






目录
视频案例,可以查看Bilibili MindStudio模型推理场景精度比对全流程和结果分析:
【经验分享】MindStudio模型推理场景精度比对全流程和结果分析
1、MindStudio介绍
MindStudio提供在AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务,依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助您在一个工具上就能高效便捷地完成AI应用开发,MindStudio采用了插件化扩展机制,开发者可以通过开发插件来扩展已有功能。本实验使用的MindStudio版本为5.0.RC3,安装请参考MindStudio安装教程。
2、交付件介绍
(1)精度对比简介
在下面两种情况下,自有实现的算子在昇腾AI处理器上的运算结果与业界标准算子(如Caffe、ONNX、TensorFlow、PyTorch)的运算结果可能存在差异。
-
在模型转换过程中对模型进行了优化,包括算子消除、算子融合、算子拆分,这些动作可能会造成自有实现的算子运算结果与业界标准算子(如Caffe、TensorFlow、ONNX)运算结果存在偏差。
-
用户原始网络可以迁移到昇腾910 AI处理器上执行训练,网络迁移可能会造成自有实现的算子运算结果与用业界标准算子(如TensorFlow)运算结果存在偏差。
(2)实现流程
为了帮助开发人员快速解决算子精度问题,需要提供自有实现的算子运算结果与业界标准算子运算结果之间进行精度差异对比的工具。
MindStudio精度比对工具提供Tensor比对能力,包含余弦相似度、欧氏相对距离、绝对误差(最大绝对误差、平均绝对误差、均方根误差)、相对误差(最大相对误差、平均相对误差、累积相对误差)、KL散度、标准差算法比对维度。精度比对总体流程如下:
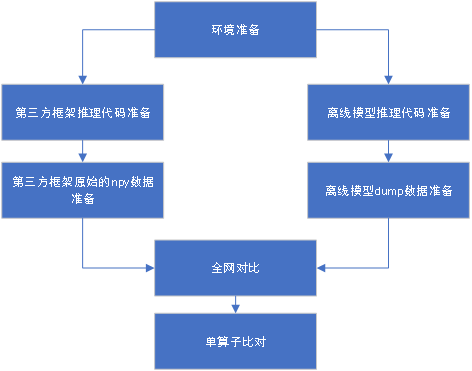
(3)代码工程
本实验基于MindStudio的代码工程结构如下所示。
本实验基于MindStudio的代码工程结构如下所示。
├── caffeResnet50_49048f18
│ ├── acl_net.py //离线模型推理脚本代码
│ ├── caffe_dump.py //原始模型推理脚本代码
│ ├── caffe_model //原始模型文件存储目录
│ │ ├── resnet50.caffemodel
│ │ └── resnet50.prototxt
│ ├── caffeResnet50.iml
│ ├── constant.py //离线模型推理脚本工具脚本
│ ├── data //数据文件夹
│ │ └── img.png
│ ├── dump //离线模型dump数据文件夹
│ ├── model //离线模型文件夹
│ │ └── resnet50.om
│ ├── npy_dump //原始模型dump数据文件夹
│ ├── output //精度比对输出文件夹
│ │ └── 20221111205145
│ └── src
│ └── acl.json //离线模型dump构造文件
(4)文章介绍
文章详细记录了如何使用MindStudio中的精度比对功能去进行推理场景下的模型的精度比对操作,包括原始第三方框架下模型的npy数据准备,离线模型的dump数据准备,精度比对以及分析。第三节介绍了MindStudio的昇腾App工程的创建。第四节介绍了推理场景下的数据准备。第五节介绍了精度比对和分析。第六节介绍了整个流程中遇到的问题和解决方案。第七节介绍MindStudio的更多的内容。
3、App工程创建
- 打开MindStudio进入算子工程创建界面
-
首次登录MindStudio:在MindStudio欢迎界面中单击“New Project”,进入创建工程界面。
-
非首次登录MindStudio:在顶部菜单栏中选择“File > New > Project…”,进入创建工程界面。
- 创建App工程
- 左侧导航栏选择“Ascend App”,如图所示,在右侧点击选择ACL Project(Python)工程。
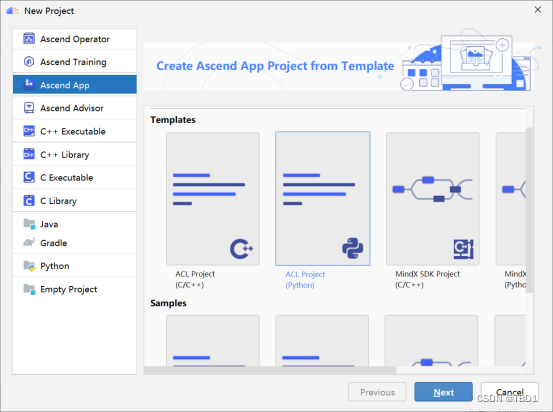
- 单击“Next”,在弹出的页面中,Project name那一行输入项目名称,然后点击Finish,既可完成工程的创建。
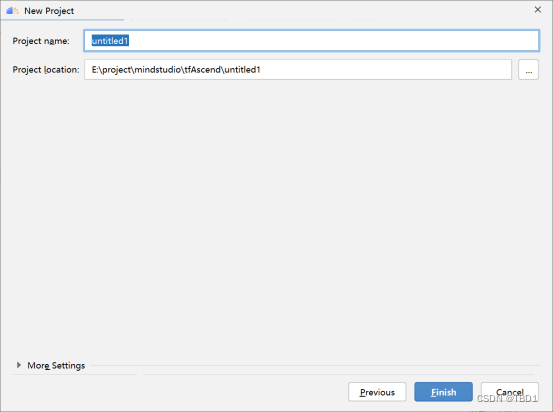
- 单击“Finish”,完成应用工程的创建
若工作窗口已打开其他工程,会出现如图所示提示。
-
选择“This Window”,则直接在当前工作窗口打开新创建的工程。
-
选择“New Window”,则新建一个工作窗口打开新创建的工程。

4、推理场景数据准备
(1)准备Caffe模型npy数据文件
MindStudio当前版本不提供Caffe模型numpy数据生成功能,请自行安装Caffe环境并提前准备Caffe原始数据“*.npy”文件。本文仅提供生成符合精度比对要求的numpy格式Caffe原始数据“*.npy”文件的样例参考。
下面给出Resnet50原始模型dump数据的推理脚本代码。请参考表1的参数说明进行使用。
表1 原始模型推理脚本参数说明
| -w | Caffe 权重文件路径,如’resnet50.caffemodel’ |
|---|---|
| -i, --input_bins | 模型推理输入bin文件或者图片文件路径,多个以;分隔,如’./a.bin;./img.png’ |
| -n, --input_names | 模型推理输入节点名称,多个以;分隔,如’graph_input_0:0; graph_input_1:0’ |
| -m | Caffe 模型文件路径,如’resnet50.prototxt’ |
| -o | dump输出文件路径,如’./output_dir’, 该路径需要用户自己创建 |
脚本代码:
# coding=utf-8
import caffe
import sys
import argparse
import os
import caffe.proto.caffe_pb2 as caffe_pb2
import google.protobuf.text_format
import json
import numpy as np
import time
TIME_LENGTH = 1000
FILE_PERMISSION_FLAG = 0o600
class CaffeProcess:
def __init__(self):
parse = argparse.ArgumentParser()
parse.add_argument("-w", dest="weight_file_path",
help="<Required> the caffe weight file path",
required=False,default="caffe_model/resnet50.caffemodel")
parse.add_argument("-m", dest="model_file_path",
help="<Required> the caffe model file path",
required=False,default="caffe_model/resnet50.prototxt")
parse.add_argument("-o", dest="output_path", help="<Required> the output path",
required=False,default="npy_dump")
parse.add_argument("-i", "--input_bins", dest="input_bins", help="input_bins bins. e.g. './a.bin;./c.bin'",
required=False,default="./data/img.png")
parse.add_argument("-n", "--input_names", dest="input_names",
help="input nodes name. e.g. 'graph_input_0:0;graph_input_0:1'",
required=False,default="data:0")
args, _ = parse.parse_known_args(sys.argv[1:])
self.weight_file_path = os.path.realpath(args.weight_file_path)
self.model_file_path = os.path.realpath(args.model_file_path)
self.input_bins = args.input_bins.split(";")
self.input_names = args.input_names.split(";")
self.output_path = os.path.realpath(args.output_path)
self.net_param = None
self.cur_layer_idx = -1
@staticmethod
def _check_file_valid(path, is_file):
if not os.path.exists(path):
print('Error: The path "' + path + '" does not exist.')
