







基本说明:
在Excel中输入函数时是不区分大小写的,无论是大写还是小写,结束函数编辑时,Excel会自动转化为大写。对于函数中的参数,当参数是文本时,要用双引号引起来,单纯的数字不需要加双引号,除非这个数字是文本性数字;如果数字前面有比较运算符,也要加双引号。此外,在编辑公式与函数时,函数中的标点符号都是英文状态下的标点符号。
示例:IF(A2>100,1000,"无奖金")、 COUNTIF(B:B,">10")。
在Excel中输入公式与函数时,若函数只有一对括号可以不用输入右括号,若函数有多对括号,则要输入所有的括号。
1)逻辑函数
在逻辑判断中,0表示FALSE,所有非零数值表示TRUE。
# IF函数:
IF(logical_test,[value_if_true],[value_if_false]),IF函数执行真假值判断,并根据逻辑测试值返回不同的结果:如果逻辑测试值的结果为TRUE,IF函数将返回第二个参数值,如果逻辑测试值的结果为FALSE,IF函数将返回第三个参数值。
##// 注意IF函数的嵌套使用:
如 IF(F2>=4,5000,IF(F2>=2,3000,0))或者是IF(F2<2,0,IF(F2<4,3000,5000)),前者与后者是等价的。
补充说明:在Excel 2010中,IF函数最多可以嵌套64层。
# AND()函数:
AND(logical1,logical2,...),它的功能是判断多个条件是否同时成立:当所有参数的计算结果都为TRUE时,AND函数返回TRUE;当所有参数的计算结果中只要有一个为FALSE,则AND函数返回FALSE。
示例:IF(AND(F2>=4,E2="A类"),5000,0)
# OR()函数:
OR(logical1,logical2,...),它的功能是判断多个条件中是否至少有一个成立:在其参数组中,任何一个参数逻辑值为TRUE,则OR函数返回TRUE;当所有参数的逻辑值都为FALSE时,OR函数才返回FALSE。
示例:IF(OR(F2>=4,D2>=10),5000,0)
##// AND与OR函数的嵌套使用示例:IF(OR(F2>4,AND(E2="A类",D2>=10)),5000,0)
# NOT()函数:
NOT(logical),它是对逻辑值求反:如果输入参数的逻辑值为FALSE,NOT函数返回TRUE;如果输入参数的逻辑值为TRUE,NOT函数返回FALSE。
补充说明:AND、OR、NOT这三个函数很少单独使用,一般都是与其它函数嵌套使用。
# IFERROR()函数:
IFERROR(value,value_if_error):它的功能是根据传入的参数是否是错误值返回指定的值。参数列表中,第一个参数表示传入的待判断的值(如果第一个参数value表示的值不是错误值时,IFERROR()函数就返回value),第二个参数表示当第一个参数表示的值为错误值时,IFERROE()函数应返回的结果。
2)查找函数
# VLOOKUP函数:
VLOOKUP(lookup_value,table_array,col_index_num,[range_lookup]),它的功能是在区域或数组的第一列查找相应的数据,返回与指定值(查找区域第一列中与要查找的值匹配的值)同行的该区域或数组中相应列的值。参数列表中,第一个参数表示要查找的值,第二个参数表示要查找的区域,第三个参数是返回的值所在区域的列号,第四个参数是查找的类型。
示例:VLOOKUP(B2,$E$2:$F$13,2,1)
补充说明1:查找的区域要采用绝对引用(避免查找结果出错),或者是为要查找的数据区域命一个名,然后将要查找的区域换成它的名称(自定义名称默认是绝对引用);使用VLOOKUP函数查询的时候只能在查询区域的第一列进行查询,也就是说只能用查找区域第一列中的数据与要查找的值进行匹配,从而查找出与要查找的值相对应的值。查找的类型分为模糊查找和精确查找,TRIUE/1表示模糊查找,FALSE/0表示精确查找,对于模糊查找,查找区域的第一列一定要是按升序排列的(避免查询结果出差),对于精确查找,查询区域的第一列可以是无序的。
补充说明2:当要查找的值或者查询区域为数值型数据类型时,一般采用模糊查找;当要查找的值或者查询区域是姓名、证件号、编号等文本型数据时,一般采用精确查找。
# HLOOKUP()函数:
HLOOKUP(lookup_value,table_array,row_index_num,[range_lookup])
