







摘要:系统记录一下自己的深度学习理论和Pytorch的使用学习过程,由于已经有一定基础,pytorch使用方面有些基础的东西就不写了。
学习资料参考:
1.阿里天池:https://tianchi.aliyun.com/course/337/3981
2.B站小甲鱼Pytorch教程:https://www.bilibili.com/video/BV1HY4y1T71A
3.https://www.bilibili.com/video/BV1r94y1S7A
1.Tensor
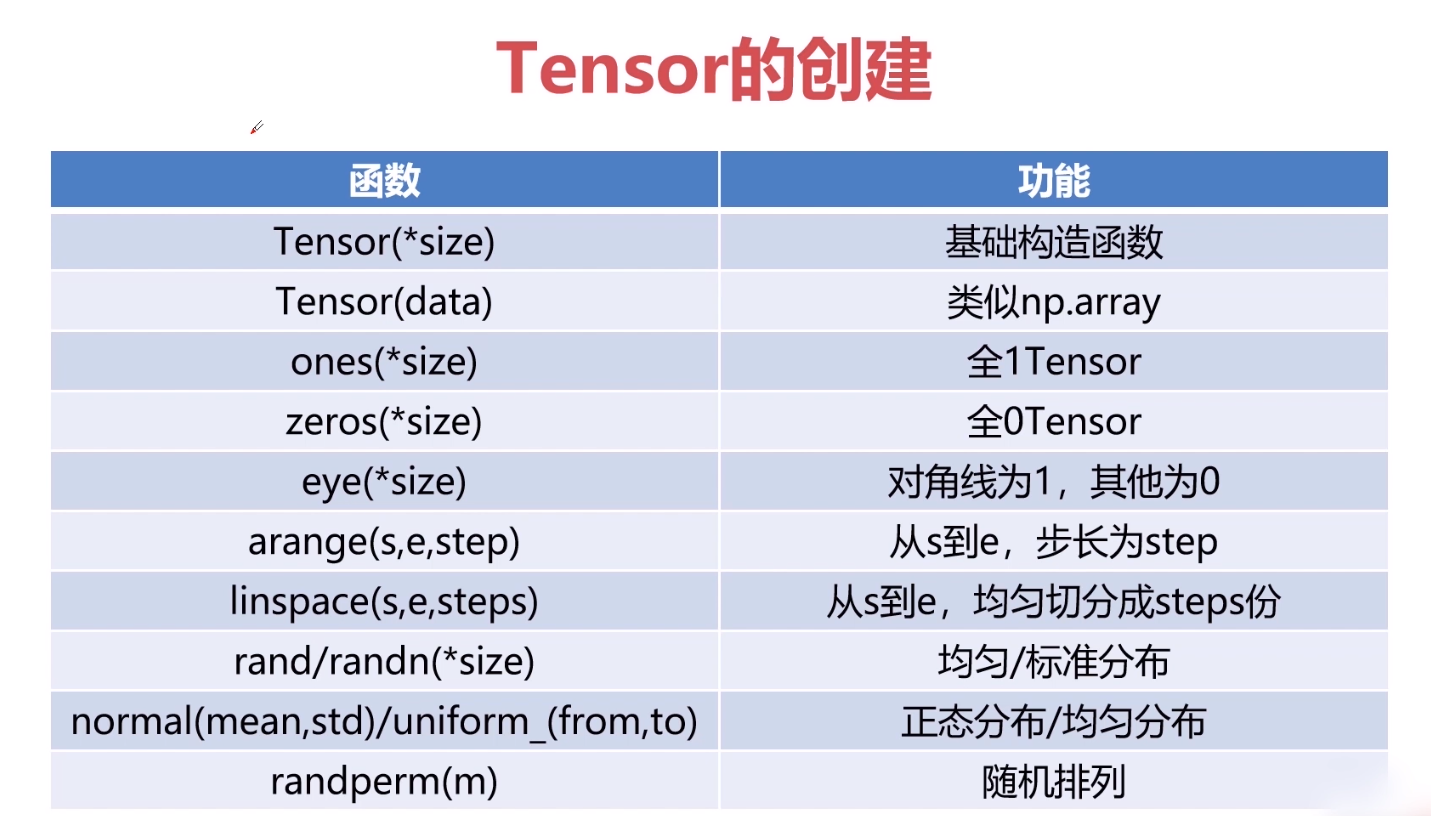
1.1 Tensor变换:
torch.reshape(input, shape):
input:要变换的张量
shape:新张量的形状
和view区别在于:view不会开辟新的内存空间,只是产生了对原存储空间的一个新别称和引用,返回值是视图。而reshape()方法的返回值既可以是视图,也可以是副本,当满足连续性条件时返回view,否则返回副本。所以为了节约内存可以用view,不知道能否用view就用reshape。
a = torch.arange(4.)