exit(-1)
if is_file:
if not os.path.isfile(path):
print('Error: The path "' + path + '" is not a file.')
exit(-1)
else:
if not os.path.isdir(path):
print('Error: The path "' + path + '" is not a directory.')
exit(-1)
def _check_arguments_valid(self):
self._check_file_valid(self.model_file_path, True)
self._check_file_valid(self.weight_file_path, True)
self._check_file_valid(self.output_path, False)
for input_file in self.input_bins:
self._check_file_valid(input_file, True)
@staticmethod
def calDataSize(shape):
dataSize = 1
for dim in shape:
dataSize *= dim
return dataSize
def _load_inputs(self, net):
inputs_map = {}
for layer_name, blob in net.blobs.items():
if layer_name in self.input_names:
input_bin = np.fromfile(
self.input_bins[self.input_names.index(layer_name)], np.float32)
input_bin_shape = blob.data.shape
if self.calDataSize(input_bin_shape) == self.calDataSize(input_bin.shape):
input_bin = input_bin.reshape(input_bin_shape)
else:
print("Error: input node data size %d not match with input bin data size %d.", self.calDataSize(
input_bin_shape), self.calDataSize(input_bin.shape))
exit(-1)
inputs_map[layer_name] = input_bin
return inputs_map
def process(self):
"""
Function Description:
process the caffe net, save result as dump data
"""
# check path valid
self._check_arguments_valid()
# load model and weight file
net = caffe.Net(self.model_file_path, self.weight_file_path,
caffe.TEST)
inputs_map = self._load_inputs(net)
for key, value in inputs_map.items():
net.blobs[key].data[...] = value
# process
net.forward()
# read prototxt file
net_param = caffe_pb2.NetParameter()
with open(self.model_file_path, 'rb') as model_file:
google.protobuf.text_format.Parse(model_file.read(), net_param)
for layer in net_param.layer:
name = layer.name.replace("/", "_").replace(".", "_")
index = 0
for top in layer.top:
data = net.blobs[top].data[...]
file_name = name + "." + str(index) + "." + str(
round(time.time() * 1000000)) + ".npy"
output_dump_path = os.path.join(self.output_path, file_name)
np.save(output_dump_path, data)
os.chmod(output_dump_path, FILE_PERMISSION_FLAG)
print('The dump data of "' + layer.name
+ '" has been saved to "' + output_dump_path + '".')
index += 1
if __name__ == "__main__":
caffe_process = CaffeProcess()
caffe_process.process()
说明:
- 运行之前需要提前准备数据文件和模型文件,原始模型下载地址为:https://gitee.com/ascend/ModelZoo-TensorFlow/tree/master/TensorFlow/contrib/cv/resnet50/ATC_resnet50_caffe_AE
-
远程安装好caffe的python3环境,在本地配置好安装的caffe的SDK。
-
将上述代码拷贝到新建的python脚本中,右键点击运行该脚本,即可以在参数-o指定的路径下生成npy数据文件。
-
生成的文件是以{op_name}.{output_index}.{timestamp}.npy形式命名。其中{op_name}为算子名称,{output_index}是算子的编号索引,{timestamp}是时间戳;设置numpy数据文件名包括output_index字段且值为0,确保转换生成的dump数据的output_index为0,否则无比对结果,原因是精度比对时默认从第一个output_index为0的数据开始。
(2)准备离线模型dump数据
通过MindStudio提供的dump功能,生成离线模型的dump数据,需要提前完成以下操作:
-
完成Caffe、TensorFlow或ONNX模型的ATC模型转换,将原始模型转换为OM离线模型。详细介绍请参见模型转换。
-
完成应用工程的开发、编译和运行,确保具备可执行的应用工程。详细介绍请参见应用开发。
操作步骤如下:
- 准备好离线模型,离线模型下载地址为:https://gitee.com/ascend/ModelZoo-TensorFlow/tree/master/TensorFlow/contrib/cv/resnet50/ATC_resnet50_caffe_AE;
或者参考如下模型转换步骤进行模型转换
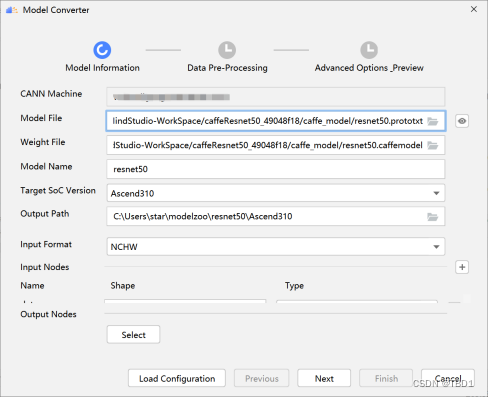
(1) 在菜单栏选择“Ascend > Model Converter”。出现如下配置界面,参数配置参考MindStudio官网>用户指南>模型转换>操作步骤。
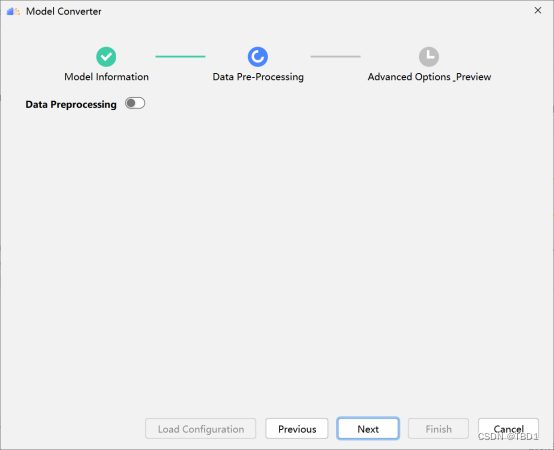
(2) 单击“Next”,进入“Data Pre-Processing”配置数据预处理页签,界面参考如图所示。