它的函数结构于VLOOKUP()函数完全一样的,只不过是把VLOOKUP()函数中的列换成行。
示例:HLOOKUP(B2,$H$2:$S$3,2,1)
##// VLOOKUP()函数和HLOOKUP()函数的比较:VLOOKUP中的V是Vertical首字母,意为垂直的,VLOOKUP函数可以理解为按列查找;HLOOKUP中的H是Horizontal的首字母,意为水平的,HLOOKUP函数可以理解为按行查找。
##// 注意VLOOKUP()函数的嵌套使用。
# Match()函数:
Match(lookup_value,lookup_array,[match_type]):它的功能是在查找区域中搜索指定项,并返回该项在查找区域中的位置,这个位置可以是查找区域的行号也可以是列号。参数列表中,第一个参数表示要查找的值,第二个参数表示查找的区域,第三个参数表示查找的类型。
补充说明:查找的区域一般采用绝对引用,而且查找的区域只能是一行或者是一列,不能选择多行或多列;查找的类型有三种:1或者省略表示模糊查找,查找小于或等于lookup_value的最大值,如果找不到要查找的值,就返回小于查找值的最大值的位置,这种情况的前提是查找的区域是按照升序排列的;0表示精确查找,此时查找的与区域可以是无序的;-1也表示模糊查找,查找大于或等于lookup_value的最小值,如果找不到要查找的值,就返回大于查找值的最小值的位置,这种情况的前提是查找的区域是按照降序排列的。
# INDEX()函数:
INDEX(array,row_num,[column_num]):它的的功能是根据输入参数返回指定位置(包括要查找的值所在区域的行号、要查找的值所在区域的列号)的值。参数列表中,第一个参数表示要查找的区域,第二个参数表示要查找值所在区域的行号,第三个参数表示要查找的值所在区域的列号。
补充说明1:函数INDEX(array,row_num,[column_num])中当参数array所表示的数据区域只有一列时,第三个参数的值只能是0或1或省略,而且这三个值对函数最后的返回结果没有影响。
补充说明2:当INDEX()函数MATCH()函数的嵌套使用时,如果要利用单元格的自动填充功能,需要把INDEX()函数和MATCH()函数的查找区域都设置为绝对引用。
补充说明3:INDEX()函数还有另外一种用法,形如INDEX(reference,row_num,[column_num],[area_num]),它与INDEX(array,row_num,[column_num])的功能相同,只不过传入的数据区域变成非连续的数据区域。参数列表中,第一个参数表示传入的非连续数据区域,第二个参数表示要查找的值在指定数据区域内的行号,第三个参数表示要查找的值在指定数据区域内的列号,第四个参数表示要查找的值在第几个数据区域。其中reference参数所表示的非连续数据区域整体要用括号括起来,非连续数据内每个单独的区域之间要用","隔开。
示例:非连续数据区域可以如下图所示
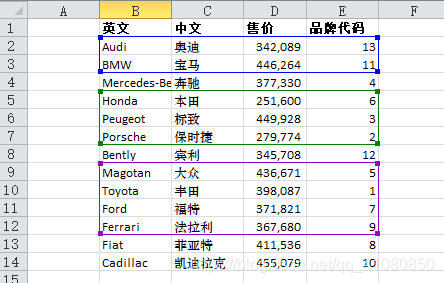
则函数INDEX((B2:E3,B5:E7,B9:E12),2,1,3)表示要查找的值位于第三个数据区域中的第二行第一列,因此函数的返回结果是"Toyota"。
# LOOKUP()函数:它的功能是根据输入参数返回要查找的指定值。
向量形式:形如LOOKUP(lookup_value,lookup_vector,result_result),参数列表中,第一个参数表示要查找的值,第二个参数表示查找区域,而且查找区域必须为单行或单列数据,第三个参数表示返回的结果所在的区域,这个区域也必须是单行或单列的数据。
补充说明:使用向量形式的LOOKUP()函数进行查找的时候,查找区域的数据必须是按照升序排列的。
数组形式:形如LOOKUP(lookup_value,array),参数列表中,第一个参数表示要查找的值,第二个参数表示查找的区域,查找区域为多行多列数据也就是数组形式的区域。LOOKUP()的数组形式可以理解为在查找区域的首列进行查找,返回查找区域的最后一列中的相应值,这种情况的前提是查找区域的行数要大于列数。如果查找区域的列数大于行数,则查找的规则就变成在第一行查找,返回最后一行中的相应值。
补充说明:使用数组形式的LOOKUP()函数进行查找的时候,查找区域第一列的数据必须是按照升序排列的。
