







本文主要介绍通过 MindStudio 全流程开发工具链,将 PaddlePaddle 模型转成 om 模型,并在昇腾环境上进行推理的流程,目录如下:
目录
一、MindStudio 环境搭建
通过 MindStudio 官网介绍可以学习了解 MindStudio 的功能,以及按照MindStudio 用户手册进行安装和使用。
官网链接:
用 户 手 册 : https://www.hiascend.com/document/detail/zh/mindstudio/50RC2/prog ressiveknowledge/index.html
1.1MindStudio 软件下载
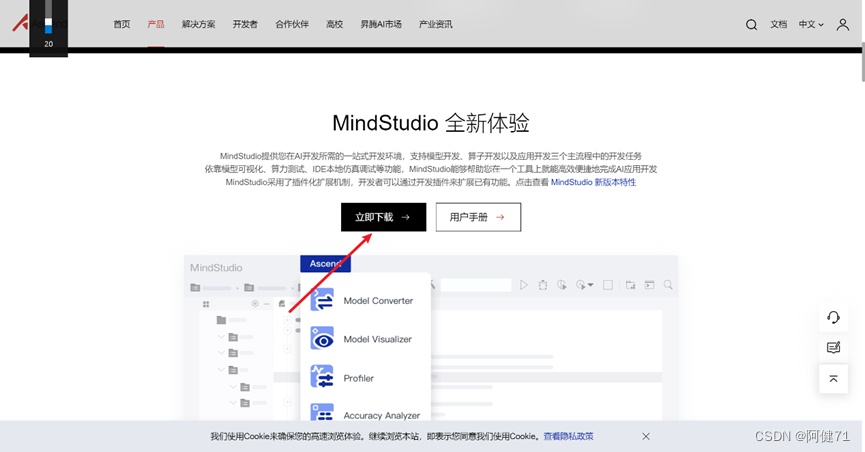
然后我们进入版本选择界面,可以根据自己的操作系统、安装方式选择不同的软件包,我们这里选择的是 MindStudio_5.0.RC2_win.exe,进行下载安装。
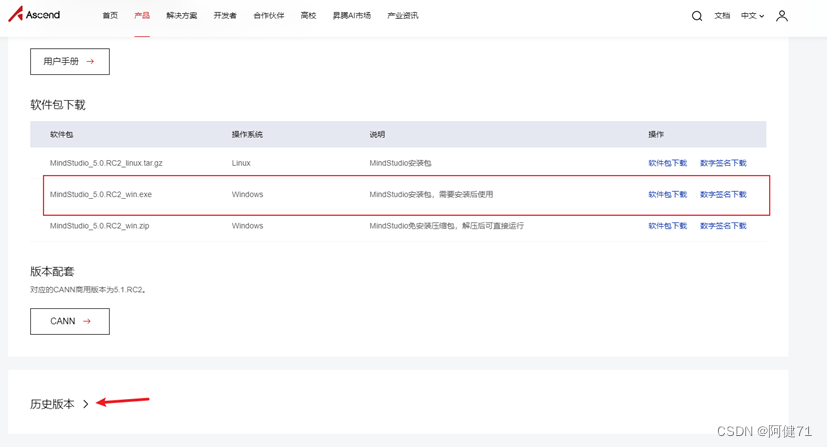
点击对应的“软件包下载”,弹出软件下载需知对话框,勾选“我已阅读并已同意 MindStudio 软件许可协议 的条款和条件”,然后点击“立即下载”进入下载流程

