






上一篇已经介绍了如何运行作业,现在看一下flink ui各模块详情。后面再逐章剖析源码
1. 首页(Overview)
- JobManager 和 TaskManager 信息
- JobManager 地址和端口:显示当前 Flink 集群中 JobManager 的网络地址和端口号,JobManager 负责作业的调度和管理。
- TaskManager 数量:展示集群中可用的 TaskManager 数量,TaskManager 是执行具体任务的工作节点。
- Slot 信息:显示总插槽数和可用插槽数。插槽是 Flink 资源管理的基本单位,每个 TaskManager 有一定数量的插槽,任务会被分配到这些插槽中执行。
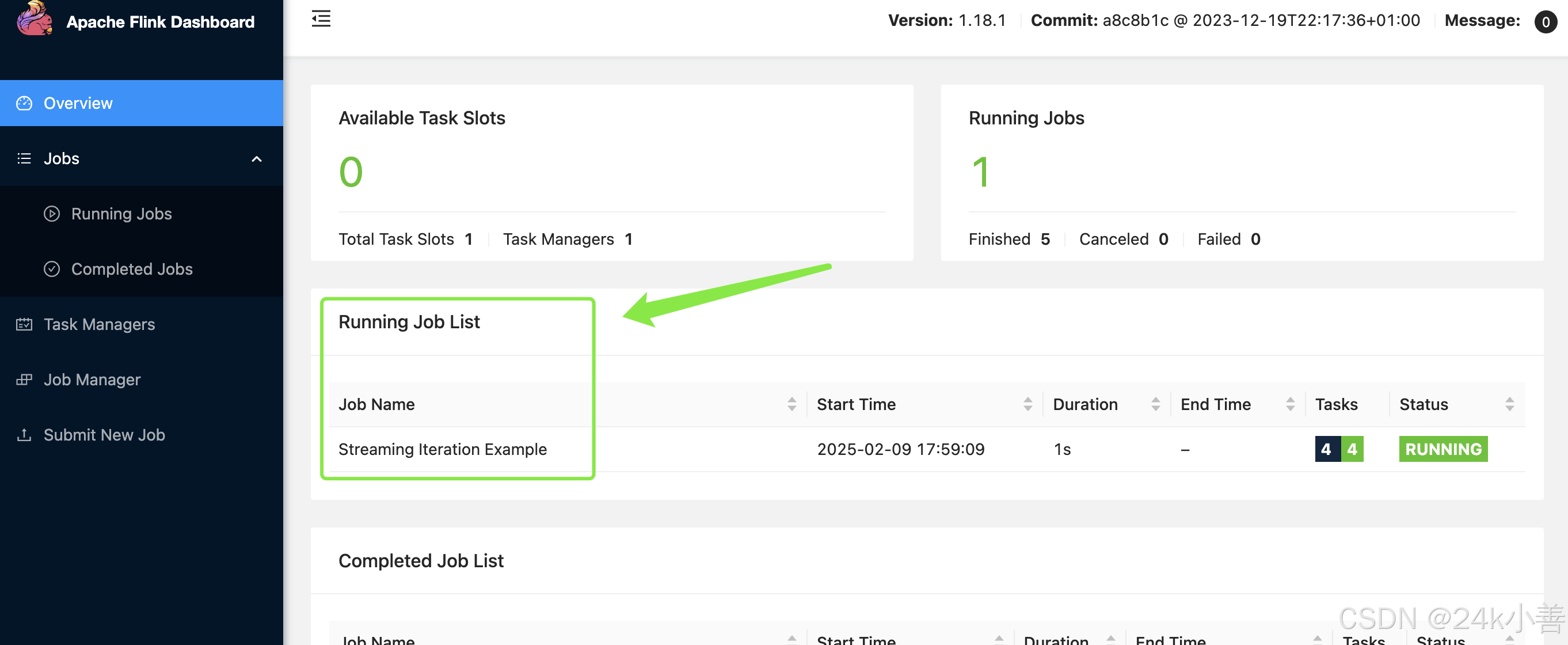
- 作业信息【重点,图中箭头所示】
- 运行中的作业列表:列出当前正在运行的作业,包括作业名称、作业 ID、开始时间、持续时间等信息。
- 已完成和失败的作业:可以查看过去已完成或失败的作业记录,方便进行故障排查和性能分析。
2. 作业详情页(Jobs)
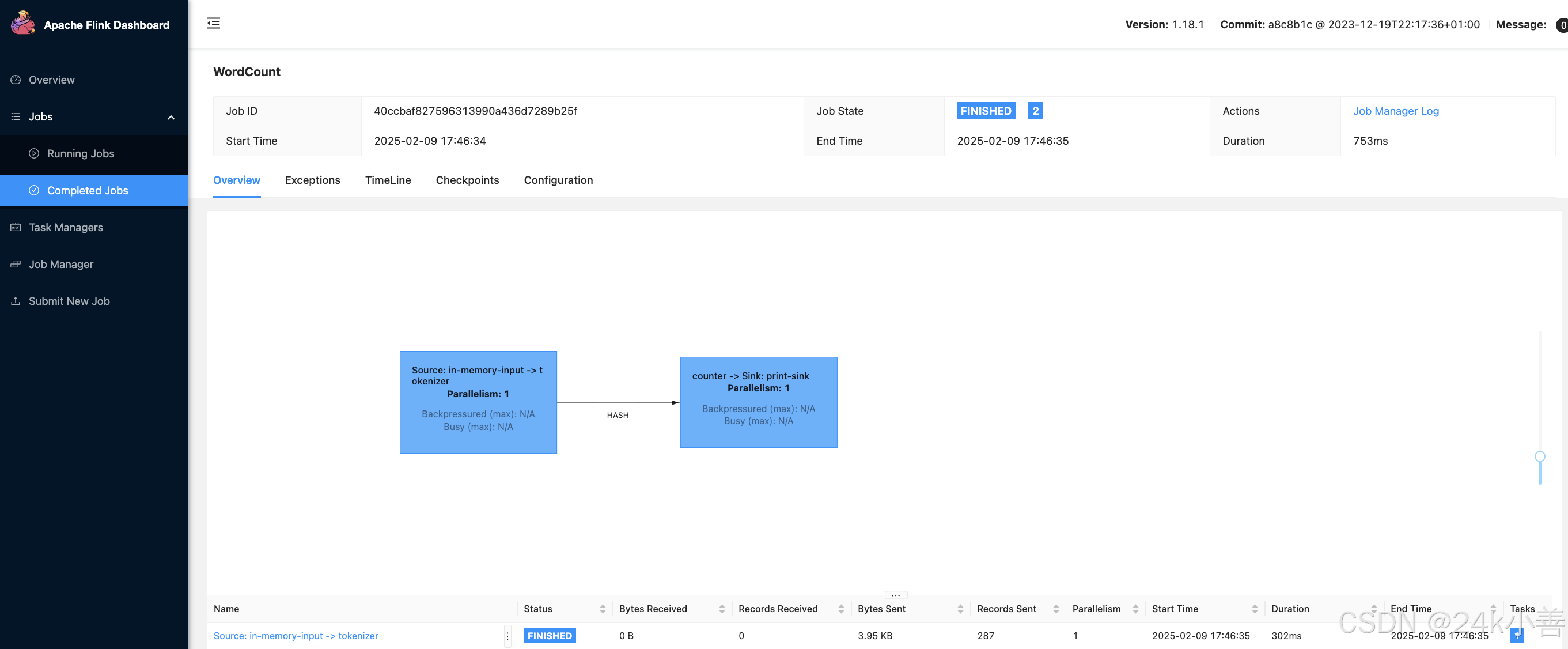
- 作业图(Job Graph)
