







用法
如果待插入的行数据将导致唯一索引或主键中的值重复,则会按照ON DUPLICATE KEY UPDATE 子句的要求更新原来的行。
官网地址说明:https://dev.mysql.com/doc/refman/8.0/en/insert-on-duplicate.html
INSERT INTO user (id, name) VALUES (1, '张三') ## 第一部分
ON DUPLICATE KEY UPDATE ## 第二部分
name = '张三' ## 第三部分
如上,一个最简单的SQL示例,我们大致可以分成三个部分。
第一部分:常规的INSERT语句
第二部分:子句声明,固定格式
第三部分:待更新的子句
即,当我们第一部分的INSERT语句出现主键或唯一索引冲突时,MySQL将根据冲突字段定位到唯一的行,并根据第三部分的子句更新指定的字段。
示例说明
业务场景:我们需要根据某一字段先去查询数据库中是否有记录,有则更新,没有则插入。一般情况下我们需要做两步操作,先查询,后修改。
这里我们使用 ON DUPLICATE KEY UPDATE 声明子句,一条SQL搞定。
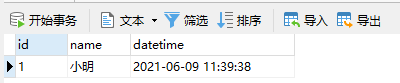
INSERT INTO user(`id`, `name`, `datetime`) VALUES (1, '张三', '2021-09-01 11:39:22')
ON DUPLICATE KEY UPDATE
`name`= '张三' 
注意事项:
1、ON DUPLICATE KEY UPDATE 是MySQL特有的。
2、触发子句的情况是 出现主键或唯一索引值冲突。
另外,实际上MySQL建议我们使用 VALUES 函数来拿到子句的值,而不是写死,VALUES函数会帮我们自动获取到INSERT语句中字段的值。即上述SQL做如下改动。
INSERT INTO user(`id`, `name`, `datetime`) VALUES (1, '张三', '2021-09-01 11:39:22')
ON DUPLICATE KEY UPDATE
`name`= VALUES(`name`), `datetime`= VALUES(`datetime`)其他方式
REPLACE INTO
以主键或唯一索引值冲突触发,即如果数据存在就换成新数据,如果不存在就直接插入。
语法和INSERT INTO完全一致,需要注意的是,如果存在没有指明的字段会用NULL填充,而不是保留原有值。可以理解成先执行一条DELETE再执行一条INSERT。
REPLACE INTO user (`id`, `name`) VALUES (1, '李四')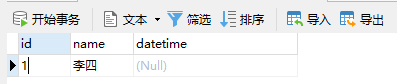
INSERT IGNORE INTO
以主键或唯一索引值冲突触发,即如果数据不存在就直接插入,存在则忽略。
一般用于批量插入数据,加上ignore关键字就可以避免由于某一条重复数据导致所有数据插入失败的情况。
INSERT IGNORE INTO user (`id`, `name`, `datetime`) VALUES (1, '王五', '2021-09-01 11:39:22')














 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