1.2 MindStudio 软件安装
双击打开下载好的 MindStudio_5.0.RC2_win.exe 软件包,进入安装流程:
欢迎界面,点击“Next”

选择安装路径,我们使用的是默认安装路径,然后点击“Next”。

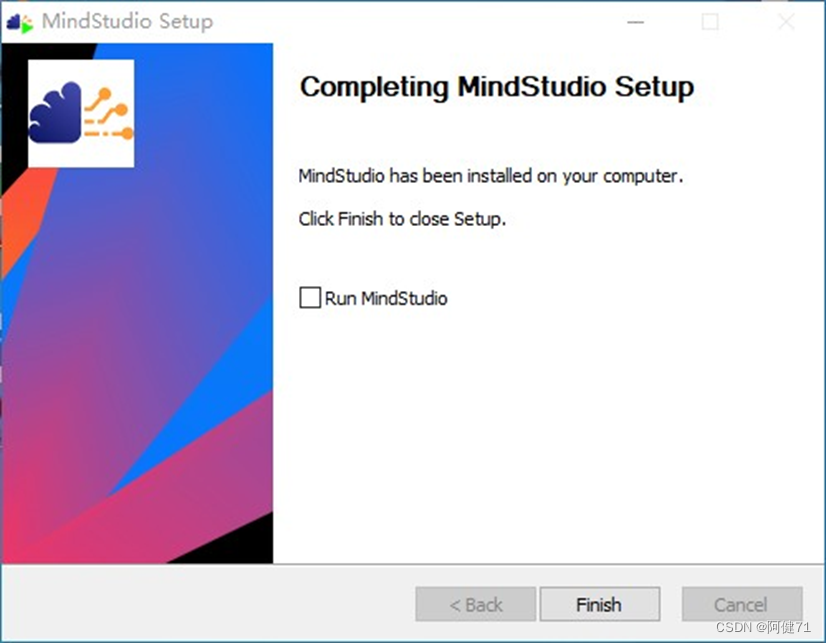
启动菜单文件夹我们使用默认配置,点击“Install”,程序进入自动安装步骤

安装完成后点击“Finsh”完成安装。
1.3 MindStudio 环境搭建
通过桌面快捷方式启动 MindStudio。
选择不导入配置,点击“OK”

Projects 标签用于工程打开、创建等。

Customize 标签用于 IDE 配置,包括界面、字体大小等。
 Plugins 标签用于管理插件的安装、删除等。
Plugins 标签用于管理插件的安装、删除等。

Learn MindStudio 标签可以通过点击“Help”进入官方社区获取帮助。在 Projects 标签下点击“New Project”创建一个新的工程。

选择 Ascend App,输入工程名、和工程目录,点击“Change”同步远端CANN

点击 Remote CANN Setting 对话框中的加号,弹出 SSH Configurations 对话框,然后点击其中的加号,填写红框中的服务器信息,点击“Test Connection” 弹出连接成功对话框。
依次点击“OK”完成 Remote Connection 配置 。

点击文件夹图标,在弹出的对话框中选择 CANN 安装路径,点击“OK”。

点击“Finish”。
开始同步远程 CANN 版本资源。

同步完成后点击“Next”。

选择 ACL Project(Python),点击“Finish”

此时成功创建了一个空的工程。

点击“Tools”->“Start SSH session”。

选择远程环境,启动远程终端窗口。

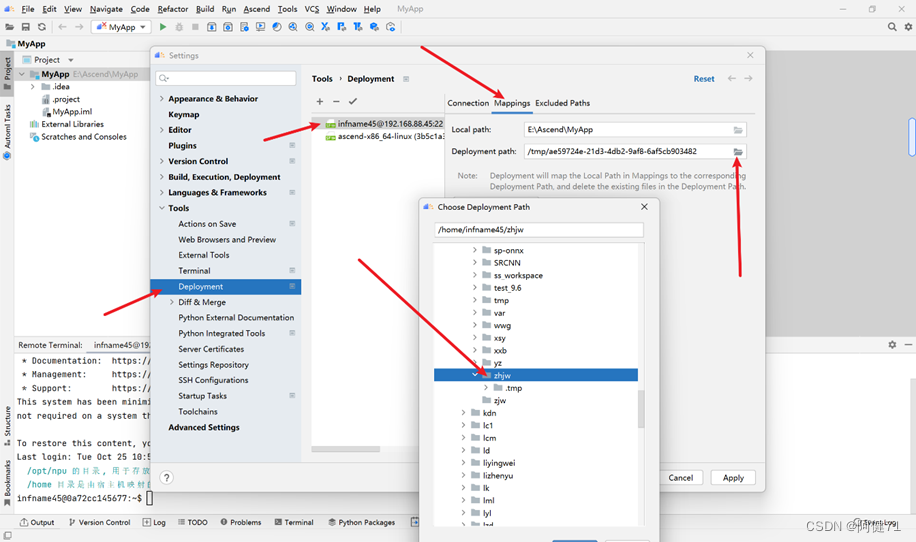
点击“Tools”->“Deployment”->“Configuration”。