说明:数据预处理是昇腾AI处理器提供的硬件图像预处理模块,包括色域转换,图像归一化(减均值/乘系数)和抠图(指定抠图起始点,抠出神经网络需要大小的图片)等功能。只有当“Model Information”页签,“Input Nodes”参数中,输入节点的“Type”有配置为“Uint8”类型,“Data Pre-Processing”页签才可以配置该节点的数据预处理功能。如果模型有多个输入,每个输入节点都可以获取shape信息中的宽和高,并且“Input Nodes”参数中每个输入节点的“Type”都配置为“Uint8”,则“Data Pre-Processing”页签可以配置多个节点的数据预处理功能。
(3) 单击“Next”,进入“Advanced Options Preview”高级选项配置页签,界面参考如图所示。
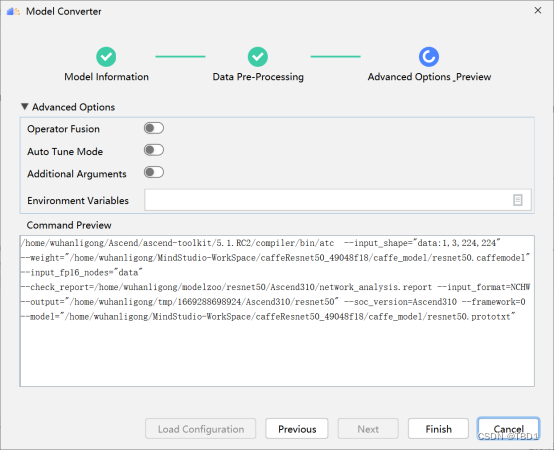
(4) 单击Finish完成模型转换。在MindStudio界面下方,“Output”窗口会显示模型转换过程中的日志信息,如果提示“Model converted successfully”,则表示模型转换成功。
-
准备好离线模型的推理代码。推理代码可以从https://gitee.com/ascend/samples/tree/master/python/level2_simple_inference/1_classification/resnet50_imagenet_classification#https://gitee.com/ascend/ModelZoo-TensorFlow/tree/master/TensorFlow/contrib/cv/resnet50/ATC_resnet50_caffe_AE中获取,或者直接拷贝下面代码。
-
构造dump的.json配置,选择“Ascend > Dump Configuration”菜单,弹出“Select Offline Model”窗口,如图所示。
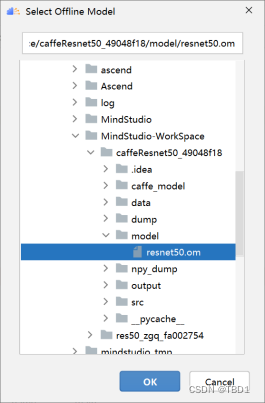
注意:如果不知道自己本地同步到远程哪个路径下,可以点击Tools>Development>Configuration下查看。
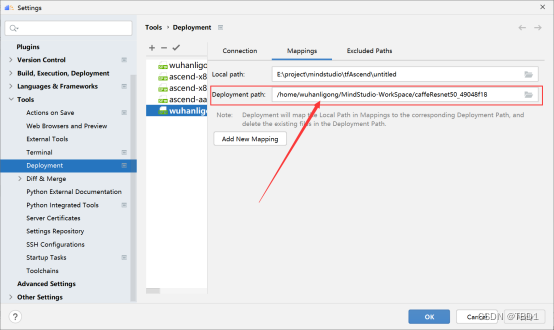
- 选择.om模型文件,单击“OK”,展示模型文件结构,设置dump开关。如图所示。
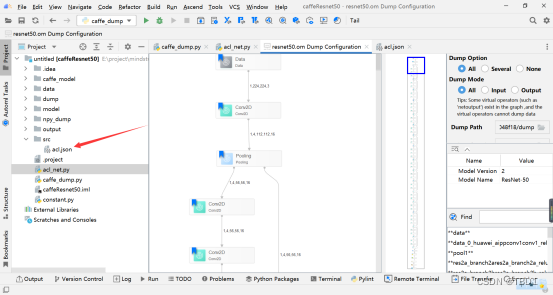
它会在src目录下生成acl.json配置文件,通过修改窗口最右侧配置项,设置.om模型文件的dump配置项,会自动更新到acl.json文件中。
(1) Dump Option:配置dump范围。
-
ALL:所有算子开启dump。
-
Several:自定义部分算子开启dump。选择该项后,需要右键单击待dump数据的算子并选择“Enable Dump”。
-
None:所有算子不开启dump。
(2) Dump Mode:dump数据模式。
-
ALL:同时dump算子的输入、输出数据。
-
Input:dump算子的输入数据。
-
Output:dump算子的输出数据。
(3) Dump Path:配置保存dump数据文件的路径,默认为:{project_path}/dump。如果Dump Path设置为其他路径,需要确保MindStudio安装用户对该路径具有读写权限。
注意:该选项要选择远程的dump目录,当前版本mindstudio只支持选择本地的dump目录,如果不能选择远程dump目录,请自行在acl.json中配置。
(4) AclConfig File:Acl配置文件,在dump操作中该文件保存算子的dump配置信息。一般路径为{project_path}/src/acl.json。
- 请参考表2中的参数说明使用该脚本
表2 离线模型推理脚本参数说明
| –device | npu设备编号。 |
|---|---|
| –model_path | 离线模型文件路径,到文件名层次。 |
| –images_path | 数据文件路径,到数据文件的文件夹层次。 |
import argparse
import numpy as np
import acl
import os
from PIL import Image
from constant import ACL_MEM_MALLOC_HUGE_FIRST, \
ACL_MEMCPY_HOST_TO_DEVICE, ACL_MEMCPY_DEVICE_TO_HOST, \
ACL_SUCCESS, IMG_EXT, NPY_FLOAT32
buffer_method = {
"in": acl.mdl.get_input_size_by_index,
"out": acl.mdl.get_output_size_by_index
}
def check_ret(message, ret):
if ret != ACL_SUCCESS:
raise Exception("{} failed ret={}"
.format(message, ret))
class Net(object):
def __init__(self, device_id, model_path):
self.device_id = device_id # int
self.model_path = model_path # string
self.model_id = None # pointer
self.context = None # pointer
self.input_data = []
self.output_data = []
self.model_desc = None # pointer when using
self.load_input_dataset = None
self.load_output_dataset = None
self.init_resource()
def release_resource(self):
print("Releasing resources stage:")
ret = acl.mdl.unload(self.model_id)
check_ret("acl.mdl.unload", ret)
if self.model_desc:
acl.mdl.destroy_desc(self.model_desc)
self.model_desc = None
while self.input_data:
item = self.input_data.pop()
ret = acl.rt.free(item["buffer"])
check_ret("acl.rt.free", ret)
while self.output_data:
item = self.output_data.pop()
ret = acl.rt.free(item["buffer"])
check_ret("acl.rt.free", ret)
if self.context:
ret = acl.rt.destroy_context(self.context)
check_ret("acl.rt.destroy_context", ret)
self.context = None
ret = acl.rt.reset_device(self.device_id)
check_ret("acl.rt.reset_device", ret)
ret = acl.finalize()
check_ret("acl.finalize", ret)
print('Resources released successfully.')
