







前言
第1章 装作自己是个小白–初识Mysql
Mysql分为客户端和服务端,客户端有很多种比如:手机 App、桌面端的软件或者网页版的微信。客户端发送请求,服务端处理请求,服务端将处理结果发送客户端。
环境变量PATH:环境变量 PATH 是一系列路径的集合,各个路径之间使用自号(:)隔离开,在我输入某个命令 时,系统会在 PATH按照顺序依次寻找输入的这个命令.如果寻找成功 则执行该命令.
启动服务端的方式很多种不加赘述,启动客户端:
mysql -h主机名 -u用户名 -p密码
例如:mysql -hlocalhost -uroot -p123456
退出
\q
-u表示用户名;也可以写成“-user-用户名”的形式-p表示密码:也可以写成“-password=密码”的形式。参数分成短形式参数和长形式参数,短形式参数加单短划线,长形式参数加双短划线。
客户端进程向服务器进程发送请求并得到响应的过程本质上是一个进程间通信的过程,比如TCP/IP,命名管道和共享内存,UNIX 域套接字等。
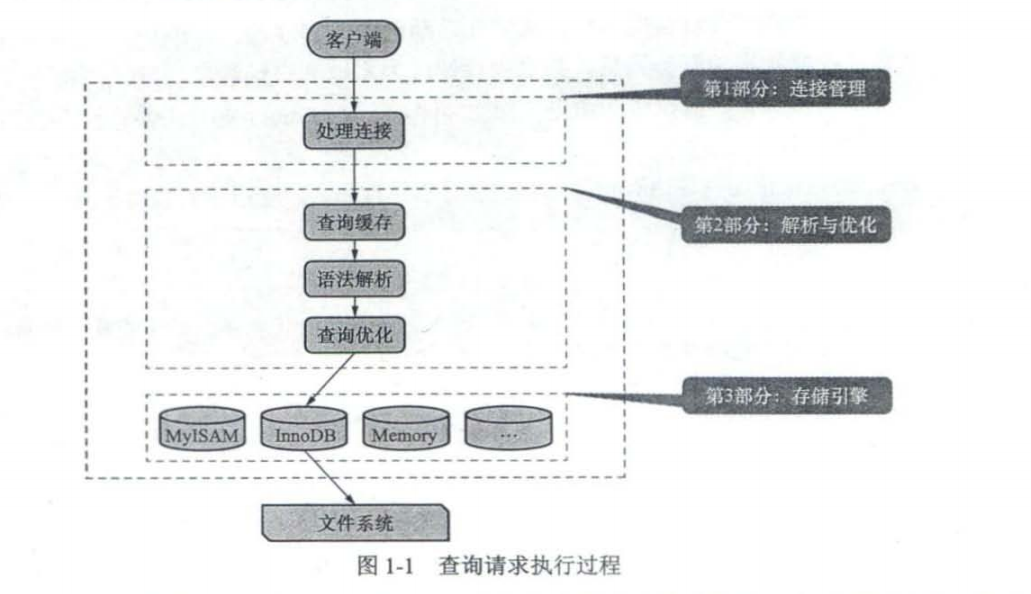
处理连接每当有一个客户端进程连接到服务器进程时,服务器进程都会创建一个线程专门处理与这个客户端的交互,当该客户端退出时会与服务器断开连接服务器并不会立即把与该客户端交互的线程销毁而是把它缓存起来 在另一个新的客户端再进行连接时,把这个缓存的线程分配给该新客户端.这样就不用频繁地创建和销毁线程,从而节省了开销。从这一点大家也能看出, MYSQL 服务器会为每一个连接进来的客户端分配一个线程,但是线程分配得太多会严重影响系统性能 所以我们也需要限制可以同时连接到服务器的客户端数量。
查询与优化MySQL8.0之前Mysql查询缓存,会把刚刚处理过的查询请求和结果缓存起来 如果下 次有同样的请求过来,直接从缓存中查找结果就好了,就不用再去底层的表中查找了,但是因为维护缓存造成的巨大开销MySQL8.0将缓存删除。
语法解析从 本中将要查询的表、各种查询条件都提取出来放到 MySQL 服务器内部使用的这些数据结构上
查询优化.优化的结果就是生成一个执行计划,这个执行计划表明了应该使用哪些索引执行查询,以及表之间的连接顺序是啥样,等等.我们可以使用 EXPLAIN 语句来查看某个语句的执行计划.
存储引擎怎么从表中读取数据,以及怎么把数据写入具体的物理存储器上,都是存储引擎负责的事情。连接管理、查询缓存、语法解析、查询优化这些并不涉及真实数据存取的功能划分server层的功能,存取真实数据的功能划分为存储引擎层的功能,InnoDB从MySQL5.5之后作为默认存储引擎,之前的存储引擎都是MyIsAM。我们可以给具体表设置存储引擎和修改存储引擎。
CREATE TABLE 表名(
建表语句;
) ENGlNE 存储引擎名称
ALTER TABLE 表名 存储引擎名称;
第2章MySQL的调控按钮一启动选项和系统变量
启动选项
启动MySQL服务器的时候可以使用选项例如mysqld --default-storage-engine=MyISAM将默认存储引擎设置为MyISAM。在命令行中设置的启动选项只肘当次启动生效,所以可以在配置文件中使用选项。如果同一个启动选项既 现在命令行中 又出现在配置文件那么以命令行中的启动选项为准。
系统变量
MySQL服务程序在运行过程中会用到很多影响程序行为的变量,他们被称为系统变量。允许同时连入的客户端数量用系统变盘 max_ connection 表示 表的默认存储引擎用系统变量 default-storage-engine 表示。大多数系统变量的值也可以在程序运行过程中修改,而无须停止并重新启动服务器。设置系统变量可以通过启动选项设置也可以在服务程序运行过程中进行设置。系统变量的作用范围分为两种:GLOBAL和SESSION。如果某个客户端改变 某个系统变量 GLOBAL 用范围的值,并不会影响系
统变量在当前已经连接的客户端作用范 围为 SESSION 的值,只会影响后续追入的客户端作用范围 SESSION 的值。
SET [GLOBAL|SESSION] 系统变量名=值;
SET GLOBAL default_storage_engine = MyISAM;
SHOW (GIOBAL ISESSION] VARIABLES [LIKE 阻匹配的模式];
SHOW SESSION VARIABLES LIKE 'defaultstorageengine';
状态变量
为了让我们更好地了解服务器程序的运行情况 MySQL 服务器程序中维护了好多关于程序运行状态的变量,它们被称为状态变量.比如, reads_ connected 表示当前有多少客户端与服务器建立了连接;
SHOW[GLOBAL|SESSION] STATUS [LIKE匹配的模式];
SHOW STATUS LIKE ‘thread%’;
第3章 字符集和比较规则
比较重要的字符集
ASCLL:字符集总共才 28 个字符
ISO 8859-1:它在 ASCIl 字符集的基础上又扩充了 128个
GB2312:如果字符在ASCLL字符集中,则采用一字节编码,否则采用两字节编码。怎么区分某个字节代表的是单独的字符还是字符的一部分,看最高位是不是0如果是0的话读取一个字节,如果是1的话读取两个字节。
GBK:
UTF-8:属于Unicode字符集,UTF-8使用1-4字节编码
Mysql支持的字符集和比较规则

# 字符集查看
SHOW (CHARACTER SET|CHARSET) [LIKE 匹配的模式];
# 比较规则查看
SHOW COLLATION [LIKE 匹配的模式]
字符集和比较规则的应用( character set connection和collation connection)
MySQL有4 个级别的字符集和 比较规则,分别是服务器级别、数据库级别、表级别、列级别。每个级别的字符集和比较规则都可以单独进行设置。只修改字符集,则比较规则将变为修改后的字符集默认的比较规则;只修改比较规则,则字符集将变为修改后的比较规则对应的字符集。
- 如果创建或修改列时没有显式指定字符集和比较规则,则该列默认使用表的字符集和比较规则;
- 如果创建表时没有显式指定字符集和比较规则,则该表默认使用数据库的字符集和比较规则;
- 如果创建数据库时没有显式指定字符集和比较规则,则该数据库默认使用服务器的(中符集和比较规则。
知道了这些规则后,对于给定的表,我们应该知道它的各个列的字符集和比较规则是什从而根据这个列的类型来确定每个列存储的实际数据所占用的存储空间大小。

如果列col使用的字符集是gbk,则两个字符就占用4字节。如果把该列的字符集修改为utf8,这两个字符实际占用的存储空间就是6字节了。
客户端和服务器通信过程中使用的字符集


第4章 从一条记录说起–InnoDB记录存储结构
MySOL服务器中负责对表中的数据进行读取和写入工作的部分是存储引擎,而服务器又支持不同类型的存储引擎,比如InnoDB、MyISAM、MEMORY啥的。不同的存储引擎一般是由不同的人为实现不同的特性而开发的真实数据在不同存储引擎中的存放格式一般是不同的,甚至有的存储引擎(比如MEMORY都不用磁盘来存储数据)。
InnoDB 存储引擎需要一条一条地把记录从磁盘上读出来么?不,那样会慢死,InoDB 采取的方式是,将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位。InnoDB 中页的大小一般为16KB。在服务器运行过程中不能改变页面的大小。
InnoDB的行格式
行格式描述了一条记录在磁盘上是怎样进行存储的。InnoDB分为四种行格式:COMPACT、REDUNDANT、DYNAMIC 和 COMPRESSED
指定行格式
CREATE TABLE 表名(列的信息) ROWFORMAT=行格式名称
ALTER TABLE 表名 ROW FORMAT=行格式名称
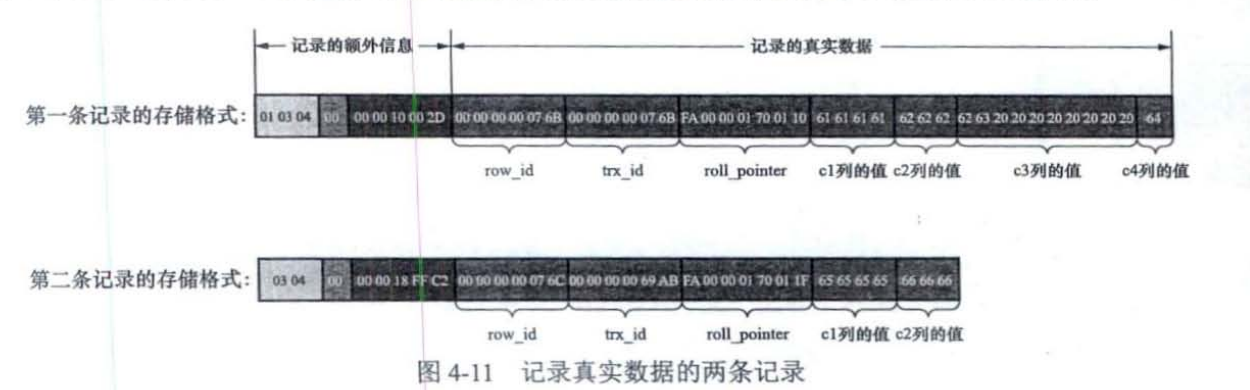
以下面的数据记录对于compact进行说明,其中c1,c2,c4都是varchar类型但是c3是char类型
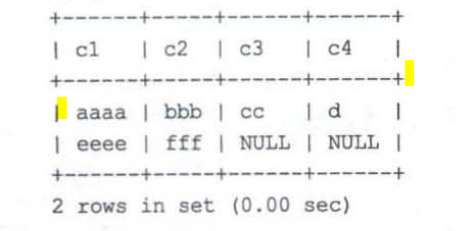
compact的行格式信息

MySOL支持一些变长的数据类型,比如VARCHAR(M)VARBINARY(M各种 TEXT类型、各种BLOB 类型,变长字段占用的存储空间分为两部分:真正的数据内容和该数据占用的字节数,变长字段占用的字节数采用逆序排放。
变长字段长度列表
如果该变长字段允许存储的最大字节数超过255字节(M*W:M为varchar存储的最大字节数,W为当前编码方式例如utf8则为3)并且真实数据占用的字节数(L)超过 127 字节,则使用2字节来表示真实数据占用的字节数,否则使用1字节。另外需要注意的一点是,变长字段长度列表中只存储值为非NULL 的列的内容长度,不存储值为 NULL 的列的内容长度。
第一条记录:01 03 04
第二条记录:03 04
NULL值列表
主键列以及使用NOT NULL修饰的列都是不可以存储NULL值的,表中c1、c3、c4都允许存储NULL值,而c2列使用NOT NULL进行了修饰,不允许存储NULL值。1、如果表中所有列都不允许为NULL,NULL值列将不会存在2、需要使用整数字节表示,不够填充3、如果该列为NULL则表示1否则表示1 4、逆序表示
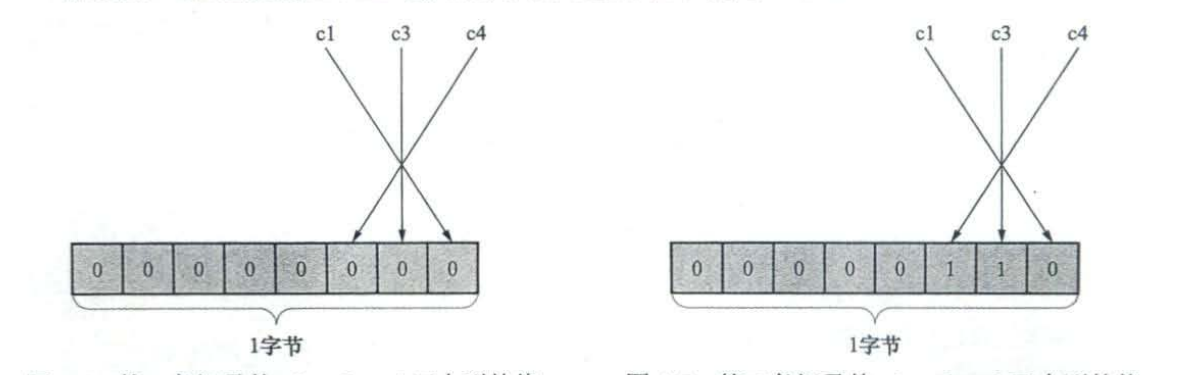
第一条记录:00
第二条记录:06
真实数据
InnoDB的主键生成策略:优先使用用户自定义的主键作为主键:如果用户没有定义主键,则选取一个不允许存储 NULL,值的UNIQUE 键作为主键:如果表中连不允许存储NULL值的UNIOUE键都没有定义,则InnoDB会为表默认添加一个名为row_id的隐藏列作为主键。
char(m)的存储格式
对于CHAR(M)类型的列来说,当列采用的是定长编码的字符集时,该列占用的字节数不会被加到变长字段长度列表;而如果采用变长编码的字符集时,该列占用的字节数就会被加到变长字段长度列表。
采用变长编码字符集的CHAR(M)类型的列要求至少占用M个字节,而VARCHAR(M)却没有这个要求。
第5章 盛放记录的大盒子–InnoDB数据页结构
页是InnoDB管理存储空间的基本单位,一个页的大小一般是16KB.InnoDB为了不同的目的而设计了多种不同类型的页,今天学习的是索引(Index)页。

User Records
我们自己存储的记录会按照指定的行格式存储到User Records部分。但是在一开始生成页的时候,其实并没有User Records部分,每当插入一条记录时,都会从Free Space部分(也就是尚未使用的存储空间)申请一个记录大小的空间,并将这个空间划分到UserRecords部分。当Free Space部分的空间全部被User Records部分替代掉之后,也就意味着这个页使用完了,此时如果还有新的记录插入,就需要去申请新的页了。