按下图所示,配置远端映射路径。依次点击“OK”完成配置。
按照下图,配置项目 SDK。

点击“SDKs”,点击加号,点击“Add Python SDK...”,

点击“SSH Interpreter”, Deploy选择配置好的Deployment,Interpreter和Name会自动识别填充,如果需要自定义远端Python版本,可以手动点击Interpreter后面的(![]() )图标,打开远端目录树自行选择Python路径,点击“OK”。
)图标,打开远端目录树自行选择Python路径,点击“OK”。

点击“Project”,选择创建的 SDK,点击“OK”。

点击“Modules”->“Dependence”,选择创建的 SDK,点击“OK”。

点击“Tools”-> “Deployment”->“Automatic Upload”。

选择远程服务器,可自动上传修改并保存的文件。至此 MindStudio 开发环境搭建完成。
二、模型获取
2.1 模型介绍
本文开发的模型为基于 PaddlePaddle 的模型库 PaddleOCR 中的SVTR模型,(https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_en/algorithm_rec_svtr_en.md)的英文识别模型,SVTR是一种用于场景文本识别的单一视觉模型,该模型在补丁图像标记化框架内,完全摒弃了顺序建模。首先将图像文本分解为称为字符组件的小块。之后,分层阶段通过组件级混合、合并和组合反复执行。设计了全局和局部混合块来感知字符间和字符内模式,从而产生多粒度字符组件感知。
2.2 获取源码
在本地终端中通过 git 命令获取源码,参考命令如下。
git clone -b release/2.6 https://github.com/PaddlePaddle/PaddleOCR.git
cd PaddleOCR
git reset --hard 7f6c9a7b99ea66077950238186137ec54f2b8cfd
cd .. 
a、修改模型配置文件
配置不使用 gpu,如下图。


修改完成后将 PaddleOCR 同步到远程服务器,如下图。

2.3 安装依赖
a. 添加依赖文件“requirements.txt”
 b 在远程终端窗口通过 pip 命令安装依赖
b 在远程终端窗口通过 pip 命令安装依赖
执行命令如下:
pip3 install -r requirements.txt [--user],普通用户安装需添加--user 参数。
通过以上步骤,成功获取 SVTR 模型的源代码框架,以及配置运行依赖环境。
三、数据预处理
3.1 添加数据预处理脚本
在工程中添加数据预处理脚本,该脚本主要对图片进行归一化操作并转成二进制文件保存如下图所示。

