







学习资料:
MySQL是怎样运行的:从根儿上理解MySQL
0. 前言:从二叉树到B+树的查找
在数据结构【大话数据结构】里,二叉树是一种基本数据结构,相关的基本概念这里就不多说了,我就从应用需求的角度,说一下在其之上的树结构形态。
在查找方面,对于顺序结构,可以采用二分查找、插值查找、斐波那契查找等方法;但实际数据中,有序的很少,在无序的数据集中,可以使用索引结构来查找元素,常见的线形索引结构包括稠密索引、分块索引(是不是有点熟悉)、倒排索引;
一旦将数据有序排列后,虽然查找方便了,但是进行插入和删除就麻烦了,所以,有没有啥结构,能够兼顾一下查找和插入删除?
有,二叉树!
-
二叉排序树(BST)
其查找时间为O(logn)~O(n),对其进行中序遍历,即可得到一个有序的序列!
那么,在生成二叉排序树的时候,如果序列本身就是有序的呢?那就会生成一个斜树,这样当然不好,就是O(n)了,要想办法平衡一下;
-
平衡二叉树(AVL)
前提是BST,根据平衡因子(Balance Factor,BT,是由左子树深度 - 右子树深度),来判断是否平衡,在插入生成BST的时候,就进行判断,通过左旋/右旋进行调节。这样得到的树结构,其查找效率就稳定在O(logn)了。
但是还有一个问题,上面说的所有查找算法的实现,默认前提都是在内存中进行的!所以才去考虑时间复杂度,那如果数据太多了,内存放不下,就只能放磁盘了,那么这个时候,瓶颈就是磁盘I/O了!这时候要考虑的就是,尽量减少磁盘的读写操作,内存中慢点,也比磁盘读写快多了!如果使用上面二叉树的话,一个结点只存一个数据元素,而且每个结点最多只有两个孩子,数据量一大,要么树的度非常大(子树个数的最大值),或者树的深度就大了,更或者两个都大才能存下这么些数据,这样的话,在进行遍历的时候就会频繁读写磁盘。
所以,要打破这个限制。
-
多路查找树(B树)
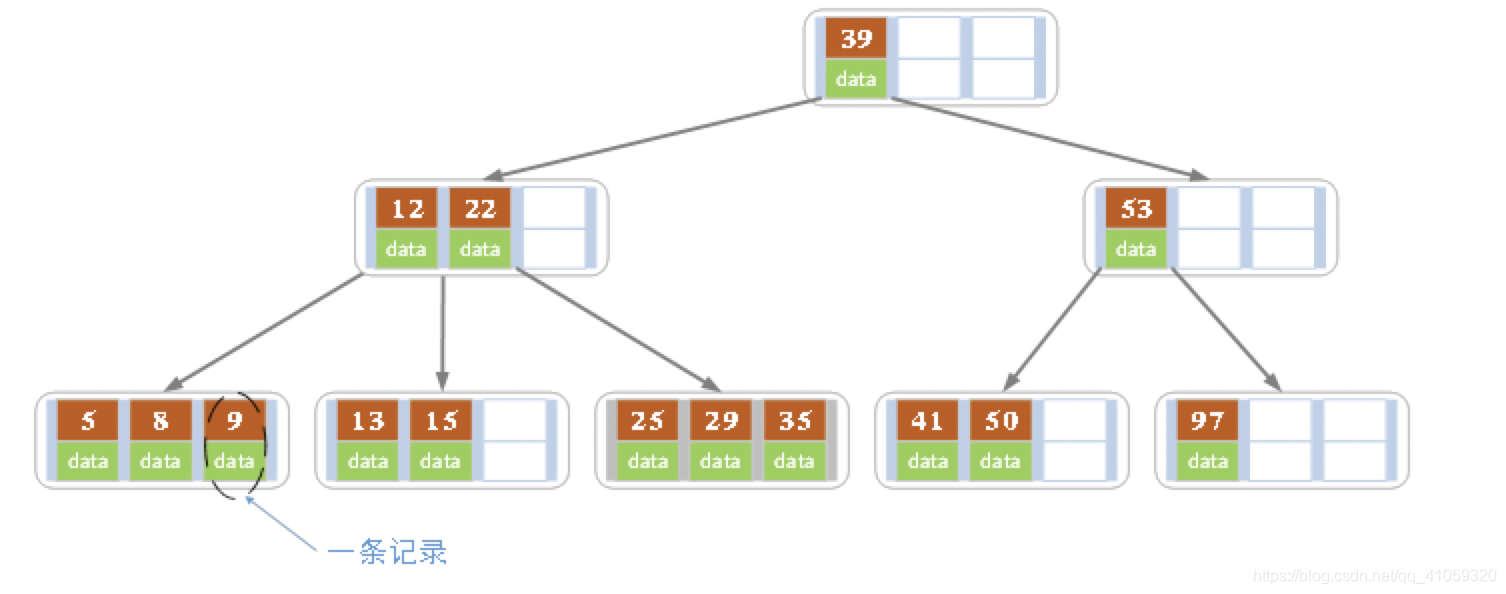
还是用平衡排序树,但是,允许一个结点中存多个数据元素,并且允许有多个孩子。这就是平衡的。这样100个数据元素中,在二叉树中或许要找6次,但是我在B树中,根结点有10个孩子,每个结点存10个元素,这样两下就判断出来了,明显减少了磁盘I/O。这就是为内外存交互准备的!
