






GLM具有自回归的空白填充通用语言模型预训练
一、背景知识扫盲:
Q1: 什么是单向注意力机制?与双向注意力机制有什么区别?
| A: |
Q2:什么是条件生成任务?
| A: 以Conditional GAN举例,核心思想就是添加条件约束。 下面是Conditional GAN解释:
|

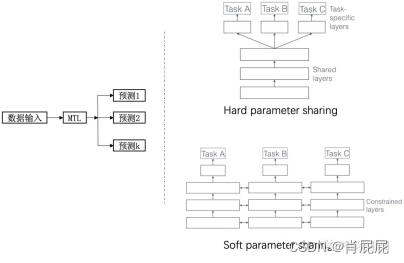
Q3:什么是多任务学习?
| A: 通常将多任务学习方法分为:hard parameter sharing和soft parameter sharing。区别在于对图中右边MTL那一个方块(一种迁移学习的思路)。
|
Q4:什么是自编码什么是自回归
| A: 自然语言处理NLP分为NLU(自然语言理解)和NLG(自然语言生成),其中自然语言理解一般使用自编码模式,即双向自注意力机制,自然语言生成使用自回归模式,即单向注意力机制。
|

二、摘要:
当前预训练架构包括:自编码模型(BERT),自回归模型(GPT),编码解码模型(T5),
自然语言理解:情感分类,抽取式回答,自然语言推理,如,自编码模型(BERT)。
无条件生成:语言建模,如,自回归模型(GPT)。
条件生成(seq2seq):摘要,生成式回答,机器翻译,如,编码解码模型(T5)。
Q研究的问题是什么?:
| A: 当前没有一种预训练框架对自然语言理解,无条件生成,条件生成三类任务表现最好。 |
Q现有的技术及存在的问题是什么:
| A: 自回归模型,如GPT,学习从左到右的语言模型,虽然能够成功的生成文本,并在扩展到十亿参数时显示微弱的学习能力,但缺点是单向注意力机制,不能完全捕捉自然语言理解任务中的上下词之间的依赖关系。 T5通过编码器-解码器模型统一了自然语言理解和条件生成任务,但是需要更多的参数来达到自编码模型相同的性能。 掩码语言模型不能完全捕捉被掩盖的字符之间的关系,因此不适合文本生成任务。 |
Q需要解决的技术问题是什么?
| A: 当前的这些预训练框架都没有足够的灵活,不能够在所有的nlp任务中表现良好,之前的研究都试图通过多任务学习结合不同的目标来统一不同的框架,然而,由于自编码和自回归目标在本质上有所不同,一个简单的统一不能完全继承这两个框架的优点。 |
三、文章核心:
提出了一种基于自回归空白填充的预训练框架GLM(通用语言模型)。按照自动编码的思想,从输入文本中随机使用[Mask]标记连续文本字段,并按照自回归预训练的思想,训练模型按顺序重建被掩码掉的文本字段。虽然在T5中用于文本到文本的预训练,但我们提出了两个改进,即跨度变换和二维位置编码。根据经验,我们表明,在相同的参数和计算成本下,GLM在SuperGLUE基准上显著优于BERT,为4.6%-5.0%,并且在类似大小(158GB)上预训练时,优于RoBERTa和BART。GLM在参数和数据较少的NLU和生成任务上也显著优于T5。
QGLM的框架?
| A:提出了一种基于新的自回归空白填充目标的通用预训练框架GLM。 |
Q什么是自回归空白填充?
| A:通过优化自回归空白填充目标进行训练。 |
3.1理论逻辑
给一个文本X=![]() ,在文本中以随机间隔的方式进行字段取样
,在文本中以随机间隔的方式进行字段取样![]() ,其中,每个Si(文本中的设置的跨度中对应的字段)对应于一系列连续的标记
,其中,每个Si(文本中的设置的跨度中对应的字段)对应于一系列连续的标记![]() ,在X中,每个跨度都被替换为一个[MASK]标记,形成一个损坏的文本。该模型以自回归的方式从损坏的文本中预测字段中缺失的标记,这意味着在预测一个字段中缺失的标记时,模型可以访问损坏的文本和先前预测的跨度。为了充分捕获不同字段之间的相互依赖关系,我们随机排列了字段的排列顺序,类似于排列语言模型。
,在X中,每个跨度都被替换为一个[MASK]标记,形成一个损坏的文本。该模型以自回归的方式从损坏的文本中预测字段中缺失的标记,这意味着在预测一个字段中缺失的标记时,模型可以访问损坏的文本和先前预测的跨度。为了充分捕获不同字段之间的相互依赖关系,我们随机排列了字段的排列顺序,类似于排列语言模型。
形式上,设Zm为长度m索引序列[1,2,···,m],和sz<i为[sz1,····,szi−1]的所有可能排列的集合,
训练前目标为:
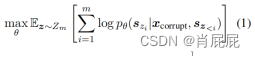
我们总是按照从左到右的顺序生成每个空白中的标记,即生成si的概率被分解为:
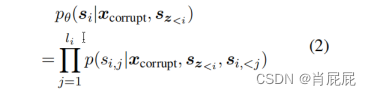
3.2技术实现:
输入x分为两部分:A部分是损坏的文本xcorrupt,B部分由掩码所掩盖的文本组成。A部分标记可以相互关注,但不能关注B中的任何标记。B部分令牌可以关注B中的A部分和前词,但不能关注B中的任何后续令牌(字段)。为了实现自回归生成,每个跨度都用特殊的标记、开始S和结束E来填充,分别输入和输出。
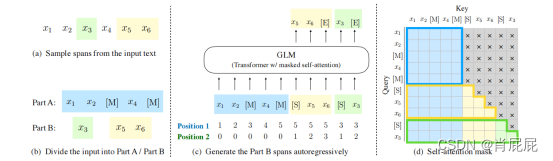
GLM预训练。(a)原始文本为[x1、x2、x3、x4、x5、x6]。对两个跨度[x3]和[x5、x6]进行采样。(b)将A部分中的采样跨度替换为[M],并打乱部分中的跨度 B. (c)GLM自动回归生成零件 B. 每个跨度以[S]作为输入,附加[E]作为输出。2D位置编码表示跨度间和跨度内位置。(d)自注意掩码。灰色区域被掩盖了。A部分标记可以关注自己(蓝色框架),但不是B。B部分标记可以关注A和B中的前因(黄色和绿色框架对应两个跨度)。[M] := [MASK],[S] := [START],以及[E] := [END]。
通过这种方式,我们的模型在一个统一的模型中自动学习一个双向编码器(A部分)和一个单向解码器(B部分)。
总结整个流程,举个栗子:




四、预训练目标:
4.1针对三类下游任务,设计预训练目标。
4.1.1针对自然语言理解任务
我们用λ = 3从泊松分布中随机抽取长度跨度。我们反复采样新的跨度,直到至少15%的原始令牌被掩盖。根据经验,我们发现15%的比率对于下游NLU任务的良好性能至关重要。(token-level objective)

4.1.2针对文本生成任务设计另外两种预训练目标:
Document-level object:我们采样了一个长度从原始文本长度的50%到100%的均匀分布中采样片段,这个预训练目标针对的是无条件的长文本生成。
Sentence-levelobjective:我们限制了每个被掩盖的片段必须是完整的句子,采样多个句子直到覆盖了原始文本中的15%的字符。这个预训练目标针对的是输出目标,常常是句子或者段落的有条件文本生成。
4.2自回归空白填充任务的挑战之一是如何对位置信息进行编码。
自回归空白填充任务的挑战之一是如何对位置信息进行编码。Transformer依赖于位置编码来注入令牌(位置编码)的绝对位置和相对位置。我们提出了二维位置编码来解决这一挑战。具体来说,每个标记都用两个位置id进行编码。第一个位置id表示已损坏的文本中的位置。对于掩码跨度,它是相应的[MASK]令牌的位置。第二个位置id表示跨内位置。对于A部分中的标记,它们的第二个位置id是0。对于B部分中的标记,它们的范围从1到跨度的长度。这两个位置id通过可学习的嵌入表被投影到两个向量中,它们都被添加到输入的词向量中。
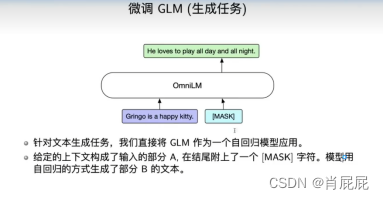
4.3 GLM与T5进行对比:

















 3422
3422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









