







Table of contents
Design a Relational Database
Designing a Relational Database and Creating an Entity Relationship Diagram
join
inner join
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;
或者
SELECT column_name(s)
FROM table1, table2
where table1.column_name = table2.column_name;
left join
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;
eg. 181
cross join
笛卡尔积
select *
from A cross join B
eg. 1280
group by having
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
ORDER BY column_name(s);
eg. 182
delete
DELETE xxx FROM table_name WHERE condition;
eg. 196
distinct
从“列”中取出不重复的元素
SELECT DISTINCT column1, column2, ...
FROM table_name;
eg. 176
Case
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;
Union
Union all 保留重复行
Union 不保留重复行
各种Rank
https://blog.csdn.net/shaiguchun9503/article/details/82349050
-
rank_number()
将select查询到的数据进行排序,每一条数据加一个序号
他不能用做于学生成绩的排名,一般多用于分页查询,比如查询前10个 查询10-100个学生。 -
rank()
简单来说rank函数就是对查询出来的记录进行排名。
与row_number函数不同的是,rank函数考虑到了over子句中排序字段值相同的情况,
如果使用rank函数来生成序号,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个。 -
dense_rank()
DENSE_RANK()密集的排名他和RANK()区别在于,排名的连续性,DENSE_RANK()排名是连续的,RANK()是跳跃的排名,所以一般情况下用的排名函数就是RANK()。
DENSE_RANK ( ) OVER ( [ <partition_by_clause> ] < order_by_clause > )
eg. 178, 1321
- ntile
NTILE()函数是将有序分区中的行分发到指定数目的组中,各个组有编号,编号从1开始,就像我们说的’分区’一样 ,分为几个区,一个区会有多少个。
分区 - PARTITION BY
分区内排名
https://www.cnblogs.com/hxfcodelife/p/10226934.html
rank() over(partition by xxx order by aaa desc)
ex: 1082
Limit, offset
https://www.sqltutorial.org/sql-limit/
Limit: 限制输出行数
offset: 跳过多少行
注意:
- MySQL里offset必须和limit连在一起用(limit可以单独使用),如果要达到同样的效果,MySQL最好用row_number()
- SQL server 可以单独使用offset
SELECT
employee_id, first_name, last_name
FROM
employees
ORDER BY first_name
LIMIT 5 OFFSET 3;
或者
SELECT
employee_id,
first_name,
last_name
FROM
employees
ORDER BY
first_name
LIMIT 3 , 5;