- 可视化展示:以图形化的方式展示作业的逻辑拓扑结构,包括数据源(如文件、Kafka 等)、转换操作(如 Map、FlatMap 等)和数据汇(如文件、控制台等)。在 WordCount 作业中,你可以看到从数据源读取数据、进行单词拆分和计数,最后将结果输出的整个流程。
- 节点信息:鼠标悬停在每个节点上,可以查看节点的详细信息,如操作名称、并行度等。
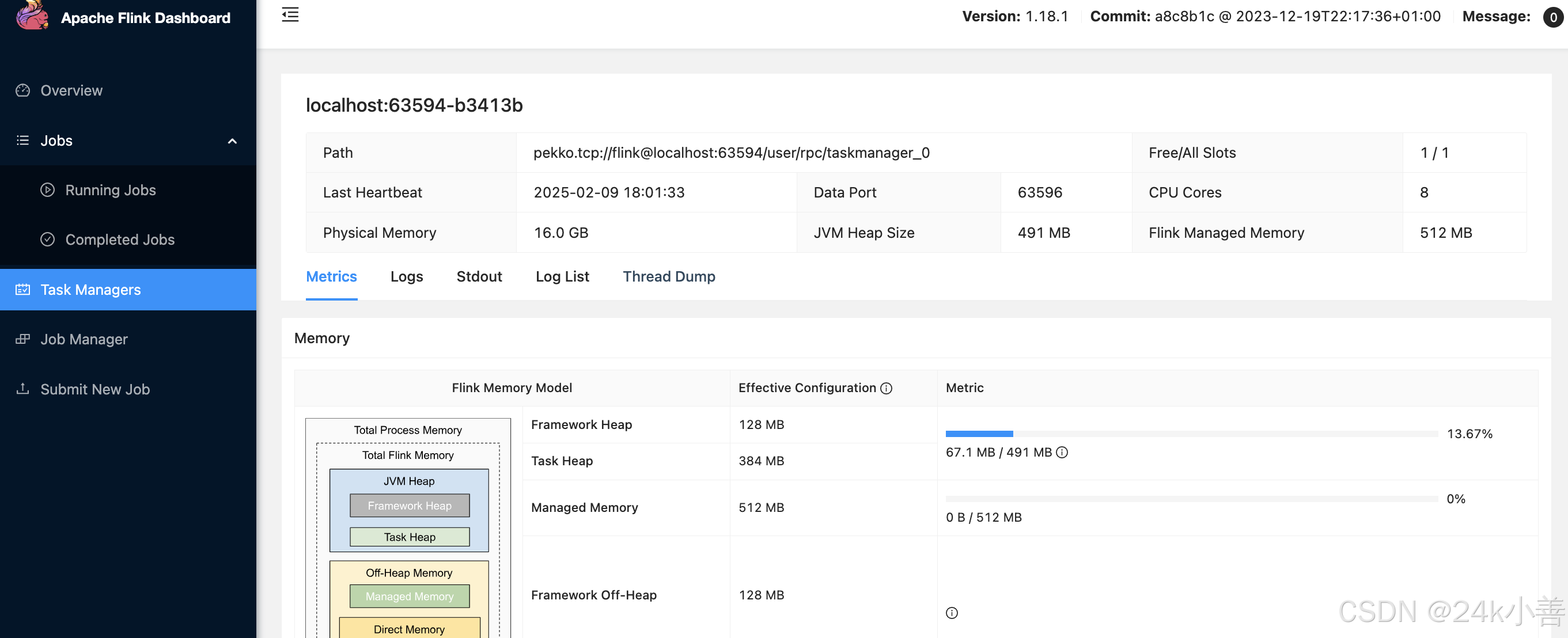
- 任务管理器(TaskManagers)
- 任务分布:显示作业的任务在各个 TaskManager 上的分布情况,帮助你了解资源的使用情况和负载均衡情况。
- 任务状态:可以查看每个任务的状态,如运行中、已完成、失败等。
- 指标监控(Metrics)
- 吞吐量:显示作业的输入和输出吞吐量,即每秒处理的记录数或字节数。在 WordCount 作业中,可以监控单词的读取和处理速度。
- 延迟:展示数据处理的延迟情况,帮助你评估作业的实时性。
- 资源利用率:包括 CPU、内存、网络 I/O 等资源的使用情况,有助于发现性能瓶颈。
3. 任务详情页(Tasks)
-
任务列表
- 子任务信息:列出作业中每个操作的所有子任务,包括子任务的 ID、状态、开始时间、持续时间等。
- 任务状态监控:实时更新子任务的状态,如运行中、已完成、失败等。如果某个子任务失败,可以查看详细的错误信息进行故障排查。