# CHOOSE()函数:
CHOOSE(index_num,value1,[value2],[value3],...):它的功能是根据序号从数值参数列表中选择对应的内容。参数列表中,第一个参数就表示序号,第一个参数后面的所有参数组成一个数值参数列表。
示例:把带有月份的日期转换呈相应的季度:CHOOSE(MONTH(A2),1,1,1,2,2,2,3,3,3,4,4,4)。
3)统计函数
# count系列函数:
count(range):它的功能是统计输入参数所表示的区域中包含的数值性数字的个数;
counta():它的功能是统计输入参数所表示的区域中包含的非空值单元格的个数;
countblank():它的功能是统计输入参数所表示的区域中包含的空白单元格的个数。
补充说明:这三个函数很少单独使用,一般都是与其它函数嵌套使用。
# 条件系列函数:
条件计数函数countif(range,creteria):它的功能是根据判断条件统计条件区域内指定值的个数。参数列表中,第一个参数表示条件计数的区域,第二个参数表示判断的条件。
多条件计数函数countifs(criteria_range1,criteria1,criteria_range2,criteria2,...)函数:它的功能是统计满足多个条件的相应记录的个数。参数列表中,第一个和第二个参数分别是条件区域1和判断条件1,第三个和第四个参数分别是条件区域2和判断条件2,以此类推······
条件求和函数sumif(range,criteria,[sum_range]):它的功能是根据判断条件与条件区域的匹配关系求取求和区域中相应值的和。参数列表中,第一个参数是条件区域,第二个参数是判断条件,第三个参数是求和区域。
补充说明:使用sumif()函数时要注意单元格地址的绝对引用与相对引用问题。
条件求平均值函数averageif(range,criteria,[average_range]):它的函数结构与sumif()函数一样,只不过其功能由条件求和变成了条件求平均值。
多条件求和函数sumifs(sum_range,criteria_range1,criteria1,criteria_range2,criteria2,...):它的功能是根据多个判断条件与条件区域的匹配关系求取求和区域中相应值的和。参数列表中,第一个参数表示求和区域,第二个和第三个参数分别表示条件区域1和判断条件1,第四个和第五个参数分别表示条件区域2和条件2,以此类推……
补充说明:使用sumifs()函数时要注意单元格地址的绝对引用与相对引用问题。
多条件求平均值函数averageifs(average_range,criteria_range1,criteria1,criteria_range2,criteria2,...):它的函数结构与sumifs()函数一样,只不过其功能由多条件求和变成了多条件求平均值。
# MEDIAN()函数:它的功能是求取一组数据中的中位数。当数据的个数是偶数个时,MEDIAN()函数求的中位数是该组数据中间两个数的平均值。求取中位数时,数据区域要按照升序或者降序排列好。
# MODE()函数:它的功能是求取一组数据中的众数。
# 排位系列函数:
RANK(number,ref,[order])函数:它的功能是返回指定值在指定数据区域内的排位。参数列表中,第一个参数表示待排位的数字,第二个参数表示排位的数字区域,第三个参数表示排位的类型(0或者省略表示按照降序排位,1表示按照升序排位)。
RANK.EQ(number,ref,[order])函数:与RANK(number,ref,[order])函数完全相同。
RANK.AVG(number,ref,[order])函数:返回结果与前面两个函数稍微有些不同(具体可以通过实际操作观察)。
# LARGE(array,k)函数:它的功能是返回一组数据中第k大的值。参数列表中第一个参数表示数据区域,第二个参数表示要求的数据区域中第几大的值。
# SMALL(array,k)函数:它的函数结构与LARGE(array,k)函数相同,只不过是其功能由求一组数据中低级大的值变成了求一组数据中第几小的值。
4)引用函数
# OFFSET()函数:
OFFSET(reference,rows,cols,[height],[width]):它的功能是根据给定的偏移量返回新的引用区域。参数列表中,第一个参数是参照点,第二个参数是行偏移量,第三个参数是列偏移量,第四个参数是可选参数(可选参数是被方括号"[]"括起来的),表示返回的引用区域的行数,第五个参数也是可选参数,表示返回的引用区域的列数。
