







文章目录
0. 前言
本文注重的,是SQL通用设计思想及性能使用上的区别,忽略了不同类型的SQL语法区别,例如ANSI-SQL、MySQL,SQL Server,Oracle,甚至是Hive,Impala,Presto。[反正只要是我用到、碰到的…]
1. union 和 union all的区别
参考来源:
SQL语句中:UNION与UNION ALL的区别
数据库中UNION和UNION ALL的区别以及并集怎么取得
关于Union和Union All的区别以及用法
先说说这两个用法的要求:
必须选择相同数量的列,每条select语句中的列的顺序也必须相同,这些列也必须拥有相似的数据类型。
也就是说,要达到六耳猕猴和通背猿猴的那种匹配度才能union (all),这是前提。
这两个关键字都是将两个结果集合并成一个
union 是在进行表链接后,筛选掉完全相同的记录,union all不会去重,记录可能有重复;
union 会按照select 字段的顺序进行排序(默认),union all 只是简单的将两个结果集合并就返回,并不排序;
所以效率上来说,union all 要比union 快很多,在确认合并的两个结果集总不包含重复数据且不需要排序的话,使用union all;
另外,
这两个操作中,select的列名不一定要一样,如果要对进行排序,不需要在每一个select结果集中排序,只需要在最后一条语句中使用order by 进行排序即可。
select pname,ename from emp
union
select username,dname from dept
order by ename;
简要回答:
UNION去重且排序
UNION ALL不去重不排序
来个栗子
现在有两张表:

1.union 测试
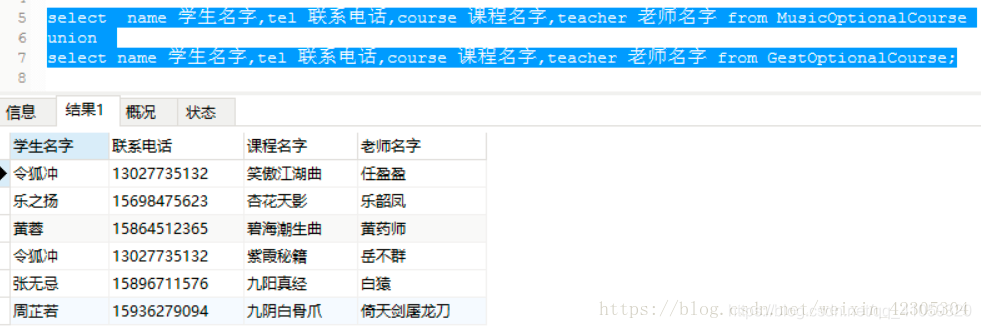 可以看到这里面有两个令狐冲,不是说会去重的嘛?!
可以看到这里面有两个令狐冲,不是说会去重的嘛?!
大家看清楚了,这段SQL中含有的字段包括了课程名字和老师名字,虽然令狐冲只有一个,但是这两个字段都不一样,所以不是重复的记录,所以这也就是我上面说,完全相同
那就来个去重的栗子尝一下
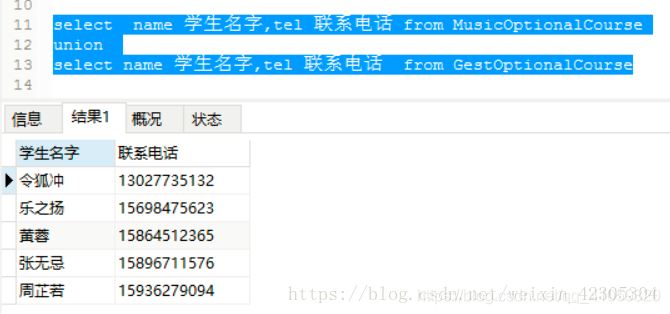 这些应该学乖了吧,select中只有前两个字段,这样令狐冲记录就是重复的,所以只显示一条记录!
这些应该学乖了吧,select中只有前两个字段,这样令狐冲记录就是重复的,所以只显示一条记录!
所以,如果要使用union,要想想自己只是想看看有哪些学生,还是要看所有信息,在select字段中选择。
2.union all测试
不好意思哈,参考来源中没做,我也懒得自己建表去测了哈哈哈~~
不过可以想到,不管选哪几个字段,都会有两个令狐冲的记录的。
注意;
Hive 1.2.0之前的版本仅支持UNION ALL,其中重复的行不会被删除,而且不支持在顶层使用,只能在子查询中用。
也就是
1. 报错
select xx from t1
union all
select xx from t2
2. 成功
select *
from (select xx from t1
union all
select xx from t2
)
2. (not)in 和 exist 的区别
参考来源:
浅谈sql中的in与not in,exists与not exists的区别以及性能分析
浅谈sql中的in与not in,exists与not exists的区别
SQL查询~ 存在一个表而不在另一个表中的数据
SQL中如何使用EXISTS替代IN
Hive不支持where语句中的 in/exists条件,可以使用 left semi-join 语法。
先放一下这两条语句是怎么用的
select t1.* from t1 where t1.id in (select t2.id from t2)
select t1.* from t1 where exists (select t2.id from t2 where t2.id = t1.id)
再看一下,我的测试过程:
- 一百多万条记录时,前面的表大,后面的表较小。两个表相差不大的情况下,可以看到,其实效率也差不多,单纯从数字上来看, 甚至 in 还要快一点。
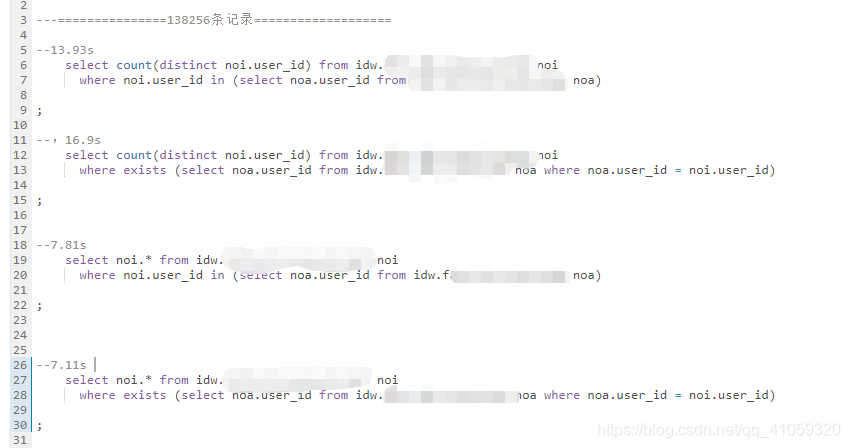
- 千万,亿级条数,
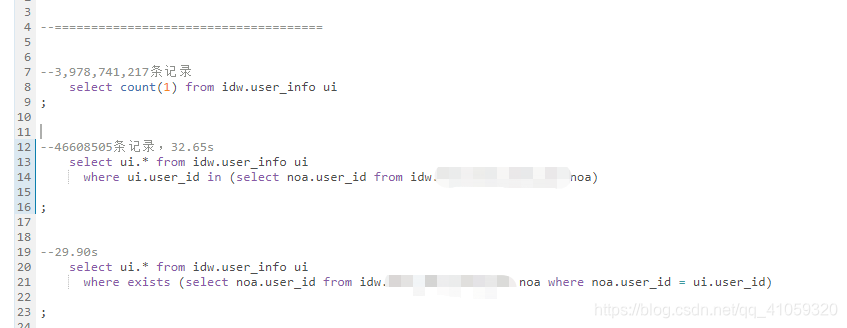 这就很奇怪了,为什么都说exists效率比in快呢,我这边测试下来,都没发生很大变化,时间原因,本次探索到此。
这就很奇怪了,为什么都说exists效率比in快呢,我这边测试下来,都没发生很大变化,时间原因,本次探索到此。
3. left join on与where的用法与区别
3.1 left join on and 和where的执行顺序与结果区别
假设有两个表
 执行以下两条SQL
执行以下两条SQL
1、 select *
from tab1
left join tab2
on tab1.size = tab2.size
where tab2.name='AAA'
2、 select *
from tab1
left join tab2
on tab1.size = tab2.size
and tab2.name='AAA'
咱来看下结果哈。可以自己先猜一下。
第一条SQL的过程:
1、中间表
on条件: tab1.size = tab2.size,生成的结果

这就是正常的左连接,无论右边表的字段啥样,都会按照左边表的字段输出。join完毕生成一张中间表。
2、再对中间表过滤
where 条件: tab2.name=’AAA’

此时进行的where条件就和join没任何关系了,所以结果就只有这一条。
第二条SQL的过程:
1、中间表
on条件: tab1.size = tab2.size and tab2.name=’AAA’