下面我们的任务就是理解记录头信息的每一个概念
deletetd_flag:0表示没有被删除,1表示被删除。这些被删除的记录为什么不从磁盘中移除?因为在移除它们之后,还需要在磁盘上重新排列其他的记录,这会带来性能消耗,所以只打一个删除标记就可以避免这个问题。所有被删除掉的记录会组成一个垃圾链表,记录在这个链表中占用的空间称为可重用空间。之后若有新记录插入到表中,它们就可能覆盖掉被删除的这些记录占用的存储空间。将deleted flag属性设置为1和将被删除的记录加入到垃圾链表中其实是两个阶段,后面在介绍uddo日志时会讲解。
min_rec_flag:B+树每层非叶子节点中的最小的目录项记录都会添加该标记
n_owned:每个组的最后一条记录(也就是组内最大的那条记录)相当于“带头大哥”,组内其余的记
录相当于“小弟”,"带头大哥"的n_owned记录的是本组内共有几条记录,"小弟"的n_owned记录的是0。
heap_no:把记录一条一条亲密无间排列的结构称之为堆 (heap),每新申请一条记录的存储空间时,该条记录比物理位置在它前边的那条记录的heap no值大1,比如2,3,4等。0表示页面中的最小记录(也可以写作Infimum记录),1表示页面中的最大记录(也可以写作Supremum记录)。
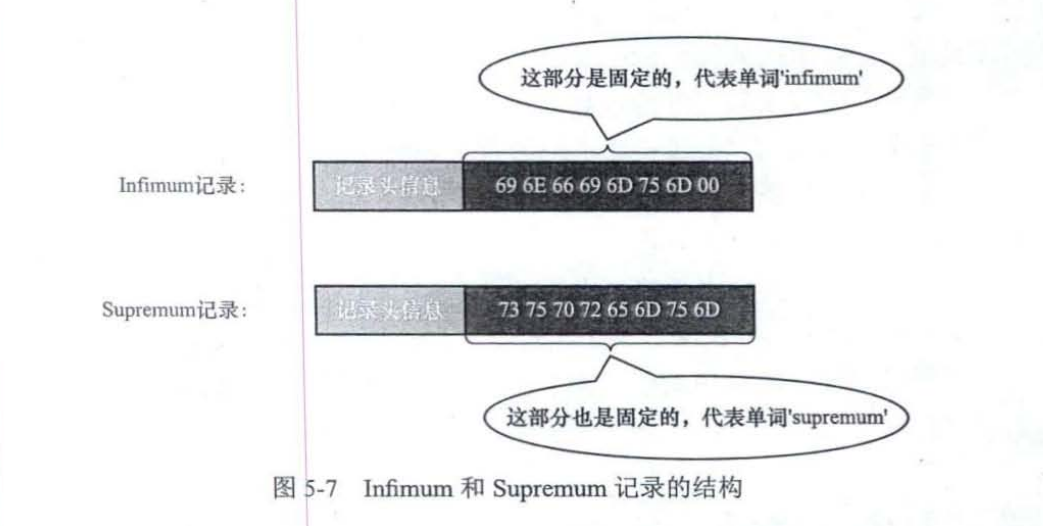
record_type:一共有4种类型的记录,其中0表示普通记录,1表示B+树非叶节点的目录项记录,2表示Infimum记录,3表示Supremum记录。我们自己插入的是普通记录记为0,1的情况在索引章节详细描述。
next_record:它表示从当前记录的真实数据到下一条记录的真实数据的距离,下一条记录指的并不是插入顺序中的下一条记录,而是按照主键值由小到大的顺序排列的下一条记录。next record 值为 32表示第1条记录的真实数据的地址向后找32字节便是下一条记录的真实数据。
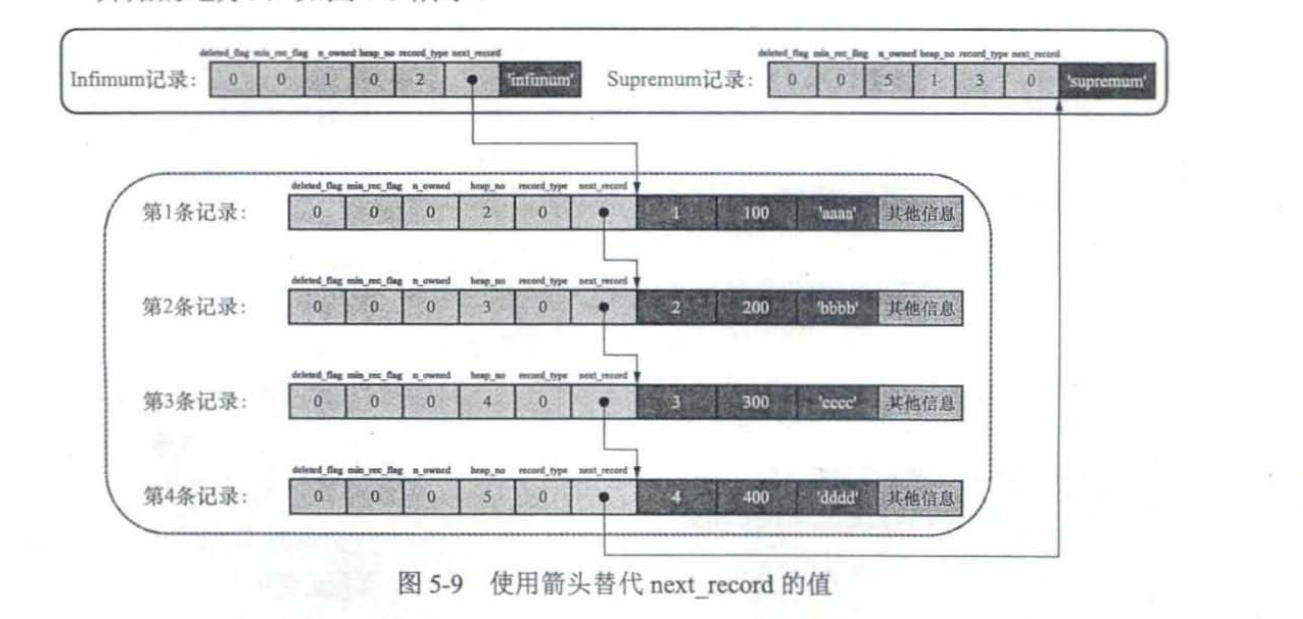
删除第2条记录后的示意图
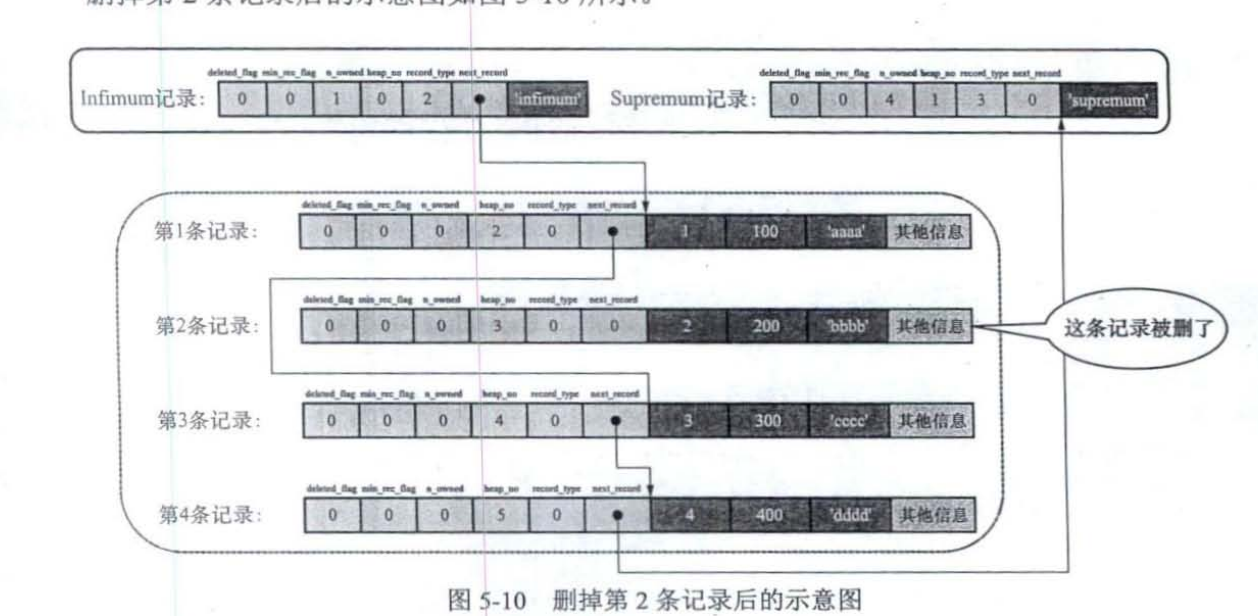
- 第2条记录并没有从存储空间中移除,而是把该条记录的deleted flag值设置为l;
- 第2条记录的next record值变为0,意味着该记录没有下一条记录了:
- 第1条记录的next record指向了第3条记录;
- Supremum记录的n_owned值从5变成了4。
总之,User Records中的记录是按照主键值由小到大的顺序串联成一个单向链表
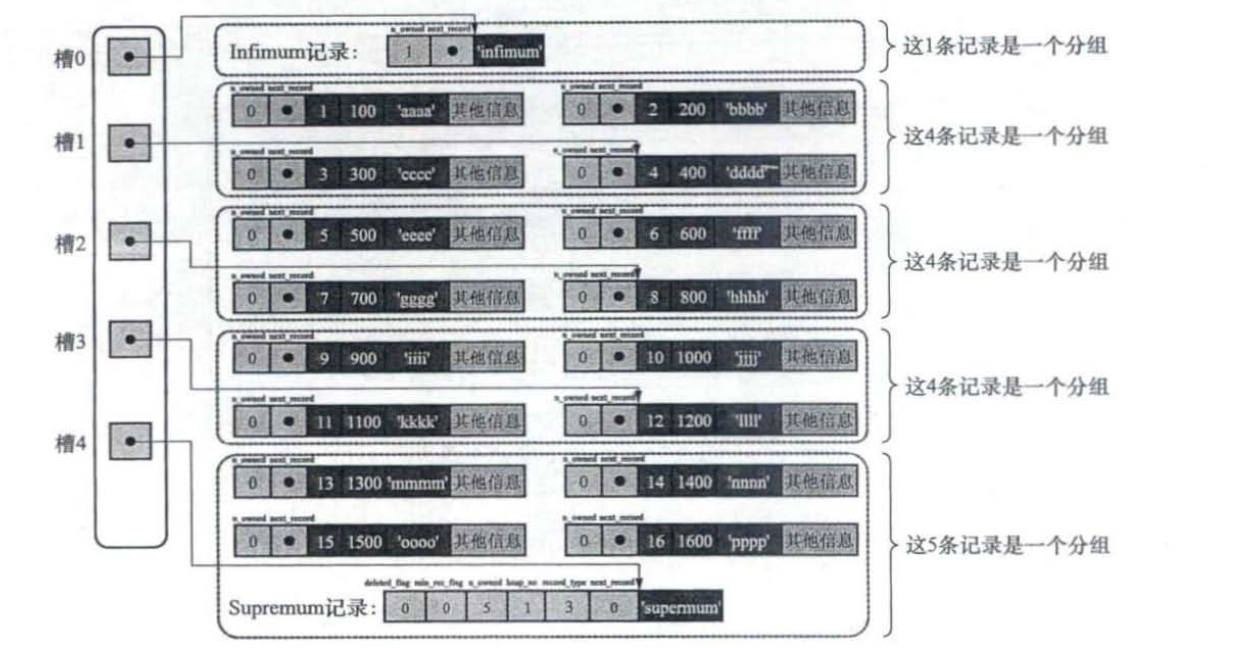
Page Directory
执行这样的sql语句怎样执行?SELECT FROM page_demo WHERE c1=3;
1.将所有正常的记录(包括infimum和Supremum记录,但不包括己经移除到垃圾链表的记录)划分为几个组。
2.每个组的最后一条记录(也就是组内最大的那条记录)相当于“带头大哥”,组内其余的记录相当于“小弟”。“带头大哥”记录的头信息中的n_owned属性表示该组内共有几条记录。
3.将每个组中最后一条记录在页面中的地址偏移量(就是该记录的真实数据与页面中第0个字节之间的距离)单独提取出来,按顺序存储到靠近页尾部的地方。这个地方就是Page Directory。页目录中的这些地址偏移量称为槽(Slot),每个槽占用2字节。页目录就是由多个槽组成的。
分组按照下面的规则:对于Infimum记录所在的分组只能有1条记录,Supremum记录所在的分组拥有的记录条数只能在1~ 8条之间,剩下的分组中记录的条数范围只能是在4~8条之间。
数据插入过程
l.在初始情况下,一个数据页中只有Infimum记录和Supremum记录这两条,它们分属于两个分组。页目录中也只有两个槽,分别代表Infimum记录和Supremum记录在页面中的地址偏移量。
2.之后每插入一条记录,都会从页目录中找到对应记录的主键值比待插入记录的主键值大并且差值最小的槽(从本质上来说,槽是一个组内最大的那条记录在页面中的地址偏移量,通过槽可以快速找到对应的记录的主键值),然后把该槽对应的记录的n_owned值加1,加1,表示本组内又添加了一条记录,直到该组中的记录数等于8个。
3.当一个组中的记录数等于8后,再插入一条记录,会将组中的记录拆分成两个组,其中一个组中4条记录,另一个5条记录。这个拆分过程会在页目录中新增一个槽,记录这个新增分组中最大的那条记录的偏移量。
数据查找过程
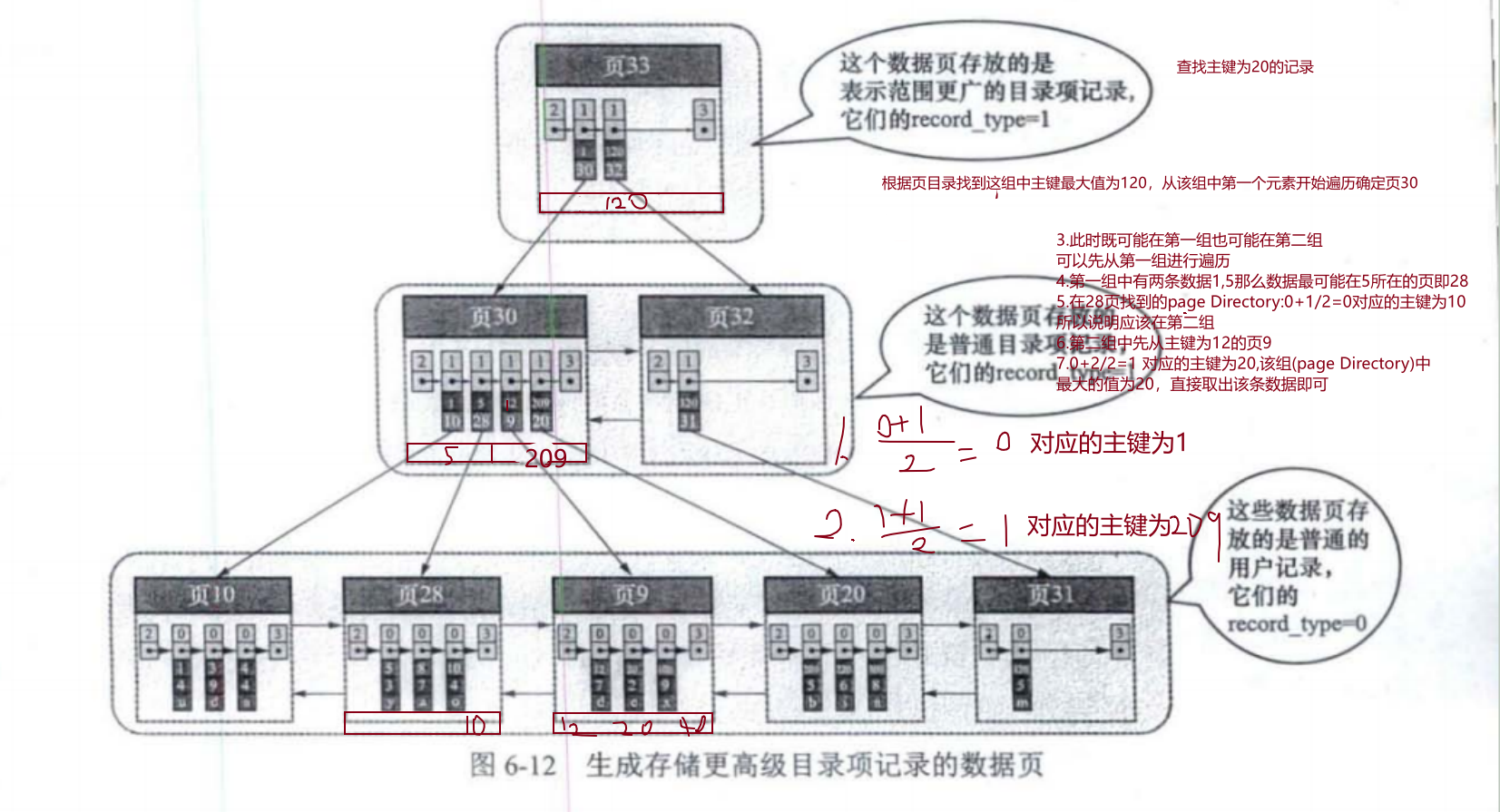
查找主键值为6的记录:
1.计算中间槽的位置:(0+4)/2=2,查看槽2对应记录的主键值为8;又因为8>6,所以设置high=2,low保持不变。
2.重新计算中间槽的位置:(0+2)/2=1,查看槽1对应记录的主键值为4:又因为4<6,所以设置low=1,high保持不变。
3.因为high一low的值为1,所以确定主键值为6的记录在槽2对应的组中。此时需要找到槽2所在分组中主键值最小的那条记录,然后沿着单向链表遍历槽2中的记录。但是前文又说过,每个槽对应的记录都是该组中主键值最大的记录,这里槽2对应的记录是主键值为8的记录,怎么定位一个组中最小的记录呢?别忘了各个槽都是挨着的,我们可以很轻易地找到槽1对应的记录(主键值为4),这条记录的下一条记录就是槽2所在分组中主键值最小的记录,其主键值为5。所以,我们可以从这条主键值为5的记录出发知道找到主键为6的那条记录。
总结:
1.通过二分法确定该记录所在分组对应的槽,然后找到该槽所在分组中主键值最小的那条记录。
2.通过记录的next record属性遍历该槽所在的组中的各个记录。
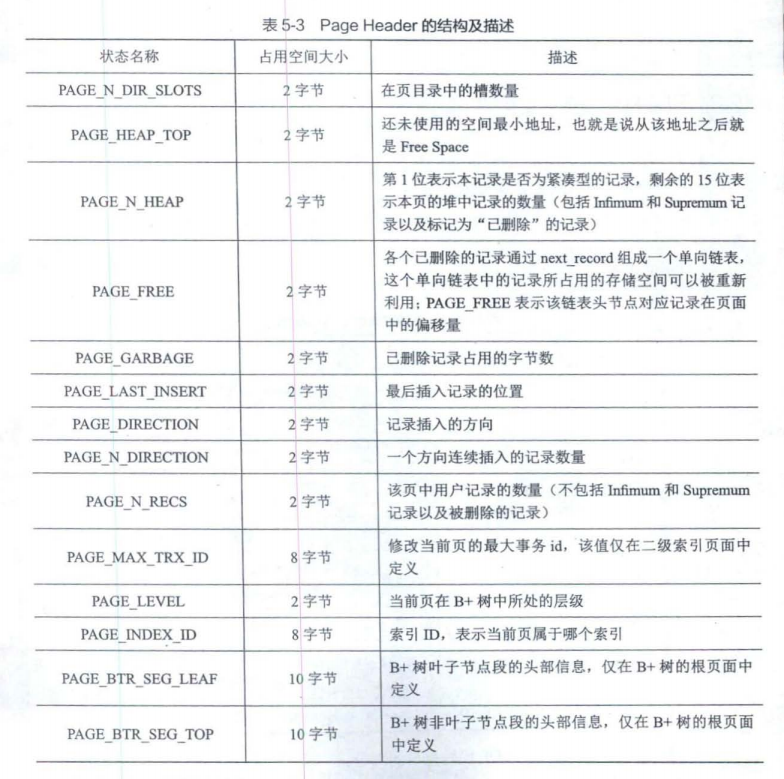
page header
描述了数据页的各种状态信息
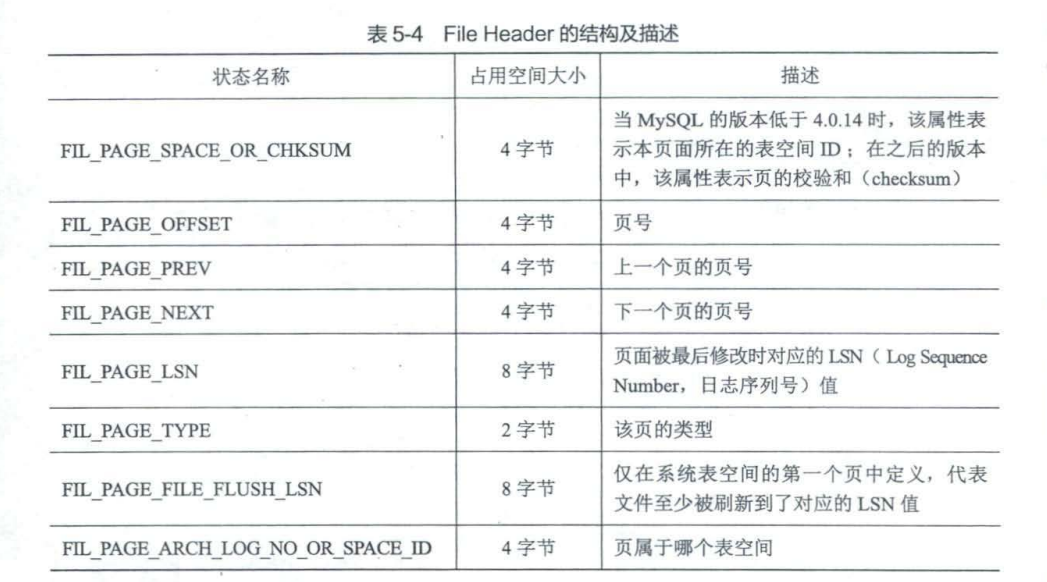
File header
适用于通用页,也就是说各种类型的也都会以File Header作为第一个组成部分,它描述了一些通用于各种页的信息,比如这个页的编号是多少,它的上一个页和下一个页是谁等等。
File Trailer
File Trailer一共占有8个字节。每当一个页面在内存中修改了,在同步之前就要把它的校验和算出来,因为File Header在页面的前边,所以校验和会被首先同步到磁盘,当完全写完时,校验和也会被写到页的尾部,如果完全同步成功,则页的首部和尾部的校验和应该是一致的,反之意味着同步中间出了错。File Trailer校验页的完整性。分成两部分:
1、File Trailer的前4个字节和File header的FIL_PAGE_SPACE_OR_CHKSUM进行校验
2、File Trailer的后4个字节和FIL_PAGE_LSN进行校验
第6章 快速查询的秘籍-B+树索引
概述
各个数据页可以组成一个双向链表,而每个数据页中的记录会按照主键值从小到大的顺序组成一个单向链表。每个数据页都会为存储在它里面的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。
select [查询列表] from 表名 where 列名=xxx
在一个页中寻找的时候如果列名是主键,那么就根据上面的查找方法可以快速找到;如果在多个页中寻找的时候,不论列名是不是主键,只能一页一页的寻找,这种方法显然是非常耗时的。所以InnoDB引入了索引的概念。
索引
B+树
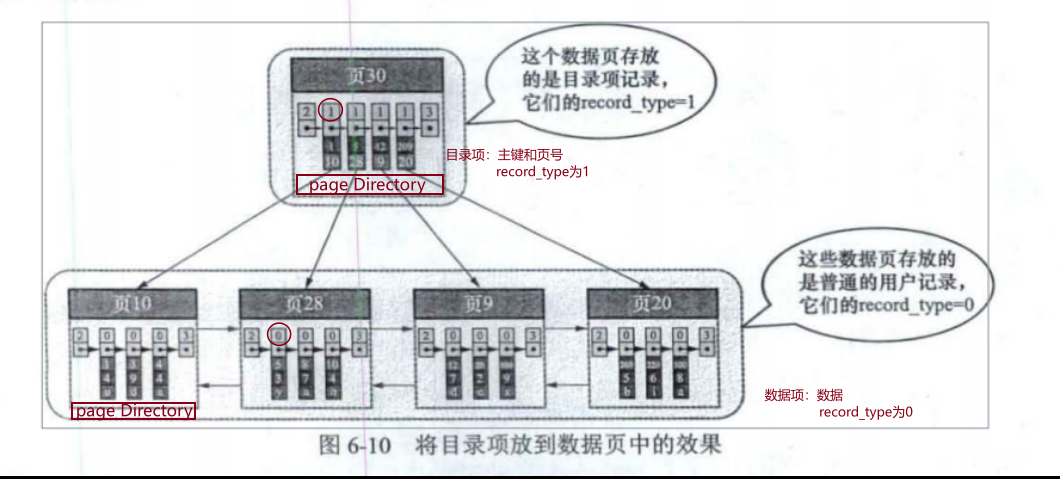
图6-10就是的名称叫做B+树,真正用到的用户记录其实都存放在B+树最底层的节点上,这些节点被称为叶子节点或者叶节点,其余用来存放目录项记录的节点称为非叶子节点或者内节点。我们使用的B+树一般不会超过4层。(因为四层就可以存放很多条数据了)。在非叶子节点中可以不断通过二分法确定查询记录所在的页,在叶子节点可以再次通过二分法确定查询记录。
InnoDB索引
聚簇索引:数据即索引,索引即数据
- 通过主键值进行大小排序
- 叶子节点存放完整的用户记录
- InnoDB引擎会自动创建聚簇索引
- 目录项为主键+页号
二级索引
- 通过c2列进行大小排序
- 叶子节点存放的是c2+主键
- 目录项为c2+页号
- 根据主键信息回表
联合索引
- 先对c2进行排序,当c2相同时对于c3进行排序
- 本质上二级索引也是一个联合索引,目录项存放的是c2+主键+页号
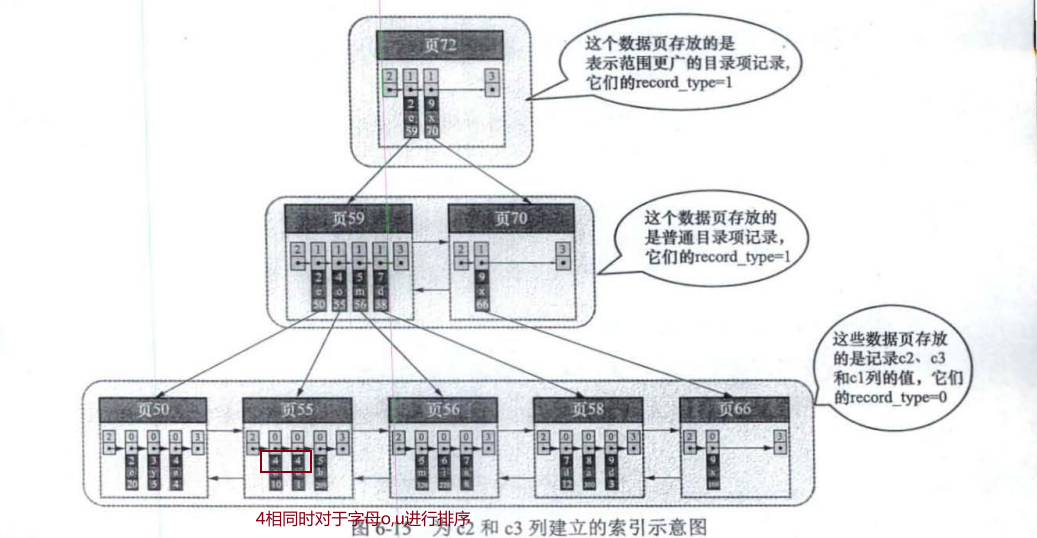
共同点:
- 页号不连续,随机分配,不同页之间使用双向链表进行连接
- 在对页中的记录进行增删改操作的过程中,我们必须通过一些诸如记录移动的操作来始终保证这个状态一直成立,这个过程称为页分裂。(1->3->5在一个页中,插入4时需要将1->3->4放在第一个页,5放在第二个页)。
索引查询过程
索引建立过程
- 创建B+树索引时,会为该索引增加一个根节点页面。
- 插入用户记录时,先将用户记录存储在根节点中
- 在根节点可用空间用完时继续插入记录时,复制根节点页得到页a,页a进行页分裂得到页b。新插入的记录根据索引列的值决定放到页a还是页b中
第7章 B+树索引的使用
索引的代价
1、空间的代价
创建索引会占用空间,这点显而易见
2、时间的代价
增删改记录需要对于目录项按照索引列递增的特点进行维护,维护可能包括页面分裂,页面回收等等;
如果索引过多,会导致成本分析过程耗时太多,生成执行计划性能也就比较差。
所以,在一个表中建立的索引越多,占用的存储空间也就越多,在增删改记录或者生成执行计划时性能也就越差。为了建立又好又少的索引,我们得先了解索引在查询执行期间到底是如何发挥作用的。
扫描区间和边界条件
全表扫描:对于使用moDB存储引擎的表来说,全表扫描意味着从聚簇索引第一个叶子节点的第一条记录开始,沿着记录所在的单向链表向后扫描,直到最后一个叶子节点的最后一条记录。
SELECT * FROM single_table WHERE id>=2 AND id <=100;
扫描区间:扫描区间为[2,100]
边界条件:边界条件为id>=2 AND id <=100
在使用某个索引执行查询时,最关键的问题就是通过搜索条件找出合适的扫描区间,对于每个扫描区间来说,进需要通过B+树定位到该扫描区间的第一条记录,就可以沿着记录所在的单项链表向后扫描,直到某条记录不符合形成该扫描区间的边界条件为止。
一些扫描区间
in:会产生多个单点扫描区间
SELECT * FROM single table WHERE key2 IN (1438,6328);
!=a:(-∞,a)和(a,+∞)
SELECT * FROM single table WHERE key != 'a';
Like:只有在匹配完整的字符串或者匹配字符串前缀时才产生合适的扫描区间。
//这种才会用到索引
LIKE 'a%'
//这种不会用到索引
LIKE '%b'
所有搜索条件都可以生成合适的扫描区间的情况
//使用key2作为索引时,扫描区间为(200,+∞)
SELECT * FROM single table WHERE key2>100 AND key2>200;
//使用key2作为索引时,common_field对应的扫描区间为(-∞,+∞)相当于TRUE,TRUE AND(100,+∞)等于(100,+∞)
SELECT * FROM single table WHERE key2>100 AND common_field='abc';
有的搜索条件不能生成合适的扫描区间的情况
//使用key2作为索引时,common_field='abc'就不能生成合适的扫描区间直接认定为TRUE。扫描区间为(-∞,+∞),如果使用二级索引还会回表,所以不用索引效果更好
SELECT * FROM single table WHERE key2>100 OR common_field='abc';
从复杂的搜索条件中找出扫描区间
