






GLM: General Language Model Pretraining with Autoregressive Blank Infilling
摘要
已经有各种类型的预训练架构,包括自编码模型(例如BERT),自回归模型(例如GPT)和编码器-解码器模型(例如T5)。然而,没有一个预训练框架对三个主要类别的所有任务(自然语言理解(NLU),无条件生成和有条件生成)都表现最佳。我们提出了一种基于自回归空白填充的通用语言模型(GLM)来应对这一挑战。GLM通过添加2D位置编码并允许任意顺序预测跨度来改进空白填充预训练,从而在NLU任务上比BERT和T5获得了性能提升。同时,通过变化空白数量和长度,可以针对不同类型的任务对GLM进行预训练。在跨NLU、有条件和无条件生成的广泛任务范围内,GLM在相同的模型大小和数据情况下优于BERT、T5和GPT,并且使用BERTLarge的1.25×参数的单个预训练模型实现了最佳性能,展示了其对不同下游任务的通用性。
1.介绍
在未标记的文本上预训练的语言模型,已经显著提高了各种NLP任务的最新技术水平,从自然语言理解(NLU)到文本生成(Radford等人,2018a; Devlin等人,2019; Yang等人,2019; Radford等人,2018b; Raffel等人,2020; Lewis等人,2019; Brown等人,2020)。在过去几年中,下游任务的性能以及参数规模也不断增加。
一般来说,现有的预训练框架可以分为三类:自回归模型、自编码模型和编码器-解码器模型。自回归模型,如GPT(Radford等人,2018a),学习从左到右的语言模型。虽然当它们扩展到数十亿个参数时,它们在长文本生成和fewshot学习能力方面表现出色(Radford等人,2018b;Brown等人,2020),但它们的固有劣势是单向注意机制,不能完全捕捉NLU任务中上下文单词之间的依赖关系。自编码模型,如BERT(Devlin等人,2019),通过去噪目标(例如掩码语言模型(MLM))学习双向上下文编码器。编码器生成适合自然语言理解任务的上下文化表示,但不能直接用于文本生成。编码器-解码器模型采用编码器的双向注意力,解码器的单向注意力,以及它们之间的交叉注意力(Song等人,2019;Bi等人,2020;Lewis等人,2019)。它们通常用于有条件的生成任务,例如文本摘要和响应生成。2. T5(Raffel等人,2020)通过编码器-解码器模型统一了NLU和条件生成,但需要更多的参数才能匹配基于BERT的模型(如RoBERTa(Liu等人,2019)和DeBERTa(He等人,2021))的性能。
这些预训练框架都不足够灵活,无法在所有NLP任务中具有竞争力。以前的工作尝试通过多任务学习(Dong等人,2019;Bao等人,2020)将不同框架的目标结合起来,但是由于自编码和自回归目标的本质差异,简单的统一不能完全继承两种框架的优点。
在本文中,我们提出了一个基于自回归空白填充的预训练框架,称为GLM(通用语言模型)。我们从输入文本中随机空白连续标记,遵循自编码的思想,并训练模型按顺序重构跨度,遵循自回归预训练的思想(见图1)。虽然在T5(Raffel等人,2020)中已经使用了填空,但我们提出了两个改进,即跨度混洗和2D位置编码。经验证明,GLM在相同的参数量和计算成本下,在SuperGLUE基准测试中比BERT表现显著提高4.6% - 5.0%,在类似大小的语料库(158GB)上进行预训练时,GLM也比RoBERTa和BART表现更好。GLM在参数和数据较少的情况下,也在NLU和生成任务中显著优于T5。
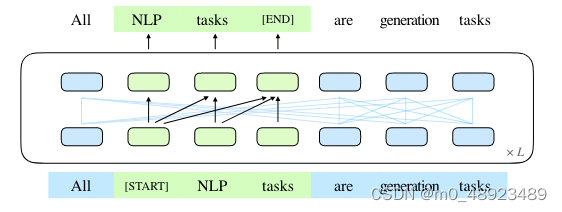