a = torch.reshape(a, (2, 2))
// tensor([[0., 1.],
// [2., 3.]])
torch.transpose(input, dim0, dim1):
交换维度。torch.transpose(input, 0, 1) = torch.t(input)—矩阵转置。
torch.squeeze(input, dim=None, out=None):
dim:若为None,移除所有长度为1的轴;若指定维度,当且仅当该轴长度为1时,可以被移除。
torch.unsqueeze(input, dim, out=None):
根据dim扩展一个维度。
torch.expand:
只能把维度为1的拓展成指定维度。如果哪个维度为-1,就是该维度不变。函数对返回的张量不会分配新内存,即在原始张量上返回只读视图,返回的张量内存是不连续的。类似于numpy中的broadcast_to函数的作用。如果希望张量内存连续,可以调用contiguous函数。
x = torch.rand((2, 1, 3, 1))
x_expand = x.expand(2, 3, 3, 2)
x_expand_1 = x.expand(-1, -1, -1, 4)
torch.repeat:
用法类似np.tile,就是将原矩阵横向、纵向地复制。与torch.expand不同的是torch.repeat返回的张量在内存中是连续的。(占用内存,不推荐)
x = torch.rand((2, 1, 3, 1))
print(x.shape)
x_rep = x.repeat(2, 3, 1, 6)
print(x_rep.shape)
//torch.Size([2, 1, 3, 1])
//torch.Size([4, 3, 3, 6])
其它:
permute(dims):根据填入的dims交换原来的dims。
x = torch.linspace(1, 30, steps=30).view(3, 2, 5)
b = x.permute(0, 2, 1)
contiguous():
torch.contiguous()方法首先拷贝了一份张量在内存中的地址,然后将地址按照形状改变后的张量的语义进行排列。很多操作比如view依赖连续内存,所以经常需要和contiguous结合使用。建议直接reshape=view + contiguous。
Broadcasting(广播):自动实现了若干unsqueeze和expand操作,以使两个Tensor的shape一致,从而完成某些操作(往往是加法)。
A = torch.arange(24).reshape(2,3,2,2) // 图片输入
B = 3 // 偏置
print(A + B) // 自动扩展后求和
torch.cat([a, b], dim):
沿着某一dim进行tensor拼接,但是要求除了待拼接的维度可以不一致,其它维度必须相同。
torch.stack([a, b], dim):
先扩展维度再拼接,在新增加的维度进行堆叠。注意a.shape = b.shape
torch.matmul(a, b):
效果和运算符@一致,矩阵相乘。
满足Broadcasting条件的会先进行Broadcasting。
a = torch.ones(2, 1, 3, 4)
b = torch.ones(5, 4, 2)
c = torch.matmul(a, b) // torch.Size([2, 5, 3, 2])
torch.split(a, dim):
按照长度拆分,a为指定的长度(每一个子段),dim为待拆分的维度。
a = torch.rand(4, 5, 4) // torch.Size([4, 5, 4])
a1, a2 = a.split([3, 1], dim=0) // torch.Size([3, 5, 4]) torch.Size([1, 5, 4])--如果每段长度一致,不用写[],写每段的长度值就行
torch.chunk(a, dim):
按照数量拆分,a为所需拆得的数量