补充说明:参数列表中的数值性参数也可以是负数,负数表示朝相反的方向引用。
# INDIRECT()函数:
INDIRECT(ref_text,[a1]):它的功能是返回一个由文本字符串指定的引用。参数列表中,第一个参数表示引用的文本,第二个参数为可选参数表示引用的类型(实际工作中一般第二个参数都省略)。
补充说明:在一个工作簿内部跨工作表引用另外一张表中某个单元格的方式是,在单元格内输入
="被引用工作表的名称!被引用单元格的地址"即可。
示例:如在同一个工作簿的汇总表中引用2009年度这张工作表里面的B8单元格,可以在指定位置的单元格里面输入="2009年度!B8"。
# ROW()系列函数:
ROW()函数里面可以有参数也可以无参数,没有参数就返回公式所在单元格的行号,有参数时,如果输入参数是某个单元格的引用,则ROW(reference)返回该引用单元格所在的行号。如果要引用整行,例如引用第一行可以写成ROW(1:1)或者写完ROW( 后点击第一行的行号。
# COLUMN()函数:它的函数结构与ROW()函数完全相同,只不过其功能由返回行号变成返回列号。
# ROWS([array])函数:它的功能是返回输入参数所占有的行数;
# COLUMNS([array])函数:它的功能是返回输入参数所占有的列数。
5)数学函数
# ROUND系列函数:
ROUND(number,number_digits):它的功能是返回对传入数值按指定位数进行四舍五入后的值。参数列表中第一个参数是待四舍五入的数字,第二个参数是四舍五入后要保留的小数位数(第二个参数还可以是负数,例如,第二个参数如果是-2的话,ROUND()函数返回的值就是四舍五入到百位的数。如ROUND(234.12,-2)=200。
补充说明:对于Excel单元格中的数值x,点击增加或减少数值小数位数的按钮来改变数值x后的小数位数,这仅仅改变了数值x显示的方式,并没有改变数值x的实际值。
ROUNDUP(number,num_digits):它的功能是对传入的数值按照指定的位数进行向上舍入。参数列表中,第一个参数表示待四舍五入的数,第二个参数表示四舍五入后要保留的小数位数。(第二个参数同样可以是负数,例如,第二个参数如果是-2的话,ROUND()函数返回的值就是四舍五入到百位数)。如ROUNDUP(34.234,2)=34.24。
ROUNDDOWN(number,num_digits):它的函数结构与ROUNDUP()函数完全相同,只不过其功能变成对传入的数值按照指定的位数进行向下舍入。
# 取整函数:
INT(number):它的功能是返回对传入数值取整后的值。如果传入的值是整数,则INT()函数进行正常的取整,如果传入的数值是负数,INT()函数则会先取传入数值的绝对值,再对绝对值进行向上取整。如,INT(-11.6)=12。
TRUNC(number,[num_digits]):如果没有给TRUNC()函数传入可选参数num_digits,TRUNC()函数会将传入数值的小数部分截去,并返回相应的值(被截去的小数部分可能会补0);如果给TRUNC()函数传入了可选参数num_digits,TRUNC()函数会按照传入参数num_digits指定的保留位数截去传入数值的小数部分(被截去的小数部分可能会补0)。
示例1:TRUNC(1025.5685)=1025.0000
示例2:TRUNC(1025.5685,2)=1025.5600
补充说明:TRUNC()函数的可选参数num_digits可以是负数。例如TRUNC(234.13,-1)=230.00。
# MOD()函数:
MOD(number,divisor):它的功能是返回两数相除后的余数。参数列表中,第一个参数是被除数,第二个参数是除数。
# RAND()函数:
RAND():RAND()函数没有参数,它的功能是返回范围在0~1之内的随机数。
# RANDBETWEEN()函数:
RANDBETWEEN(bottom,top):它的功能是返回两个指定的数之间的一个随机整数。参数列表中,第一个参数是要返回的最小值(返回结果可以取到),第二个参数是要返回的最大值(返回结果也可以取到)。
补充说明:RANDBETWEEN()函数还可以返回两个指定日期之间的日期