-
任务指标
- 输入和输出指标:显示每个子任务的输入和输出记录数、字节数等信息,帮助你了解数据在各个子任务之间的流动情况。
- 处理时间指标:展示子任务的处理时间,包括平均处理时间、最大处理时间等,有助于优化作业性能。
-
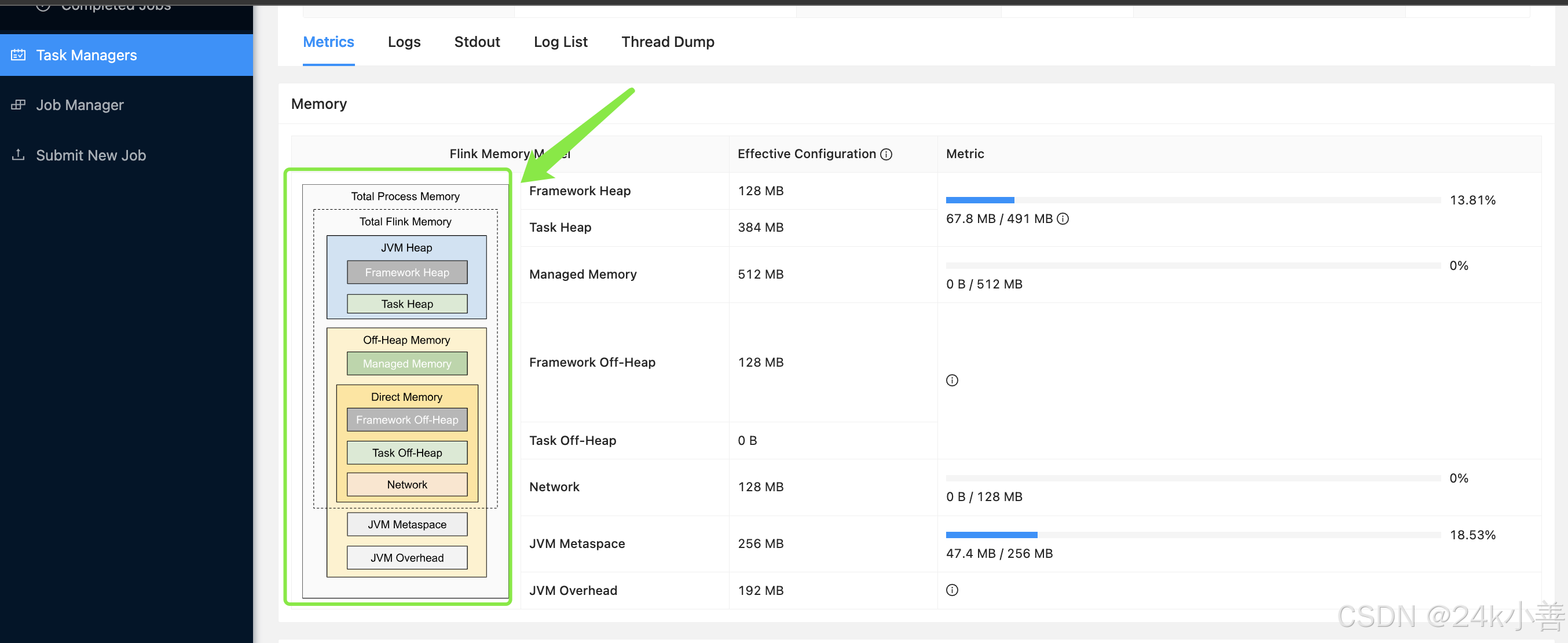
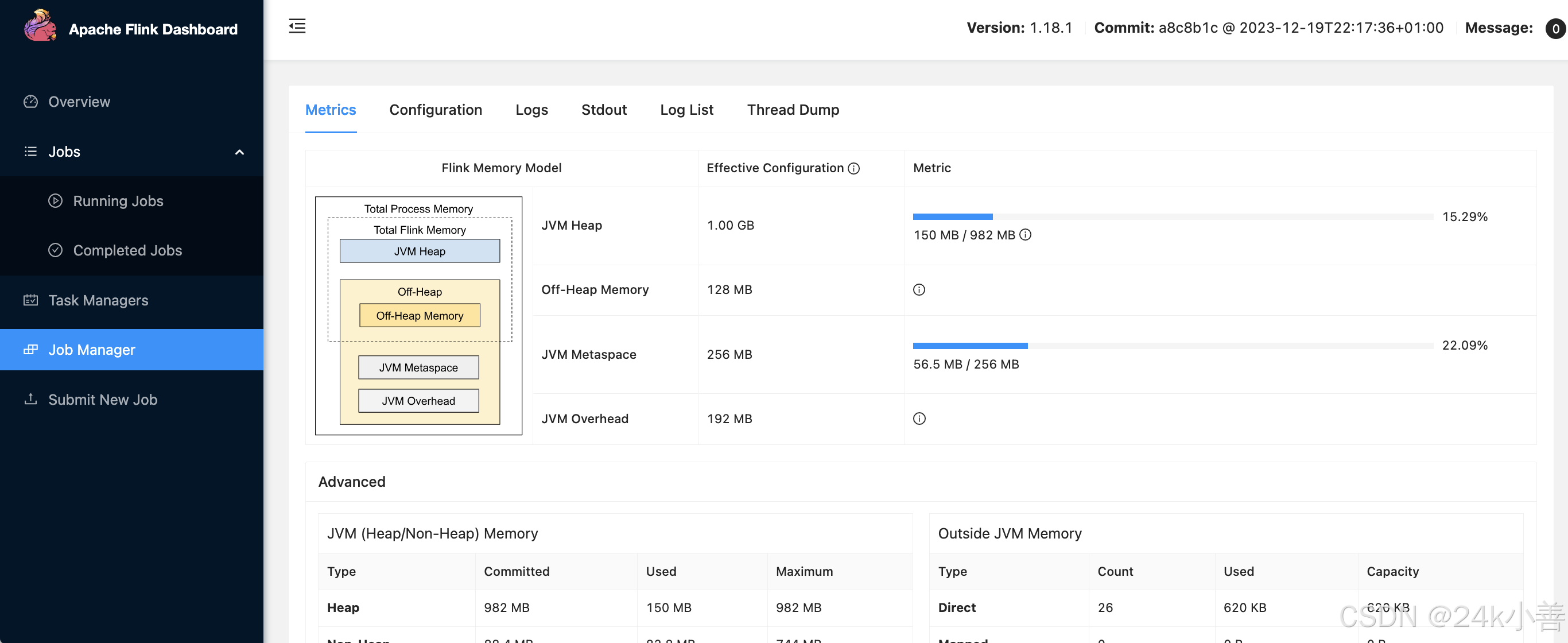
内存模型【重要‼️】
用于分析任务执行情况
4. 配置页(Configuration)
- 全局配置信息
- Flink 集群的配置参数:显示 Flink 集群的各种配置参数,如内存分配、并行度设置、网络配置等。你可以在这里查看和验证作业运行时使用的配置信息。
- 作业特定配置
- 作业的配置参数:如果作业有特定的配置参数,也会在这个页面显示,方便你了解作业的个性化设置。
5. 堆内存分析页(Heap)【如内存模型】
- 堆内存使用情况
- 实时监控:以图表的形式实时展示 JobManager 和 TaskManager 的堆内存使用情况,帮助你及时发现内存泄漏或内存不足的问题。
- 历史数据:可以查看堆内存使用的历史数据,分析内存使用的趋势和波动情况。
6. 线程转储页(Thread Dump)【如内存模型】