- key1有二级索引idx_key1,key列有唯一二级索引uk_key2
SELECT * FROM single_table WHERE
(key1>'xyz' AND key2=748 )OR
(key1<'abc' AND key1>'1mn')OR
(key1< 'abc'AND key1>'1mn')OR
(key1 LIKE '%suf'AND key1>'zzz'AND (key2<8000 OR common_field='abc'));
- 1、使用key1作为索引,将不能形成合适扫描区间的搜索条件暂时移除掉,移除方法就是将其换成TRUE,所以西面的sql变成:
SELECT * FROM single_table WHERE
(key1>'xyz' AND TRUE) OR
(key1<'abc' AND key1>'1mn') OR
(TRUE AND key1 > 'zzz'AND TRUE)
- 2、化简
key1 >'xyz' OR (key1<'abc' AND key1>'1mn') OR (key1 > 'zzz')
- 3、化简
key1>'xyz'
索引下推
1、根据最左原则,只会使用name作为搜索条件,比如找到了"张三"和"张五",此时需要回表到聚簇索引中找到具体的数据,找到谁的名字为10返回。
2、可以使用联合索引(name,age),找到张三和王五之后直接判断谁的age=10,直接返回。这种方法可以减少回表次数。
select * from tuser where name like '张%' and age=10;
使用联合索引执行查询时对应的扫描区间
key_part1—>key_part2–>key_part3
我们可以定位到符合key part1=a’AND key part2=b’AND key part3=c’条件的第一条记录,然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key part1='a’条件或者key part2='b’条件或者key part3='c’条件为止。扫描区间为[(‘a’,‘b’,'c),(‘a’,'b,'c)],
SELECT * FROM single_table WHERE key_part1='a'AND key_part2='b'AND key_part3='c';
下面的sql不能使用联合索引
SELECT * FROM single_table WHERE key_part2='a';
下面的sql能利用到联合索引的只有一点即找到key_partl='a’的第一条记录,扫描区间为[‘a’ ‘a’]
SELECT FROM single_table WHERE key_partl='a'AND key_part3 ='c';
key_partl<‘b’,与key_part2='a无关,key_part1 ='b’会使用到key_part2='a’的条件。当二级索引记录的key partl列值为’b’时,也可以通过key part2='a’条件减少需要扫描的二级索引记录范围。也就是说,当扫描到不符合key_partl=b’AND key_part.2=‘a’条件的第一条记录时,就可以结束扫描,而不需要将所有key part1列值为b’的记录扫描完。第一条sql扫描区间为(-∞,‘b’),第二条sql的扫描区间为[(-∞,-∞),(b’,'a)]。
SELECT * FROM single_table WHERE key_part1<'b'AND key_part2='a';
SELECT * FROM single_table WHERE key_partl <='b'AND key_part2 ='a';
索引用于排序
文件排序:使用ORDER BY子句对查询出来的记录按照某种规则进行排序。这种在内存或者磁盘中进行排序的方式统称为文件排序,但是,如果ORDER BY子句中使用了索引列,就有可能省去在内存或磁盘中排序的步骤。
使用联合索引的注意事项
- ORDER BY子句后面的列的顺序也必须按照索引列的顺序给出
不可以使用索引进行排序的集中情况
- ASC、DESC混用一般执行优化器不会使用联合索引,但是Mysql8.0引入了一种称为Descending Index的特性,可以支持ORDER BY子句中ASC、DESC混用的情况.
- 排序列包含非同一个索引的列。比如
SELECT * FROM single_table ORDER BY key1,key2 LIMIT 10;不能使用key1索引进行排序 - 排序列是某个联合索引的索引列,但是这些排序列在联合索引中并不连续。比如
SELECT * FROM single_table ORDER BY key_part1,key_part3 LIMIT 10;就不能使用 key_part1->key_part2->key_part3的联合索引进行排序 - 用来形成扫描区间的索引列与排序列不同。比如
SELECT * FROM single_table WHERE key1= 'a' ORDER BY key2 LIMIT 10;此时排序会使用key1的索引,就不会使用key2的索引进行排序。 - 排序列不是以单独列名的形式出现在ORDER BY子句中,比如
SELECT * FROM single_table ORDER BY UPPER(key1) LIMIT 10;此时不会使用key1的索引进行排序。
索引用于分组
分组列的顺序也需要与索引列的顺序一致,也可以只使用索引列中左边连续的列进行分组
回表的代价
需要执行回表操作的记录越多,使用二级索引进行查询的性能也就越低,某些查询宁愿使用全表扫描也不使用二级索引。比如,假设ky1值在’a’~'c之间的用户记录数量占全部记录数量的99%以上,如果使用idx key1索引,则会有99%以上的id值需要执行回表操作。这不是吃力不讨好么,还不如直接执行全表扫描。
一般情况下,可以给查询语句指定LIMIT来限制查询返回的记录数,这可能会让查询优化器倾向于选择使用二级索引+回表的方式进行查询,原因是回表的记录越少,性能提升就越高
更好的创建和使用索引
- 只为用于搜索、排序或分组的列创建索引,比如
SELECT common_field,key_part3 FROM single_table WHERE key1= 'a';只需要为key1创建索引即可。 - 考虑索引列中不重复的个数,如果重复的列/整个记录比例过大,将该列创建为索引列并不划算
- 索引列的类型要尽量小,因为占用存储空间。尤其是主键,因为二级索引都包含主键。
- 为列前缀建立索引例如
ALTER TABLE single table ADD INDEX idx_keyl(key1(10));,不过无法实现分组SELECT * FROM single_table ORDER BY key1 LIMIT 10 SELECT key1,id FROM single_table WHERE key1= 'a' AND key1 = 'c';使用key1索引不会进行回表,最好仅把业务中需要的列放在查询列表中,而不是简单地以*替代。- 让索引列以列名的形式在搜索条件中单独出现,
SELECT * FROM s1 single_table WHERE key2*2 4;此时不会使用key2列作为索引列 - 页面分裂意味着什么?意味着性能损耗!所以,如果想尽量避免这种无谓的性能损耗,最好让插入记录的主键值依次递增
- 冗余索引,如果已经有key_part1、key_part2、key_part3列建立的联合索引,那么key_part1和key_part1、key_part2的联合索引都是冗余索引。
第8章 数据的家–Mysql的数据目录
像InnoDB、MyISAM这样的存储引擎都是把表存储在磁盘上,而操作系统又是使用文件系统来管理磁盘,所以用专业一点的话来表述就是:像InnoDB、MyISAM这样的存储引擎都是把数据存储在文件系统上。本章讲述的是InnoDB和MyISAM这两个存储引擎的数据是如何在文件系统中存储的。
数据目录的结构
//如何确定Mysql中的数据目录
show variables like 'datadir';
数据库在文件系统中的表示
每当我们新建一个数据库时,MySQL会帮我们做两件事:
- 在数据目录下创建一个与数据库名同名的子目录
- 在与该数据库名同名的子自录下创建一个名为b.opt的文件。这个文件中包含了该据库的一些属性,比如该数据库的字符集和比较规则
表在文件系统中的表示
我们的数据其实都是以记录的形式插入到表中的。每个表的信息可以分为两种:
- 表结构的定义;
- 表中的数据。
表结构的定义相关数据存储在数据库dahaizi对应的子目录下就会创建一个名为test.fim文件。
InnoDB是如何存储数据的
表空间
(1)系统表空间(system tablespace)
系统表空间可以对应文件系统上一个或多个实际的文件,在默认情况下,InnoDB会在数据目录下创建一个名为ibdata1,这个文件是自扩展文件,当不够用的时候会自己增加文件大小。Mysql 5.6.5及以前表中的数据都会被默认存储在这个系统表空间。我们也可以不把系统表空间对应的文件路径配置到数据目录下,甚至可以配置到单独的磁盘分区上,也可以改变系统表空间对应的文件。
(2)独立表空间(fle-per-table tablespace)
在MySQL5.6.6以及之后的版本中,InnoDB不再默认把各个表的数据存储到系统表空间中,而是为每一个表建立一个独立表空间,在表所属数据库对应的子目录中增加了一个.ibd文件。
假如我们使用独立表空间来存储dahaizi数据库下的test表,那么在该表所在数据库对应的dahaizi目录下会为test表创建下面这两个文件
- test.fm;
- test.ibd。
我们可以指定新建的表数据存在系统表空间中或者存在独立表空间中,也可以将系统表空间和独立表空间存储的数据转换。
MyIsAM是如何存储数据的
假如test表使用的是MyISAM存储引擎,那么在它所在数据库对应的dahaizi目录下会为test表创建下面这3个文件:
- test.frm;
- test.MYD;
- test.MYI。
test.MYD表示表的数据文件,也就是插入的用户记录:test.MYI表示表的索引文件。
Mysql系统数据库简介
每一个数据库都用不同的作用,需要可以自行查阅。(不太重要)
第9章 存放页面的大池子–InnoDB的表空间
表空间是一个抽象的概念,我们向表中插入数据的时候,就是从表空间的池子里面找到一个页将数据写入。InnoDB支持许多种类型的表空间,本章主要对于系统表空间和独立表空间进行概述,系统表空间额外包含了一些关于整个系统的信息。
独立表空间
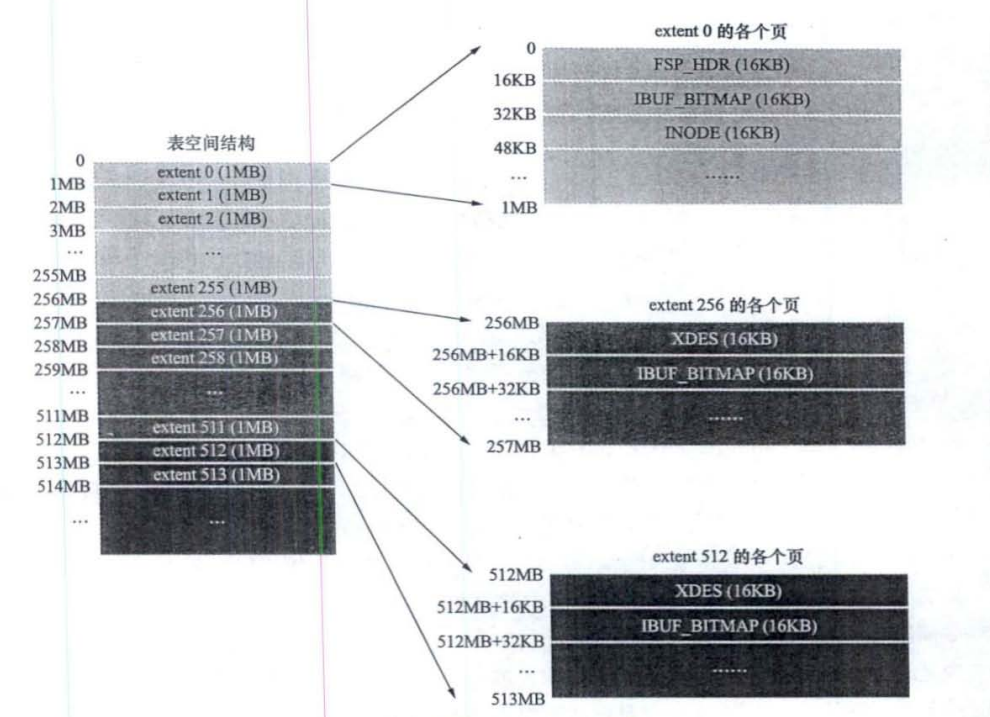
表空间被划分为许多连续的区,每个区默认由64个页组成(1M),每256个区划分为一组(256M),第一组中前三个页面比较特殊,后面的组中前两个页面比较特殊,后面会详细介绍这些页面的作用。
区相关
为什么要有区
B+树的每一层中的页都会形成一个双向链表,如果是以页为单位来分配存储空间的话,双向链表相邻的两个页之间的物理位置可能离得非常远。我们介绍B+树索引的适用场景的时候特别提到范围查询只需要定位到最左边的记录和最右边的记录,然后沿着双向链表一直扫描就可以了,而如果链表中相邻的两个页物理位置离得非常远,就是所谓的随机IO。再一次强调,磁盘的速度和内存的速度差了好几个数量级,随机IO是非常慢的,所以我们应该尽量让链表中相邻的页的物理位置也相邻,这样进行范围查询的时候才可以使用所谓的顺序IO.
引入区的概念,一个区就是在物理位置上连续的64个页。因为InnoDB中的页大小默认是16KB,所以一个区的大小是64*16KB=1MB。在表中数据量大的时候,为某个索引分配空间的时候就不再按照页为单位分配了,而是按照区为单位分配,甚至在表中的数据特别多的时候,可以一次性分配多个连续的区。虽然可能造成一点点空间的浪费(数据不足以填充满整个区),但是从性能角度看,可以消除很多的随机IO,功大于过!
区分类