图1:GLM的示意图。我们将文本跨度(绿色部分)空白并自回归地生成它们。(一些注意力边缘被省略了;请参见图2。)
受Pattern-Exploiting Training(PET)(Schick和Schütze,2020a)的启发,我们将NLU任务重新构造为手动制作的填空问题,以模拟人类语言。与PET使用的基于BERT的模型不同,GLM可以通过自回归空白填充自然地处理填空问题的多标记答案。
此外,我们展示了通过变化缺失跨度的数量和长度,自回归空白填充目标可以对语言模型进行有条件和无条件的生成预训练。通过不同预训练目标的多任务学习,单个GLM可以在NLU和(有条件和无条件的)文本生成中表现出色。从实验结果来看,与独立基线相比,通过参数共享,多任务预训练的GLM在NLU、有条件文本生成和语言建模任务中均实现了改进。
2 GLM预训练框架
我们提出了一个基于新型自回归空白填充目标的通用预训练框架GLM。GLM将NLU任务表述为包含任务描述的填空问题,可以通过自回归生成来回答这些问题。
2.1 预训练目标
2.1.1 自回归空白填充
GLM通过优化自回归空白填充目标进行训练。给定一个输入文本 x = [ x 1 , ⋯ , x n ] x=[x_1,\cdots,x_n] x=[x1,⋯,xn],采样多个文本跨度 { s 1 , ⋯ , s m } \{s_1,\cdots,s_m\} {s1,⋯,sm},其中每个跨度 s i s_i si对应于 x x x中一系列连续的标记 [ s i , 1 , ⋯ , s i , l i ] [s_i,1,\cdots,s_i,l_i] [si,1,⋯,si,li]。每个跨度都用单个[MASK]标记替换,形成一个损坏的文本 x c o r r u p t x_{corrupt} xcorrupt。模型通过自回归方式从损坏的文本中预测跨度中缺失的标记,这意味着当预测跨度中缺失的标记时,模型可以访问损坏的文本和之前预测的跨度。为了完全捕捉不同跨度之间的相互依赖关系,我们随机排列跨度的顺序,类似于置换语言模型(Yang等,2019)。形式上,令 Z m Z_m Zm为长度为m的索引序列 [ 1 , 2 , ⋯ , m ] [1,2,\cdots,m] [1,2,⋯,m]的所有可能排列的集合, s z < i s_{z<i} sz<i为 [ s z 1 , ⋯ , s z i − 1 ] [s_{z_1},\cdots,s_{z_{i-1}}] [sz1,⋯,szi−1],我们将预训练目标定义目标函数的数学表达式为:
m a x θ E z ∼ Z m [ ∑ i = 1 m log p θ ( s z i ∣ x c o r r u p t , s z < i ) ] \underset{\theta}{max} \mathbb{E}_{z \sim Z_m}\left[\sum_{i=1}^m \log p_{\theta}(s_{z_i} | x_{corrupt}, s_{z<i})\right] θmaxEz∼Zm[∑i=1mlogpθ(szi∣xcorrupt,sz<i)]
我们总是按照从左到右的顺序生成每个空白中的标记,即生成跨度 s i s_i si的概率可以分解为:
p θ ( s i ∣ x c o r r u p t , s z < i ) = ∏ j = 1 l i p θ ( s i , j ∣ x c o r r u p t , s z < i , s i , < j ) p_{\theta}(s_i|x_{corrupt}, s_{z<i} ) = \prod_{j=1}^{l_i} p_{\theta}(s_{i,j} |x_{corrupt}, s_{z<i} , s_{i,<j} ) pθ(si∣xcorrupt,sz<i)=∏j=1lipθ(si,j∣xcorrupt,sz<i,si,<j)