def init_resource(self):
print("init resource stage:")
current_dir=os.path.dirname(os.path.abspath(__file__))
ret = acl.init(os.path.join(current_dir,"./src/acl.json"))
check_ret("acl.init", ret)
# ret = acl.mdl.init_dump()
# check_ret("acl.init", ret)
# ret = acl.mdl.set_dump(os.path.join(current_dir,"./src/acl.json"))
# check_ret("acl.init", ret)
ret = acl.rt.set_device(self.device_id)
check_ret("acl.rt.set_device", ret)
self.context, ret = acl.rt.create_context(self.device_id)
check_ret("acl.rt.create_context", ret)
# load_model
self.model_id, ret = acl.mdl.load_from_file(self.model_path)
check_ret("acl.mdl.load_from_file", ret)
print("model_id:{}".format(self.model_id))
self.model_desc = acl.mdl.create_desc()
self._get_model_info()
print("init resource success")
def _get_model_info(self,):
ret = acl.mdl.get_desc(self.model_desc, self.model_id)
check_ret("acl.mdl.get_desc", ret)
input_size = acl.mdl.get_num_inputs(self.model_desc)
output_size = acl.mdl.get_num_outputs(self.model_desc)
self._gen_data_buffer(input_size, des="in")
self._gen_data_buffer(output_size, des="out")
def _gen_data_buffer(self, size, des):
func = buffer_method[des]
for i in range(size):
# check temp_buffer dtype
temp_buffer_size = func(self.model_desc, i)
temp_buffer, ret = acl.rt.malloc(temp_buffer_size,
ACL_MEM_MALLOC_HUGE_FIRST)
check_ret("acl.rt.malloc", ret)
if des == "in":
self.input_data.append({"buffer": temp_buffer,
"size": temp_buffer_size})
elif des == "out":
self.output_data.append({"buffer": temp_buffer,
"size": temp_buffer_size})
def _data_interaction(self, dataset, policy=ACL_MEMCPY_HOST_TO_DEVICE):
temp_data_buffer = self.input_data \
if policy == ACL_MEMCPY_HOST_TO_DEVICE \
else self.output_data
if len(dataset) == 0 and policy == ACL_MEMCPY_DEVICE_TO_HOST:
for item in self.output_data:
temp, ret = acl.rt.malloc_host(item["size"])
if ret != 0:
raise Exception("can't malloc_host ret={}".format(ret))
dataset.append({"size": item["size"], "buffer": temp})
for i, item in enumerate(temp_data_buffer):
if policy == ACL_MEMCPY_HOST_TO_DEVICE:
if "bytes_to_ptr" in dir(acl.util):
bytes_data = dataset[i].tobytes()
ptr = acl.util.bytes_to_ptr(bytes_data)
else:
ptr = acl.util.numpy_to_ptr(dataset[i])
ret = acl.rt.memcpy(item["buffer"],
item["size"],
ptr,
item["size"],
policy)
check_ret("acl.rt.memcpy", ret)
else:
ptr = dataset[i]["buffer"]
ret = acl.rt.memcpy(ptr,
item["size"],
item["buffer"],
item["size"],
policy)
check_ret("acl.rt.memcpy", ret)
def _gen_dataset(self, type_str="input"):
dataset = acl.mdl.create_dataset()
temp_dataset = None
if type_str == "in":
self.load_input_dataset = dataset
temp_dataset = self.input_data
else:
self.load_output_dataset = dataset
temp_dataset = self.output_data
for item in temp_dataset:
data = acl.create_data_buffer(item["buffer"], item["size"])
_, ret = acl.mdl.add_dataset_buffer(dataset, data)
if ret != ACL_SUCCESS:
ret = acl.destroy_data_buffer(data)
check_ret("acl.destroy_data_buffer", ret)
def _data_from_host_to_device(self, images):
print("data interaction from host to device")
# copy images to device
self._data_interaction(images, ACL_MEMCPY_HOST_TO_DEVICE)
# load input data into model
self._gen_dataset("in")
# load output data into model
self._gen_dataset("out")
print("data interaction from host to device success")
def _data_from_device_to_host(self):
print("data interaction from device to host")
res = []
# copy device to host
self._data_interaction(res, ACL_MEMCPY_DEVICE_TO_HOST)
print("data interaction from device to host success")
result = self.get_result(res)
self._print_result(result)
# free host memory
for item in res:
ptr = item['buffer']
ret = acl.rt.free_host(ptr)
check_ret('acl.rt.free_host', ret)
def run(self, images):
self._data_from_host_to_device(images)
self.forward()
self._data_from_device_to_host()
def forward(self):
print('execute stage:')
ret = acl.mdl.execute(self.model_id,
self.load_input_dataset,
self.load_output_dataset)
check_ret("acl.mdl.execute", ret)
