









张量
张量是现代机器学习的基础。它的核心是一个数据容器,多数情况下,它包含数字,有时候它也包含字符串,但这种情况比较少。因此把它想象成一个数字的容器,用来存放数据。
激活函数
主流的激活函数主要有下图4种,分别是relu、sigmoid、tanh、softplus,根据面对的问题不同往往需要选择不同的激活函数。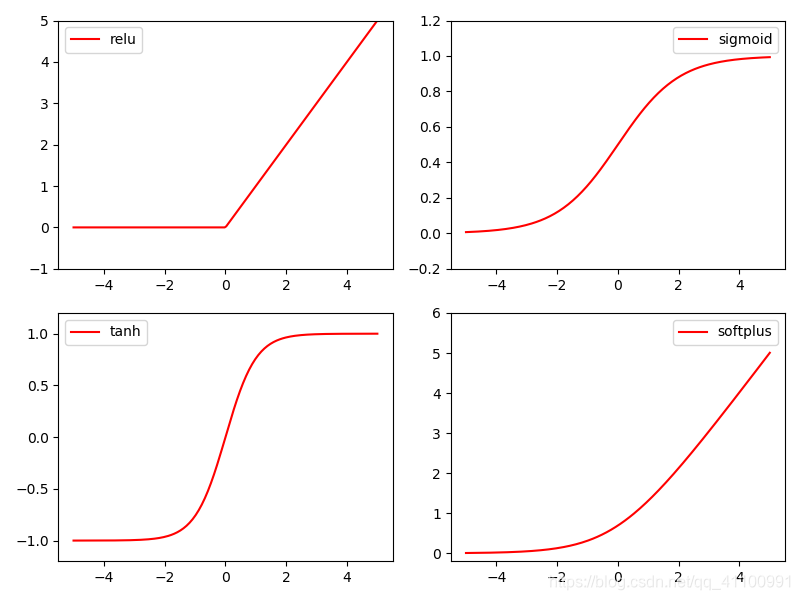
代码
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
x = torch.linspace(-5, 5, 200)
x_np = x.data.numpy()
y_relu = F.relu(x).data.numpy()
y_sigmoid = torch.sigmoid(x).numpy()
y_tanh = torch.tanh(x).numpy()
y_softplus = F.softplus(x).data.numpy()
plt.figure(1, figsize=(8, 6))
plt.subplot(221)
plt.plot(x_np, y_relu, c='red', label='relu')
plt.ylim((-1, 5))
plt.legend(loc='best')
plt.subplot(222)
plt.plot(x_np, y_sigmoid, c='red', label='sigmoid')
plt.ylim((-0.2, 1.2))
plt.legend(loc='best')
plt.subplot(223)
plt.plot(x_np, y_tanh, c='red', label='tanh')
plt.ylim((-1.2, 1.2))
plt.legend(loc='best')
plt.subplot(224)
plt.plot(x_np, y_softplus, c='red', label='softplus')
plt.ylim((-0.2, 6))
plt.legend(loc='best')
plt.show()
神经网络的搭建
这里说的是如何搭建神经网络
# 实现定义类
class [类名](torch.nn.Module):
def __init__(self):
# 下面这一步是固定的,缺少了会报错
super([类名], self).__init__()
# 这里只是用Linear函数做个列子,torch.nn中还有很多其他方法,self必须加,
# 不然torch会无法识别,生成的神经网络会忽略该层
self.[方法名] = torch.nn.Linear([输入神经元个数], [输出神经元个数])
# 激活函数的使用,可以通过包裹的方法
self.[方法名] = torch.relu(torch.nn.Linear([输入神经元个数], [输出神经元个数]))
# 也可以通过Sequential()函数,与上面等效,也可以通过Sequential()方法快速搭建,这样就不需要定义class了
self.[方法名] = torch.nn.Sequential(
torch.nn.ReLU(),
torch.nn.Linear([输入神经元个数], [输出神经元个数]),
)
# 调用
def forward(self, [输入]):
[输出] = self.[方法名]([输入]) # 调用上面定义的方法,并得到输出
return [输出]
回归问题
这里小编通过一个训练神经网络去拟合二元一次函数的例子,结果如下图