# CONVERT()函数:
CONVERT():它的功能是将传入的数值从一个度量系统转换到另一个度量系统。并返回转换后的值。参数列表中,第一个参数是传入的要转换单位数值,第二个参数转换前的某个度量系统里的单位,第二个参数是要转换的目标度量系统里的单位。
6)日期时间函数
# 日期与时间本质:在Excel中日期和时间本质上就是数值,只是外观显示成一种日期时间格式的样子。Excel规定1900年1月1日为1,以此类推。日期转换成数值后,它的整数部分表示日期,小数部分表示时间。
# 在单元格中插入当前系统日期的快捷键:<Ctrl+;> ,插入当前时间的快捷键是<Ctrl+Shift+;>
# TODAY()函数:
TODAY():这个函数没有参数,其功能是返回当前系统的日期。而且它是一个动态函数,会随着工作表的更新而更新。
# NOW()函数:它的函数结构与TODAY()函数完全一样,只不过其功能是返回当前系统的时间。
# 提取日期系列函数:
YEAR(serial_number):它的功能是提取并返回传入的日期参数中的年份。
MONTH(serial_number):它的功能是提取并返回传入的日期参数中的月份。
DAY(serial_number):它的功能是提取并返回传入的日期参数中的日。
补充说明:与提取日期函数相对的是合并日期函数DATE(year,month,day),它可以将位于不同单元格的年、月、日合并到同一单元格中。
# 提取时间系列函数:
HOUR(serial_number):它的功能是提取并返回传入的时间参数中的小时。
MINUTE(serial_number):它的功能是提取并返回传入的时间参数中的分钟。
SECOND(serial_number):它的功能是提取并返回传入的时间参数中的秒。
补充说明:与提取时间函数相对的是合并时间函数TIME(hour,minute,second),它可以将位于不同单元格的小时、分钟、秒合并到同一单元格中。
# WEEKDAY()函数:
WEEKDAY(serial_number,[return_type]):它的功能是将传入的具体的日期转化为相应的星期几,并返回转换后的值。参数列表中,第一个参数是待判断星期几的日期,第二个参数是可选参数,它返回的值与日期之间关系的类型(例如,第二个参数若为1或者省略,则返回值中1表示星期日,6表示星期天。第二个参数为其它值时的情况,具体可参见使用WEEKDAY()函数时Eexcel给出的参数提示)。
# NTETWORKDAYS()函数:
NETWORKDAYS(start_date,end_date,[holidays]):它的功能是计算并返回传入的两个指定日期之间所有的工作日。参数列表中,第一个参数表示开始日期,第二个参数表示结束日期,第三个参数为可选参数,表示要剔除的节假日。
# WORKDAY()函数:
WORKDAY(start_date,days,[holidays]):它的功能是计算并返回传入的指定日期向前(此时第二个参数为负数)或者向后(此时,第二个参数为正数)数个工作日后的日期。参数列表中,第一个参数表示开始日期,第二个参数表示工作日(不含星期六和星期天)的天数,第三个参数为可选参数,表示要剔除的节假日。
# EOMONTH()函数:
EOMONTH(start_date,months):它的功能是返回传入的指定日期向前(此时第二个参数为负数)或者向后(此时第二个参数为正数)几个月的那个月的最后一天日期。参数列表中,第一个参数表示开始日期,第二个参数表示向前或者向后的月数(例如,如果第二个参数的值为0,则表示函数返回指定日期当月的最后一天的日期)。
示例1:EOMONTH("2018-09-07",0)="2018-09-30"
示例2:EOMONTH("2018-09-07",-1)="2018-08-31"
# EDATE()函数:
EDATE(start_date,months):它的功能是返回传入的指定日期向前或者向后几个月的日期。参数列表中,第一个参数表示开始日期,第二个参数表示向前或者向后的月数。
示例:EDATE("2018-09-07",2)="2018-11-07"
# DATEDIF()函数:
DATEDIF(start_date,end_date,unit):它的功能是计算并返回传入的两个指定日期的之间的间隔。参数列表中,第一个参数表示开始日期,第二个参数表示结束日期,第三个参数表示两个指定日期之间间隔时间的单位。