我们使用以下技术实现自回归空白填充目标。输入
x
x
x被分成两部分:第一部分A是损坏文本
x
c
o
r
r
u
p
t
x_{corrupt}
xcorrupt,第二部分B由掩蔽的跨度组成。第一部分A的标记可以相互关注,但不能关注第二部分B中的任何标记。第二部分B的标记可以关注第一部分A和B中的先行标记,但不能关注B中的任何后续标记。为了实现自回归生成,每个跨度都用特殊标记[START]和[END]填充,作为输入和输出。这样,我们的模型在一个统一的模型中自动学习双向编码器(用于第一部分A)和单向解码器(用于第二部分B)。GLM的实现如图2所示。
我们从泊松分布(λ = 3)中随机抽样长度为的跨度。我们反复抽样新的跨度,直到至少有15%的原始令牌被掩蔽。根据实验证明,15%的比率对于在下游NLU任务中获得良好性能至关重要。
2.1.2 多任务预训练
在前面的部分中,GLM掩蔽短跨度,并适用于NLU任务。然而,我们有兴趣预训练一个单一模型,可以处理NLU和文本生成。我们研究了一个多任务预训练设置,其中第二个目标是与空白填充目标联合优化的长文本生成任务。我们考虑以下两个目标:
• 文档级别。我们随机抽样一个跨度,其长度从原始长度的50%到100%的均匀分布中抽样。该目标旨在进行长文本生成。
• 句子级别。我们限制掩蔽跨度必须是完整的句子。我们随机抽样多个跨度(句子)以覆盖15%的原始令牌。此目标旨在进行序列到序列任务,其预测通常为完整的句子或段落。
这两个新目标与原始目标相同,即Eq.1。唯一的区别在于跨度数量和跨度长度。
2.2 模型架构
GLM使用单个Transformer,并对架构进行了几个修改:(1)我们重新排列了层归一化和残差连接的顺序,这已被证明对于避免数值错误的大规模语言模型至关重要(Shoeybi等,2019);(2)我们使用单个线性层进行输出标记预测;(3)我们用GeLU激活函数替换了ReLU激活函数(Hendrycks和Gimpel,2016)。
2.2.1 二维位置编码
自回归空白填充任务的一个挑战是如何编码位置信息。Transformer依赖于位置编码来注入令牌的绝对和相对位置。我们提出了2D位置编码来解决这个问题。具体来说,每个令牌都用两个位置ID进行编码。第一个位置ID表示在损坏的文本xcorrupt中的位置。对于掩蔽区域,它是相应的[MASK]令牌的位置。第二个位置ID表示内部跨度位置。对于Part A中的令牌,它们的第二个位置ID为0。对于Part B中的令牌,它们的位置范围从1到跨度的长度。这两个位置ID通过可学习的嵌入表投影为两个向量,这两个向量都被添加到输入令牌的嵌入中。我们的编码方法确保模型在重构掩蔽区域时不知道它们的长度。这是与其他模型的重要区别。例如,XLNet(Yang等,2019)编码原始位置,以便它可以感知缺失令牌的数量,而SpanBERT(Joshi等,2020)使用多个[MASK]令牌替换跨度并保持长度不变。我们的设计适用于下游任务,因为通常不知道生成文本的长度。
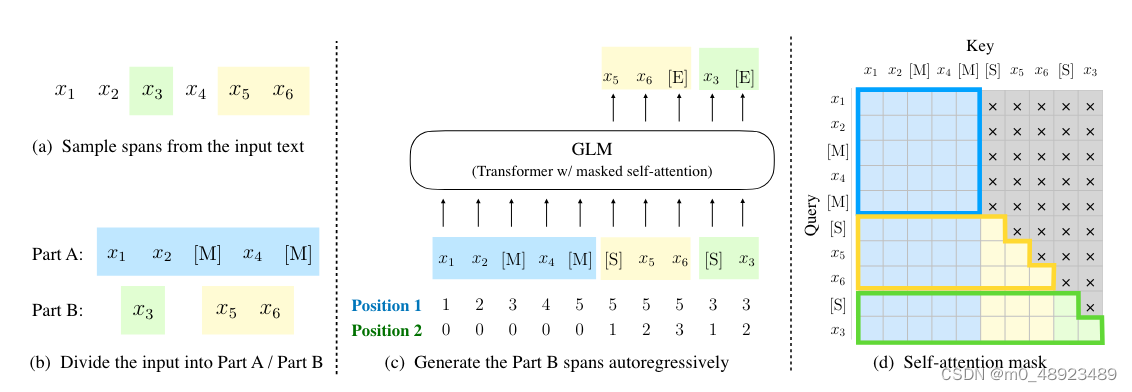
图2:GLM预训练。(a) 原始文本为
[
x
1
,
x
2
,
x
3
,
x
4
,
x
5
,
x
6
]
[x_1, x_2, x_3, x_4, x_5, x_6]
[x1,x2,x3,x4,x5,x6]。采样了两个跨度
[
x
3
]
[x_3]
[x3] 和
[
x
5
,
x
6
]
