







背景
经典的CNN可能并不适合声纹识别。本文提出了一种网络搜索的办法,来寻找最适合的network。
实现
search space:网络由多个cell,组成,每个cell的结构如下:

每个xi代表了一个tensor,每个edge代表了一种operation oij(.)
每个Cell包括2个input node、4个intermediate node、1个output node
第k个input的x0为第 k-2个cell的output,x1为第 k-1个cell的output
对于intermediate来说

output即将所有intermediate的output连接起来。
一共有14条Edge,每条edge对应8种常用的operation(search space O)。

主干网络由8层cell组成,其中在1/3与2/3位置的为reduction cell(先除以resolution数2,再乘通道数2),其他的为normal cell(保持spatial resolution)。所有normal cell的结构相同,所有reduction cell的结构也相同。
NAS:
优化两组参数:
1. α用来选择operation
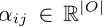
2. W用来代表operation的参数
通过Softmax来优化参数α损失函数:
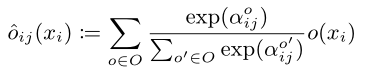
用Lvalidation来优化α,Ltrain来优化W。
本文将两者都用cross-entropy来表示:
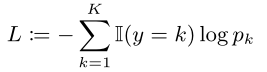
K代表说话人数量。
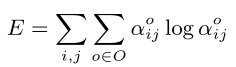
训练过程如下:

训练完成之后,对每个x,保留两种拥有最高的softmax probability的operation(0除外),概率计算为:
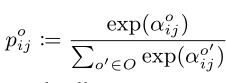
之后测试不同数量的cell、channel,1/3与2/3的位置为reduction cell,其他为normal cell,用cross entropy loss进行优化,将average pooling的输出作为embedding。
实验
Voxceleb1分别提供了SV与SID的数据集,NAS时用SV数据集进行训练;模型训练时,用两个数据集分别训练。
测试了N=8、C=64,N=30、C=64与N=8、C=128的模型,保持它们的参数相同。















 511
511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