a = torch.rand(4, 5, 4) // torch.Size([4, 5, 4])
a1, a2 = a.chunk(2, dim=0) // torch.Size([2, 5, 4]) torch.Size([2, 5, 4])
torch.floor/ceil/trunc/frac/clamp():
a = torch.tensor(3.14)
print(a.floor()), print(a.ceil())
print(a.trunc()), print(a.frac()) // 分离整数小数部分
//torch.clamp(input, min, max, out=None)--限制值的范围
a = torch.tensor([[3.14, 2.18, 6.45], [4.16, 7.64, 8.17]])
print(a.clamp(5, 6))
print(torch.clamp(a, 5, 6))
1.2 Tensor属性:
1.torch.dtype:数据类型
2.torch.device:存储设备
3.torch.layout:内存布局
a = torch.tensor([1, 2, 3], dtype=torch.float32, device='cpu')
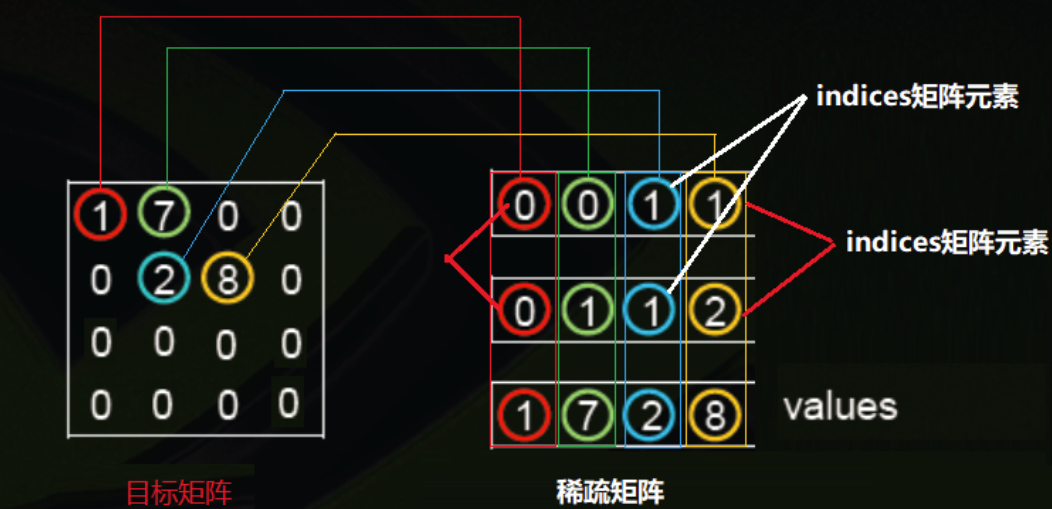
1.3 稀疏张量:
参考资料:https://blog.csdn.net/HiWangWenBing/article/details/119615940
稀疏张量指矩阵中的大多数元素的值都为0,由于其中非常多的元素都是0,使用常规方法进行存储非常的浪费空间,所以采用indices+values矩阵来描述和定义稀疏矩阵。
indices是一个张量,张量中的最内层的向量表示了稠密矩阵中非零元素的位置。
values是一个一维向量,是有稠密矩阵中非零元素的数值组成的序列。
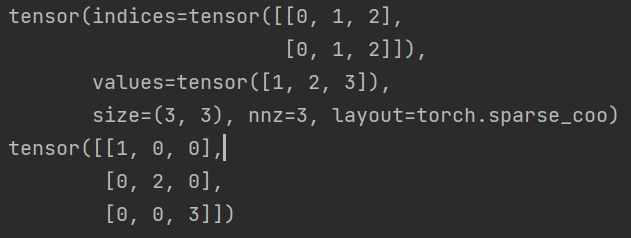
indices = torch.tensor([[0, 1, 2], [0, 1, 2]])
values = torch.tensor([1, 2, 3])
a = torch.sparse_coo_tensor(indices, values, (3, 3))
print(a) // 输出稀疏张量
print(a.to_dense()) // 输出对应的稠密形式
2.数据集划分和CheckPoints(待补充)
一般将数据集划分为:
Train Set:用于训练。
Val Set:用于验证。
Test Set:用于测试。
之所以要有Val Set,实际上工作和竞赛中是不会给你Test Set的,所以需要自己划分一个Val Set用于验证训练结果,防止过拟合(如果train的效果很好,但是test的效果很差,说明泛化能力很差,很有可能是过拟合了)。
关于CheckPoints:
一般会根据Train和Val的结果,将较好的状态的权重记录下来,作为一个checkpoint。此外,在训练时间较长的时候,也可以通过保存的checkpoint作为断点,从该状态继续进行训练。最好的checkpoint将作为test时的状态进行网络性能的测试。
数据集划分方法:以CIFAR-10为例
import torchvision
from torch.utils.data import DataLoader, random_split
train_set = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(), download=False)
test_set = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=False)
print('train:', len(train_set), 'test:', len(test_set)) // 查看训练集的样本数
train_set, val_set = random_split(train_set, [40000, 10000]) // 将50000个训练样本划分为:40000训练10000验证