[x_5, x_6]
[x5,x6]。(b) 在 Part A 中用
[
M
]
[M]
[M] 替换采样的跨度,在 Part B 中打乱跨度的顺序。© GLM 自回归生成 Part B。每个跨度在输入时添加
[
S
]
[S]
[S],在输出时添加
[
E
]
[E]
[E]。2D 位置编码表示跨度之间和跨度内部的位置。(d) 自注意力掩码。灰色区域被掩盖。Part A 的标记可以关注自身(蓝框),但不能关注 Part B。Part B 的标记可以关注 A 和 B 中它们的前置标记(黄色和绿色框分别对应两个跨度)。
[
M
]
:
=
[
MASK
]
[M] := [\text{MASK}]
[M]:=[MASK],
[
S
]
:
=
[
START
]
[S] := [\text{START}]
[S]:=[START],
[
E
]
:
=
[
END
]
[E] := [\text{END}]
[E]:=[END]。
2.3 微调广义线性模型
通常情况下,在下游的自然语言理解任务中,线性分类器将预训练模型生成的序列或标记表示作为输入,并预测正确的标签。这些实践与生成式预训练任务不同,导致预训练和微调之间存在不一致性。因此,我们将自然语言理解分类任务重新表述为填空生成任务,遵循PET(Schick and Schütze,2020a)的方法。具体而言,对于给定的标记示例 ( x , y ) (x, y) (x,y),我们通过包含单个掩码标记的模式将输入文本 x x x转化为填空题 c ( x ) c(x) c(x)。该模式用自然语言书写,以表示任务的语义。例如,情感分类任务可以表示为“{SENTENCE}. It’s really [MASK]”(“{SENTENCE}”为句子部分,即输入文本;“[MASK]”为掩码标记)。候选标签 y ∈ Y y \in Y y∈Y也被映射到填空题的答案中,称为口语化表述 v ( y ) v(y) v(y)。在情感分类中,“positive”和“negative”标签被映射到单词“good”和“bad”。给定 x x x,预测 y y y的条件概率为
p ( y ∣ x ) = p ( v ( y ) ∣ c ( x ) ) ∑ y ′ ∈ Y p ( v ( y ′ ) ∣ c ( x ) ) p(y|x) = \frac{p(v(y)|c(x))}{\sum\limits_{y' \in Y} p(v(y')|c(x))} p(y∣x)=y′∈Y∑p(v(y′)∣c(x))p(v(y)∣c(x))
对于文本生成任务,给定的上下文构成了输入的A部分,末尾附加一个掩码标记。模型通过自回归的方式生成B部分的文本。我们可以直接使用预训练的广义线性模型进行无条件生成,或者在下游条件生成任务上进行微调。
(其中 Y Y Y为标签集合)。因此,句子为正面或负面的概率与在填空处预测“good”或“bad”成比例。然后,我们使用交叉熵损失微调广义线性模型(参见图3)。
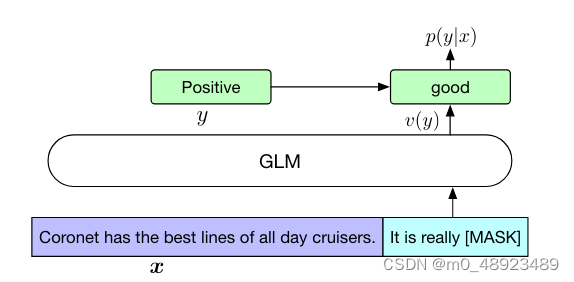
图3:将情感分类任务作为使用广义线性模型填充空白的公式化。
2.4 讨论和分析
本节中,我们将讨论广义线性模型与其他预训练模型的区别,主要关注它们如何适应下游的填空生成任务。
与BERT(Devlin等,2019)的比较。正如(Yang等,2019)所指出的,由于MLM的独立性假设,BERT无法捕捉到掩码标记之间的相互依赖关系。BERT的另一个缺点是它无法正确地填充多个标记的空白。为了推断出长度为 l l l的答案的概率,BERT需要进行 l l l次连续的预测。如果长度 l l l是未知的,我们可能需要枚举所有可能的长度,因为BERT需要根据长度更改[MASK]标记的数量。