- 线程信息
- 线程状态:显示 JobManager 和 TaskManager 中所有线程的状态,包括运行中、等待、阻塞等。
- 线程堆栈信息:可以查看每个线程的堆栈信息,用于定位线程阻塞或死锁的问题。
7. 故障容灾checkpoint
生产中故障恢复能力至关重要,所以单独拿出来讲
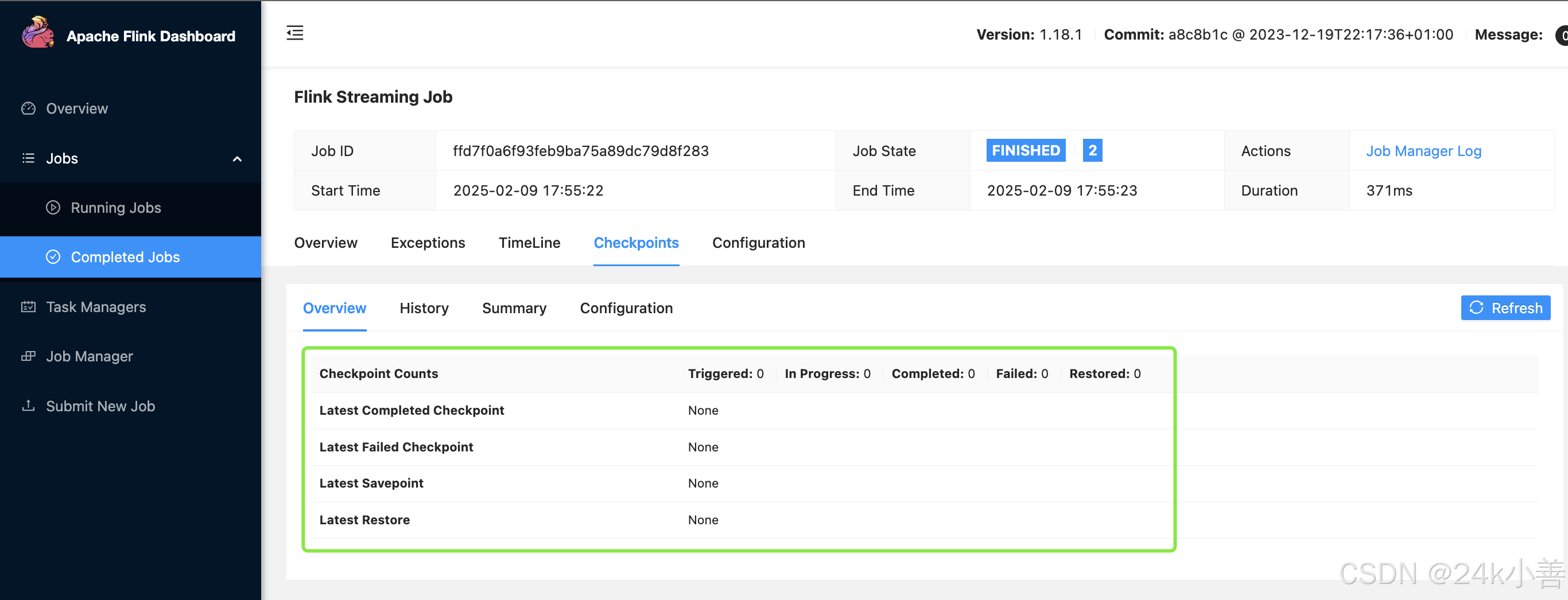
Checkpoint 相关页面为用户提供了对 Flink 作业的检查点(Checkpoint)操作和状态进行监控与管理的功能。检查点是 Flink 实现容错机制的关键特性,它可以在作业出现故障时将作业的状态进行持久化保存,以便后续能够从保存的状态恢复作业,继续进行处理。
a. 检查点概览(Checkpoint Overview)
- 检查点统计信息
- 总检查点数量:显示作业总共触发的检查点数量,包括成功的、失败的和进行中的检查点。
- 成功检查点数量:记录成功完成的检查点的数量。成功的检查点意味着作业的状态已经被完整且正确地保存到了指定的存储位置。
- 失败检查点数量:展示执行过程中失败的检查点的数量。失败的原因可能有很多,如网络问题、存储系统故障、状态过大等。
- 最近一次成功检查点时间:显示最近一次成功完成检查点的时间戳,有助于了解作业状态最后一次被持久化的时间。