处于FREE、FREE_FRAG以及FULL _FRAG这3种状态的区都是独立的,算是直属于表空间;而处于FS
EG状态的区是附属于某个段的。
我觉得这段解释非常好,所以就摘抄下来。

段相关
为什么要有段
对于范围查询,其实是对B+树叶子节点中的记录进行顺序扫描,而如果不区分叶子节点和非叶子节点,统统把节点代表的页面放到申请到的区中的话,进行范围扫描的效果就大打折扣了。所以InnoDB对B+树的叶子节点和非叶子节点进行了区别对待,也就是说叶子节点有自己独有的区,非叶子节点也有自己独有的区。存放叶子节点的区的集合就算是一个`段(segment),存放非叶子节点的区的集合也算是一个段。也就是说一个索引会生成2个段,一个叶子节点段,一个非叶子节点段。
除了索引的叶子节点段和非叶子节点段之外,InnoDB中还有为存储一些特殊的数据而定义的段,比如回滚段。所以,常见的段有数据段、索引段、回滚段。数据段即为B+树的叶子节点,索引段即为B+树的非叶子节点。
在InnoDB存储引擎中,对段的管理都是由引擎自身所完成,DBA不能也没有必要对其进行控制。这从一定程度上简化了DBA对于段的管理。
段其实不对应表空间中某一个连续的物理区域,而是一个逻辑上的概念,由若干个零散的页面以及一些完整的区组成。
碎片区
为什么要有碎片区?
默认情况下,一个使用InnoDB存储引擎的表只有一个聚簇索引,一个索引会生成2个段,而段是以区为单位申请存储空间的,一个区默认占用1M(64*16Kb=1024Kb)存储空间,所以默认情况下一个只存了几条记录的小表也需要2M的存储空间么?以后每次添加一个索引都要多申请2M的存储空间么?这对于存储记录比较少的表简直是天大的浪费。这个问题的症结在于到现在为止我们介绍的区都是非常纯粹的,也就是一个区被整个分配给某一个段,或者说区中的所有页面都是为了存储同一个段的数据而存在的,即使段的数据填不满区中所有的页面,那余下的页面也不能挪作他用。
为了考虑以完整的区为单位分配给某个段对于数据量较小的表太浪费存储空间的这种情况,InnoDB提出了一个碎片(fragment)区的概念。在一个碎片区中,并不是所有的页都是为了存储同一个段的数据而存在的,而是碎片区中的页可以用于不同的目的,比如有些页用于段A,有些页用于段B,有些页甚至哪个段都不属于。碎片区直属于表空间,并不属于任何一个段。
所以此后为某个段分配存储空间的策略是这样的:
- 在刚开始向表中插入数据的时候,段是从某个碎片区以单个页面为单位来分配存储空间的。
- 当某个段已经占用了
32个碎片区页面之后,就会申请以完整的区为单位来分配存储空间。所以现在段不能仅定义为是某些区的集合,更精确的应该是某些零散的页面以及一些完整的区的集合。
XDES Entry
每一个区都对应着一个XDES Entry结构,XDES Entry存储在每个组中的第一个页中(FSP_HDR,XDES)
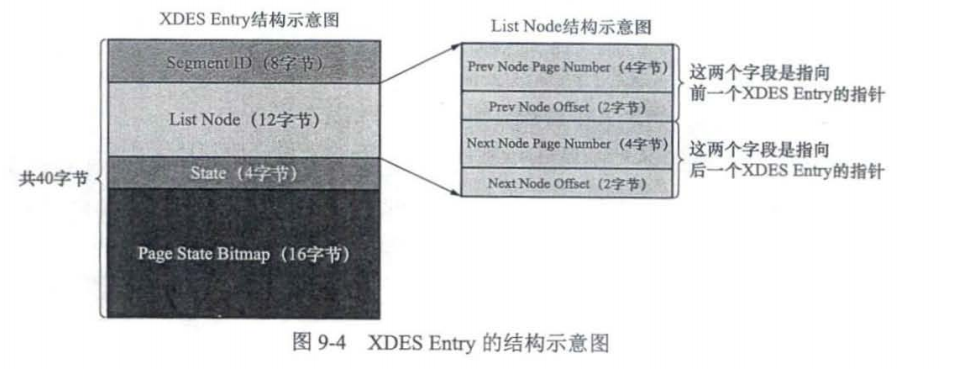 重要的字段:
重要的字段:
- ListNode,组成双向链表。
- 通过List Node把状态为FREE的区对应的XDES Entry结构连接成一个链表,这个链表称为FREE链表。
- 通过List Node把状态为FREE FRAG的区对应的XDES Entry结构连接成一个链表,这个链表称为FREE FRAG链表。
- 通过List Node把状态为FULL FRAG的区对应的XDES Entry结构连接成一个链表,这个链表称为FULL FRAG链表。
- state,记录了本区的类型
FREE,FREE FRAG,FULL FRAG每一种都会建立一个链表,另外类型为FSEG的区会建立3个链表,名字为FREE,NOT_FULL,FULL。
回顾数据插入的过程:(自己总结-。-)
1、段中数据较少,首先看表空间碎片区为FREE FRAG的链表是否有状态为FREE_FRAG的区,如果找到直接插入
2、如果没有找到申请一个FREE的区,将该区的状态变成FREE_FRAG,再将数据插入
3、如果FREE_FRAG满了,那么将其标记为FULL_FRAG
4、如果某个段中的零散页面的个数超过32个,则会为该段申请一个FSEG专门存储该段数据
每个链表都对应一个List Base Node结构,这个结构中记录了链表的头尾节点的位置以及该链表中包含的节点数。正是因为这些链表的存在,管理这些区才变成了一件相当容易的事情。
INODE Entry
段其实不对应表空间一个连续的物理区域,而是一个逻辑上的概念,由若干个零散的页面和一个完整的区组成,每个段都定义了一个INODE Entry结构。

表空间组中固定页面总结
FSP HDR:表空间中第一个页面的类型为FSP HDR,它存储了表空间的一些整体属性以及第一个组内256个区对应的XDES Entry结构。
XDES:其余组的第一个页面的类型为XDES,这种页面的结构和FSP HDR类型的页面对比,除了少了File Space Header部分之外(也就是除了少了记录表空间整体属性的部分之外),其余部分是一样的
IBUF BITMAP:存储了一些关于Change Buffer的信息
INODE:表空间中第一个分组的第三个页面的类型是NODE,它是为了存储NODE Entry结构而设计的,这种类型的页面会组织成下面两个链表。
- SEG INODES FULL链表:在该链表中,NODE类型的页面中已经没有空闲空间来存储额外的NODE Entry结构。
- SEG INODES FREE链表:在该链表中,NODE类型的贡面中还有空闲空闻来存储额外的NODE Entry结构。
Segement Header
Segment Header结构占用l0字节,是为了定位到具体的INODE Entry结构而设计的。
系统表空间
与独立表空间相比,系统表空间有一个明显的不同之处,就是在表空间开头有许多记录整个系统属性的页面。
InnoDB提供了一系列系统表来描述元数据,其中SYS TABLES、SYS COLUMNS、SYS
NDEXES、SYS FIELDS这4个表尤其重要,称为基本系统表(basic system table)。
第10 章 条条大路通罗马–单表访问方法
- 我们向上面这个表插入1000条数据。
CREATE TABLE single_table(
id INT NOT NULL AUTO INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY uk_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1,key_part2,key_part3)
Engine=InnoDB CHARSET=utf8;
)
回到MySQL中来,我们平时所写的那些查询语句本质上只是一种声明式的语法,只是告诉MySQL要获取的数据符合哪些规则,至于MySQL背地里是如何把查询结果搞出来的则是MySQL自己的事儿。同一个sql的查询语句可以使用多种不同的访问方法执行,虽然最后的查询结果是一样的,但是不同的执行方式花费的时间成本可能差距很大。
const
通过主键或者唯一二级索引列与常数的等值比较来定位一条记录的访问方法称为const(意思是常数级别的,代价是可以忽略不计的)。比如下面的查询语句
select * from single_table where id = 1438;//id是主键
select * from single_table where key2=3841;//key2是唯一二级索引列,只有一条记录需要回表
ref
搜索条件为二级索引列与常数进行等值比较,形成的扫描区间为单点扫描区间,采用二级索引来执行查询”的访问方法称为ref。
SELECT * FROM single_table WHERE key1='abc';//key1是二级索引,可能有多条记录需要回表
另外需要注意两种情况:
- 无论是普通的二级索引,还是唯一二级索引,它们的索引列并不限制NULL值的数量,所以在执行包含“key IS NULL”形式的搜索条件的查询时,最多只能使用ref访问方法,而不能使用const访问方法。
- 对于联合索引idx_key_part,,只要最左边连续的列是与常数进行等值比较,就可以采用ref访问方法。比如下面这几个查询都可以采用ref访问方法执行:
select * from single_table where key1_part1 = 'god like';
select * from single_table where key1_part1 = 'god like' and key_part2 = 'legendary'
select * from single_table where key1_part1 = 'god like' and key_part2 = 'legendary' and key_part3 = 'penta kill'
下面的访问方法就不能被称为ref,因为左边连续的列不是等值比较的。
select * from single_table where key1_part1 = 'god like' and key_part2 > 'legendary'
ref_or_null
当使用二级索引而不是全表扫描的方式执行该查询时,对应的扫描区间就是[NULL,NULL]以及[‘abc’,‘abc’],此时执行这种类型的查询所使用的访问方法就称为ref or null。
SELECT * FROM single_table WHERE key1 = 'abc' OR key1 IS NULL;
总结:const,ref,ref_null都是等值比较用到的访问方法
range
SELECT * FROM single_table WHERE key2 IN (1438,6328)OR (key2 >38 AND key2 <79);
如果使用idx key.2执行该查询,那么对应的扫描区间就是[1438,1438]、[6328,6328]以及[38,79],这种访问方法被称为range。
index
第一种情况: 它的查询列表只有key_part1、key_part.2和key_part3这3个列,而索引idx_key_part又恰好包含这3个列;搜索条件中只有key part2列,这个列也包含在索引idx key part中。(查询列表和搜索条件都包含在联合索引中)
SELECT key_part1,key_part2,key_part3 FROM single_table WHERE key_part2 = 'abc';
我们可以直接遍历idx key part索引的所有二级索引记录,针对获取到的每一条二级索引记录,都判断key part2='abc’条件是否成立。如果成立,就从中读取出key_part1、key_part2、key_part3这3个列的值并将它们发送给客户端。因为由于二级索引记录比聚簇索记录小得多(聚簇索引记录要存储用户定义的所有列以及隐藏列,而二级索引记录只需要存放索引列和主键)所以直接扫描全部的二级索引记录比直接扫描全部的聚簇索引记录的成本要小很多。
第二种情况:当通过全表扫描对使用InnoDB存储引擎的表执行查询时,如果添加了“ORDER BY主键的语句,那么访问方法也是Index
SELECT * FROM single_table ORDER BY id;
all
全表扫描
注意事项
重温二级索引+回表
SELECT * FROM single_table WHERE key1 = 'abc'AND key2>1000;
如果使用key1作为索引MAME对应的搜索区间为[‘abc’,‘abc’],如果使用key2作为索引那么对应的搜索区间为(1000,+∞)。优化器会通过访问表中的少量数据或者直接根据事先生成的统计数据,来计算['abc,'abc]扫描区间包含多少条记录,再计算(100,+∞)扫描区间包含多少条记录,之后再通过一定算法来计算使用这两个扫描区间执行查询时的成本分别是多少,最后选择成本更小的那个扫描区间对应的索引执行查询。
索引合并
MySQL在“一般情况下”只会为单个索引生成扫描区间,但还存在特殊情况。在这些特殊情况下,MySQL也可能为多个索引生成扫描区间。
Intersection索引合并
select * from single_table where key1 = 'a' and key3='b';
同时使用idx_key1和idx_key3执行查询,也就是在idx_key1中扫描key1值在[‘a’,‘a’]区间中的二级索引记录,同时在iadx_key3中扫描key3值在[‘b’,‘b’]区间中二级索引记录,然后从两者的操纵结果中找到id列相同的记录,最后根据这些共有的id执行回表操作。
值得注意的是:如果使用Intersection索引合并的方式执行查询,并且每个使用到的索引都是二级索引的话,则要求从每个索引中获取到的二级索引记录都是按照主键值排序的。比如下面就不能将索引合并查询。
- key1>a的记录并不是按照主键大小进行排序的
SELECT * FROM single table WHERE key1 >'a' AND key3 ='b';
- key_part1当key_part1=a之后并不是按照主键排序的,而是暗转key_part2
SELECT * FROM single_table WHERE key1= 'a'AND key_part1= 'a';
Union索引合并
select * from single_table where key1='a' or key3='b';
我们可以同时使用idx key1和idx key3来执行查询。也就是在idx key1中扫描keyl值位于[‘a’,‘a’]区间中的二级索引记录,同时在idx key3中扫描key3值位于[‘b’,‘b’]区间中的二级索引记录,然后根据二级索引记录的id值在两者的结果中进行去重,再根据去重后的id值执行回表操作,这样重复的id值只需回表一次。
值得注意的是:如果使用Uion索引合并的方式执行查询,并且每个使用到的索引都是二级索引的话,要求从每个索引中获取到的二级索引记录都是按照主键值排序的。比如下面就不能用索引合并进行查询
- key1>a的记录并不是按照主键大小进行排序的
SELECT * FROM single table WHERE key1 >'a' OR key3 ='b';
- key_part1当key_part1=a之后并不是按照主键排序的,而是暗转key_part2
SELECT * FROM single_table WHERE key1= 'a' OR key_part1= 'a';
Sort-Union索引合并
SELECT * FROM single_table WHERE key1<'a'OR key3 >'z'
先根据key1<'a’条件从idx keyl二级索引中获取二级索引记录,并将获取到的二级索引记录的主键值进行排序,
再根据key3>z’条件从idx key3二级索引中获取二级索引记录,并将获取到的二级索引记录的主键值进行排序,
因为上述两个二级索引主键值都是排好序的,所以剩下的操作就与Union索引合并方式一样了。
为什么只有Sort-Union索引合并没有Sort-Intersection索引合并呢?
Intersection交集之后进行回表操作,由此推测交集之前的数据肯定比较多,这样对于主键进行排序的效率并不高,所以没有引入Sort-Intersection。而Union是数据并集之后进行回表操作,由此推测并集之前的数据并不多,所以没有引入Sort-Union。
第11 章 两个表的亲密接触–连接的原理
连接简介
连接就是把各个表中的记录取出来一次进行匹配,并且把匹配之后的组合发送给客户端。
t1:

t2:

将两个表进行连接
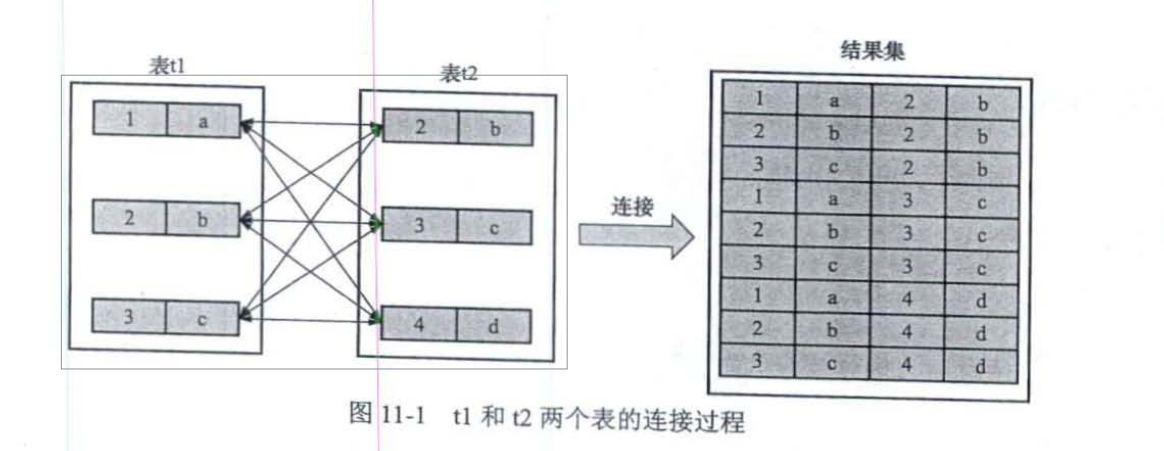
连接过程
SELECT * FROM t1,t2 WHERE t1.ml>1 AND t1.m1=t2.m2 AND t2.n2<'d';
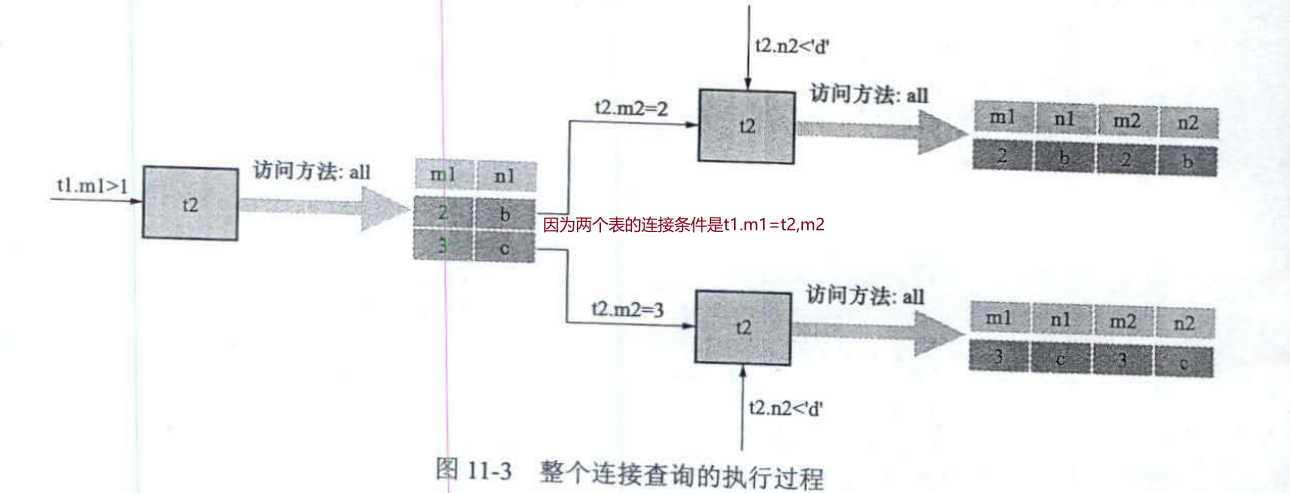
从上面的步骤可以看出来,两个表的连接查询共需要查询1次t1表,2次t2表。这里面t1表是驱动表,t2表是被驱动表,驱动表只会被访问一次,被驱动表可能会被访问多次。
内连接和外连接
我们现在有下面的两张表,如果执行下面的sql的到的结果如图2所示
SELECT * FROM student,score WHERE student.number = score.number;
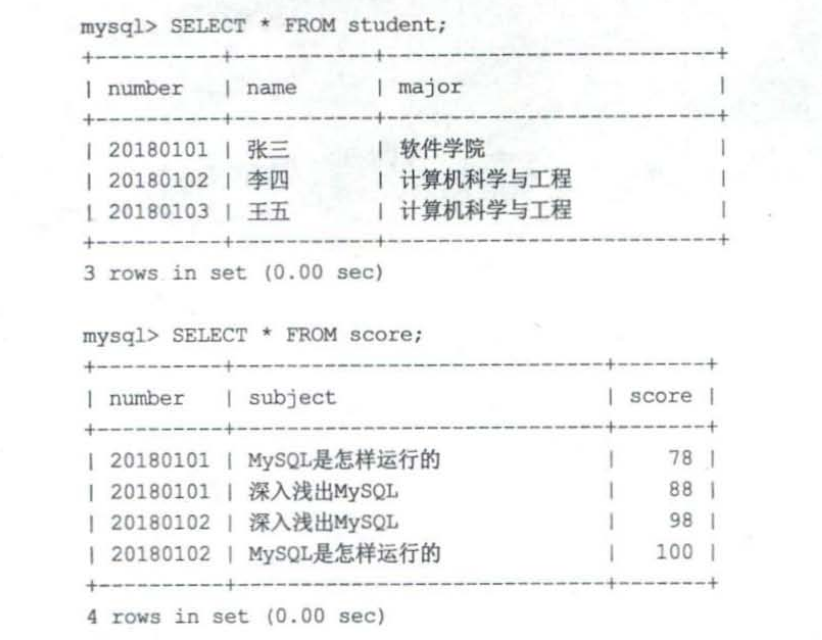
我们可以看到王五虽然在驱动表中,但是最后的结果集中并没有王五这条数据。这种属于内连接

- 内连接:若驱动表的记录在被驱动表中找不到匹配的记录,则该记录不会加到最后的结果集中
- 外连接:即使驱动表的记录在被驱动表中没有匹配的记录,仍然需要加到结果集中
- 左外连接:选取左侧的表为驱动表
- 右外连接:选取右侧的表为驱动表
对于外连接来说:Where子句的过滤条件,凡是不符合where子句的过滤条件的记录都不会加入到最后的结果集中,on子句的过滤条件,对于外连接的驱动表来说,如果无法在被驱动表中找到匹配on子句过滤条件的记录,那么该驱动表记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NUll填充。
对于内连接来说:where和on子句是等价的,凡是不符合过滤条件的记录都不会加入到最后的结果集中。
内外连接的语法
左(外)连接的语法
SELECT * FROM t1 LEFT[OUTER] JOIN t2 [ON连接条件] [WHERE普通过滤条件];
右(外)连接的语法
SELECT * FROM t1 RIGHT[OUTER] JOIN t2 [ON连接条件] [WHERE普通过滤条件];
内连接的语法
SELECT * FROM t1[INNER I CROSS]JOIN t2 [ON连接条件] [WHERE普通过滤条件];
SELECT FROM t1 JOIN t2;
SELECT FROM t1 CROSS JOIN t2;
SELECT FROM t1,t2
连接的原理
步骤1.选取驱动表,使用与驱动表相关的过滤条件,选取代价最低的单表访问方法来执行对驱动表的单表查询。
步骤2.对步骤1中查询驱动表得到的结果集中的每一条记录,都分别到被驱动表中查找匹配的记录。
eq_ref
在单表中使用主键值或者唯一二级索引列的值进行等值查找的方式称为cost,而在连接查询中对被驱动表的主键或者不允许存储NULL值的唯一二级索引进行等值查找使用的访问方法就称为eq_ref。(唯一主键值或者不允许存储NULL的唯一二级索引是on连接条件)
左连接和内连接在关联字段上驱动表创建索引好还是被驱动表建立索引参考文章
https://blog.csdn.net/qq_41714995/article/details/130207182?spm=1001.2014.3001.5501
在左连接查询中优先给右表建立索引
mysql中表关联的算法
在被驱动表的连接字段没有索引的情况下mysql才会使用这些关联算法进行表连接。
嵌套循环连接 Nested-Loop Join(NLJ)
假设t1表数据是100,t2表数据是10000条
select * from t1 left join t2 on t1.name=t2.name;
- 会先从表t1里拿出第一条记录row1,完了再用row1遍历表t2里的每一条记录,来寻找是否name字段是否相等,以便输出。然后循环这个过程,直到t1表里的所有的记录都取出。
- 在整个过程中
- t1表遍历了1遍。t2表遍历了100*1遍。即每层t1表中取出1条记录,都要遍历一遍t2表。
- 因为这些文件都是在磁盘上的。想想在遍历t2表100遍过程中得有多少次IO操作呀。
- 整个过程跟我们平时写程序的双重for循环本质是一样的。但是我们程序写的双重for循环是基于内存得,而mysql中这些却是基于磁盘的,需要将文件从磁盘调用内存,这样双重for循环,内表需要反复调入内存。
- 假设将表t2。全部调入内存需要10次IO。即每次调入1000条记录。则在t2表的100次遍历过程中需要调用IO次数为 10*100=1000次IO。
块嵌套循环连接 Block Nested-Loop Join(BNLJ)
- 基于嵌套循环查询的问题,mysql进行了优化,采用块嵌套循环连接。
- 它多了一块内存缓冲区join buffer。
- 在这个过程中,不再是每次从t1表中取1条记录。而是在开始时用内存缓冲区join buffer将t1表全部装入内存,每次取t2表的1000条记录调入内存。然后,让t1表与t2表在内存的这一部分(t2表在内存的这一部分作为外层循环,t1表作为内层循环)通过双重for循环进行匹配,然后循环这个过程,直到t2表的10000条数据都调入内存一次(即需要十次IO调入)。
- 在整个过程中
- t1表遍历了1*10000遍,t2表遍历了1遍。再结合表的大小,其实匹配的总的次数是一样的。
- 但是变化的是IO次数。在整个过程中,t1表一开始调入内存,需要一次IO。而t2表也只是将表调入内存一次,需要10次IO。IO的次数是少了两个量级。
第12 章 谁最便宜就选谁–基于成本的优化
Mysql的执行成本是由两个方面组成的。
IO成本:我们的表经常使用的MyISAM、InnoDB存储引擎都是将数据和索引存储到磁盘上。当查询表中的记录时,需要先把数据或者索引加载到内存中,然后再进行操作。这个从磁盘到内存的加载过程损耗的时间称为I/O成本。
CPU成本:读取记录以及检测记录是否满足对应的搜索条件、对结果集进行排序等这些操作损耗的时间称为CPU成本。
InnoDB存储引擎来说,页是内存和磁盘之间进行交互的基本单位,Mysql规定:读取一个页面花费的成本默认为1.0,读取以及检测一条记录是否符合搜索条件的成本为0.2。
单表查询的成本
- 我们向上面这个表插入1000条数据。
CREATE TABLE single_table(
id INT NOT NULL AUTO INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY uk_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1,key_part2,key_part3)
Engine=InnoDB CHARSET=utf8;
)
进行如下查询
SELECT * FROM single_table WHERE
keyl IN ('a','b','c')AND
key2>10 AND key2<1000 AND
key3>key2 AND
key_part1 LIKE'号hello号' AND
common field = '123';
基于成本的优化步骤
- 根据搜索条件,找出所有可能使用的索引
- 计算全表扫描的代价
- 计算使用不同索引执行查询的代价(需要考虑索引是否合并)
- 对比各种执行方案的代价,找出成本最低的那个方案
全表扫描的代价
将聚簇索引对应的页面加载到内存中,然后再检测记录是否符合搜索条件,在计算全表扫描的代价时需要两个信息:(1)聚簇索引占用的页面数(2)该表中的记录数。这两个信息可以通过下面的sql语句获得:
SHOW TABLE STATUS LIKE 'dept_tbl'
- Rows:表示表中的记录数,比如为9693
- Data_length:表占用的存储空间的字节数,聚簇索引的页面数量*每个页面的大小==>聚簇索引的页面数=Data_length量/16/1024,比如为97
全表扫描的代价:97 * 1 + 9693 * 0.2
计算使用不同索引执行查询的代价
对于使用二级索引+回表方式执行的查询,MySQL在计算这种查询的成本时,依赖于两方面的数据:扫描区间数量和需要回表的记录数。
- 无论某个扫描区间的二级索引到底占用了多少页面,都认为
扫描区间的二级索引付出的IO成本为1 * 1.0=1,一个单点扫描区间付出的IO成本为1 * 1.0,比如key1 IN(‘a’,‘b’,'c,)付出的IO成本为3 * 1.0 需要回表的IO成本:查询优化器需要计算二级索引的某个扫描区间到底包含多少条记录(具体计算方法不需要掌握)比如扫描区间共有95条记录。- 读取这95条二级索引记录需要付出的cpu成本是95 * 0.2
- 根据这些主键值进行回表
- IO成本为95*1.0
- CPU成本为 95*0.2
所以上面总的成本为95 * 1.0 + 1 * 1.0 + 95 * 0.2 + 95 * 0.2
基于索引统计数据的成本计算
index dive MySOL的大叔把这种通过直接访问索引对应的B+树来计算某个扫描区间内对应的索引记录条数的方式称为index dive。如果单点扫描区间非常多,那么index dive的成本消耗非常大。Mysql提供了一个系统变量eq_range_index_dive_limit,如果超过eq_range_index_dive_limit将不会使用index dive的方式计算扫描区间对应的索引记录,而是使用基于索引统计数据的成本计算。具体方法如下:
- 使用SHOW TABLE STATUS语句显示出来的Rows值:表示一个表中有多少条记录
- 使用SHOW INDEX语句显示出来的Cardinality属性,这个属性表示该列没有重复的值。
- Rows值是9693,keyl列的Cardinality值是968,所以可以计算单个值的平均重复次数:9,693÷968≈10条
- 假设in对应2000个扫描区间,那么对应的索引记录数为10*2000
连接查询的成本
条件过滤
在MySQL中连接查询采用的是嵌套循环连接算法,驱动表会被访问一次,被驱动表可能会被访问多次。所以它的查询成本由两部分组成:
- 单次查询驱动表的成本
- 多次查询被驱动表的成本:扇出值*单次访问被驱动表的成本
计算驱动表扇出值可能需要猜测:
- 如果使用全表扫描方式执行单表查询
- 使用索引执行单表查询,但是还有其他搜索条件
举例如下:
- common field不是索引需要全表扫描,所以需要计算扇出值
SELECT * FROM S1 INNER JOIN S2 WHERE s1.common field > 'xyz';
- 虽然key2可以使用索引,但是common field不是索引,所以需要猜测扇出值
SELECT * FROM S1 INNER JOIN s2
WHERE s1.key2>10 AND s1.key2<1000 AND
s1.common field>'xyz';
两表连接的成本分析
下面举例说明
SELECT * FROM s1 INNER JOIN S2
ON s1.key1 = s2.common_field
WHERE s1.key2 > 10 AND s1.key2<1000 AND
s2.key2>1000 AND s2.key2<2000;
假设使用s1作为驱动表
- 驱动表单次扫描成本: s1.key2 > 10 AND s1.key2<1000 使用uk_key2或者全表扫描两种方式找出最低的
- 被驱动表单次扫描成本:s2.common field=常数和s2.key2>1000ANDs2.key2<2000,s2.common field=常数不会使用使用索引,s2.key2>1000ANDs2.key2<2000使用uk_key2
- 所以,此时使用sl作为驱动表的成本如下:使用uk_key2访问s1的成本+s1的扇出值×使用uk_key2访问s2的成本
优化的重点:
- 尽量减少驱动表的扇出
- 访问被驱动表的成本要尽量低(被驱动表的连接列最好建立索引,这样就可以使用ref访问方法来降低被驱动表的访问成本了,如果可以被驱动表的连接列最好是该表的主键或者唯一二级索引列)
调节成本常数
我们可以通过手动修改mysql数据库下engine_cost表或者server_cost表中的某些成本常数,
更精确地控制在生成执行计划时的成本计算过程。
查看索引信息
show index from 表名