与XLNet(Yang等,2019)的比较。GLM和XLNet都使用自回归目标进行预训练,但它们之间存在两个差异。首先,XLNet在破坏前使用原始位置编码。在推断过程中,我们需要知道或枚举答案的长度,与BERT相同的问题。其次,XLNet使用双流自注意机制,而不是向右移位,以避免Transformer内部的信息泄漏。这将导致预训练的时间成本加倍。
与T5(Raffel等,2020)的比较。T5提出了类似的填空生成目标,以预训练编码器-解码器Transformer。T5为编码器和解码器使用独立的位置编码,并依赖于多个标记来区分掩码范围。在下游任务中,只使用其中一个标记,导致了模型容量的浪费和预训练与微调之间的不一致性。此外,T5始终按固定的从左到右的顺序预测范围。因此,如第3.2节和第3.3节所述,GLM可以在具有更少参数和数据的情况下显着优于T5的NLU和seq2seq任务。
与UniLM(Dong等,2019)的比较。UniLM通过在双向、单向和交叉注意力之间更改注意力掩码,将不同的预训练目标结合到自编码框架中。但是,UniLM始终使用[MASK]标记替换掩码范围,这限制了它对掩码范围及其上下文之间依赖关系的建模能力。GLM输入前一个标记,并自回归地生成下一个标记。在下游的生成任务上,微调UniLM还依赖于掩码语言建模,效率较低。UniLMv2(Bao等,2020)采用部分自回归建模用于生成任务,并采用自编码目标用于NLU任务。相反,GLM使用自回归预训练统一了NLU和生成任务。
3 实验
我们现在描述我们的预训练设置和下游任务的评估。
3.1 预训练设置
为了与BERT(Devlin等,2019)进行公平比较,我们使用BooksCorpus(Zhu等,2015)和英文维基百科作为我们的预训练数据。我们使用BERT的未大小写的WordPiece分词器,词汇表大小为30k。我们使用与BERTBase和BERTLarge相同的架构来训练GLMBase和GLMLarge,分别包含110M和340M个参数。对于多任务预训练,我们使用空白填充目标和文档级或句子级目标的混合训练两个大型模型,分别称为GLMDoc和GLMSent。此外,我们使用文档级多任务预训练训练了两个更大的GLM模型,分别具有410M(30层,隐藏大小为1024,16个注意力头)和515M(30层,隐藏大小为1152,18个注意力头)个参数,分别称为GLM410M和GLM515M。为了与SOTA模型进行比较,我们还训练了一个与RoBERTa(Liu等,2019)具有相同数据、分词和超参数的大型模型,称为GLMRoBERTa。由于资源限制,我们只对模型进行了250,000步的预训练,这是RoBERTa和BART训练步骤的一半,并且接近T5训练的令牌数量。更多的实验细节可以在附录A中找到。
3.2 SuperGLUE
为了评估我们预训练的GLM模型,我们在SuperGLUE基准测试(Wang等,2019)上进行实验,并报告标准度量。SuperGLUE由8个具有挑战性的NLU任务组成。我们按照PET(Schick和Schütze,2020b)的方法,将分类任务重新表述为填空生成,并提供人工制作的闭合问题。然后,我们按照第2.3节的描述,对每个任务对预训练的GLM模型进行微调。闭合问题和其他细节可以在附录B.1中找到。
为了与GLMBase和GLMLarge进行公平比较,我们选择BERTBase和BERTLarge作为基线,它们使用相同的语料库进行预训练,并且预训练的时间相近。我们报告标准微调(即对[CLS]标记表示进行分类)的性能。BERT使用闭合问题的性能在第3.4节中报告。