补充说明:第三个参数可以分别为:y表示时间间隔以年为单位;m表示时间间隔以月为单位;d表示时间间隔以天为单位;ym表示时间间隔是忽略传入的两个指定日期的年份后它们之间相差的月数;yd表示时间间隔是忽略传入的两个指定日期的年份后它们之间的天数差;md表示时间间隔是忽略传入的两个指定日期的年份和月份后它们之间的天数差。
示例1:DATEDIF("2010-08-06","2013-05-22","y")=2
示例2:DATEDIF("2013-08-06","2013-11-15","m")=3
示例3:DATEDIF("2012-08-15","2013-09-04","d")=385
示例4:DATEDIF("2008-04-05","2013-05-11","ym")=1
示例5:DATEDIF("2012-03-21","2013-03-25","yd")=189
示例6:DATEDIF("2011-12-19","2013-03-25","md")=6
7)文本函数
# LEN()函数:
LEN(text):它的功能是返回传入的文本字符串中的字符数。
# LENB()函数:
LENB(text):它的功能是返回传入的文本字符串中字符占用的字节数。
# FIND()函数:
FIND(find_text,within_text,[start_num]):它的功能是查找指定字符(区分大小写)在指定的查找文本中第一次出现的位置,并返回查找结果。参数列表中,第一个参数表示要查找的字符(字符串),第二个参数表示查找的区域(在那个文本中查找),第三个参数为可选参数表示查找开始的位置(字符串中的位置从1开始计数,当第三个参数省略时,默认从字符串中的位置1开始查找)。
# SEARCH()函数:
SEARCH(find_text,within_text,[start_num]):它的函数结构和FIND()函数完全一样,只不过查找时不区分大小写。
# MID()函数:
MID(text,start_num,num_chars):它的功能是从传入文本的指定位置,提取并返回指定个数的字符。参数列表中,第一个参数表示要从中提取字符的文本,第二个参数表示要提取字符的开始位置,第三个参数表示要提取字符的个数。
补充说明:FIND()函数可以和MID()函数嵌套使用,用于提取文本中指定的字符。
# LEFT()函数:
LEFT(text,[num_chars]):它的功能是从输入文本的左侧提取并返回指定个数的字符。参数列表中,第一个参数表示要提取字符的文本,第二个参数为可选参数,表示要提取的字符个数。
# RIGHT()函数:
RIGHT(text,[num_chars]):它的函数结构和LEFT()函数完全一样,只不过是从传入文本的右侧提取字符。
# TRIM()函数:
TRIM(text):它的功能是将传入文本前后的空格和中间多余的空格删除,但仍会在文本中间保留一个空格。
补充说明:要想清除文本中的所有空格,我们可以用替换的方法,将文本中的所有空格替换成""。
# CLREAN()函数:
CLWEAN(text):它的功能是清除传入的文本中的非打印字符。
# CONCATENATE()函数:
CONCATENATE(text1,[text2],...):它的功能时将传入的多个文本合并并返回合并后的结果。
补充说明:一般情况下,要完成相同的连接目标,使用连字符"&"比CONCATENATE()函数要简单。
# 处理英文的函数:
PROPER(text):它的功能时将传入文本中每个单词的首字母转换成大写,并返回转换后的结果。
UPPER(text):它的功能是将传入文本中的字母全部转换成大写,并返回转换后的结果。
LOWER(text):它的功能是将传入文本中的字母全部转换成小写,并返回转换后的结果。
# 文本替换函数REPLACE()和SUBSTITUTE():
REPLACE(old_text,start_num,num_chars,new_text):它的功能是以字符为单位,根据指定的位置对传入的文本参数进行替换,并返回替换后的结果。参数列表中,第一个参数表示要在其中替换字符的文本,第二个参数表示替换的起始位置,第三个参数表示要替换的字符个数,第四个参数表示要替换成什么样的文本。
示例1:REPLACE("2018-RR-09",5,1,"")="2018RR-09"
示例2:REPLACE("2018-RR-09",5,2,"OO")="2018OOR-09"
示例3:REPLACE("2018-RR-09",5,2,"O")="2018OR-09"