第13章 兵马未动,粮草先行–InnoDB统计数据是如何收集的
略
第14章 基于规则的优化(内含子查询优化二三事)
MySQL 竭尽全力地把这些很糟糕的语句转换成某种可以高效执行的形式,这个过程也可以称为查询重写。
条件简化
移除不必要的括号
SELECT * FROM (t1,(t2,t3)) WHERE t1.a = t2.a AND t2.b = t3.b;
SELECT * FROM t1,t2,t3 WHERE t1.a = t2.a AND t2.b = t3.b;
常量传递
a= 5 AND b>a
a=5 AND b>5
移除没用的条件
(a<1 AND b=b) or (a=6 OR 5!=5)
(a<1 AND true) or (a=6 OR false)
表达式计算,这些内容都很简单,不再赘述。
a=6+1;
a=7
//下面的无法进行化简
ABS(a)>5
HAVING子句和WHERE子句的合并
如果查询语句中没有出现诸如SUM、MAX这样的聚集函数以及GROUP BY子句,查询优化器就把HAVING子句和WHERE子句合并起来。
常量表查询
常量表
- 查询的表中一条记录都没有,或者只有一条记录。
- 使用主键等值匹配或者唯一二级索引列等值匹配作为搜索条件来查询某个表
查询优化器在分析一个查询语句时,首先执行常量表查询,然后把查询中涉及该表的条件全部替换成常数,最后再分析其余表的查询成本。
比如下面的sql查询
SELECT * FROM table INNER JOIN table2
ON table1.column1 = table2.column2
WHERE table1.primary_key = 1;
SELECT table1记录各个字段的常量值,table2.* FROM table1 INNER JOIN table2
on table1表column1列的常量值=table2.column2
外连接消除
内连接可能通过优化表的连接顺序来降低整体的查询成本,而外连接却无法优化表的连接顺序。被驱动表的WHERE子句符合空值拒绝的条件后,外连接和内连接可以相互转换。这种转换带来的好处就是优化器可以通过评估表的不同连接顺序的成本,选出成本最低的连接顺序来执行查询。
子查询优化
子查询语法
子查询可以放在select,from,where、on中
子查询的分类
- 按照结果集划分:
标量子查询(那些只返回一个单一值的子查询称为标量子查询),行子查询顾名思义,就是返回一条记录的子查询,不过这条记录需要包含多个列,列子查询就是查询出一个列的数据,不过这个列的数据需要包含多条记录,表子查询就是子查询的结果既包含很多条记录,又包含很多个列。 - 按与外层查询的关系来区分子查询:
不相关子查询子查询可以单独运行出结果,而不依赖于外层查询的值
SELECT * FROM t1 WHERE m1 in (SELECT m2 FROM t2 WHERE t2.column1 = 'a')相关子查询子查询的执行需要依赖于外层查询的值,我们就可以把这个子查询称为相关子查询。
SELECT * FROM t1 WHERE m1 in (SELECT m2 FROM t2 WHERE t2.column1 = t1.column1)
子查询在布尔表达式中的使用
- 使用=、>、<、>=、<=、◇、!=、<=>作为布尔表达式的操作符,需要注意的是子查询只能是
标量子查询或者行子查询。
select * from t1 where (m1,n1) = (select m2,n2 from t2 limit 1) ;
- [NOT]IN/ANY/SOME/ALL子查询
// >Any 相当于 >(SELECT min(m2) FROM t2)
// =Any 相当于 in (SELECT m2 FROM t2)
// >ALL 相当于 >(SELECT max(m2) FROM t2)
SELECT * FROM t1 WHERE m1 > ANY(SELECT m2 FROM t2);
SELECT * FROM t1 WHERE m1> ALL(SELECT m2 FROM t2);
-
IN或者NOT IN
-
EXSISTS 子查询
//如果子查询的结果不是空的,那么where条件则为true返回t1表的全部结果
SELECT * FROM t1 WHERE EXSISTS (SELECT 1 FROM t2);
子查询的注意事项(不需要背诵,用到时看一下即可)
- 如果子查询结果集中有多个列或者多个行 则不允许放在SELECT子句中
- 对于[NOT]IN/ANY/SOME/ALL子查询来说,子查询中不允许有LMIT语句。
- 在子查询中使用ORDER BY子句、DISTINCT子句,以及没有聚集函数和HAVING子句的GROUP BY子句是毫无意义的
- 不允许在一条语句中增删改某个表的记录时,同时还对该表进行子查询
IN子查询优化_子查询是怎么运行的
- 标量子查询、行子查询的执行方式
- 相关
1、单独执行子查询SELECT * FROM s1 WHERE key1 = (SLECT common_filed FROM s2 WEHRE key3 = 'a' LIMIT 1)
2、然后将子查询得到的结果当作外层查询的参数,再执行外层查询- 不相关
1、先从外层查询中获取一条记录SELECT * FROM s1 WHERE key1 = (SLECT common_filed FROM s2 WEHRE s1.key3 = s2.key3 LIMIT 1);
2、对应执行子查询
3、用子查询的查询结果检测外层查询WHERE子句的条件是否成立
4、跳到步骤1,直到外层查询中获取不到记录为止。 - IN子查询优化
物化表: 将子查询的结果集写入一个临时表中(临时表的记录会被去重:1、子查询的结果集中只有一个列那么建立主键索引2、子查询的结果集中有多个列为临时表的所有列建立联合主键或者联合唯一索引)小的物化表是基于内存的的物化表有哈希索引,大的物化表基于磁盘的物化表有B+树索引将物化表转为内连接将子查询转为半连接:子查询不能完全和内连接等价。如果SELECT coomon_field FROM s2 WHERE key3 = 'a'没有重复值,那么子查询等价于内连接,否则内连接会比子查询结果集更多(s1表中的某条记录可能在s2表中有多条匹配的记录,所以该条记录可能多次被添加到最后的结果集中)。于是产生了半连接的概念。
半连接的实现SELECT * FROM s1 WHERE key1 IN (SELECT coomon_field FROM s2 WHERE key3 = 'a') SELECT s1.* FROM s1 INNER JOIN s2 on s1.key1 = s2.common_field WHERE s2.key3='a' - Table pullout(子查询中的表上拉)SELECT * FROM s1 WHERE key1 IN (SELECT key2 FROM s2 WHERE key3 = ‘a’) key2 是s2 表的主键或者唯一索引
- Duplicate Weedout(重复值消除)我们可以建立一个临时表,CREATE TABLE tmp id INT PRIMARY KEY);每当某条s1表中的记录要加入结果集时,就首先把这条记录的d值加入到这个临时表中。如果添加成功,则说明之前这条s1表中的记录并没有加入。
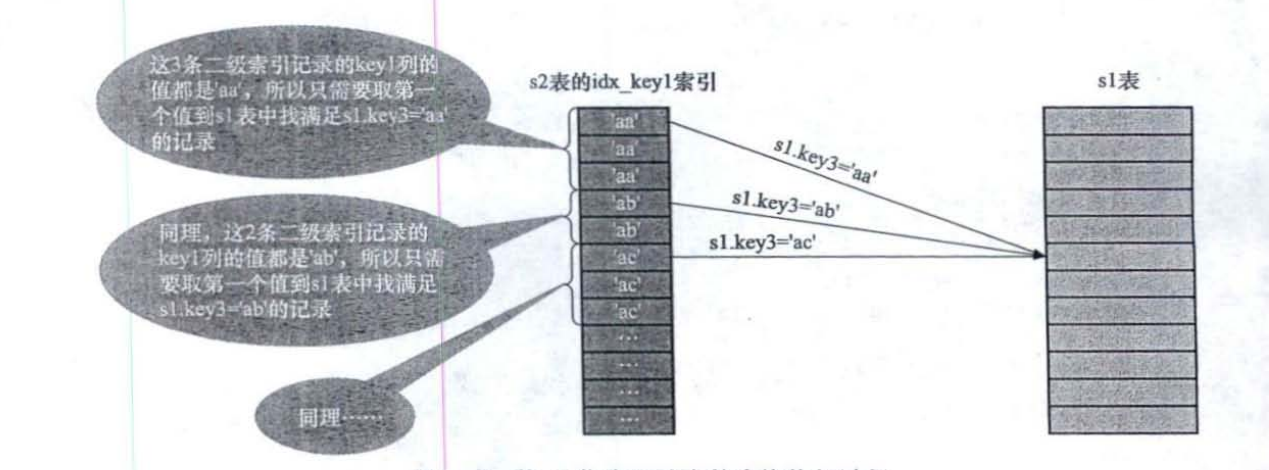
- LooseScan(松散扫描)在s2表的idx key1索引中,值为’aa’的二级索引记录一共有3条只需要取第一条的值到s1表中查找s1.key3=aa’的记录,这种虽然是扫描索引,但只取键值相同的第一条记录去执行匹配的操作方式叫做松散扫描。
SELECT * FROM s1 WHERE key3 IN (SELECT key1 FROM s2 WHERE key1>'a' AND key1<'b')
- Semi-join Materialization(半连接物化):先把外层查询的IN子句中的不相关子查询进行物化,然后再将外层查询的表与物化表进行连接。物化表没有重复值可以直接将子查询转为连接查询。
- FirstMatch(首次匹配):和相关子查询一样
IN子查询优化_半连接的适用条件
- 该子查询必须是与N操作符组成的布尔表达式,并且在外层查询的WHERE或者ON子句中出现:
- 外层查询也可以有其他的搜索条件,只不过必须使用AND操作符与N子查询的搜索条件连接起来:
- 该子查询必须是一个单一的查询,不能是由UNION连接起来的若干个查询:
- 该子查询不能包含GROUP BY、HAVING语句或者聚集函数。
IN子查询优化_不能转为半连接的子查询的优化
如果IN子查询不符合转换为半连接的条件,那么查询优化器会从下面两种策略中找出一
种成本更低的方式来执行子查询:
- 对于不相关的子查询,可以尝试把它们物化之后再参与查询。请注意,这里将子查询物化之后不能转为与外层查询的表的连接,只能是先扫描s1表,然后针对s1表的某条记录来判断该记录的key1值是否在物化表中
SELECT * FROM s1
WHERE key1 NOT IN (SELECT common_field FROM s2 WHERE key3 = 'a')
- 无论子查询是相关的还是不相关的,只要in子查询放在WHERE或者OR子句中,都可以把IN子查询尝试转为EXISTS子查询。转换方法如下:
outer_expr IN (SELECT inner_expr FROM ..WHERE subquery_where)
EXISTS (SELECT inner_expr FROM ..WHERE subquery_where AND outer_expr=inner_expr)
例如下面的sql将in转为exsists之后可以使用s2的key3索引
SELECT * FROM s1
WHERE key1 IN (SELECT key3 FROM s2 WHERE s1.common_field = s2.common_field)
SELECT * FROM s1
WHERE EXSISTS (SELECT key3 FROM s2 WHERE s1.common_field = s2.common_field AND s2.key3 = s1.key1)
Any/ALL子查询优化
[NOT]EXISTS子查询的执行
- 不相关子查询:可以先执行子查询。
- 相关子查询:和in类型中标量子查询和行子查询(不相关)相同
派生表的优化
SELECT * FROM(
SELECT id AS d_id,key3 AS d_key3 FROM s2 WHERE key1 = 'a'
)AS derived_s1 WHERE d_key3='a'
- 将派生表物化(延迟物化:在查询中真正使用到派生表时才会去尝试物化派生表,而不是在执行查询之前就先把派生表物化)
- 将派生表和外层表查询合并
SELECT * FROM(
SELECT * FROM s1 WHERE key1 = 'a'
)AS derived_s1 INNER JOIN s2
ON derived_s1.key1 = s2.key1
WHERE s2.key2=1;
SELECT * FROM s1 AS INNER JOIN s2
ON derived_s1.key1 = s2.key1
WHERE s2.key2=1 AND s1.key1='a'
但是如果派生表中有下面这些函数或者语句时,就不能与外层查询合并:
- 聚集函数
- DISTINCT
- GROUP BY
- HAVING
- LIMIT
- UNION或者UNION ALL
- 派生表对应的select子句中有另一个子查询
第15章 查询优化的百科全书–Explain详解
本章的内容就是为了帮助大家看懂EXPLAIN语句的各个输出项都是干嘛使的,从而可以
有针对性地提升查询语句的性能。


下面我们逐一介绍上面介绍的每一个属性
id
查询语句中每出现一个SELECT关键字,设计MySQL的大叔就会为它分配一个唯一的id值,这个id值就是EXPLAIN输出的第一列。
EXPLAIN SELECT * from table1

在连接查询的执行计划中,每个表都会对应一条记录,这些记录的d列的值是相同的:出现在前面的表表示驱动表,出现在后面的表表示被驱动表。
EXPLAIN SELECT s1.* FROM s1 INNER JOIN s2
ON s1.key2 = s2.key2
WHERE s2.key3 = 'a'
 但是在下面这两种情况下, 一条查询语句中会出现多个 SELECT关键字,那么可能同时出现多个id
但是在下面这两种情况下, 一条查询语句中会出现多个 SELECT关键字,那么可能同时出现多个id
- 查询中包含子查询的情况,但是需要注意的是子查询可能转为连接查询,此时id只有一个举例如下:
EXPLAIN
SELECT s1.* FROM s1 WHERE s1.key2 in (SELECT key2 FROM s2 WHERE key3 = 'a')

- 查询中包含UNION子句的情况
EXPLAIN
SELECT * FROM table1
UNION
SELECT * FROM table2

UNION子句去重, MySQL使用的是内部临时表<unionl,2>。与UNION比起来,UNIONALL就不需要对最终的结果集进行去重,所以也就不需要使用临时表。
SELECT_TYPE
SIMPLE:查询语句中不包含UNION或者子查询的查询都算作SIMPLE类型

PRIMARY对于包含UNION、UNIONALL或者子查询的大查询来说,它是由几个小查询组成的;其中最左边那个查询的select_type值就是PRIMARY

UNION对于包含UNION、UNIONALL,除了最左边那个查询的select_type值就是PRIMARY,其他的都是UNION。
UNION RESULT使用UNION进行查询时,查重使用的临时表select_type就是UNION RESULT。
SUBQUERY:如果包含子查询的查询语句不能够转为对应的半连接形式,并且该子查询是不相关子查询,而且查询优化器决定采用将该子查询物化的方案来执行该子查询时,该子查询的第一个SELECT关键字代表的那个查询的select_type就是SUBQUERY
DEPENDENT SUBQUERY:如果包含子查询的查询语句不能够转为对应的半连接形式,并且该子查询被查询优化器转换为相关子查询的形式,则该子查询的第一个SELECT关键字代表的那个查询的select_type就是DEPENDENT SUBQUERY。
DEPENDENT UNION:在包含UNION或者UNIONALL的大查询中,如果各个小查询都依赖于外层查询,则除了最左边的那个小查询之外,其余小查询的select_type的值就是DEPENDENT UNION。
DERIVED:在包含派生表的查询中,如果是以物化派生表的方式执行查询,则派生表对应的子查询的select_type就是DERIVED。
MATERIALIZED:当查询优化器在执行包含子查询的语句时,选择将子查询物化之后与外层查询进行连接查询,该子查询对应的select_type属性就是MATERIALIZED。
table
下面对于几种特殊的table进行总结
EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2;
可以看到id=NULL,table为<union1,2>表示临时表,需要进行union去重。

EXPLAIN SELECT* FROM(SELECT key1,count(*) as c FROM s1 GROUP BY key1) AS derived_s1 WHERE c>1;
可以看到table显示的是,表示该查询是针对将派生表物化之后进行查询的

EXPLAIN SELECT * FROM s1 key1 IN (SELECT key1 FROM s2)
第二条记录的table列的值是,说明该表其实就是执行计划中id为2对应的子查询执行之后产生的物化表;然后再将s1和该物化表进行连接查询。

type
system当表中只有一条记录并且该表使用的存储引擎(比如MyISAM、MEMORY)的统计数据是精确的,那么对该表的访问方法就是system
const这个在前文唠叨过,当我们根据主键或者唯一二级索引列与常数进行等值匹配时,对单表的访问方法就是const
eq_ref:执行连接查询时,如果被驱动表是通过主键或者不允许存储NULL值的唯一二级索引列等值匹配的方式进行访问的(如果该主键或者不允许存储NULL值的唯二级索引是联合索引,则所有的索引列都必须进行等值比较),则对该被驱动表的访问方法就是eq_ref。
ref:当通过普通的二级索引列与常量进行等值匹配的方式来查询某个表时,如果是执行连接查询,被驱动表是通过某个普通的二级索引列进行访问的。
fulltext:全文索引,这里不展开讲解
ref_or_null:当对普通二级索引列进行等值匹配且该索引列的值也可以是NULL值时
unique_subquery:如果查询优化器决定将IN子查询转换为EXISTS子查询,而且子查询在转换之后可以使用主键或者不允许存储NULL值的唯一二级索引进行等值匹配,那么该子查询执行计划的type列的值就是unique_subquery。
index_subquery:index_subquery与unique_subquery类似,只不过在访问子查询中的表时使用的是普通的索引
range:如果使用索引获取某些单点扫描区间的记录,那么就可能使用到range访问方法。
EXPLAIN SELECT * FROM s1 WHERE key1 IN ('a','b','c');
EXPLAIN SELECT * FROM s1 WHERE key1>'a' AND key1<'b';
index:当可以使用索引覆盖,但需要扫描全部的索引记录时,该表的访问方法就是index;当我们需要执行全表扫描,并且需要对主键进行排序时,此时的type列的值也是index
ALL:全表扫描
possible_key和key
possible_key表示执行表执行单表查询时可能用到的索引有哪些,key列表示实际用到的索引有哪些。不过有一点比较特别,就是在使用index访问方法查询某个表时,possible_keys列是空的,而key列展示的是实际使用到的索引。
key_len

- 该列实际数据最多占用的存储空间的长度:key1列的类型是VARCHAR(100),使用的字符集是utf8,所以该列的实际数据最多占用的存储空间长度就是300字节。
- 如果该列可以存储NULL值,再加1字节。
- 对于使用变长类型的列来说,还需要再原来的基础上增加2字节。


ref
当访问方法是const、eq_ref、ref、ref_or_null、unique_subquery、index_subquery中的其中一个时,ref列展示的就是与索引列进行等值匹配的东西是啥,比如只是一个常数或者是某个列或者是一个函数。

rows
行计划的rows列就代表预计扫描的索引记录
EXPLAIN SELECT * FROM students WHERE id>='1' AND id <='3'

EXPLAIN SELECT * FROM students WHERE id='1'

filtered
- 如果使用全表扫描的方式来执行单表查询,那么计算驱动表扇出时需要估计出满足全部搜索条件的记录到底有多少条
- 如果使用索引来执行单表扫描,那么计算驱动表扇出时需要估计出在满足形成索引扫描区间的搜索条件外,还满足其他搜索条件的记录有多少条
我们更关注在连接查询中驱动表对应的执行计划的filtered值,比如下面的查询中s1为驱动表,我们可以得到s1的扇出值为9688*10%=968,说明被驱动表需要执行大月968次查询。

Extra
Extr列是用来说明一些额外信息的,我们可以通过这些额外信息来更准确地理解MySQL到底如何执行给定的查询语句。
No tables used:当查询语句中没有FROM子句时将会提示该额外信息

Impossible WHERE:查询语句的WHERE子句永远为FALSE时将会提示该额外信息。

No matching min/max row:当查询列表处有MN或者MAX聚集函数,但是并没有记录符合WHERE子句中的搜索条件时,将会提示该额外信息

Using index:使用覆盖索引执行查询时,Extra列将会提示该额外信息

Using index condition如果在查询语句的执行过程中使用索引条件下推特性,在Extra列中将会显示Using index condition。下面的sql的扫描空间为key1>‘z’。正常来说存储引擎层位到key1>'z’的第一条二级索引记录之后,根据主键进行回表判断其他条件是否满足,如果满足则发送给客户端,重复上面过程直到遍历完整个(‘z’,+无穷)。有了索引下推特性之后,存储引擎定位到k>'z’的记录之后还会判断是否符合key1 LIKE ‘%a’,如果符合才会回表。
SELECT * FROM s1 WHERE key1>'z'AND key1 LIKE '%b';

Using Where:Using where:当某个搜索条件需要在server层进行判断时,在Extra列中会提示Using Where。
Using join buffer (Block Nested Loop):在连接查询的执行过程中,当被驱动表不能有效地利用索引加快访问速度时,MySQL一般会为其分配一块名为连接缓冲区(Join Buffer)的内存块来加快查询速度;也就是使用基于块的嵌套循环算法来执行连接查询
Using intersect()Using union()和Using sort union():如果执行计划出现了上述提示,说明上面使用了索引合并。