代码
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
# 生成数据
y = x.pow(2) + 0.2*torch.rand(x.size())
# 神经网络
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = torch.relu(self.hidden(x))
x = self.predict(x)
return x
# 实例化
net = Net(1, 10, 1)
print(net)
plt.ion()
plt.show()
# 优化器
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
# 定义计算误差的工具
loss_func = torch.nn.MSELoss()
for t in range(100):
prediction = net(x)
# 计算误差
loss = loss_func(prediction, y)
# 梯度归零,如果不进行梯度归零,误差值会不断累加
optimizer.zero_grad()
# 误差反向传递,优化神经网络
loss.backward()
# 更新网络的参数
optimizer.step()
if t % 5 == 0:
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.item(), fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
分类
这里小编是通过,随机生成的两类数据,然后让神经网络不断训练,最后结果如下图
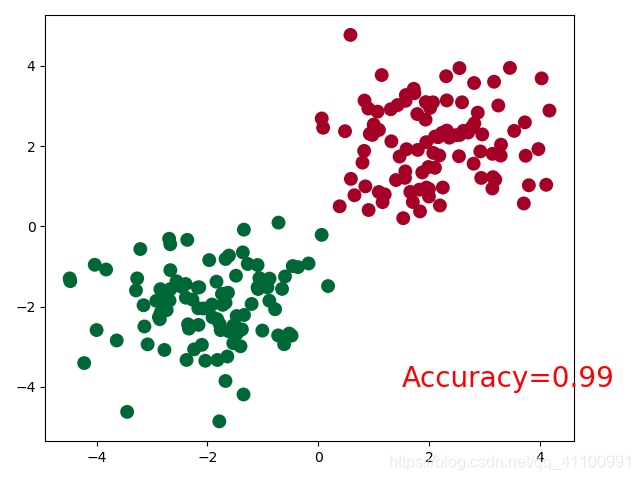
代码
import torch
import matplotlib.pyplot as plt
# 神经网络
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = torch.relu(self.hidden(x))
x = self.predict(x)
return x
# 数据准备
n_data = torch.ones(100, 2)
x0 = torch.normal(2*n_data, 1)
y0 = torch.zeros(100)
x1 = torch.normal(-2*n_data, 1)
y1 = torch.ones(100)
# 合并x数据集,并改变数据类型,不改变会报错,pytorch的输入数字类型必须是Float
x = torch.cat((x0, x1), 0).type(torch.FloatTensor)
# 合并y数据集
y = torch.cat((y0, y1), ).type(torch.LongTensor)
# 初始化
net = Net(2, 10, 2)
print(net)
plt.ion()
plt.show()
# 优化器
optimizer = torch.optim.SGD(net.parameters(), lr=0.02)
# 选择计算误差的方法
loss_func = torch.nn.CrossEntropyLoss()
for t in range(100):
out = net(x)
# 计算误差
loss = loss_func(out, y)
print(loss)
# 梯度归零
optimizer.zero_grad()
# 误差反向传递
loss.backward()
# 更新网络参数
optimizer.step()
# 上面4步一般是固定的
if t % 2 == 0:
plt.cla()
prediction = torch.max(out, 1)[1]
pred_y = prediction.data.numpy()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
accuracy = float((pred_y == target_y).astype(int).sum()) / float(target_y.size)
plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
网络的保存与读取
保存
# 保存整个神经网络
torch.save(net, 'net.pkl')
# 只保存神经网络中的参数
torch.save(net.state_dict(), 'net_params.pkl')
第二种方法较第一种方法主要是速度上的优势
提取
和上面保存的方法对应
torch.load('net.pkl')
net.load_state_dict(torch.load('net_params.pkl'))














 280
280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