SUBSTITUTE(text,old_text,new_text,[instance_num]):它的功能是根据指定的文本对传入的文本参数进行替换,并返回替换后的结果。参数列表中,第一个参数表示要在其中替换字符的文本,第二个参数表示要替换掉的文本,第三个参数表示替换后的新文本,第四个参数为可选参数表示替换第几次出现的文本(第四个参数如果省略,则默认替换text中出现的所有形如old_text的文本)。
示例1:SUBSTITUTE("2018-RR-09","-","",2)="2018-RR09"
示例2:SUBSTITUTE("2018-RR-09","-R","X",1)="2018XR-09"
# TEXT()函数:
TEXT(value,format_text):它的功能是将传入的数字转换成按照指定格式显示的文本。参数列表中第一个参数表示要设置格式的数字,第二个参数表示格式设置的代码。
示例:TEXT("4008008020","000-000-0000")=400-800-8020
8)信息函数
# ISTEXT()函数:
ISTEXT(value):它的功能是判断传入的参数是否是文本,并返回判断结果。
# ISNUMBER()函数:
ISNUMBER(value):它的功能是判断传入的参数是否是数值,并返回判断结果。
# ISNONTEXT()函数:
ISNONTEXT(value):它的功能是判断传入的参数是否是非文本(数值和空单元格),并返回判断结果。
# ISBLANK()函数:
ISBLANK(value):它的功能是判断传入的参数是否是空单元格,并返回判断结果。
# ISERROR()函数:
ISERROR(value):它的功能是判断传入的参数是否是错误值(这个错误值包含Excel中所有可能的错误值),并返回判断结果。
# IFERROR()函数:
IFERROR(value,value_if_error):它的功能是判断传入的参数是否是错误值,并根据判断结果返回相应的值。若传入的参数不是错误值,则返回value代表的公式计算的结果,反之返回指定的代表错误值的结果。
9)数组公式
数组公式的应用场景:当公式与函数的返回结果有多个值,或者想对公式与函数的返回结果进行多项计算时,这个时候可以选择使用数组公式(用<Ctrl+SHift+enter>键确定输入)。
示例1:{=C3:C15*D3:D15}
它返回的是C3:C15与D3:D15对应单元格里值的乘积(一共有13个积)。因为它的返回结果有多个值,所以应该先选中多个单元格,然后再输入数组公式。
示例2:{=SUM(C3:C15*D3:D15)},它返回的是C3:C15与D3:D15对应单元格里值的乘积之和。
补充说明:上述两个示例中的{}并不是手动添加上去的,而是在向单元格中输入公式与函数完成后,按<Ctrl+SHift+enter>键时自动添加的。
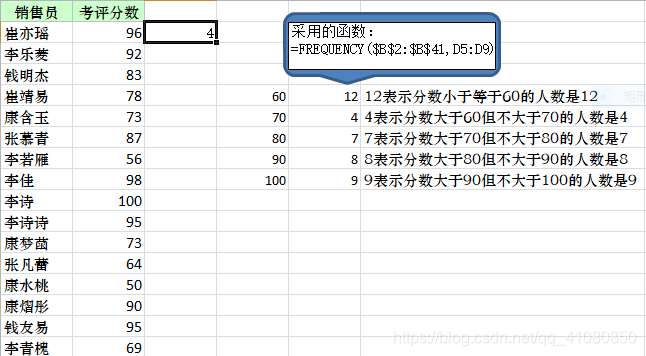
# FREQUENCY()函数:
FREQUENCY(data_array,bins_array):它的功能是以垂直数组的形式返回传入的数据在指定的范围内出现的频数(可以理解为分组统计)。参数列表中,第一个参数表示传入的要分组统计的数据,第二个参数表示设置的频率分布的区间。
补充说明:注意FREQUENCY()函数返回的结果是多个值,也可以说是一个数组。
示例(图片中左边的数据只是其中的一部分):
# TRANSPOSE()函数:
TRANSPOSE(array):它的功能是对传入数组或者数据区域进行行列转置,并返回转置后的结果。TRANSPOSE()函数可以用于一维表和二维表之间的相互转换。
补充说明1:TRANSPOSE()函数是要以数组公式的形式输入的,函数输入完成后要按<Ctrl+SHift+enter>组合键才能得到返回结果。
补充说明2:要向实现转置的目的,除了使用TRANSPOSE()函数外,还可以使用Excel中的选择性粘贴功能。二者的区别是对于TRABSPOSE()函数实现的转置,原表与转换后的表之间的数据是联动(就是说转置后的表中的数据会随着原表中的数据的变动而变动)的;对于使用选择性粘贴功能实现转置,原表与转置后的表之间的数据不存在联动关系。
# 将数组公式应用于查找中:
此时应该注意单元格的相对引用与绝对引用问题。
注:本文主要参考刘伟的视频教程《Excel 2010公式与函数》。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









