策略网络结构之前,我们首先描述RL环境的组件(动作、状态、奖励)。
3.1.1 Actions
~~~~~~~ 给定具有关系 r \mathcal{r} r的实体对 ( e s , e t ) \mathcal{(e_s, e_t)} (es,et),我们希望智能体找到连接这些实体对的最有信息量的路径。从源实体 e s e_s es 开始,使用策略网络选择最有希望的关系,在每一步扩展它的路径,直到它到达目标实体 e t e_t et 。为保持策略网络输出维数的一致性,将行动空间定义为KG中的所有关系。
3.1.2 States
~~~~~~~ KG中的实体和关系自然是离散的原子符号。因为现有的实际KGs,如Freebase (Bollacker et al., 2008)和NELL (Carlson et al.,2010b)经常有大量的三元组。不可能直接模拟所有状态中的符号原子。为了捕获这些符号的语义信息,我们使用基于翻译的嵌入,如TransE (Bordes et al.,2013)和TransH (Wang et al.,2014)来表示实体和关系。这些嵌入将所有符号映射到一个低维向量空间。在我们的框架中,每个状态(state)捕获智能体在KG中的位置。在执行一个操作(action)之后,智能体将从一个实体移动到另一个实体。这两者通过智能体所采取的动作(action)(关系 relation)联系在一起。在t步处的状态向量如下:
s t = ( e t , e t a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 942
942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