这里可以看到,on中的条件只对右边的表进行了过滤,对左边的表毫无影响,所以才会出现这样的结果。
其实以上结果的关键原因就是 left join,right join,full join 的特殊性,不管on上的条件是否为真都会返回 left 或 right 表中的记录,full则具有left和right的特性的并集。
而inner jion没这个特殊性,则条件放在on中和where中,返回的结果集是相同的。
简单概括一下:
- 先on 再 where是对两个表join后的结果进行where筛选
- on and只能对join右边的表进行筛选,对左边表无影响
3.2 同样结果,使用left join 比直接使用where速度快
参考来源:
使用left join比直接使用where速度快的原因
亲测SQL left join on 和 where 效率
这个问题我看网上的帖子很少,我是在自己碰到的,发现有时候同一个结果,用 left join 和 where 都可以。
先煮个栗子。
例如下面这几张表:
t1 (s_id, s_name, s_dep, s_age)
学号,学员姓名,所属单位,学员年龄
t2 (s_id, c_id, grade)
学号,课程编号,学习成绩
--查询选修课程编号为’C5’的学员姓名和所属单位?
--1. 使用left join on
select t1.s_name
,t1.s_dep
from t1
left join t2
on t2.s_id = t1.s_id
where t2.c_id = "C2"
--2. 使用where
select s_name
,s_dep
from t1,t2
where t1.s_id = t2.s_id
and t2.c_id = "C2"
我在写时,习惯性的用 left join,可能是在公司中见到的 left join比较多,都忘了也可以用 where来这么实现了。
那么,这两个sql有啥区别么?
按照参考文章中的说法:
多表使用left join只是把主表里的所有数据查询出来,其他表只查询表中的符合条件的某一条记录,所以速度非常快;而多表使用where内联,是把所有表的数据全查出来,然后进行比对,所以速度非常慢。
2019-05-05更新
原答案是这样:

看到牛客网讨论区这么说:

这么看来,还是实践出真知啊,实习中学的比看书来的直接。
4. ROW_NUMBER()和RANK(),DENSE_RANK()区别
参考来源:
一个SQL语句分清楚RANK(),DENSE_RANK(),ROW_NUMBER()三个排序的不同
sql 四大排名函数—(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介
先看个栗子:
写几句SQL
SELECT s.deptno
,s.ename,s.sal,
RANK() over(partition by s.deptno order by s.sal) as rank,
DENSE_RANK() over(partition by s.deptno order by s.sal) as dense_rank,
ROW_NUMBER() over(partition by s.deptno order by s.sal) as row_number
FROM emp s;
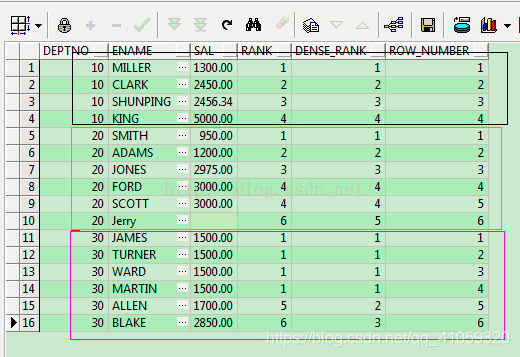 总结一下:
总结一下:
rank 根据order by排名 会出现并列排名。下一个值会跳过并列值 比如 1 2 2 4 5
通常对应rank还有 dense_rank 出现并列排名以后,下一个值不跳过并列值 1 2 2 3 4
row_number 就是直接排出一个名次。不会出现并列排名 1 2 3 4 5
5. group by与distinct效率分析及优化措施
在去重计数的时候,一般有两种方法:
--1. count(distinct)
select count(distinct t.user_id) from idw.fact_borrows t
--2. group by
select count(*) from (select t.user_id from idw.fact_borrows t group by t.user_id) t2
根据参考博客,和本人实测(实验环境为HUE上的 Impala查询,实际生产数据),先说本文得到的结论:
- 当不同记录的数量较小时,group by 要明显快于 count(distinct);
- 当不同记录的数量较大时,count(distinct)反而要更快
实验记录:
-
结果数据集只有一百多万个时:
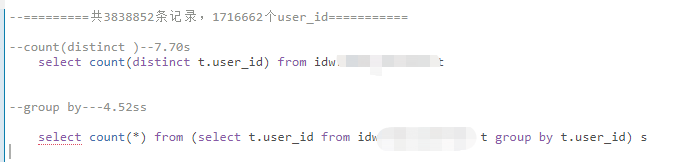
-
结果数据集达到一千多万时:
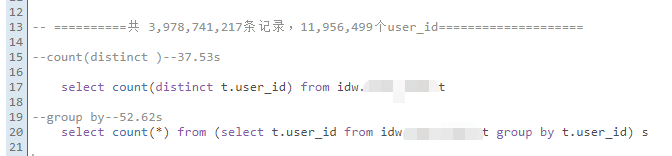
这里的秒数,都是我多跑了好几次,取的众数。
OK,那就按照参考博客的原因来总结一下原因。
因为当结果数据集较小的时候,执行计划会使用HashAggregation,在内存中维护一个Hash表,而当结果集较大时,无法通过在内存中维护Hash表的方式使用HashAggregation,planner会使用GroupAggregation,并会用到排序,而且因为目标数据集太大,无法在内存中使用Quick Sort,而要在外存中使用Merge Sort,而这就极大的增加了I/O开销。
(其实这么一段话我也不是很清楚其原理)

















 2847
2847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