Update
eg. 627
UPDATE,
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
累计求和
两种方式
1、sum(weight) over(order by id asc)
也可以加上 between unbounded preceding and current row
2、利用不等式join,group by
eg. 534, 1204
Find the Start / End Number of Continuous Ranges
ROW_NUMBER()
eg. 1285
First_value()
SELECT DISTINCT
player_id,
FIRST_VALUE(device_id) OVER (
PARTITION BY player_id
ORDER BY event_date ASC
) AS device_id
FROM Activity
ORDER BY player_id;
eg. 512
null, ‘’, 0
这三个值是不同的。
对于0,直接用=检查即可。
对于“”,也可以直接用=检查。但是需要注意的是,0 = “” 是成立的。所以需要单独删除0的情况。
对于Null,直接使用 is null 或者 is not null
eg: 176
with temp as (
select distinct salary, dense_rank() over(order by salary desc) as r
from Employee
)
select IF(
(select temp.salary from temp where temp.r = 2) = '' and (select temp.salary from temp where temp.r = 2) != 0,
null,
(select temp.salary from temp where temp.r = 2)) as SecondHighestSalary
null, ifnull
isnull(value1,value2) (SQL server)
ifnull(value1,value2) (MySQL)
1、假如value1为null的话,返回value2,否则返回value1
2、value1与value2的数据类型必须一致。
如果希望有 “” 的时候,用null代替,则可以加一些表达式。比如max
ifnull 也会删除“”(empty)
https://stackoverflow.com/questions/17832906/how-to-check-if-field-is-null-or-empty-in-mysql
eg: 176
- NULL 不参与 > < = 的运算, 使用这些符号会输出null,需要注意使用前进行null的检查
- 用 >, <, =, != 进行筛选的时候,原数据中的 null 不会被保留 eg 577,584
- count:使用count的时候,如果用count(*),那么就是数行数,这时不管有没有null都不影响输出。如果是count(var),那么var中的null是不参与计数的。
blank & Null
有时候会select不会东西来,结果就是一个空.
但是我们不希望有空, 而希望是Null, 这个时候可以使用一些函数在结果上,比如max(), 然后结果就会变成Null
eg. 176
with temp as (
select distinct salary, dense_rank() over(order by salary desc) as r
from Employee
)
select max(salary) as SecondHighestSalary
from temp
where r = 2
Date
between
between表示的是闭区间,但是需要注意如果包涵具体时间的话,按照以下方式。
a between '2020-01-01' and '2020-01-10'
a >= 2020-01-01 00:00:00
a <= 2020-01-10 00:00:00
如果需要具体选择,有以下几种方式。
https://stackoverflow.com/questions/16347649/sql-between-not-inclusive/16347680
比如需要选取 created_at looks like 2013-05-01 22:25:19
- 使用cast,将原本的 datetime 全部改成 date
SELECT *
FROM Cases
WHERE cast(created_at as date) BETWEEN '2013-05-01' AND '2013-05-01'
- 直接用新一天的开区间选择
SELECT *
FROM Cases
WHERE created_at >= '2013-05-01' AND created_at < '2013-05-02'
- 注意:如果只有年月日,那么就是默认时间是“00:00:00”。比如“2019-12-01”,也就是“2019-12-01 00:00:00”
eg. 1294
选择year/month/date
- postgresql
https://www.postgresqltutorial.com/postgresql-extract/
EXTRACT(field FROM source)
source: DAY, QUARTER, MONTH …
- MySQL
SELECT YEAR("2017-06-15");
SELECT QUARTER("2017-06-15");
SELECT MONTH("2017-06-15");
SELECT DAY("2017-06-15");
选择“year-month”
DATE_FORMAT(trans_date, '%Y-%m')
LEFT(trans_date, 7)
eg. 1193
日期相减
- interval 1 day (不能直接减数字,或者两个日期直接相减和数字比较, 因为相差一年也会出现相减等于 1)
- TO_DAYS:
TO_DAYS(wt1.DATE) - TO_DAYS(wt2.DATE)=1 - DATEDIFF: MySQL:
DATEDIFF(a.Date, b.Date)=1,a.Date - b.Date = 1, - DATEDIFF: SQL Server:
DATEDIFF(day, a.Date, b.Date)=1, b.Date - a.Date = 1
DATE_DIFF
DATE_DIFF(time1, time2, day)
注意:将时间全部转成date,然后计算日期的间隔;和直接用timestamp算会有差异
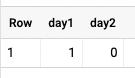
SELECT
DATE_DIFF(
DATE "2021-12-30",
EXTRACT(date
FROM
CAST("2021-12-29 23:59:59" AS TIMESTAMP)), day) AS day1,
DATE_DIFF(
CAST("2021-12-30" AS TIMESTAMP),
CAST("2021-12-29 00:00:01" AS TIMESTAMP), day) AS day2
Split, UNNEST
SELECT
split_tags,
tags
FROM
`bigquery-public-data.stackoverflow.posts_questions`,
UNNEST(SPLIT(tags, '|')) AS split_tags
WHERE
EXTRACT(year
FROM
creation_date) = 2020 )
Pivot
- MySQL没有pivot函数,需要用group by + case来构建每一列
- SQL Server可以用pivot函数
https://www.techonthenet.com/sql_server/pivot.php
eg. 1179
function 函数
eg. 2205
CREATE FUNCTION getUserIDs(startDate DATE, endDate DATE, minAmount INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
select count(distinct user_id) as user_cnt
from Purchases
where time_stamp >= startDate and time_stamp <= endDate and amount >= minAmount
);
END
eg 2230
CREATE PROCEDURE getUserIDs(startDate DATE, endDate DATE, minAmount INT)
BEGIN
# Write your MySQL query statement below.
select distinct user_id as user_id
from Purchases
where time_stamp between startDate and endDate and amount >= minAmount
order by user_id asc;
END














 123
123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