预处理代码解读:
- 获取文件地址,并且配置环境变量

2. 读取yml配置文件中的相关参数,准备进行预处理。

3. 1.根据配置文件信息,读取数据集。
2.创建进度条,方便观察处理进度。
3.将预处理好的文件重命名保存到对应的输出位置。

3.2 设置可执行命令
a. 如下图所示,点击下拉按钮,选择“Edit Configurations…

b. 如下图所示,点击加号,选择“Ascend App”。
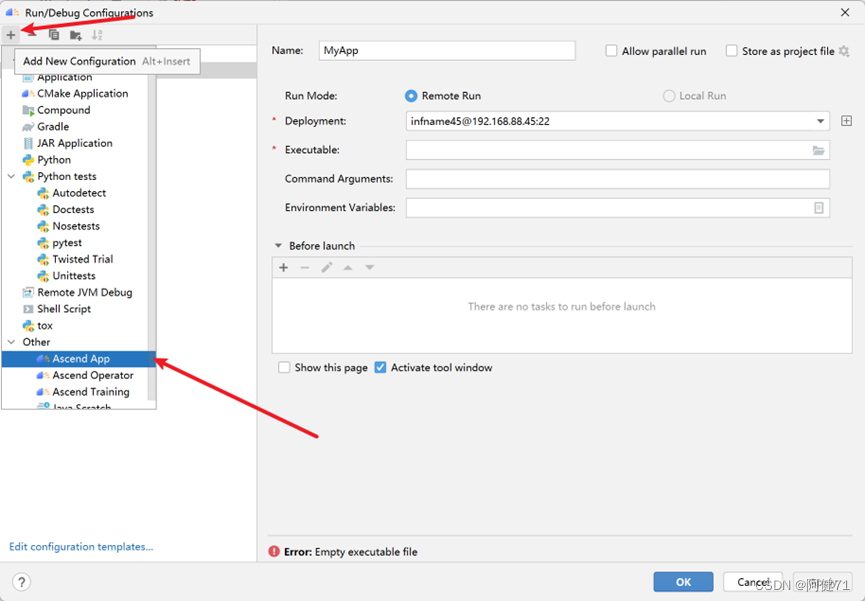
c. 如下图所示,输入命令名称,选择可执行脚本,点击“OK”。

d. 如下图所示,添加命令参数,点击“OK”。
--config=PaddleOCR/configs/rec/rec_r34_vd_none_none_ctc.yml --opt=bin_data=./SVTR_bindata config:模型配置文件。
opt:bin 文件保存路径

e. 点击执行按钮,进行数据预处理。

通过以上步骤,完成了数据预处理的工作,生成的预处理数据保存在 SVTR_bindata 目录下
四、模型转换
4.1 将训练模型转为推理模型
a. 获取推理权重文件,权重链接为:https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_train.tar下载之后,解压到本地 inference 目录下,并上传到远程服务器,如下图所示。

b.在指令栏中运行以下指令
python3 tools/export_model.py
-c configs/rec/rec_svtrnet.yml
-o Global.pretrained_model=./rec_svtr_tiny_none_ctc_en_train/best_accuracy Global.save_inference_dir=./inference/rec_svtr_tiny_stn_en
参数介绍:
-c:模型配置文件。
-o: 模型入参信息。
Global.pretrained_model:权重文件保存路径。
Global.save_inference_dir:paddleocr推理模型保存路径。

4.2 转onnx模型
a、在远程终端执行转 onnx 命令,并将生成的 onnx 模型拉取到本地,如下图所示,参考命令如下:
paddle2onnx
--model_dir=./inference/rec_svtr_tiny_stn_en/
--model_filename inference.pdmodel
--params_filename inference.pdiparams
--save_file ./inference/det_onnx/svtr.onnx
--opset_version=12
--enable_onnx_checker=True
参数介绍:
--model_dir:PaddlePaddle模型目录。
--model_filename:PaddlePaddle模型的网络文件名,位于--model_dir设置的目录下。
--params_filename:PaddlePaddle模型的参数文件名(参数文件组合成单个文件),位于--model_dir设置的目录下。
--save_file:保存onnx模型的文件路径。
--opset_version:设置要导出的onnx opset版本。
--enable_onnx_checker:是否检查onnx模型的有效性。