为了与GLMRoBERTa进行比较,我们选择T5、BARTLarge和RoBERTaLarge作为基线。T5在与BERTLarge的参数数量上没有直接匹配,因此我们展示了T5Base(220M个参数)和T5Large(770M个参数)的结果。所有其他基线都与BERTLarge的大小相似。表1显示了结果。
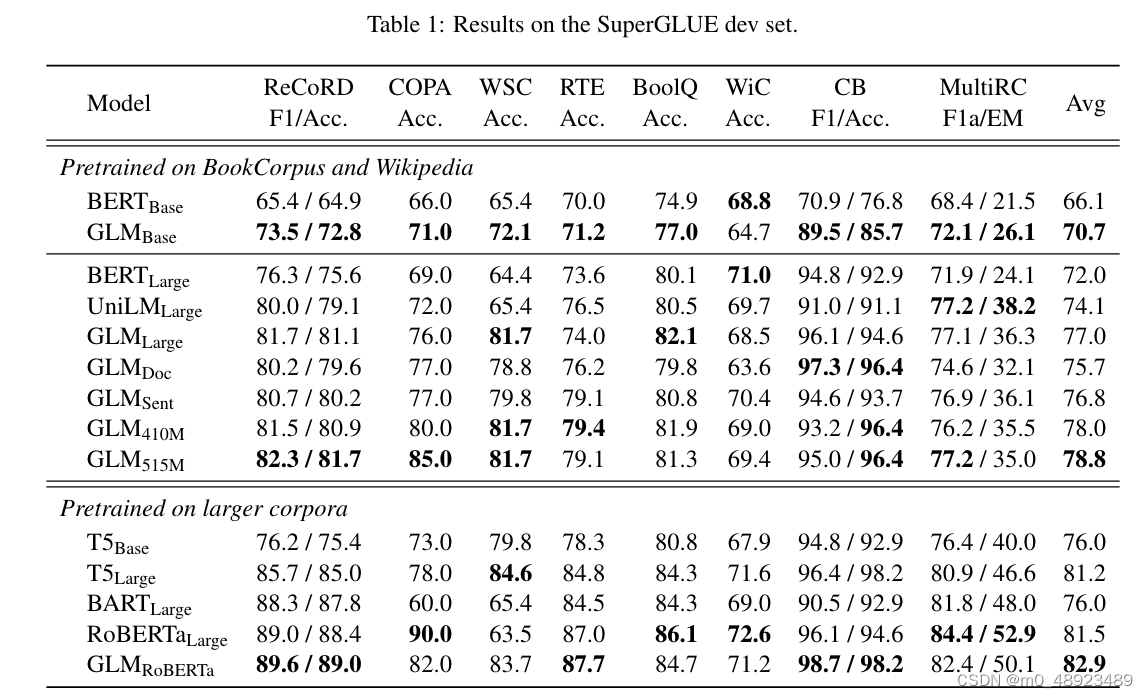 表1:在SuperGLUE开发集上的结果。
表1:在SuperGLUE开发集上的结果。
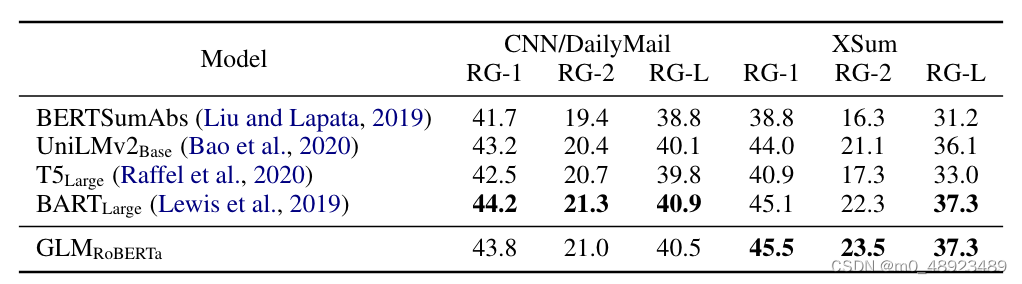
表2:在CNN/DailyMail和XSum测试集上进行的生成式摘要的结果。
在相同数量的训练数据下,GLM在大多数任务上均优于具有基础或大型架构的BERT,唯一的例外是WiC(词义消歧)。平均而言,GLMBase的得分比BERTBase高4.6%,GLMLarge的得分比BERTLarge高5.0%。这清楚地表明了我们方法在NLU任务中的优势。在RoBERTaLarge设置中,GLMRoBERTa仍然可以超过基线,但差距较小。具体来说,GLMRoBERTa胜过了T5Large,但只有其一半大小。我们还发现BART在具有挑战性的SuperGLUE基准测试上表现不佳。我们推测这可能归因于编码器-解码器架构和去噪序列到序列目标的参数效率低。
3.3 多任务预训练
然后我们在多任务设置中评估GLM的表现(第2.1节)。在一个训练批次中,我们等概率地采样短跨度和长跨度(文档级别或句子级别)。我们对自然语言理解(NLU)、序列到序列(seq2seq)、空白填充和零样本语言建模等多任务模型进行评估。SuperGLUE。对于NLU任务,我们在SuperGLUE基准测试上评估模型。结果也显示在表1中。我们观察到,在多任务预训练下,GLMDoc和GLMSent的表现略逊于GLMLarge,但仍然优于BERTLarge和UniLMLarge。在多任务模型中,GLMSent平均比GLMDoc表现好1.1%。将GLMDoc的参数增加到410M(1.25×BERTLarge)可以比GLMLarge获得更好的表现。具有515M参数(1.5×BERTLarge)的GLM甚至可以表现更好。
序列到序列。考虑到可用的基准结果,我们使用Gigaword数据集(Rush等人,2015)进行抽象概括,使用SQuAD 1.1数据集(Rajpurkar等人,2016)进行问题生成(Du等人,2017)作为预训练在BookCorpus和维基百科上的模型的基准测试。此外,我们使用CNN/DailyMail(See等人,2017)和XSum(Narayan等人,2018)数据集作为在更大语料库上预训练的模型的抽象概括基准测试。在表3和4中显示了在BookCorpus和维基百科上训练的模型的结果。我们观察到,GLMLarge可以在这两个生成任务上实现与其他预训练模型相匹配的性能。GLMSent可以比GLMLarge表现更好,而GLMDoc的表现略逊于GLMLarge。这表明文档级别目标,即教授模型扩展给定的上下文,对条件生成不太有帮助,而条件生成旨在从上下文中提取有用信息。将GLMDoc的参数增加到410M可以在两个任务上获得最佳性能。在更大语料库上训练的模型的结果显示在表2中。GLMRoBERTa可以实现与seq2seq BART模型相匹配的性能,并且优于T5和UniLMv2。
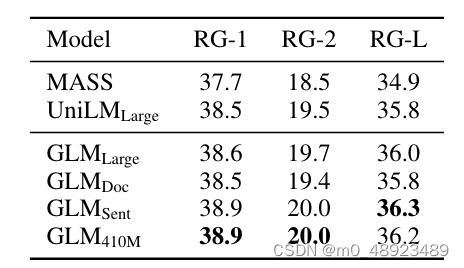
表3:在Gigaword摘要任务上的结果。
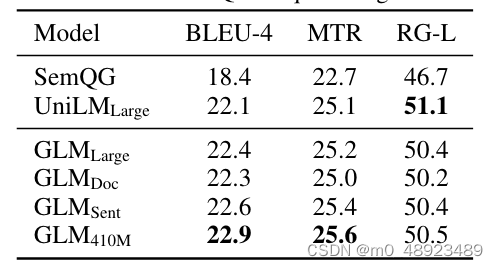
表4:在SQuAD问答生成任务上的结果。
