






事务的目的
在对数据库经过一系列的并发读写操作后,保持数据的一致性。
事务的特性(ACID)
原子性(Atomicity):
一个事务中的所有操作,要么全部执行完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性(Consistency):
在事物开始之前和事物结束之后,数据库的完整性没有被破坏。
隔离性(Isolation):
并发多个事物时,各个事物不干涉其他事务的内部数据,处理的都是另一个事物处理之前或之后的数据。
持久性(Durability):
事务处理结束以后,对数据的修改就是永久的,即便系统故障也不会丢失。
满足ACID的事务才是真事务,否则是假的事务。
一、原子性的实现
undo log
undo log叫做回滚日志,用于记录数据被修改前的信息,在发生错误的时候根据这些信息对数据进行回滚。
undo log的生成
假设有两张表bank和finance,表中原始数据如图所示,当进行插入,删除以及更新操作时生成undo log。

从上图可以了解到数据的变更产生了undo log:
- 产生了变更前数据(bank -> zhangsan,1000)的undo log
- 产生了变更前数据(finance -> zhangsan,0)的undo log
根据undo log进行回滚
当系统发生错误或者执行rollback操作时需要根据undo log进行回滚。

根据undo log生成回滚语句,比如:
- 如果在回滚日志里有新增数据记录,则生成删除该条的语句
- 如果在回滚日志里有删除数据记录,则生成新增该条的语句
- 如果在回滚日志里有修改数据记录,则生成修改到原先数据的语句
补充
undo log主要分为两种,一种是insert undo log(插入undo log),只有在事务回滚时需要,所以在事务提交后可以立即丢弃;另一种是update undo log(修改/删除undo log),不仅在事务回滚时需要,在MVCC中也需要,所以在事务提交后、MVCC中不需要时由后台purge线程删除。
二、隔离性的实现
前提概念理解
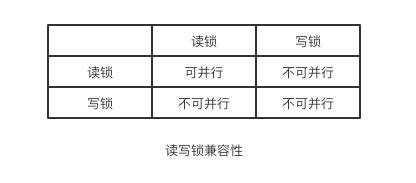
1、读写锁
- 共享锁,又称读锁。读锁状态下,其他读请求可以共享读锁,写请求阻塞,直到读锁释放(写请求阻塞时,读请求也会阻塞,避免读请求长期占用锁,造成写请求长期阻塞)。
- 排它锁,又称写锁。写锁会排斥其他所有获取锁的请求,一直阻塞,直到写入完成释放锁。
2、快照读和当前读
- 当前读:
它读取的数据库记录,都是当前最新的版本,会对当前读取的数据进行加锁,防止其他事务修改数据。是悲观锁的一种操作。 - 快照读:
快照读的实现是基于多版本并发控制,即MVCC,既然是多版本,那么快照读读到的数据不一定是当前最新的数据,有可能是之前历史版本的数据。
3、MVCC
MVCC(MultiVersion Concurrency Control)——多版本并发控制。
InnoDB的MVCC,是通过在每行记录的后面保存两个隐藏的列来实现的:
- DB_TRX_ID:最近插入/修改这条记录的事务ID(事务ID唯一自增。删除当作是更新,采用逻辑删除)。
- DB_ROLL_PTR:回滚指针,指向undo log。
Read View(读视图):
事务进行快照读操作的时候生成读视图(Read View),Read View的属性:
- trx_ids: 创建此read view 时,当前系统活跃(未提交)事务版本号集合。
- low_limit_id: 创建此read view 时,当前系统活跃事务最大版本号+1。
- up_limit_id: 创建此read view 时,当前系统活跃事务最小版本号。
- creator_trx_id: 创建此read view的事务版本号。
Read View可见性判断:
if(DB_TRX_ID < up_limit_id || DB_TRX_ID == creator_trx_id){
// 显示
// 1、比最小的版本号小,说明该数据在当前事务之前就已存在
// 2、和creator_trx_id相等,说明是自己修改的
}else if(DB_TRX_ID >= low_limit_id){
// 不显示
// 比最大的版本号大,说明该数据在当前事务之后才存在
}else if(trx_ids.contains(DB_TRX_ID )){
// 不显示
// 事务还未提交
}else{
// 显示
// 事务已提交
}
隔离级别
- read uncommited(读未提交)
- read commited(读已提交)
- repeatable read(可重复读)
- serializable(序列化)
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。
1、read uncommited(读未提交)
在read uncommited隔离级别下,读不会加任何锁,写加排他锁,并到事务结束之后释放。所以在读的过程中其他事务修改数据的话,就会导致脏读。
优点:读写并行,并发处理性能高
缺点:造成脏读
2、read commited(读已提交)
InnoDB在read commited隔离级别下,写数据时使用排它锁,读数据时不加锁而是使用了MVCC机制(读写分离机制),解决了脏读的问题。
由于每次快照读都会新生成一个Read View,所以会出现可重复读的问题。
3、repeatable read(可重复读)
InnoDB在repeatable read隔离级别下,也是写数据时使用排它锁,读数据时不加锁而是使用了MVCC机制(读写分离机制)。但是每次快照读都是使用同一个Read View,所以解决了脏读、可重复读的问题。
4、serializable(序列化)
在serializable隔离级别下,读加读锁 (S锁),写加写锁 (X锁),事务串行化,并发性能最低。
三、持久性的实现
redo log
redo log叫做重做日志,用于记录数据被修改后的信息,是用来实现事务的持久性。
mysql的数据存储机制
mysql的表数据是存放在磁盘上的,因此想要存取的时候都要经历磁盘IO,磁盘IO是非常消耗性能的。
为了提升性能,InnoDB提供了缓冲池(Buffer Pool),Buffer Pool中包含了磁盘数据页的映射,可以当作缓存来使用:
- 读数据:会首先从缓冲池中读取,如果缓冲池中没有,则从磁盘读取再放入缓冲池;
- 写数据:会首先写入缓冲池,缓冲池中的数据会定期同步到磁盘中。
redo log的作用
缓冲池的措施虽然在性能方面带来了质的飞跃,但是也引入了新的问题,当mysql系统宕机、断电的时候可能会丢失数据。因为我们的数据已经提交了,但此时数据还在缓冲池里,还没来得及在磁盘持久化,所以需要一种机制存一下已提交的数据,为恢复数据使用。即redo log。
redo log 的产生:

四、一致性的实现
原子性、持久性、隔离性的实现也是实现一致性的一部分。在涉及并发的情况下,往往在性能和一致性之间做平衡,做一定的取舍,所以隔离性也是对一致性的一种破坏。















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