通过以上步骤,成功生成并获取onnx模型:svtr.onnx。
4.3 转 om 模型
下面使用MindStudio的模型转换功能将onnx模型转成om模型。
a.如下图所示,点击“Model Converter”按钮。
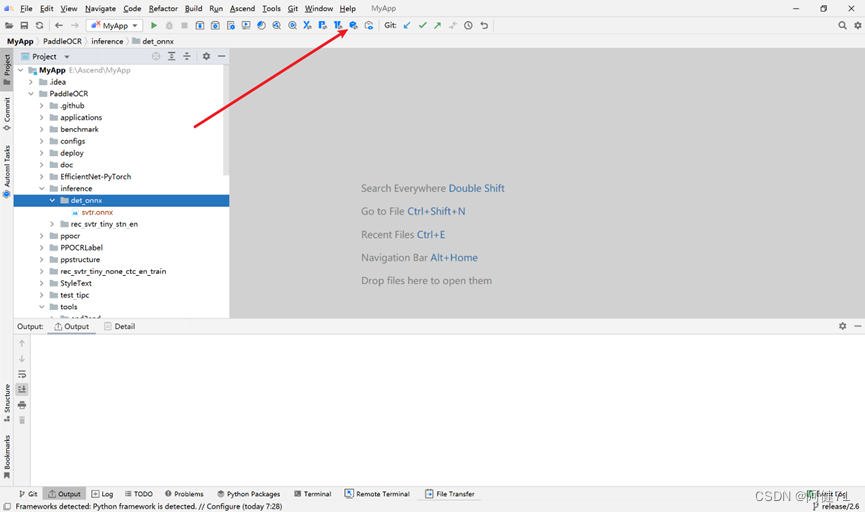
b.在弹出的 Model Converter 窗口中选择 Model File,点击“OK”。

c. 自动解析模型中,如下图。

d. 解析完成后,Model Name、Target SoC Version、Output Path、 Input Format、Shape、Type 信息,点击“Next”
参数解释:
Model Name : 模型名称。
Target SoC Version:处理器型号。
Output Path:om模型生成目录
Input Format:数据格式
Shape:输入数据的形状
Type:模型类型

e. 检查界面配置参数,没有问题则进入下一个配置界面。

f. 检查完成后点击“Next”。
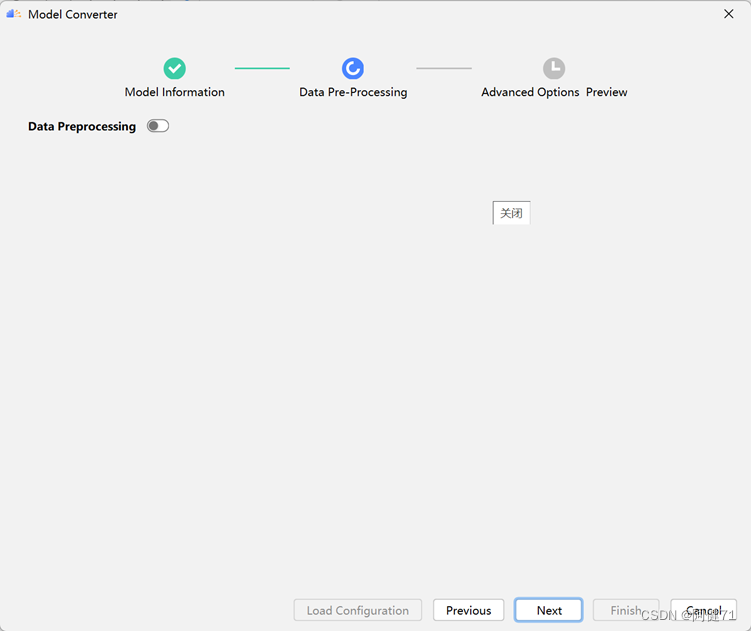
g. 检视生成的 atc 命令,确认无误后点击“Finish”

