









常见的数据结构
栈
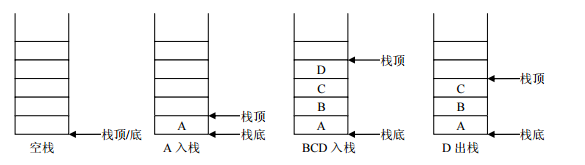
- 栈:stack 又称堆栈,它是运算受限的线性表,其限制是仅允许在标的一端进行插入和删除操作,不允许在其他位置进行添加、查找、删除等操作。
简单的说:采用该结构的集合,对数据的存取有如下的特点:
- 先进后出:存进去的元素,要在它后面的元素依次取出后,才能取出该元素
- 栈的入口、出口都是在栈的顶端位置
简单的说:采用该结构的集合,对元素的存取有如下的特点
-
压栈/入栈:就是存元素。即,把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。例如,子弹压进弹夹,先压进去的子弹在下面,后压进去的子弹在上面,当开枪时,先弹出上面的子弹,然后才能弹出下面的子弹。
-
弹栈/出栈:就是取元素。即,把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置
总结:

队列
队列:queue,简称队,它同堆栈一样,也是一种运算受限的线性表,其限制是仅允许在表的一端进行插入,而在表的另一端进行删除。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
- 先进先出(即,存进去的元素,要在后它前面的元素依次取出后,才能取出该元素)。例如,小火车过山洞,车头先进去,车尾后进去;车头先出来,车尾后出来。
- 队列的入口、出口各占一侧。例如,下图中的左侧为入口,右侧为出口。

总结:

数组
数组:Array,是有序的元素序列,数组是在内存中开辟一段连续的空间,并在此空间存放元素。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
- 查找元素快:通过索引,可以快速访问指定位置的元素

-
增删元素慢
- 指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置。如下图

- 指定索引位置删除元素: 需要创建一个新数组,把原数组元素根据索引,复制到新数组对应索引的位置,原数组中指定索引位置元素不复制到新数组中。如下图

- 指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置。如下图
总结:
链表
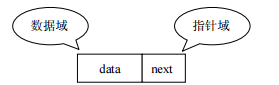
- 链表:linked list,由一系列节点node(链表中每一个元素称为节点)组成,节点可以在运行时i动态生成。每个节点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个节点地址的指针域。我们常说的链表结构有单向链表与双向链表,那么这里给大家介绍的是单向链表。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
-
多个结点之间,通过地址进行连接。例如,多个人手拉手,每个人使用自己的右手拉住下个人的左手,依次类推,这样多个人就连在一起了。

-
查找元素慢:想查找某个元素,需要通过连接的节点,依次向后查找指定元素
-
增删元素快:
- 增加节点:

- 删除节点:

总结:

- 增加节点:
红黑树
- 二叉树:binary tree ,是每个节点不超过2的有序树(tree) 。
简单的理解,就是一种类似于我们生活中树的结构,只不过每个节点上都最多只能有两个子节点。
二叉树是每个节点最多有两个子树的树结构。顶上的叫根节点,两边被称作“左子树”和“右子树”。
如图:

我们要说的是二叉树的一种比较有意思的叫做红黑树,红黑树本身就是一颗二叉查找树,将节点插入后,该树仍然是一颗二叉查找树。也就意味着,树的键值仍然是有序的。
红黑树的约束:
-
节点可以是红色的或者黑色的
-
根节点是黑色的
-
叶子节点(特指空节点)是黑色的
-
每个红色节点的子节点都是黑色的
-
任何一个节点到其每一个叶子节点的所有路径上黑色节点数相同
红黑树的特点:
速度特别快,趋近平衡树,查找叶子元素最少和最多次数不多于二倍
总结:

ArrayList集合
java.util.ArrayList集合数据存储的结构是数组结构。元素增删慢,查找快,由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList是最常用的集合。
许多程序员开发时非常随意地使用ArrayList完成任何需求,并不严谨,这种用法是不提倡的。
LinkedList集合
java.util.LinkedList集合数据存储的结构是链表结构。方便元素添加、删除的集合。
LinkedList是一个双向链表,那么双向链表是什么样子的呢,我们用个图了解下

实际开发中对一个集合元素的添加与删除经常涉及到首尾操作,而LinkedList提供了大量首尾操作的方法。这些方法我们作为了解即可:
public void addFirst(E e):将指定元素插入此列表的开头。public void addLast(E e):将指定元素添加到此列表的结尾。public E getFirst():返回此列表的第一个元素。public E getLast():返回此列表的最后一个元素。public E removeFirst():移除并返回此列表的第一个元素。public E removeLast():移除并返回此列表的最后一个元素。public E pop():从此列表所表示的堆栈处弹出一个元素。public void push(E e):将元素推入此列表所表示的堆栈。public boolean isEmpty():如果列表不包含元素,则返回true。
LinkedList是List的子类,List中的方法LinkedList都是可以使用,这里就不做详细介绍,我们只需要了解LinkedList的特有方法即可。在开发时,LinkedList集合也可以作为堆栈,队列的结构使用。
HashSet集合存储数据的结构(哈希表)
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。
而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示

看到这张图就有人要问了,这个是怎么存储的呢?
为了方便大家的理解我们结合一个存储流程图来说明一下:

总而言之,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
总结:

HashSet 为什么不能存储重复元素:















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