print('train:', len(train_set), 'val:', len(val_set))
train_dataloader = DataLoader(train_set, batch_size=64) // 加载train_set
val_dataloader = DataLoader(val_set, batch_size=64) // 加载val_set
3.Autograd
- torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False) – 自动求取梯度
tensors:用于求导的张量,如 loss
retain_graph:通常一次backward后计算图自动销毁,该参数为True用于保存计算图进行多次求导
create_graph:创建导数计算图,用于高阶求导
grad_tensors:多梯度权重 - torch.autograd.grad(outputs, inputs, grad_outputs=None, retain_graph=None, create_graph=False) — 计算和返回out关于in的梯度的和
outputs:用于求导的张量,如 loss
inputs:需要梯度的张量,可以定义多个tensor
4.正则化
loss其实是风险最小化。
正则化是结构最小化,L1正则是对L0正则的逼近,由于L1有不可导点,用L2正则对L1正则逼近。pytorch自带L2正则(weight_decay):
optimizer = torch.optim.Adam(net.parameters(), lr=0.001, weight_decay=0.001)
5.卷积层
5.1 参数量与计算量

5.2 压缩参数量与计算量
基本要求:感受野不变,减少参数量。
方法:小卷积核代替大卷积核;深度可分离卷积;channel shuffle;pooling;加大步长等。
6.Dropout

7.分类模型优化思路
参考:https://www.imooc.com/article/305024
7.1 调参技巧
1.Backbone:根据任务需求选择主干网络。
2.过拟合:降低网络复杂度。
3.学习率调整:初始学习率和衰减方式。
4.优化函数
5.数据增强:亮度,对比度,饱和度,裁剪,旋转。
6.使用更好的loss
7.预训练模型
8.加大batchsize
9.使用不同的权重初始化方法
针对拟合程度较为合适的网络:
主要目的在于优化网络结构,在保持性能的前提下尽可能实现更小,更轻量的网络结构,减少参数量以降低计算代价,减少对内存等资源的占用。
手段比如:减少网络层数;减少不同层的参数主要是卷积核数量;考虑深度可分离卷积等轻量卷积结构。
针对欠拟合网络:
主要目的:增强拟合能力
手段:加大eopch;进一步衰减调小学习率;添加更多层;去掉正则化约束;加入BN层加快收敛;增强网络的非线性度;优化数据集进行数据清洗。
针对过拟合网络:
主要目的:降低拟合能力
手段:增加样本数量;数据增强;早停,在loss不再下降时停止;增加网络稀疏度;降低网络深度;正则化;Dropout;适当降低学习率;适当减少epoch。
针对收敛但是振荡的网络:
情况描述:网络在训练集上已经趋于收敛,但是在测试集上存在很严重的LOSS震荡的情况。
可能原因:测试集和训练集分布存在较大差异;数据增强过度;学习率是否过高;测试集loss的计算方式是基于单个batch还是整个测试集(应该基于整个测试集);网络是否存在欠拟合。
针对完全不收敛的网络:
照自己定义的LOSS函数估计下,全部为0的时候LOSS是多少,就可以大致估计出LOSS要低于多少网络才能算作是收敛了。
不收敛的原因可能是:
输入数据和与处理环节可能有错误;数据增强可能有问题;标签问题;网络设计或参数问题;loss和优化是否合理;设计的算法本身存在问题。















 113
113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