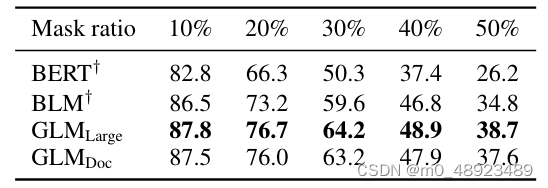
表5:在Yahoo文本填充任务上的BLEU得分。†表示来自(Shen等人,2020)的结果。
文本填充。文本填充是预测与周围上下文一致的缺失文本段落的任务(Zhu等人,2019;Donahue等人,2020;Shen等人,2020)。GLM通过自回归空白填充目标进行训练,因此可以直接解决这个任务。我们在Yahoo Answers数据集(Yang等人,2017)上评估GLM,并与专门设计用于文本填充的Blank Language Model(BLM)(Shen等人,2020)进行比较。从表5的结果可以看出,GLM大幅优于先前的方法(1.3到3.9 BLEU),在该数据集上达到了最先进的结果。我们注意到GLMDoc略逊于GLMLarge,这与我们在序列到序列实验中的观察一致。
语言建模。大多数语言建模数据集(如WikiText103)都是由维基百科文档构建的,而我们的预训练数据集已经包含了它们。因此,我们在预训练数据集的一个保留测试集(包含约20M个令牌)上评估语言建模的困惑度,标记为BookWiki。我们还在LAMBADA数据集(Paperno等人,2016)上评估GLM,该数据集测试系统对文本中长程依赖关系的建模能力。任务是预测一个段落的最后一个词。作为基准,我们使用与GLMLarge相同的数据和分词方式训练一个GPTLarge模型(Radford等人,2018b;Brown等人,2020)。
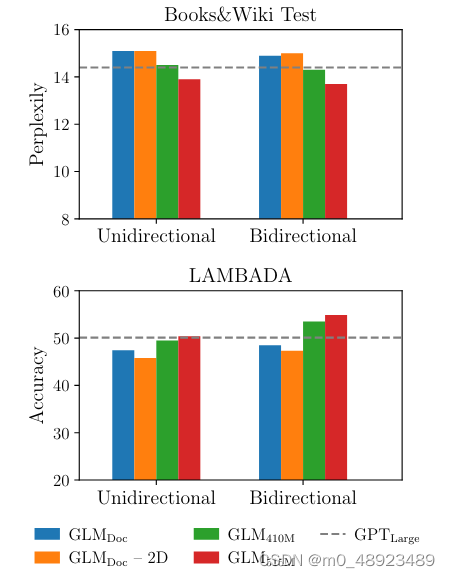
图4:零样本语言建模的结果。
结果显示在图4中。所有模型都在零样本设置下进行评估。由于GLM学习双向注意力,我们还评估了在编码上下文时使用双向注意力的GLM设置。在预训练期间没有生成目标的情况下,GLMLarge无法完成语言建模任务,困惑度大于100。使用相同数量的参数,GLMDoc的表现比GPTLarge还差。这是预期的,因为GLMDoc还优化了空白填充目标。将模型的参数增加到410M(GPTLarge的1.25×)可以使其表现接近于GPTLarge。GLM515M(GPTLarge的1.5×)可以进一步优于GPTLarge。在相同数量的参数下,使用双向注意力编码上下文可以提高语言建模的性能。在这种设置下,GLM410M优于GPTLarge。这是GLM相对于单向GPT的优势。我们还研究了2D位置编码对长文本生成的贡献。我们发现去除2D位置编码会降低语言建模的准确度和困惑度。
总结。总的来说,我们得出结论,GLM有效地在自然语言理解和生成任务之间共享模型参数,比独立的BERT、编码器-解码器或GPT模型实现了更好的性能。
表6:在SuperGLUE开发集上的消融研究。(T5 ≈ GLM - 洗牌跨度 + 哨兵标记)
3.4 消融研究
表6展示了我们对GLM进行的消融分析。首先,为了提供与BERT的苹果对苹果比较,我们使用我们的实现、数据和超参数训练了一个BERTLarge模型(第2行)。其性能略差于官方BERTLarge,并且明显劣于GLMLarge。这证实了GLM在NLU任务上的优越性超过了Masked LM预训练。
其次,我们展示了GLM微调为序列分类器(第5行)和BERT采用clozestyle微调(第3行)的SuperGLUE性能。与BERT采用cloze-style微调相比,GLM受益于自回归预训练。特别是在ReCoRD和WSC上,其中verbalizer包含多个标记的情况下,GLM始终优于BERT。这证明了GLM在处理可变长度空白时的优势。另一个观察是,cloze公式对GLM在NLU任务上的性能至关重要。对于大型模型,clozestyle微调可以提高性能7个百分点。