-
B+树
但是,上面还有个问题,这些都是排序树,对排序树进行中序遍历,得到整体的有序列表,在B树中,虽然查找记录的时候,找一次就可以找到数据元素所在的磁盘地方,但是要进行中序遍历的时候,因为是左-根-右的顺序,所以要多次反复在不同结点中遍历,才能得到一个完整的有序列表,这显然是无法忍受的。
那么如何解决呢?既然问题是出来了得到整个数据集的有序列表上,那么我就多做一步,把所有数据都挪下来放在叶子结点,并且在各个叶子结点之间,形似链表连起来,因为本来就是按照平衡排序树插入的,这样叶子结点的数据元素从左到右连起来,就是一个完整的有序数据集,也不用再去根结点中序遍历了。
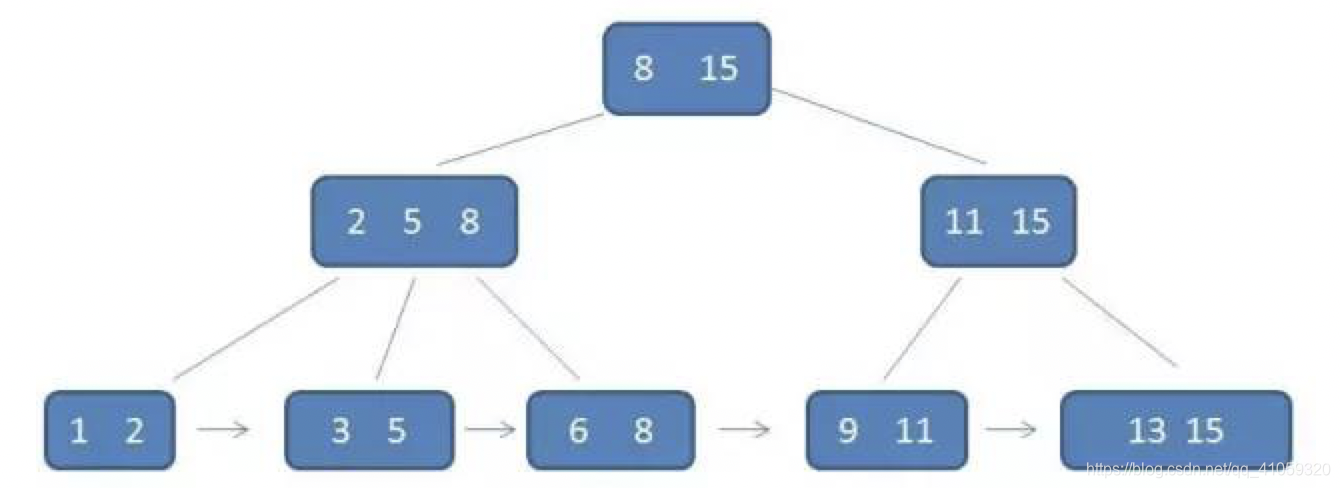
也就是说,叶子结点包含所有的数据,其他结点只是起到索引的作用,因为只是用来找元素所在的叶子结点嘛,找到了在叶子中拿就行了嘛。(索引,承上启下的知识点对不对)
关于二叉树到B+树的更详细信息同学自己去查哈,我也是手捧数据结构书学习的=_=
1. Innodb的索引方案
不知道经过刚才的介绍和前面的学习笔记,同学是否有看到存储结构和B+树索引结构这中间的联系。
1.1 重新捋一下存储结构