Zero limit:当LMIT子句的参数为0时,表示压根儿不打算从表中读出任何记录,此时将会提示该额外信息。

Using filesort:这种在内存中或者磁盘中进行排序的方式统称为文件排序(filesort)。有些排序可以利用索引,有些排序只能利用filesort。
Using temporary:我们在执行许多包含DISTINCT、GROUP BY、UNION等子句的查询过程中,如果不能有效利用索引来完成查询,MySQL很有可能通过建立内部的临时表来执行查询。MySQL会在包含GROUP BY子句的查询中默认添加ORDER BY子句,也就是说SELECT common_field,count( * ) AS amount FROM s1 GROUP BY common_field 等价于 SELECT common_field,count( * ) AS amount FROM s1 GROUP BY common_field ORDER BY common_field。如果我们不想为GROUP BY子句查询进行排序需要显示的写上OREDER BY NULL。
Start temporary,End temporary:子查询时,查询优化器会尝试将IN子查询转为半连接,而半连接又有多种执行策略,当执行策略为Duplicate Weedout,驱动表查询执行计划的Extra列将显示Start temporary提示,被驱动表查询执行计划的Extra列将显示End temporary提示
LooseScan:在将IN子查询转为半连接时,如果采用的是LooseScan执行策略,则驱动表执行计划的Extra列就显示LooseScan提示
FirstMatch(tbl name):在将IN子查询转为半连接时,如果采用的是FirstMatch执行策略,则被驱动表执行计划的Extra列就显示FirstMatch(tbl name)提示
JSON格式的执行计划
在EXPLAIN单词和真正的查询语句中间加上FORMAT=JSON,可以得到JOSN格式的执行计划。
Extended EXPLAIN
在使用EXPLAIN语句查看了某个查询的执行计划后,紧接着还可以使用SHOW WARNINGS语句来查看与这个查询的执行计划有关的扩展信息,SHOW WARNINGS展示出来的信息有3个字段,分别是Level、.Code和Message。当Code值为1,003时,Message字段展示的信息类似于查询优化器将查询语句重写后的语句
第16章 神兵利器–optimizer trace的神奇功效
optimizer trace可以让用户方便地查看优化器生成执行计划的整个过程。这个功能的开启与关闭由系统变量optimizer trace来决定。
使用optimizer trace的完整步骤如下:
set optimizer_trace = 'enabled=on'
- 输入自己的查询语句
SELECT ...
- 从OPTIMIZER_TRACE表中查看上一个查询的优化过程
SELECT * FROM information_schema.OPTIMIZER_TRACE
-停止查看语句的优化过程时,将optimizer trace功能关闭
set optimizer_trace='enabled=off'
优化过程分为三个阶段:
- prepare阶段
- optimize阶段
- execute阶段
对于单表查询来说主要关注的是optimize阶段的rows_estimation过程,这个过程主要分析了针对单表查询的各种执行方案的成本,对于多表连接查询来说,我们更多的关注的是considered_execution_plans过程,这个过程中会写明各种不同的表连接顺序所对应的成本。
第17章 调节磁盘和cpu的矛盾–InnoDB的buffer pool
即使只需要访问一个页的一条记录,也需要先把整个页的数据加载到内存中。将整个页加载到内存中后就可以进行读写访问了,而且在读写访问之后并不着急把该页对应的内存空间释放掉,而是将其缓存起来,这样将来有请求再次访问该页面时,就可以省下磁盘/O的开销了。
InnoDB的Buffer Pool
什么是Buffer Pool
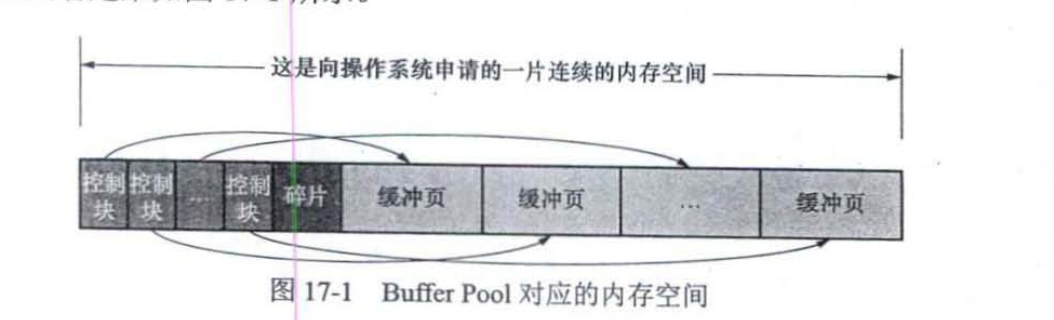
MySQL服务器启动时就向操作系统申请了一片连续的内存,他们给这片内存起了个名字一Buffer Pool(缓冲池)。可以在启动服务器的时候配置innodb buffer pool size启动选项。
Buffer Pool的内部组成
Buffer Pool由控制块和缓冲页组成就像下面这样,我们设置的innodb buffer pool size并不包含控制块的内存,所以整个Buffer Pool更大。
free链表的管理
free链表:我们可以把所有空闲的缓冲页对应的控制块作为一个节点放到一个链表中,这个链表也可以称为free链表(或者说空闲链表)
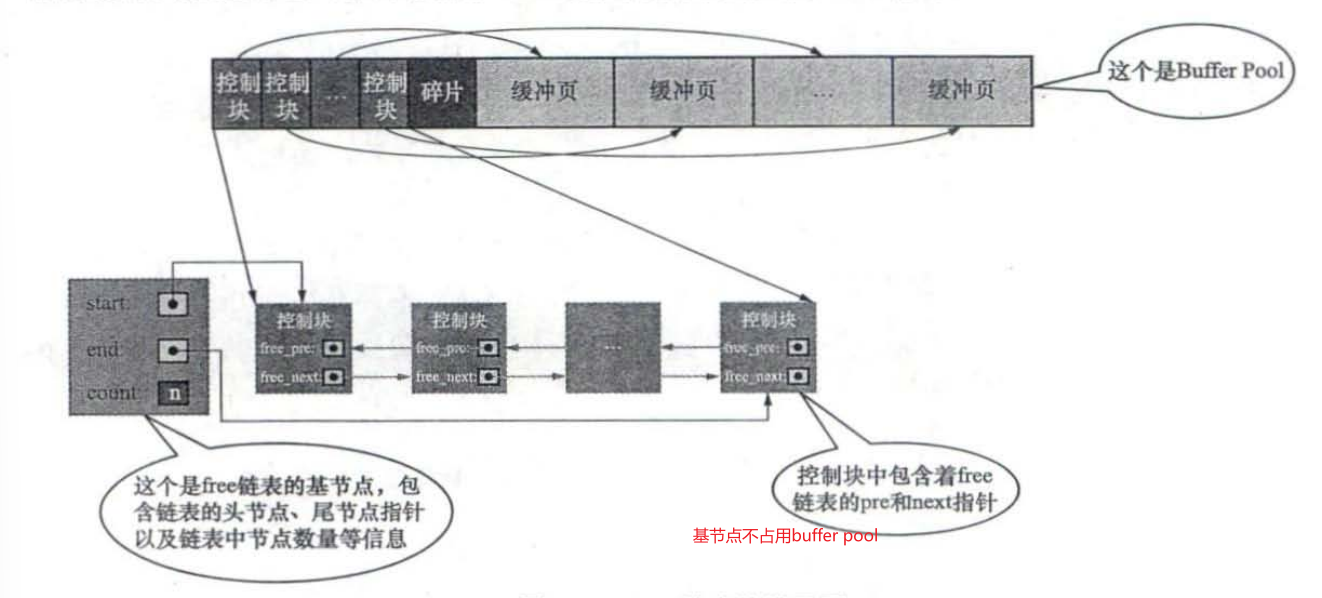
当需要从磁盘中加载一个页到Buffer Pool中时,就从free链表中取一个空闲的缓冲页对应的控制块,并且把该缓冲页对应的控制块的信息填上(就是该页所在的表空间、页号之类的信息),然后把该缓冲页对应的free链表节点(也就是对应的控制块)从链表中移除,表示该缓冲页已经被使用了。
缓冲页的hash处理
缓冲页的hash处理:用表空间号+页号作为key,用缓冲页控制块的地址作为vaue来创建一个哈希表。
在需要访问某个页的数据时,先从哈希表中根据表空间号+页号看看是否有对应的缓冲页。如果有,直接使用该缓冲页就好:如果没有,就从free链表中选一个空闲的缓冲页,然
后把磁盘中对应的页加载到该缓冲页的位置。
flush链表的管理
脏页:如果我们修改了Buffer Pool中某个缓冲页的数据,它就与磁盘上的页不一致了,这样的缓冲页也称为脏页(dirty page)。
每次修改缓冲页后,我们并不着急立即把修改刷新到磁盘上,而是在未来的某个时间点进行刷新。
flush链表:我们创建一个存储脏页的链表,凡是被修改过的缓冲页对应的控制块都会作为一个节点加入到这个链表中。
LRU链表的管理
简单的LRU链表:如果该页不在buffer pool 中,那么则将该页加载到buffer pool中,并且将控制块的信息放到LRU链表的头部,如果该页已经被加载到LRU中,那么将该页的控制块信息直接放在LRU链表的头部。
划分区域的LRU链表:由于预读和全表扫描的存在,有可能会将使用频率很高的页从Buffer Pool中淘汰掉。所以对于LRU链表进行改进,将LRU链表分成两节,两节的比例由系统变量innodb old blocks pct确定。
- 一部分存储使用频率非常高的缓冲页;这一部分链表也称为热数据,或者称为youg区域
- 另一部分存储使用频率不是很高的缓冲页:这一部分链表也称为冷数据,或者称为old
区域。
针对old和young区域进行下一步的优化:
- 针对预读的页面可能不进行后续访问的优化:当磁盘上的某个页面初次加载到Buffer Pool中的缓冲页时,该缓冲页对应的控制块会放到old区域的头部。
- 针对全表扫描时,短时间内访问大量使用频率非常低的页面的优化:首次加载时放到LRU链表的old区,后面访问时直接放在young的头部吗?不是的,在对某个处于old区域的缓冲页进行第一次访问时,就在它对应的控制块中记录下这个访间时间,如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该页面就不会从old区域移动到young区域的头部,否则将它移动到young区域的头部,这个间隔时间可以通过系统变量innnodb_old_blocks_time进行控制。
为什么要通过间隔时间,而不是记录访问次数,第二次访问时才将缓冲页放young区域?
每次去页面中读取一条记录时,都算是访问一次页面。而一个页面中可能会包含很多条记录,也就是说读取完某个页面的记录就相当于访问了这个页面好多次。但是读完一个页的时间花费非常少。
LRU进一步优化:young区域分为3/4和1/4,只有被访问的缓冲页位于young区域的后1/4时,才会被移动到LRU链表头部。
刷新脏页到磁盘
后台有专门的线程负责每隔一段时间就把脏页刷新到磁盘,这样可以不影响用户线程处
正常的请求。刷新方式主要有下面两种。
- 从LRU链表的冷数据中刷新一部分页面到磁盘
- 从flush链表中刷新一部分页面到磁盘。
- 如果后台线程刷新脏页的速度特别慢,导致用户线程准备加载一个磁盘页也到Buffer Pool中时没有可用的缓冲页,此时就会看是否存在可以直接释放掉的未修改的缓冲页。如果没有会将LRU链表尾部的脏页刷新到磁盘。
多个Buffer Pool实例
多线程环境下,访问Buffer Pool中的各种链表都需要加锁处理。在Buffer Pool特别大并且多线程并发访问量特别高的情况下,单一的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别大时,可以把它们拆分成若干个小的Buffer Pool(由系统变量innodb_buffer_pool_instances控制)每个Buffer Pool都称为一个实例。一个实例的所占用的内存空间的大小为:
innodb_buffer_pool_size / innodb_buffer_pool_instances
innodb_buffer_pool_chunk_size
不再一次性为某个Buffer Pool实例向操作系统申请一大片连续的内存空间,而是以一个chunk为单位向操作系统申请空间,一个Buffer Pool实例其实是由若干个chunk组成的。每一个chunk是一块连续的内存空间。正是因为发明了chunk的概念,我们在服务器运行期间调整Buffer Pool的大小时,就可以以chunk为单位来增加或者删除内存空间。通过innodb buffer pool_chunk size启动选项指定,在服务器运行过程中无法修改。
配置Buffer Pool时的注意事项
innodb buffer pool size必须是innodb buffer pool chunk size×innodb buffer pool instances的倍数(主要是想保证每一个Buffer Pool实例中包含的chunk数量相同)。
查看Buffer Pool的状态信息
SHOW ENGINE INNODB STATUS\G
第18章 从猫爷借钱说起–事务简介
ACID特性
原子性
现实世界中一个不可分割的操作却可能对应着数据库世界中若干条不同的操作,数据库中的一条操作也可能被分解成若干个步骤(比如先修改缓冲页,之后再刷新到磁盘等)。每个时间点都可能会发生错误, 如果在执行操作的过程中发生了错误,就把已经执行的操作恢复成没执行之前的样子。
隔离性
对于现实世界中状态转换对应的某些数据库操作来说,不仅要保证这些操作以原子方式执行完成,而且要保证其他的状态转换不会影响到本次状态转换,这个规则称为隔离性。
一致性
如何保证数据库中数据的一致性呢(就是符合所有现实世界的约束)?这其实是靠两方面
的努力。
- 数据库本身能为我们解决一部分一致性需求,例如主键,唯一索引,外键,还可以声明某个列为NOT NULL来拒绝NULL值的插入。
- 更多的一致性需求需要靠写业务代码的程序员自己保证。例如银行账户需要大于0,那么每次取钱的时候可以进行判断。
持久性
当把现实世界中的状态转换映射到数据库世界时,持久性意味着该次转换对应的数据库操作所修改的数据都应该在磁盘中保留下来,无论之后发生了什么事故,本次转换造成的影响都不应该丢失。
事务的概念
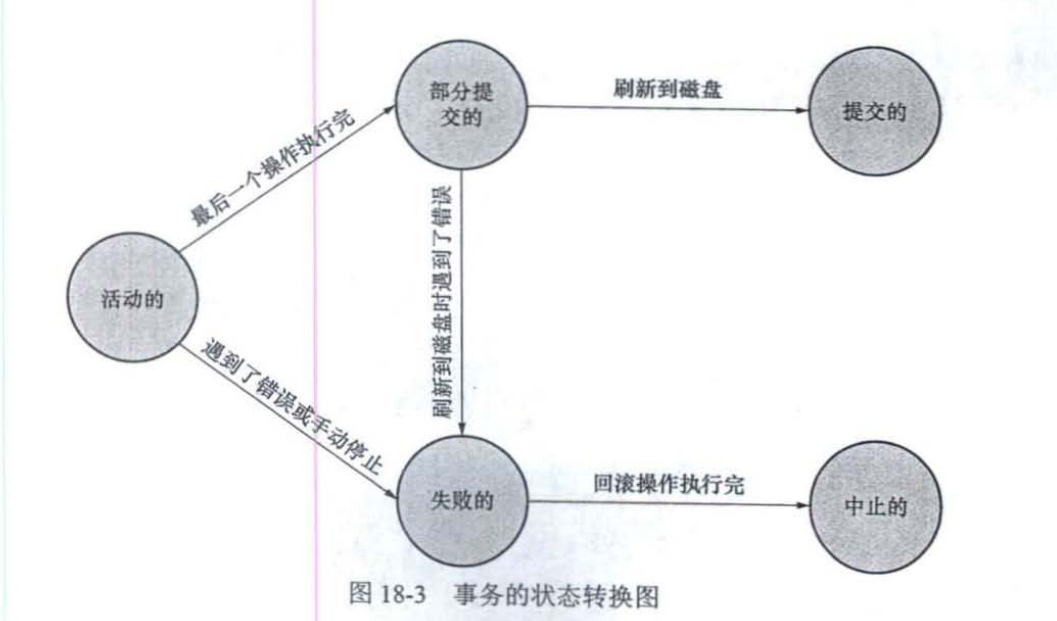
一个事务中会包含一个或者多个数据库操作,这些操作所执行的不同阶段把事务大致分为了下面的几个状态:
- 活动的(active):事务对应的数据库操作正在执行过程中时,我们就说该事务处于活动的状态。
- 部分提交的(partially committed):当事务中的最后一个操作执行完成,但由于操作都在内存中执行,所造成的影响并没有刷新到磁盘时,我们就说该事务处于部分提交的状态。
- 失败的(failed):活动的或者部分提交的出现了错误,我们就说该事务处于失败的状态。
- 中止的(aborted):要撤销失败事务对当前数据库造成的影响,即数据库进行回滚。
- 提交的(committed):当一个处于部分提交的状态的事务将修改过的数据都刷新到磁盘中之后,我们就可以说该事务处于提交的状态。
Mysql中事务的语法
开启事务
BEGIN
START TRANSACTION
- READ ONLY 表示当前事务的数据库操作只能读取数据,不能修改数据
- READ WRITE 表示当前事务的数据库操作既可以读取数据,又可以修改数据
- WITH CONSISTENT SNAPSHOT 启用一致性读
提交事务
COMMIT
手动终止事务
ROLLBACK
支持事务的存储引擎
在MySQL中,并不是所有的存储引擎都支持事务的功能,目前只有InnoDB和NDB存储引擎支持。该表使用的存储引擎不支持事务,那么对该表所做的修改将无法进行回滚。
自动提交
MySQL中有一个系统变量autocommit,用来自动提交事务,默认值为on。使用SET autocommit = OFF设置关闭自动提交,这样只有我们显示的写出COMMIT将事务提交掉或者显示的写出ROLLBACK将事务回滚掉。
SHOW VARIABLES LIKE 'autocommit'
隐式提交
我们关闭自动提交事务的功能,但是下面的操作会导致隐式的提交事务。
定义或修改数据库对象的数据定义语言:数据库对象,指的就是数据库、表、视图、存储过程等这些东西
隐式使用或修改mysql数据库中的表
事务控制或关于锁定的语句
- 我们在一个事务还没提交或者还没回滚时就又使用START TRANSACTION或者BEGN
- 在当前的autocommit系统变量的值为OFF,而我们手动把它调为ON时
- 使用LOCK TABLES、UNLOCK TABLES等关于锁定的语句
保存点
设计数据库的大叔提出了保存点(savepoint)的概念,就是在事务对应的数据库语句中“打”几个点。我们在调用ROLLBACK语句时可以指定回滚到哪个点,而不是回到最初的原点。
SAVEPOINT保存点名称;
SAVEPOINT s1
- WORK和SAVEPOINT可以没有
ROLLBACK [WORK] TO [SAVEPOINT] 保存点名称
ROLLBACK To s1
第19章 说过的话就一定要做到–redo日志
redo日志是啥
事务有一个特性即持久性,在事务提交后即使系统发生了崩溃,这个事务对数据库做的更改页不会丢失。
真正访问页面之前,需要将磁盘的页加载到Buffer Pool中才可以访问。如果在Buffer Pool中修改了页面,数据库宕机,那么修改的内容就会丢失,这样不满足事务的持久性,但是直接将修改的页面刷入磁盘会造成下面的两个问题:
- 刷新一个完整的数据页太浪费了。因为磁盘和内存交互的单位是页,那么修改一个字节就要将整个页刷入磁盘中,这是非常浪费的。
- 一个事务可能包含多个语句,一个语句可能会修改多个页面。这些页面不一定是连续的,那么需要进行很多的随机IO操作。
我们不需要每次事务提交都直接将数据刷入磁盘,可以将修改操作记录在redo日志中事务提交时将redo日志刷新到磁盘中,这样我们可以通过redo日志进行恢复,保证事务的一致性。使用redo日志的好处:
- redo日志占用的空间非常小,因为只存储表空间ID,页号,偏移量以及需要更新的值
- redo日志是顺序写入磁盘的
redo 日志的分类
- 简单的redo日志类型:即只需要向redo日志中记录在某个页面的某个偏移量处修改了几个字节的值,具体修改后的内容是啥就好了。比如修改Max Row ID。
- 复杂一些的redo日志类型:需要修改的内容非常多。比如将一条记录插入一个页面中,设计到页面,包括FILE HEADER,PAGE DIRECOTRY还有页分裂信息等等。总之不能用一条redo log记录就能描述清楚。
一条redo日志既包含物理层面的意思也包括逻辑层面的意思:
- 从物理层面上看,这些日志都指明了对表空间的哪个页进行修改
- 从逻辑层面上看,这些日志并不会直接记录数据是怎么被修改的,只是把在本页面插入一条记录的所有必备的要素记录下来。后面恢复数据的时候将这些要素作为参数调用某些函数进而完整的恢复数据记录。
redo日志这样设计的目的是为了保证redo记录占用的内存空间尽可能小。
Mini-Transaction
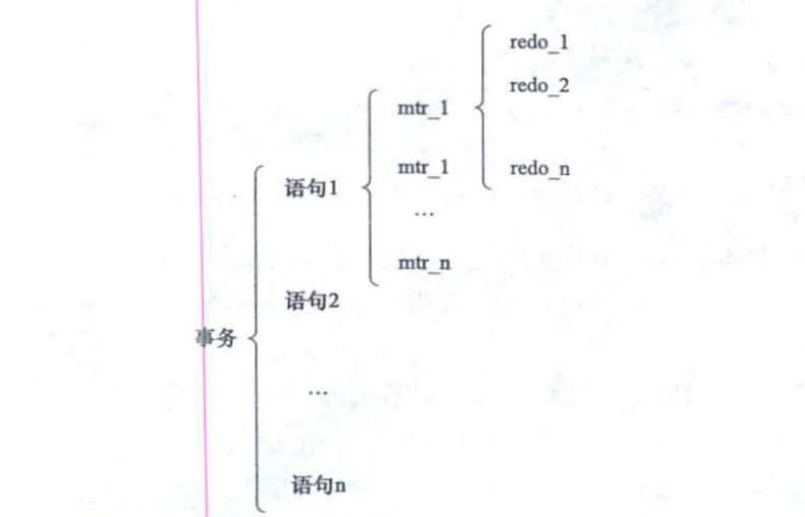
以组的形式写入redo日志
Mysql以组的形式记录redo日志,靠组划分redo日志保证了操作的原子性,一个组中的操作是不可分割的。比如向聚簇索引的B+树中插入一条数据所产生的的多条redo日志记录就是一个组。
Mini-Transaction的概念
Mysql将对于底层页面进行一次原子访问的过程称为一个MTR。比如向B+树中插入一条记录的过程就算是一个MTR。事务,语句,MTR之间的关系:一个事务可能会包含多条语句,一条语句又会包含多个MTR。