self._destroy_databuffer()
print('execute stage success')
def _print_result(self, result):
vals = np.array(result).flatten()
top_k = vals.argsort()[-1:-6:-1]
print("======== top5 inference results: =============")
for j in top_k:
print("[%d]: %f" % (j, vals[j]))
def _destroy_databuffer(self):
for dataset in [self.load_input_dataset, self.load_output_dataset]:
if not dataset:
continue
number = acl.mdl.get_dataset_num_buffers(dataset)
for i in range(number):
data_buf = acl.mdl.get_dataset_buffer(dataset, i)
if data_buf:
ret = acl.destroy_data_buffer(data_buf)
check_ret("acl.destroy_data_buffer", ret)
ret = acl.mdl.destroy_dataset(dataset)
check_ret("acl.mdl.destroy_dataset", ret)
def get_result(self, output_data):
result = []
dims, ret = acl.mdl.get_cur_output_dims(self.model_desc, 0)
check_ret("acl.mdl.get_cur_output_dims", ret)
out_dim = dims['dims']
for temp in output_data:
ptr = temp["buffer"]
# 转化为float32类型的数据
if "ptr_to_bytes" in dir(acl.util):
bytes_data = acl.util.ptr_to_bytes(ptr, temp["size"])
data = np.frombuffer(bytes_data, dtype=np.float32).reshape(tuple(out_dim))
else:
data = acl.util.ptr_to_numpy(ptr, tuple(out_dim), NPY_FLOAT32)
result.append(data)
return result
def transfer_pic(input_path):
input_path = os.path.abspath(input_path)
with Image.open(input_path) as image_file:
image_file = image_file.resize((256, 256))
img = np.array(image_file)
height = img.shape[0]
width = img.shape[1]
# 对图片进行切分,取中间区域
h_off = (height - 224) // 2
w_off = (width - 224) // 2
crop_img = img[h_off:height - h_off, w_off:width - w_off, :]
# rgb to bgr,改变通道顺序
img = crop_img[:, :, ::-1]
shape = img.shape
img = img.astype("float16")
img[:, :, 0] -= 104
img[:, :, 1] -= 117
img[:, :, 2] -= 123
img = img.reshape([1] + list(shape))
img = img.transpose([0, 3, 1, 2])
result = np.frombuffer(img.tobytes(), np.float16)
return result
if __name__ == '__main__':
current_dir = os.path.dirname(os.path.abspath(__file__))
parser = argparse.ArgumentParser()
parser.add_argument('--device', type=int, default=0)
parser.add_argument('--model_path', type=str,
default=os.path.join(current_dir, "./model/resnet50.om"))
parser.add_argument('--images_path', type=str,
default=os.path.join(current_dir, "./data"))
args = parser.parse_args()
print("Using device id:{}\nmodel path:{}\nimages path:{}"
.format(args.device, args.model_path, args.images_path))
images_list = [os.path.join(args.images_path, img)
for img in os.listdir(args.images_path)
if os.path.splitext(img)[1] in IMG_EXT]
net = Net(args.device, args.model_path)
for image in images_list:
print("images:{}".format(image))
img = transfer_pic(image)
net.run([img])
# acl.mdl.finalize_dump()
# net.run([img])
print("*****run finish******")
net.release_resource()
说明:
(1) 数据文件应该是与原始模型生成npy数据文件保持一致。
(2) 如果是从gitee上下载的代码,需要修改acl.init()这行代码,在里面传入dump的配置参数.json文件。
6.设置dump完成后,单击MindStudio界面“Run”菜单,重新编译和运行应用工程。工程运行完毕后,可以在{project_path}/dump路径下查看到生成的dump数据文件。生成的路径及格式说明:time/device_id/model_name/model_id/data_index/dump文件
-
time:dump数据回传落盘时间。格式为:YYYYMMDDhhmmss。
-
device_id:Device设备ID号。
-
model_name:模型名称。
-
model_id:模型ID号。
-
data_index:针对每个Task ID执行的次数维护一个序号,从0开始计数,该Task每dump一次数据,序号递增1。
-
dump文件:命名规则如{op_type}.{op_name}.{taskid}.{timestamp}。
如果model_name、op_type、op_name出现了“.”、“/”、“\”、空格时,转换为下划线表示。
5、精度比对及分析
(1)全网精度比对操作步骤
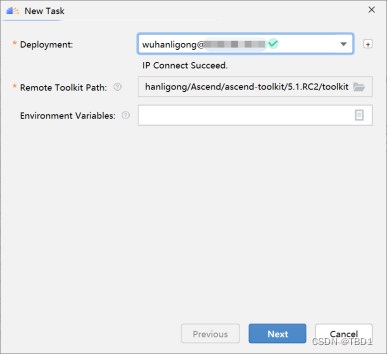
- 在MindStudio界面菜单栏选择“Ascend > Model Accuracy Analyzer > New Task”菜单,进入比对界面,如下图所示。
- 参考表3配置好参数后点击Next下一步。进入到数据和模型的配置界面。
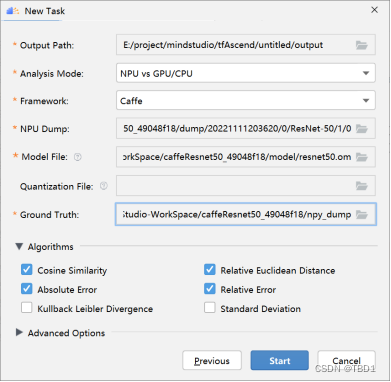
表3 精度比对New Task参数说明
| 参数 | 说明 |
|---|---|
| Run Mode | Remote Run:远程运行。Local Run:本地运行。Windows使用场景下仅支持Remote Run,该参数不展示。 |
| Deployment | 运行配置,选择Remote Run模式时可见,必选配置。通过Deployment功能,详细请参见Deployment,可以将指定项目中的文件、文件夹同步到远程指定机器的指定目录。 |
| Remote Toolkit Path | 远端运行环境toolkit软件包安装路径,选择Remote Run模式时可见,必选配置。例如配置为${HOME}/Ascend/ascend-toolkit/xxx/toolkit。与Deployment参数为绑定关系,单击“Start”后参数值将被保存。再次配置时,如连接已配置过的Deployment,则参数自动填充,可手动修改。 |