前面说了:innodb是以页为存储的基本单位,一页16kb,页内除了一些额外信息,真实数据按照不同的行格式存储,各行按主键有序排列,按照头信息中的next_record指针,连成一个单链表,该链表的头和尾分别是页内的infimum和supremum,页内查找是根据分块索引的原理,根据page direction的slot来进行索引。这些大概还捋的清对吧。
那咱继续。
数据量多了咋办?建树!其实我的理解,这也是一种分块查找。看图说话。
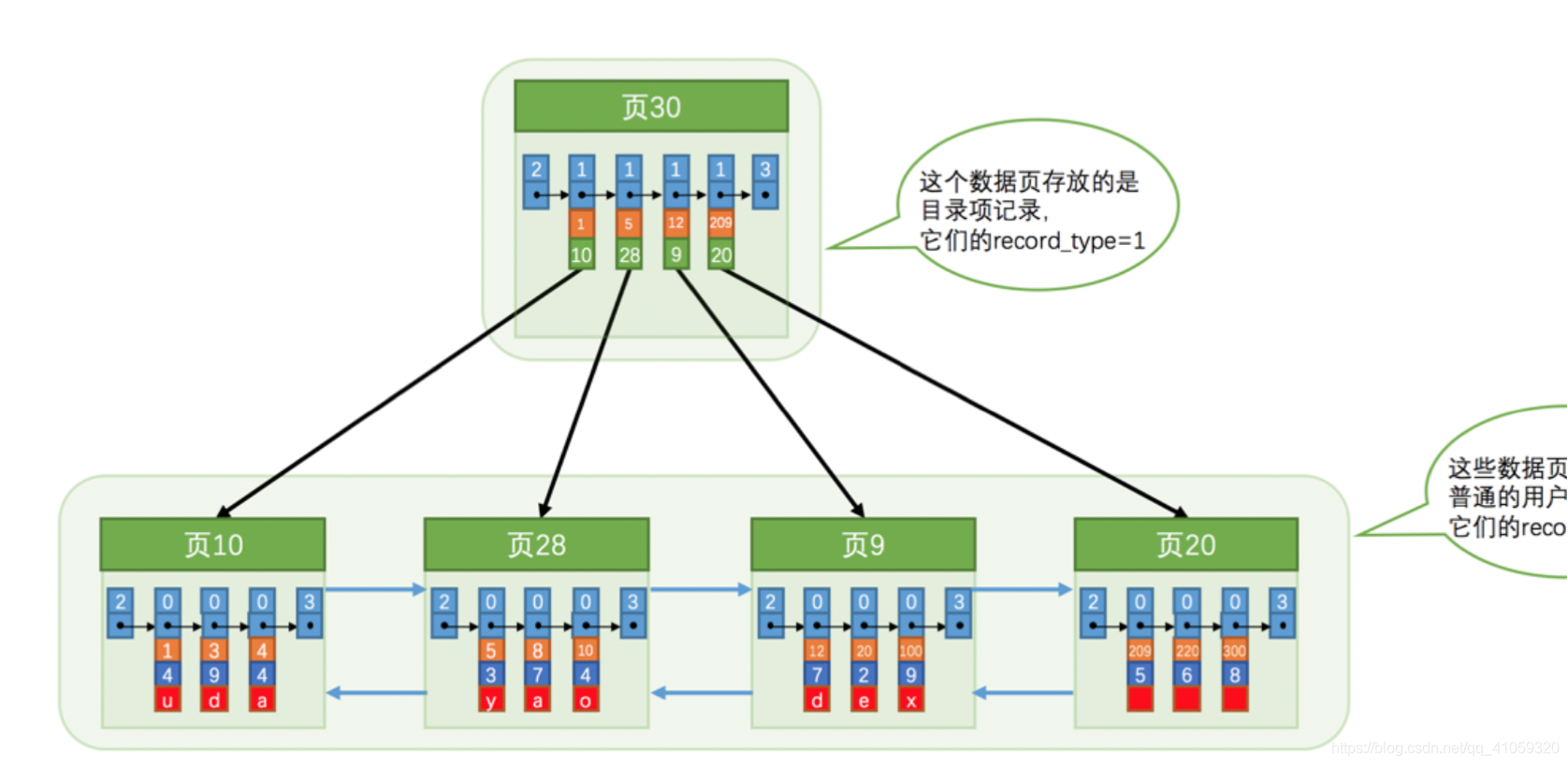
叶子结点就是正常的数据页,但是上面的页是目录页。同学仔细看里面的(简化)行格式,头尾其实就是数据页各种中一样的infimum和supremum,咱先不管。正经的数据记录是{1,10},这意思是:第10页数据页,主键最小的一行记录是1,后面同理。这不就是分块一样的道理么,而且可以是递归形式的往下延伸,啥意思,就是这一层的目录页数量太多了,还可以往上抽象呗,就这样一层一层的,可不就是一颗树嘛。
这里有一个和上一章,存储结构对应的地方:
| record_type | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 含义 | 普通记录 | 索引记录 | 最小值记录 | 最大值记录 |
可以看到,页内的单链表都是从record_type = 2开始,以record_type = 3结束,也就是从infimum开始,以supremum结束!中间的普通记录和索引记录很明显了
1.2 所以这和B+树有啥联系呢?