最后,我们比较不同预训练设计的GLM变体,以了解它们的重要性。第6行显示,去除跨度洗牌(总是从左到右预测掩码跨度)会导致SuperGLUE性能严重下降。第7行使用不同的哨兵标记代替单个[MASK]标记表示不同的掩码跨度。该模型的性能比标准GLM差。我们假设它浪费了一些建模容量来学习不同的哨兵标记,这些标记在只有一个空白的下游任务中并未使用。在图4中,我们展示去除2D位置编码的第二个维度会损害长文本生成的性能。我们注意到T5使用类似的空白填充目标进行预训练。GLM在三个方面不同:(1)GLM由单个编码器组成,(2)GLM对掩码跨度进行洗牌,(3)GLM使用单个[MASK]而不是多个哨兵标记。虽然由于训练数据和参数数量的差异,我们无法直接比较GLM和T5,但表1和表6的结果已经证明了GLM的优势。
4 相关工作
预训练语言模型。预训练大规模语言模型显著提高了下游任务的性能。有三种类型的预训练模型。第一种是自编码模型,通过去噪目标学习双向上下文化编码器进行自然语言理解(Devlin等,2019;Joshi等,2020;Yang等,2019;Liu等,2019;Lan等,2020;Clark等,2020)。第二种是采用从左到右的语言建模目标训练的自回归模型(Radford等,2018a,b;Brown等,2020)。第三种是编码器-解码器模型,用于序列到序列任务的预训练(Song等,2019;Lewis等,2019;Bi等,2020;Zhang等,2020)。在编码器-解码器模型中,BART(Lewis等,2019)通过将相同的输入馈送到编码器和解码器中,并取解码器的最终隐藏状态来进行NLU任务。而T5(Raffel等,2020)则将大多数语言任务形式化为文本到文本框架。然而,这两个模型需要更多的参数才能胜过RoBERTa(Liu等,2019)等自编码模型。UniLM(Dong等,2019;Bao等,2020)在不同的注意力掩码下统一了三种预训练模型的掩码语言建模目标。
NLU作为生成。以前,预训练语言模型使用线性分类器在学习表示上完成NLU分类任务。GPT-2(Radford等,2018b)和GPT-3(Brown等,2020)表明,生成式语言模型可以直接预测正确答案,完成诸如问答等NLU任务,而无需进行微调或提供任务说明或少量标记样本。然而,由于单向注意力的限制,生成模型需要更多的参数才能正常工作。最近,PET(Schick和Schütze,2020a,b)提出在少样本情况下,将输入示例重新制定为带有类似于预训练语料库的模式的掩码问题。与梯度微调结合使用后,已经证明PET可以在少样本情况下比GPT-3实现更好的性能,同时只需要0.1%的参数。类似地,Athiwaratkun等人(2020)和Paolini等人(2020)将结构化预测任务(如序列标记和关系提取)转换为序列生成任务。
空白语言建模。Donahue等人(2020)和Shen等人(2020)也研究了空白填充模型。与他们的工作不同,我们使用空白填充目标进行语言模型的预训练,并在下游的NLU和生成任务中评估它们的性能。
5 结论
GLM是一种用于自然语言理解和生成的通用预训练框架。我们展示了NLU任务可以被形式化为条件生成任务,因此可以由自回归模型解决。GLM将不同任务的预训练目标统一为自回归空白填充,具有混合的注意力掩码和新颖的二维位置编码。我们的实验证明GLM在NLU任务中优于先前的方法,并且可以有效地共享参数以用于不同的任务。















 1795
1795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