第21章 一条记录的多副面孔–事务隔离级别和MVCC
事务在并发执行时遇到的一致性问题
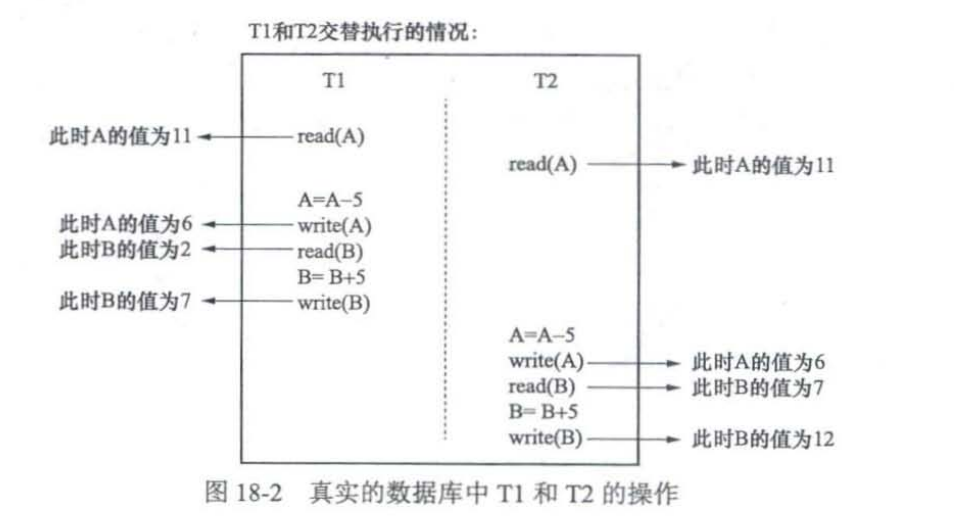
根据 A Critique of ANSI SQL Isolation Levels的定义
- 脏写:一个事务修改了另一个未提交事务修改的数据。例如w1[x=1]w2[x=2]w2[y=2]c2w1[y=1]c1
- 脏读:一个事务读到了另一个未提交事务修改的数据。例如w1[x=1]r2[x=1]r2[y=0]c2w1[y=1]c1
- 不可重复读:一个事务修改了另一个未提交事务读到的数据。例如:r1[x=0]w2[x=1]w2[y=1]c2r1[y=1]c1
- 幻读:一个事务先根据搜索条件查询出一些记录,在事务未提交时,另一个事务写入了一些符合搜索条件的记录(这里的写入可以指INSERT,DELETE,UPDATE)
上面四种一致性问题的严重性排序:
脏写>脏读>不可重复读>幻读
SQL标准中的4种隔离级别
第0章 楔子——阅读前必看 1
第1章 装作自己是个小白——初识MySQL 3
1.1 MySQL的客户端/服务器架构 3
1.2 MySQL的安装 3
1.3 启动MySQL服务器程序 5
1.3.1 在类UNIX系统中启动服务器程序 5
1.3.2 在Windows系统中启动服务器程序 6
1.4 启动MySQL客户端程序 7
1.5 客户端与服务器连接的过程 10
1.5.1 TCP/IP 10
1.5.2 命名管道和共享内存 10
1.5.3 UNIX域套接字 11
1.6 服务器处理客户端请求 11
1.6.1 连接管理 12
1.6.2 解析与优化 12
1.6.3 存储引擎 14
1.7 常用存储引擎 14
1.8 关于存储引擎的一些操作 16
1.8.1 查看当前服务器程序支持的存储引擎 16
1.8.2 设置表的存储引擎 16
1.9 总结 17
第2章 MySQL的调控按钮——启动选项和系统变量 19
2.1 启动选项和配置文件 19
2.1.1 在命令行上使用选项 19
2.1.2 配置文件中使用选项 21
2.1.3 在命令行和配置文件中启动选项的区别 26
2.2 系统变量 27
2.2.1 系统变量简介 27
2.2.2 查看系统变量 27
2.2.3 设置系统变量 28
2.3 状态变量 32
2.4 总结 32
第3章 字符集和比较规则 34
3.1 字符集和比较规则简介 34
3.1.1 字符集简介 34
3.1.2 比较规则简介 34
3.1.3 一些重要的字符集 35
3.2 MySQL中支持的字符集和比较规则 36
3.2.1 MySQL中的utf8和utf8mb4 36
3.2.2 字符集的查看 36
3.2.3 比较规则的查看 38
3.3 字符集和比较规则的应用 39
3.3.1 各级别的字符集和比较规则 39
3.3.2 客户端和服务器通信过程中使用的字符集 44
3.3.3 比较规则的应用 52
3.4 总结 53
第4章 从一条记录说起——InnoDB记录存储结构 55
4.1 准备工作 55
4.2 InnoDB页简介 55
4.3 InnoDB行格式 56
4.3.1 指定行格式的语法 56
4.3.2 COMPACT行格式 56
4.3.3 REDUNDANT行格式 64
4.3.4 溢出列 68
4.3.5 DYNAMIC行格式和COMPRESSED行格式 70
4.4 总结 71
第5章 盛放记录的大盒子——InnoDB数据页结构 72
5.1 不同类型的页简介 72
5.2 数据页结构快览 72
5.3 记录在页中的存储 73
5.4 Page Directory(页目录) 80
5.5 Page Header(页面头部) 85
5.6 File Header(文件头部) 86
5.7 File Trailer(文件尾部) 88
5.8 总结 88
第6章 快速查询的秘籍——B+树索引 90
6.1 没有索引时进行查找 90
6.1.1 在一个页中查找 90
6.1.2 在很多页中查找 91
6.2 索引 91
6.2.1 一个简单的索引方案 92
6.2.2 InnoDB中的索引方案 94
6.2.3 InnoDB中B+树索引的注意事项 102
6.2.4 MyISAM中的索引方案简介 104
6.2.5 MySQL中创建和删除索引的语句 105
6.3 总结 106
第7章 B+树索引的使用 107
7.1 B+树索引示意图的简化 107
7.2 索引的代价 109
7.3 应用B+树索引 110
7.3.1 扫描区间和边界条件 110
7.3.2 索引用于排序 122
7.3.3 索引用于分组 125
7.4 回表的代价 126
7.5 更好地创建和使用索引 127
7.5.1 只为用于搜索、排序或分组的列创建索引 127
7.5.2 考虑索引列中不重复值的个数 127
7.5.3 索引列的类型尽量小 127
7.5.4 为列前缀建立索引 128
7.5.5 覆盖索引 129
7.5.6 让索引列以列名的形式在搜索条件中单独出现 129
7.5.7 新插入记录时主键大小对效率的影响 129
7.5.8 冗余和重复索引 130
7.6 总结 131
第8章 数据的家——MySQL的数据目录 132
8.1 数据库和文件系统的关系 132
8.2 MySQL数据目录 132
8.2.1 数据目录和安装目录的区别 132
8.2.2 如何确定MySQL中的数据目录 132
8.3 数据目录的结构 133
8.3.1 数据库在文件系统中的表示 133
8.3.2 表在文件系统中的表示 134
8.3.3 其他的文件 137
8.4 文件系统对数据库的影响 137
8.5 MySQL系统数据库简介 138
8.6 总结 138
第9章 存放页面的大池子——InnoDB的表空间 140
9.1 回忆一些旧知识 140
9.1.1 页面类型 140
9.1.2 页面通用部分 141
9.2 独立表空间结构 142
9.2.1 区的概念 142
9.2.2 段的概念 144
9.2.3 区的分类 145
9.2.4 段的结构 149
9.2.5 各类型页面详细情况 150
9.2.6 Segment Header结构的运用 156
9.2.7 真实表空间对应的文件大小 157
9.3 系统表空间 158
9.4 总结 164
第10章 条条大路通罗马——单表访问方法 166
10.1 访问方法的概念 167
10.2 const 167
10.3 ref 168
10.4 ref_or_null 170
10.5 range 171
10.6 index 171
10.7 all 172
10.8 注意事项 172
10.8.1 重温二级索引+回表 172
10.8.2 索引合并 173
10.9 总结 177
第11章 两个表的亲密接触——连接的原理 178
11.1 连接简介 178
11.1.1 连接的本质 178
11.1.2 连接过程简介 180
11.1.3 内连接和外连接 181
11.2 连接的原理 185
11.2.1 嵌套循环连接 186
11.2.2 使用索引加快连接速度 187
11.2.3 基于块的嵌套循环连接 188
11.3 总结 189
第12章 谁最便宜就选谁——基于成本的优化 190
12.1 什么是成本 190
12.2 单表查询的成本 190
12.2.1 准备工作 190
12.2.2 基于成本的优化步骤 191
12.2.3 基于索引统计数据的成本计算 198
12.3 连接查询的成本 201
12.3.1 准备工作 201
12.3.2 条件过滤(Condition Filtering) 201
12.3.3 两表连接的成本分析 203
12.3.4 多表连接的成本分析 205
12.4 调节成本常数 206
12.4.1 mysql.server_cost表 206
12.4.2 mysql.engine_cost表 208
12.5 总结 209
第13章 兵马未动,粮草先行——InnoDB统计数据是如何收集的 210
13.1 统计数据的存储方式 210
13.2 基于磁盘的永久性统计数据 211
13.2.1 innodb_table_stats 211
13.2.2 innodb_index_stats 214
13.2.3 定期更新统计数据 215
13.2.4 手动更新innodb_table_stats和innodb_index_stats表 216
13.3 基于内存的非永久性统计数据 217
13.4 innodb_stats_method的使用 217
13.5 总结 219
第14章 基于规则的优化(内含子查询优化二三事) 220
14.1 条件化简 220
14.1.1 移除不必要的括号 220
14.1.2 常量传递 220
14.1.3 移除没用的条件 221
14.1.4 表达式计算 221
14.1.5 HAVING子句和WHERE子句的合并 221
14.1.6 常量表检测 221
14.2 外连接消除 222
14.3 子查询优化 224
14.3.1 子查询语法 225
14.3.2 子查询在MySQL中是怎么执行的 230
14.4 总结 244
第15章 查询优化的百科全书——EXPLAIN详解 245
15.1 执行计划输出中各列详解 246
15.1.1 table 246
15.1.2 id 247
15.1.3 select_type 249
15.1.4 partitions 252
15.1.5 type 252
15.1.6 possible_keys和key 255
15.1.7 key_len 256
15.1.8 ref 258
15.1.9 rows 258
15.1.10 filtered 259
15.1.11 Extra 260
15.2 JSON格式的执行计划 266
15.3 Extented EXPLAIN 268
15.4 总结 269
第16章 神兵利器——optimizer trace的神奇功效 270
16.1 optimizer trace简介 270
16.2 通过optimizer trace分析查询优化器的具体工作过程 271
第17章 调节磁盘和CPU的矛盾——InnoDB的Buffer Pool 278
17.1 缓存的重要性 278
17.2 InnoDB的Buffer Pool 278
17.2.1 啥是Buffer Pool 278
17.2.2 Buffer Pool内部组成 278
17.2.3 free链表的管理 279
17.2.4 缓冲页的哈希处理 280
17.2.5 flush链表的管理 281
17.2.6 LRU链表的管理 282
17.2.7 其他的一些链表 286
17.2.8 刷新脏页到磁盘 287
17.2.9 多个Buffer Pool实例 287
17.2.10 innodb_buffer_pool_chunk_size 288
17.2.11 配置Buffer Pool时的注意事项 289
17.2.12 查看Buffer Pool的状态信息 291
17.3 总结 293
第18章 从猫爷借钱说起——事务简介 294
18.1 事务的起源 294
18.1.1 原子性(Atomicity) 295
18.1.2 隔离性(Isolation) 295
18.1.3 一致性(Consistency) 296
18.1.4 持久性(Durability) 298
18.2 事务的概念 298
18.3 MySQL中事务的语法 300
18.3.1 开启事务 300
18.3.2 提交事务 301
18.3.3 手动中止事务 302
18.3.4 支持事务的存储引擎 302
18.3.5 自动提交 303
18.3.6 隐式提交 304
18.3.7 保存点 305
18.4 总结 307
第19章 说过的话就一定要做到——redo日志 308
19.1 事先说明 308
19.2 redo日志是啥 308
19.3 redo日志格式 309
19.3.1 简单的redo日志类型 309
19.3.2 复杂一些的redo日志类型 311
19.3.3 redo日志格式小结 314
19.4 Mini-Transaction 315
19.4.1 以组的形式写入redo日志 315
19.4.2 Mini-Transaction的概念 319
19.5 redo日志的写入过程 319
19.5.1 redo log block 319
19.5.2 redo日志缓冲区 320
19.5.3 redo日志写入log buffer 321
19.6 redo日志文件 323
19.6.1 redo日志刷盘时机 323
19.6.2 redo日志文件组 323
19.6.3 redo日志文件格式 324
19.7 log sequence number 327
19.7.1 flushed_to_disk_lsn 328
19.7.2 lsn值和redo日志文件组中的偏移量的对应关系 330
19.7.3 flush链表中的lsn 330
19.8 checkpoint 332
19.9 用户线程批量从flush链表中刷出脏页 335
19.10 查看系统中的各种lsn值 335
19.11 innodb_flush_log_at_trx_commit的用法 336
19.12 崩溃恢复 336
19.12.1 确定恢复的起点 337
19.12.2 确定恢复的终点 337
19.12.3 怎么恢复 337
19.13 遗漏的问题:LOG_BLOCK_HDR_NO是如何计算的 339
19.14 总结 340
第20章 后悔了怎么办——undo日志 342
20.1 事务回滚的需求 342
20.2 事务id 343
20.2.1 分配事务id的时机 343
20.2.2 事务id是怎么生成的 343
20.2.3 trx_id隐藏列 344
20.3 undo日志的格式 344
20.3.1 INSERT操作对应的undo日志 345
20.3.2 DELETE操作对应的undo日志 347
20.3.3 UPDATE操作对应的undo日志 353
20.3.4 增删改操作对二级索引的影响 357
20.4 通用链表结构 357
20.5 FIL_PAGE_UNDO_LOG页面 359
20.6 Undo页面链表 361
20.6.1 单个事务中的Undo页面链表 361
20.6.2 多个事务中的Undo页面链表 362
20.7 undo日志具体写入过程 363
20.7.1 段的概念 363
20.7.2 Undo Log Segment Header 364
20.7.3 Undo Log Header 365
20.7.4 小结 367
20.8 重用Undo页面 368
20.9 回滚段 369
20.9.1 回滚段的概念 369
20.9.2 从回滚段中申请Undo页面链表 371
20.9.3 多个回滚段 372
20.9.4 回滚段的分类 374
20.9.5 roll_pointer的组成 374
20.9.6 为事务分配Undo页面链表的详细过程 375
20.10 回滚段相关配置 376
20.10.1 配置回滚段数量 376
20.10.2 配置undo表空间 376
20.11 undo日志在崩溃恢复时的作用 377
20.12 总结 377
第21章 一条记录的多副面孔——事务隔离级别和MVCC 379
21.1 事前准备 379
21.2 事务隔离级别 379
21.2.1 事务并发执行时遇到的一致性问题 382
21.2.2 SQL标准中的4种隔离级别 385
21.2.3 MySQL中支持的4种隔离级别 386
21.3 MVCC原理 388
21.3.1 版本链 388
21.3.2 ReadView 390
21.3.3 二级索引与MVCC 397
21.3.4 MVCC小结 397
21.4 关于purge 398
21.5 总结 399
第22章 工作面试老大难——锁 401
22.1 解决并发事务带来问题的两种基本方式 401
22.1.1 写-写情况 401
22.1.2 读-写或写-读情况 403
22.1.3 一致性读 404
22.1.4 锁定读 404
22.1.5 写操作 405
22.2 多粒度锁 406
22.3 MySQL中的行锁和表锁 408
22.3.1 其他存储引擎中的锁 408
22.3.2 InnoDB存储引擎中的锁 409
22.3.3 InnoDB锁的内存结构 417
22.4 语句加锁分析 423
22.4.1 普通的SELECT语句 423
22.4.2 锁定读的语句 424
22.4.3 半一致性读的语句 441
22.4.4 INSERT语句 442
22.5 查看事务加锁情况 444
22.5.1 使用information_schema数据库中的表获取锁信息 444
22.5.2 使用SHOW ENINGE INNODB STATUS获取锁信息 446
22.6 死锁 450
22.7 总结 454















 5159
5159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