我来尝试着对应一下哈,看看能不能更具体一点。
| B+树 | Innodb索引 |
|---|---|
| 排序 | 在插入记录时,就按照主键排序插入的 |
| 多叉 | 一个目录页对应多个数据页 |
| 平衡 | 真实数据页,即所有叶子结点,都在同一层 |
| 叶子结点包括所有数据,非叶子节点不保存关键字记录的指针,只进行数据索引 | 同上,其实也只有叶子结点才有数据,上面都是只有主键值和对应的页号 |
| 叶子节点的关键字从小到大有序排列 | 数据页结构中的file header有双指针,以双链表形式将上一页和下一页有序连接 |
差不多就是这样吧啊。
1.3 两种索引
上面说的,都是以主键为前提做索引的,这样查到的叶子结点,是包含完整的所有数据的,这样的索引叫聚簇索引,相对应的,还有一个二级索引。
有时候,一个表里面,除了必要的主键索引,还会建立二级索引,这时的索引结构也是一样,但是在叶子结点就不会是完整的数据了,而是{二级索引值:主键值}这样的行记录了。说直接点,就是在用二级索引进行查找的时候,其实一般要找两次:
- 根据二级索引查到叶子结点,找到对应的主键值;
- 再根据找到的主键值,去聚簇索引,找到完整的数据记录;
为什么说一般要找两次呢?同学想想,如果是下面这种:
select pk, col2 from xx where col2 = xx;
就选主键和二级索引两个字段,而且筛选字段就只有二级索引,那根据col2去二级索引,直接找到主键(pk)和二级索引值就行了,就不用再去聚簇索引再找了。(因为人家不需要啊啊啊啊)
还有一点,就是二级索引有时候并不唯一,这就导致了在构建B+树的时候,不符合唯一性了,简单,本来二级索引的结果就是主键值,主键肯定是唯一的,所以二级索引记录的内容实际是三部分:
- 二级索引值;
- 主键值;
- 页号;
另外,联合索引也是一种二级索引。
2. MyISAM的索引
在刚才innodb的索引介绍上,其实可以看到,索引和数据是不分家的,都在一颗树上,叶子是完整数据,其他是索引。
但是在MyISAM里,是分开的。简单粗暴。
- 按照插入的数据记录顺序插入一个文件,不分页,也不按照主键排序,而且有一个行号,就像代码的行号,这个就是数据文件;
- 单独为表的主键建一个索引,索引的叶子结点并没有完整记录,而是{主键:行号}的形式;
所以可以看出来几点不同:
- 插入时没有按照主键排序,所以无法利用二分、分块等方法查找;
- 索引文件和数据文件是分开的;
- 要先经过索引文件找到行号,再根据行号去数据文件中找到数据,也就是全都是二级索引;
这样看下来同学可能会觉得效率肯定比innodb引擎低,虽然我没深究,但我觉得不是的,因为查到行号,然后根据行号去查找,就有点像hash表的查找了,O(1)啊同学!
3. B+树索引的使用
还是先捋一下上面说过的东西:
- 每个索引都是一个B+树,叶子结点为数据页,存储完整数据,其余为目录项,存储索引列;
- 自动为主键建立聚簇索引,用户可以定义二级索引;
- 每一层,无论是叶子结点还是目录页,都是按照索引列值从小到大有序排列的,通过每页的file header形成双向链表;
- 根据索引找到所在的数据页,页内使用page direction实现分块索引,找到对应的记录;
太具体的使用场景就不记了,这个其实是可以想到的,就简单说几个点:
-
凡事都有两面性,索引提高了查找效率,比如会付出代价,空间上,每多一颗B+树,每个结点都是一个数据页,每一页就是16kb,这对于mysql的“节省”来讲,也是一笔大的开支;时间上,在插入和删除的时候,进行索引的维护工作肯定是耗时的;
-
让索引列单独出现在比较表达式中,使用复杂条件时,无法使用索引。啥意思呢?
select xx from xx where col * 2 < 8; -- 无法使用索引 select xx from xx where col < 4; -- 可以使用索引 -
注意左边匹配、精准匹配的原则
如何挑选索引,这也是个学问:
- 只为用于搜索、分组或排序的字段,也就是一般出现在where/group by/order by条件里面的;
- 基数大的列,说明重复值少;
- 索引列的类型要小,这样cpu操作快,占地方也小;
- 可以考虑对字符串的前缀进行索引,而不是整个字符串;
- 聚簇索引最好少auto_increment,避免发生页面分裂和记录移位现象(这点我没细看);
- 定位并删除表中的重复和冗余索引;














 4207
4207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