h. 模型转换成功后,如下图所示。

通过以上步骤,使用 MindStudio 的模型转换功能成功将 onnx 模型转成 om 模型:svtr.om。
五、模型推理
5.1 获取推理工具
我们使用 ais-infer 工具进行推理,ais-infer 工具获取及使用方式请查看
ais_infer 推理工具使用文档,链接:
https://gitee.com/ascend/tools/tree/master/ais-bench_workload/tool/ais_infer
a. 在本地终端命令中通过 git 获取推理工具代码,命令如下:
git clone https://gitee.com/ascend/tools.gitb.将 starnet\tools\ais-bench_workload\tool\ais_infer
目录下的 ais_infer.py 文件和 frontend 文件夹复制到工程根目录下, 并将修改的文件依次上传到远程服务器,如下图所示。

c.编译并安装 aclruntime 包,如下图所示,命令如下,
cd tools/ais-bench_workload/tool/ais_infer/backend/
pip3 wheel ./
pip3 install aclruntime-0.0.1-cp37-cp37m-linux_x86_64.whl
通过以上步骤,成功获取 ais_infer 工具,并安装了 aclruntime。
5.2 进行模型推理
a.创建 results 目录用来保存推理结果,并上传到远程服务器。

b 添加 ais_infer 的可执行命令,点击“OK”,如下图所示。
参数解释:
--model:om模型路径。
--input:bin文件路径。
--batchsize:om模型的batch。
--output:推理结果保存路径。

c.执行 ais_infer 命令,完成后在远程服务器上生成推理结果,推理结果如下图所示。


d.须将远程生成的结果 load 到本地,否则在执行其他命令进行同步的时候会删除

六、模型精度验证
6.1 数据后处理
a.添加数据后处理脚本。

后处理代码解读:
1. 获取文件地址,并且配置环境变量

2. 读取fml配置文件内容,准备进行后处理

3. 1. 通过配置内容,读取数据集信息
2.生成后处理还原算法
3. 创建进度条,方便观察处理进度
4. 生成后处理结果文件地址
5. 读取文件,变形后,并改为paddle.tensor类型
6. 获取batch_size
7. 还原文件
8. 进行对比
9. 输出对比的精度结果

b. 添加后处理命令。点击“OK”。
参数解释:
--config:模型配置文件。
--opt:推理结果路径。

c.执行后处理命令。

d.后处理执行完成后,打印的推理结果如下图,具体为

七、性能测试
由于精度验证使用的是源码提供的样例图片,需要使用 ais_infer 工具的纯 推理功能进行性能测试
a. 创建性能测试命令,如下图所示
参数解释:
--model:om模型路径。
--loop:推理次数。
--batchsize:om模型的batch

b. 执行性能测试命令,如下图所示。

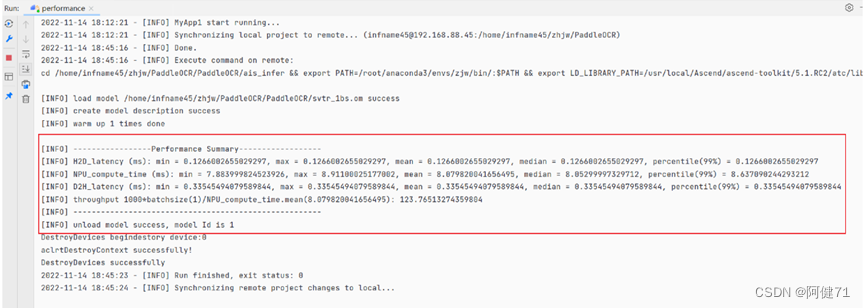
c. 性能测试结果如下图所示
八、总结
本文主要介绍使用 MindStudio 全流程开发工具链,将 PaddlePaddle 模型转成 om 模型,并在昇腾环境上进行推理的端到端流程。在使用 MindStudio 过程中也遇到过很多问题和不懂的地方,除了参考官方指导文档外,帮助更多的还是开发者社区,如下图所示,推荐大家多看些经验分享,写的很详细也很有帮助。
昇腾官网:https://www.hiascend.com/
昇腾社区:华为云社区_大数据社区_AI社区_云计算社区_开发者中心-华为云
昇腾论坛:华为云论坛_云计算论坛_开发者论坛_技术论坛-华为云
















 902
902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