| Environment Variables | 环境变量配置,选择Remote Run模式时可见,可以直接在框中输入,也可以单击后在弹窗内单击填写。可选配置,当Model File指定文件为离线模型文件(.om)时,需要配置环境变量,否则工具将无法为离线模型文件(.om)进行ATC转换导致比对失败。与Deployment参数为绑定关系,单击“Start”后参数值将被保存。再次配置时,如连接已配置过的Deployment,则参数自动填充,可手动修改。 |
| Output Path | 比对数据结果存放路径,必选配置。无论选择Remote Run模式还是Local Run模式,均需要指定为本端路径。默认路径为当前系统的用户目录。 |
| Analysis Mode | 精度比对分析模式,必选配置。可选择模式为:NPU vs NPU:表示两个比对文件均为昇腾AI处理器上运行生成的dump数据文件。此时Model File参数可选。一般用于分析开启和关闭融合规则时进行模型转换后的dump数据文件之间的精度差。模型转换开启和关闭融合规则的详细介绍请参见模型转换。NPU vs GPU/CPU:表示昇腾AI处理器上运行生成的dump数据文件与原始模型的npy文件进行比对。此时展示Framework必选参数。 |
| Framework | 比对数据所属的框架类型,必选配置。Analysis Mode为NPU vs GPU/CPU时可见。可选类型为:- TensorFlow:TensorFlow框架模型dump数据的精度比对,支持推理、训练场景,Model File参数必选。- ONNX:ONNX框架模型dump数据的精度比对,支持推理场景,Model File参数必选。- Caffe:Caffe框架模型dump数据的精度比对,支持推理场景,Model File参数必选。 |
| NPU Dump | 昇腾AI处理器上运行生成的dump数据文件目录,必选配置。在远端执行比对时(Remote Run),须指定远端设备上的dump数据文件目录。 |
| Model File | 模型文件或融合规则文件。Analysis Mode为NPU vs NPU时,进行离线模型转换开启算子融合功能前后的dump数据精度比对,需要指定开融合的算子映射文件(.json)或离线模型文件(.om)和关融合的算子映射文件(.json)或离线模型文件(.om)。Analysis Mode为NPU vs GPU/CPU时,根据Framework选择的框架类型选择不同的文件:l TensorFlow:推理场景选择昇腾模型压缩后的量化融合规则文件(json文件)或离线模型文件(.om);训练场景选择计算图文件(.txt)。l ONNX:选择昇腾模型压缩后的量化融合规则文件(json文件)或离线模型文件(.om)。l Caffe:选择昇腾模型压缩后的量化融合规则文件(json文件)或离线模型文件(.om)。l 具体选择文件请参见比对场景。 |
| Quantization Rule File(.json) | 量化算子映射关系文件(昇腾模型压缩输出的json文件),可选配置。仅Framework为Caffe时展示。 |
| Ground Truth | 原始模型的npy文件目录,必选配置。在远端执行比对时(Remote Run),须指定远端设备上的原始模型的npy文件目录。 |
| Algorithm | 比对算法维度。取值为:l Cosine Similarity:余弦相似度算法,默认勾选。l Relative Euclidean Distance:欧氏相对距离算法,默认勾选。l Absolute Error,绝对误差,默认勾选,此项执行的比对算法为:l Max Absolute Error:最大绝对误差。l Mean Absolute Error:平均绝对误差。l Root Mean Square Error:均方根误差。l Relative Error,相对误差,默认勾选,此项执行的比对算法为:l Max Relative Error:最大相对误差。l Mean Relative Error:平均相对误差。l Accumulated Relative Error:累积相对误差。l Kullback Leibler Divergence:KL散度算法,默认不勾选。l Standard Deviation:标准差算法,默认不勾选。l 与Customized Algorithm自定义算法之间至少勾选一种算法。 |
| Advance Options | 扩展选项。包括Customized Algorithm、Advisor和Operator Range。 |
| Customized Algorithm | 自定义算法文件路径。与Algorithm内置算法之间至少勾选一种算法。需用户自行准备自定义算法.py文件,所在目录格式为“algorithm”,指定该目录下的自定义算法.py文件,生成自定义算法。自定义算法.py文件相关要求参见《精度比对工具使用指南》附录中的“准备自定义算法.py文件”章节。 |
| Advisor | 专家系统分析开关,默认关闭。开启后会在完成整网比对后对比对结果进行专家系统分析并输出问题节点、问题类型和优化建议。详细介绍请参见比对结果专家建议。使用本功能前需要先执行****pip3**** *install* ****pandas****命令安装pandas 1.3或更高版本依赖。与Operator Range无法同时开启。 |
| Operator Range | 设定算子比对范围。有两种设置方式:方式一:单击“Select”按钮,在弹出框内勾选需要比对的算子。方式二:根据Start、End、Step参数配置比对算子的范围。l start:第一个比对的算子,取值范围为[1, 参与计算的算子个数],默认值为1。l end:最后一个比对的算子,取值范围为-1或[start, 参与计算的算子个数],默认值为-1(动态获取网络模型中最后一个参与计算的算子)。l step:第start+stepn个比对的算子,step取值范围为[1, 参与计算的算子个数),默认值为1,n为从1开始的正整数。配置格式为:“start,end,step”。比如:-r 1,101,20,表示算子1,21,41,61,81,101的Tensor参与比对。不配置本参数时,比对网络模型中的所有参与计算的算子。配置本参数且Analysis Mode参数配置为NPU vs NPU时,需同时指定NPU Dump和Ground Truth的Model File分别指定开融合的算子映射文件(.json)或离线模型文件(.om)和关融合的算子映射文件(.json)或离线模型文件(*.om)。与Advisor无法同时开启。 |
(2)全网比对结果分析
上面步骤配置好参数后点击start即可以出现对比的结果界面。如下所示。
图一

图二
图三
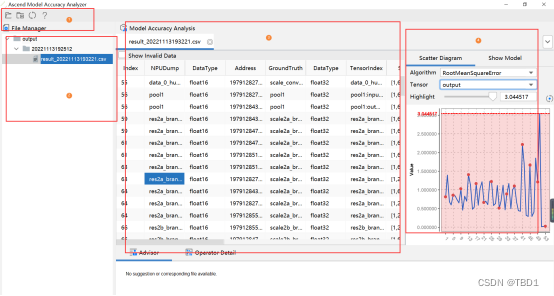
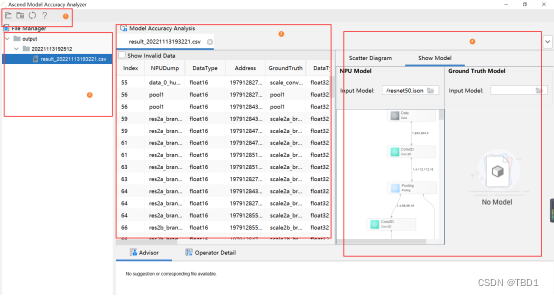
所示将Tensor比对结果界面分为四个区域分别进行介绍。其中1~4区域为整网比对结果。
表4 整网比对结果说明
| 区域 | 区域名称 | 说明 |
|---|---|---|
| 1 | 菜单栏 | 从左到右分别为Open…、New Task、Refresh、Help四项功能。Open…为打开并展示比对结果csv文件;New Task为创建新的比对任务;Refresh用于读取并刷新File Manager中管理的文件;单击Help弹出小窗,可展示精度比对工具的使用限制(Restrictions)、使用建议、在线教程链接等。 |
| 2 | File Manager,历史数据管理 | 显示用户指定文件夹以及文件夹下生成的整网比对的csv文件以及显示通过Open…单独打开的csv文件;对文件夹和csv,提供历史数据管理功能,包括打开、删除、另存为;在文件夹处右键删除;在空白处右键创建新比对任务(New Task)、刷新(Refresh)和Open…(打开并展示比对结果csv文件)。 |
| 3 | Model Accuracy Analysis,精度比对分析界面 | 默认仅显示有结果的算子。可单击列名,进行排序;单击Show Invalid Data,可展示无法比对的数据,各列字段含义请参见表2。 |
| 4 | Scatter Diagram,各项算法指标的散点分布图Show Model,比对模型可视化展示 | Scatter Diagram:横坐标表示算子的执行顺序,纵坐标为算法指标在对应Tensor上的实际取值。各字段含义请参见表3。Show Model:分别展示NPU和Ground Truth的模型图。详细介绍请参见表4。 |
表5 比对结果字段说明
| 字段 | 说明 |
|---|---|
| Index | 网络模型中算子的ID。 |
| OpSequence | 算子运行的序列。全网层信息文件中算子的ID。仅配置“Operator Range”时展示。 |
| OpType | 算子类型。 |
| NPUDump | 表示NPU Dump模型的算子名。光标悬浮时,可显示具体算子所在的文件路径。 |
| DataType | 表示NPU Dump侧数据算子的数据类型。 |
| Address | dump tensor的虚拟内存地址。用于判断算子的内存问题。仅基于昇腾AI处理器运行生成的dump数据文件在整网比对时可提取该数据。 |
| GroundTruth | 表示Ground Truth模型的算子名。光标悬浮时,可显示具体算子所在的文件路径。 |
| DataType | 表示Ground Truth侧数据算子的数据类型。 |
| TensorIndex | 表示NPU Dump模型算子的input ID和output ID。 |
| Shape | 比对的Tensor的Shape。 |
| OverFlow | 溢出算子。显示YES表示该算子存在溢出;显示NO表示算子无溢出;显示NaN表示不做溢出检测。开启Advisor功能时展示,为比对结果专家建议的FP16溢出检测专家建议提供数据。 |
| CosineSimilarity | 进行余弦相似度算法比对出来的结果。取值范围为[-1,1],比对的结果如果越接近1,表示两者的值越相近,越接近-1意味着两者的值越相反。 |
| MaxAbsoluteError | 进行最大绝对误差算法比对出来的结果。取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
| KullbackLeiblerDivergence | 进行KL散度算法比对出来的结果。取值范围为0到无穷大。KL散度越小,真实分布与近似分布之间的匹配越好。 |
| RootMeanSquareError | 表示均方根误差。取值范围为0到无穷大,MeanAbsoluteError趋于0,RootMeanSquareError趋于0,说明测量值与真实值越近似;MeanAbsoluteError趋于0,RootMeanSquareError越大,说明存在局部过大的异常值;MeanAbsoluteError越大,RootMeanSquareError等于或近似MeanAbsoluteError,说明整体偏差越集中;MeanAbsoluteError越大,RootMeanSquareError越大于MeanAbsoluteError,说明存在整体偏差,且整体偏差分布分散;不存在以上情况的例外情况,因为RMSE ≥ MAE恒成立。 |
| MaxRelativeError | 表示最大相对误差。取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
| RelativeEuclideanDistance | 进行欧氏相对距离算法比对出来的结果。取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
| StandardDeviation | 进行标准差算法比对出来的结果。取值范围为0到无穷大。标准差越小,离散度越小,表明越接近平均值。该列显示NPU Dump和Ground Truth两组数据的均值和标准差,第一组展示NPU Dump模型dump数据的数值(均值;标准差),第二组展示Ground Truth模型dump数据的数值(均值;标准差)。 |
| AccumulatedRelativeError | 进行累积相对误差算法比对出来的结果。取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
| MeanAbsoluteError | 表示平均绝对误差。取值范围为0到无穷大,MeanAbsoluteError趋于0,RootMeanSquareError趋于0,说明测量值与真实值越近似;MeanAbsoluteError趋于0,RootMeanSquareError越大,说明存在局部过大的异常值;MeanAbsoluteError越大,RootMeanSquareError等于或近似MeanAbsoluteError,说明整体偏差越集中;MeanAbsoluteError越大,RootMeanSquareError越大于MeanAbsoluteError,说明存在整体偏差,且整体偏差分布分散;不存在以上情况的例外情况,因为RMSE ≥ MAE恒成立。 |
| MeanRelativeError | 表示平均相对误差。取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
| CompareFailReason | 算子无法比对的原因。若余弦相似度为1,则查看该算子的输入或输出shape是否为空或全部为1,若为空或全部为1则算子的输入或输出为标量,提示:this tensor is scalar。 |
注1:余弦相似度和KL散度比较结果为NaN,其他算法有比较数据,则表明左侧或右侧数据为0;KL散度比较结果为inf,表明右侧数据有一个为0;比对结果为nan,表示dump数据有nan。
注2:光标悬浮在表头可以看到对应的参数详细解释。
注3:若配置了自定义算法比对,则在比对结果的内置算法后增加对应自定义算法列。
表6 散点分布图字段说明
| 字段 | 说明 |
|---|---|
| Algorithm | 选择展示对应比对算法结果的散点分布图,不支持展示StandardDeviation、KullbackLeiblerDivergence和AccumulatedRelativeError。 |
| Tensor | 过滤显示Input、Output结果散点分布图。 |
| Highlight | 对算子Tensor散点进行高亮。通过拖拉游标在对应算法指标的[min,max]间滑动来设置算法指标(纵坐标)的阈值,高于或等于阈值的点显示为蓝色,低于阈值的点显示为红色。如针对余弦相似度,图中设置阈值为0.98,小于0.98的算子Tensor被标记为红色。 |
注1:光标移动到对应Tensor点上时,浮窗显示Tensor信息。信息包括:Index(Tensor对应算子的Index)、Op Name(算子名称)、Tensor Index(Tensor类型(input/output))以及Value(在当前算法维度下的Tensor数值)。
注2:支持对散点图进行缩放。
注3:指定区域3中的Tensor时,高亮对应Tensor点。
表7 比对模型可视化展示字段说明
| 字段 | 说明 |
|---|---|
| NPU Model | 离线模型可视化。指定算子映射文件(.json)或离线模型文件(.om)展示。训练场景下,若整网比对使用的Model File为计算图文件(.txt),此处不支持展示模型图。 |
| Ground Truth Model | 原始模型可视化。指定原始模型文件展示。 |
| Input Model | 指定算子映射文件(.json)、离线模型文件(*.om)或原始模型文件。 |
| 注:指定区域3中的Tensor时,高亮对应模型网络中的节点。 |
在第一部分我们可以选择菜单,精度对比、历史等选项。我们可以从第二部分选择我们经过精度对比操作之后得到的不同的答案,并选择我们想要的内容来进行第三部分和第四部分的展示,在本次的实例当中我们只生成了一个模型的整网对比,所以只有一个对应的结果的文件,打开相应的文件夹,双击里面的csv文件,就可以呈现出我们本次模型的精度对比。
精度对比页面第三部分看出我们的原模型和转换模型之间每个算子之间的结果的差距,并且也可以得到输入和输出的shape。在后面几栏的算子的精度的对比,我们可以根据不同的评判方法得出原算子和转化的算子之间经过运算之后得出的结果的相似程度来判断算子转化的优劣,我们根据后面几项的精度对比,从数据上可以看出精度正在下降,也意味着误差正在增加。随后也可观察4部分的散点图来观察从最开始的输入到最后的输出,经过每一个算子的计算,两模型之间的精度差距,我们可以看到余弦相似度的值有下降的趋势,且最后的结果接近于零,所以说两模型之间的误差在慢慢的增大。并且在第四部分还可以根据Algorithm选项选择不同的精度比较方法,比如说图1和图3选择的是余弦相似度和均方根误差来来展示精度的对比。在Tensor选项当中,我们可以选择input或者output选项来展示输入或者输出之间的精度对比。我们还可以选择第四部分的show model选项,即可以展示网络模型结构中算子之间的关系,也可以配合精度比对结果来定位具体算子的精度问题。
(3)单算子精度比对操作步骤
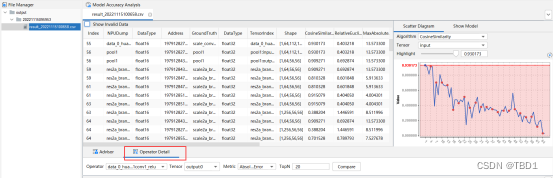
- 在刚刚的整网络分析界面下,点击下面的Operator Detail,出现如下界面。
- 对比操作。
(1)基于已经读取到的Tensor信息,通过Operator下拉框选择要比对的算子和对应Tensor(output/input)。
(2)通过Metric选择比对算子的Absolute Error(绝对误差)或Relative Error(相对误差)。
(3)配置输出该指标的TopN个Tensor元素(取值范围为[1,10000])。
(4)单击“Compare”按钮进行单算子比对。
TopN结果显示请参见比对结果。
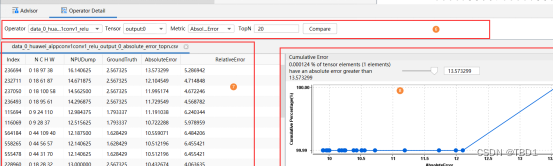
- 单算子比对界面说明。算子比对功能是在比对结果的基础上选择具体算子并根据需要指定参数进行比对的。界面展示为图5的6区域、7区域和8区域,如图5。详细介绍请参见表7
表7 单算子比对结果说明
| 区域 | 说明 |
|---|---|
| 5 | Operator Detail,单算子比对功能。下发单算子比对命令。具体操作请参见比对操作。 |
| 6 | 单算子比对TopN结果。各列字段解释请参见表8。 |
| 7 | Cumulative Error,对于TopN Tensor元素,绘制的误差累积分布折线图。详细介绍请参见表8。 |
- 比对结果。单算子比对结果界面展示为图5的7区域和8区域。详细介绍请参见表8。
表8 比对结果字段说明
| 字段 | 说明 |
|---|---|
| 6区域 | |
| Index | 算子比对的条数。 |
| N C H W | 数据格式。 |
| NPUDump | NPU Dump侧算子的dump值。 |
| GroundTruth | Ground Truth侧算子的dump值。 |
| Absolute Error | 绝对误差,NPU Dump侧算子的dump值减Ground Truth侧算子的dump值取绝对值比对出来的结果。小数点后最多6位。 |
| Relative Error | 相对误差,Absolute Error值除以Ground Truth侧算子的dump值比对出来的结果。当Ground Truth侧算子的dump值为0时,该处显示为“-”。小数点后最多6位。 |
| 7区域 | |
| A % of tensor elements (B elements) have an absolute error greater than C. | 当前算子比对的所有tensor元素的绝对误差结果中有A %的tensor也就是B个元素的绝对误差超过了C。其中absolute error根据5区域配置的Metric取值变化可以为relative error;右侧滑块控制C的取值,范围由6区域AbsoluteError或RelativeError的最大最小值决定。 |
| 误差累积分布折线图 | 横坐标为6区域的AbsoluteError或RelativeError,取值范围由AbsoluteError或RelativeError的最大最小值决定;纵坐标为累积百分占比,含义为AbsoluteError或RelativeError到达某个阈值时,小于等于该阈值的所有tensor元素在整体tensor元素中的占比。 |
| 注:光标移动到对应Tensor点上时,浮窗显示Tensor信息。信息包括:Index(算子比对的条数)、Absolute Error/Relative Error(绝对/相对误差)、Cumulative Percentage(累积百分占比) |
(4)对比结果专家建议
- FP16溢出检测
针对比对数据中数据类型为FP16的数据,进行溢出检测。如果存在溢出数据,输出专家建议。
专家系统分析结果:
- Detection Type: FP16 overflow
- Operator Index: 228
- Expert Advice: Float16 data overflow occurs. Rectify the fault and perform comparison again.
- 检测类型:FP16溢出检测
- Operator Index:228
专家建议:存在Float16数据溢出,请修正溢出问题,再进行比对。
- 输入不一致检测
针对整网的输入数据进行检测,主要判断整网两批待比对数据的输入data是否一致。如果存在不一致问题(余弦相似度<0.99),输出专家建议。
专家系统分析结果:
- Detection Type: Input inconsistent
- Operator Index: 0
- Expert Advice: The input data of NPUDump is inconsistent with that of GroundTruth. Use the same data or check the data preprocessing process.
- 检测类型:输入不一致检测
- Operator Index:0
专家建议:NPUDump和GroundTruth间的输入数据不一致,请使用相同数据或者检查数据预处理流程。
- 整网一致性检测(问题节点检测)
判断整网比对结果中,是否某层小于阈值,该层后续数据均小于阈值或最后一层小于阈值(余弦相似度<0.99),输出量化误差修正建议。
专家系统分析结果:
- Detection Type: global consistency
- Operator Index: 1174
- Expert Advice: The accuracy of some tensors is low, resulting in an unqualified final accuracy. This may be caused by quantization. Calibrate the data or contact Huawei for further diagnosis.
- 检测类型:整网一致性检测
- Operator Index:1174
- 专家建议:部分张量精度较低,且导致最终结果精度不达标;很可能由量化造成,请进行数据校准或者反馈给华为做进一步定位。
- 整网一致性检测(单点误差检测)
判断整网比对结果中,是否某层小于阈值(余弦相似度<0.99),但最终结果符合精度要求,输出专家建议。
专家系统分析结果:
- Detection Type: global consistency
- Operator Index: 195
- Expert Advice: The accuracy of some tensors is low, while the final accuracy is qualified. This may be caused by Ascend internal optimization. Ignore or contact Huawei for further diagnosis.
- 检测类型:整网一致性检测
- Operator Index:195
- 专家建议:部分张量精度较低,但最终结果精度达标,可能由内部优化导致,请忽略或反馈给华为做进一步定位。
- 整网一致性检测(一致性检测)
比对结果中的所有数据均符合精度要求,输出专家建议。
专家系统分析结果:
- Detection Type: global consistency
- Operator Index: NA
- Expert Advice: All data in the comparison result meets the accuracy requirements.
- If data accuracy of the model is still not up to standard in practical application, please check the post-processing process of model outputs.
- 检测类型:整网一致性检测
- Operator Index:NA
- 专家建议:比对结果中的所有数据均符合精度要求。如果模型实际应用中,精度依旧不达标,请排查输出数据的后处理流程。
6、经验总结
-
运行代码的时候,显示同步文件出现问题,如下。
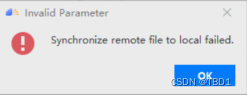
解决方法:远程python3运行环境中缺少google模块和protobuf==3.19.0模块,使用pip安装后再运行即可。 -
单算子分析的时候,点击下面栏框显示不出来单算子分析的窗口。
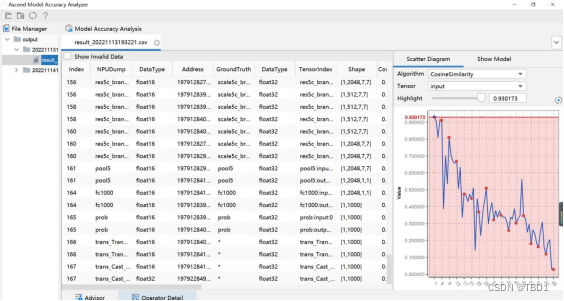
解决方法:确认没有报错信息的情况下,点击自己电脑的设置,调整显示屏分辨率或者缩放比例即可。 -
Windows端的MindStudio中使用离线模型dump数据时,路径配置只能选择本地的路径,没有可选的远程路径。
解决方法:找到自己项目目录下的src/acl.json文件,手动修改JSON文件导出路径配置为远程目录的路径。 -
配置好路径,但是运行的时候有时候会报错路径不存在。
解决方法:所有文件路径,请先确保本地存在相应路径,再同步到远程服务器中,有时候MindStudio不会自动生成路径,导致报错。
7、关于MindStudio更多的内容
如果需要了解关于MindStudio更多的信息,请查阅昇腾社区中MindStudio的用户手册https://www.hiascend.com/document/detail/zh/mindstudio/50RC3/progressiveknowledge/index.html,里面有算子开发、模型开发等各种使用操作的详细介绍。
如果在使用MindStudio过程中遇到任何问题,也可以在昇腾社区中的昇腾论坛https://www.huaweicloud.com/s/JU1pbmRTdHVkaW_mkK3lu7ol/t_60_p_1里进行提问,会有华为内部技术人员对其进行解答,如下图。

















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}