- 检查点大小和持续时间
- 最小、最大和平均检查点大小:反映了检查点所占用的存储空间大小,这些信息可以帮助你评估状态的规模,以及存储系统的压力。
- 最小、最大和平均检查点持续时间:展示了检查点从开始到完成所花费的时间,持续时间过长可能表示作业状态复杂或者存储系统性能不佳。
b. 检查点列表(Checkpoint List)
- 检查点记录:该列表会详细列出每个检查点的相关信息,包括:
- ID:每个检查点的唯一标识符,用于区分不同的检查点。
- 状态:显示检查点的当前状态,如 “Completed”(已完成)、“In Progress”(进行中)、“Failed”(失败)等。
- 触发时间:记录检查点开始触发的时间。
- 持续时间:显示检查点从触发到结束所花费的时间。
- 大小:表示检查点所占用的存储空间大小。
- 对齐时间:对于使用了精确一次(Exactly-Once)语义的作业,该时间表示在进行检查点操作时,数据对齐所花费的时间。
- 详细信息查看:点击列表中某个检查点的 ID,可查看该检查点的详细信息,如参与检查点的各个任务的状态、状态存储的位置等。
c. 检查点配置(Checkpoint Configuration)
- 检查点间隔:显示作业配置的检查点触发间隔时间,即每隔多长时间触发一次检查点操作。合理设置检查点间隔可以在容错能力和性能之间取得平衡。
- 超时时间:表示检查点操作允许的最长执行时间。如果检查点在超时时间内未能完成,则会被标记为失败。
- 最大并发检查点数:指定在同一时间内可以同时进行的检查点的最大数量。该参数可以控制检查点操作对作业正常处理的影响。
- 保留策略:说明检查点的保留规则,例如保留最近的几个检查点,或者根据时间来保留检查点。保留策略可以帮助在需要时恢复到特定时间点的作业状态。
d. 检查点状态存储(State Backend)
- 状态后端类型:显示作业所使用的状态后端类型,如 MemoryStateBackend、FsStateBackend、RocksDBStateBackend 等。不同的状态后端适用于不同的场景,例如 MemoryStateBackend 适用于测试环境,而 FsStateBackend 和 RocksDBStateBackend 更适合生产环境。
- 存储位置:如果使用的是支持外部存储的状态后端(如 FsStateBackend 或 RocksDBStateBackend),会显示检查点数据实际存储的位置,如 HDFS 路径等。


















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









