







这篇论文还是还是有许多人通读的,给几个我用来参考的链接:
https://www.jianshu.com/p/7582df96b081 和https://www.pianshen.com/article/819194787/
https://zhuanlan.zhihu.com/p/158985765
首先先看一下网上的解析,对这篇文章有一个直接的认识。
他的方法就是:使用cnn提取图像特征,并将softmax层之前的那一层vector作为encoder端的输出并送入decoder中,并使用LSTM对其解码生成句子,但是这篇文章更近一步,在基础上嵌入了soft和hard attention。
(数学公式太复杂了)
整体架构:

为此分为两个步骤,第一个步骤是用CNN提取特征,再是用有attention机制的RNN来解码特征。
相当于就是分成了三个部分,编码器encoder,attention机制和解码器(decoder)
编码器(encoder)
在这篇文章中采用的是经过预训练的VggNet作为编码器提取图像的特征。
并且值得注意的是:他与之前的使用softmax层之前的全连接层提取图像特征不同,这篇论文提取的特征是来自
low-level的卷积层,所以可以用decoder通过选择所有特征向量的子集来选择性地聚焦于图像的某些部分,为此也就可以引出attention机制。
注意力机制(attention机制)
这个的原理就是:生成一组权重,对需要关注的部分给予较高的权重,不需要关注的部分给予较低的权重。在这篇文章中,提到了两种注意力方法:hard
attention和soft attention (公式没记住)
解码器(decoder)
就是RNN和lstm
其中看到一个视频里的图片总结:

然后知乎上的一个说法就是:**
这个文章的创新点在于引进了“注意力”机制,而图像也不是从一开始就全部编码“静态地”传入lstm,而是在每一个time
step将不同的特征“动态地”传到lstm.从而生成对应的单词,一次encoder之后的信息也不再是经过整个convnet处理的图像,而是低卷积层的特征。
**
之后就是对这两种注意力机制:soft deterministic和hard stochastic机制的具体讨论了。
论文细则:
首先在摘要中就提到了:
- 标准的反向传播技术
- 最大化变分下界 这两个刚好对应了两种注意力机制。
在第三章中开始了对两种注意力机制的解析,首先要知道的是,这两种注意力机制最主要的区别就是函数的定义。并且在之后的代码中,粗字体表示向量,大写字母表示矩阵。

这个是对应的LSTM,与之前不同的就是在于,在每一个time step的输出里多了一个 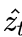
这个是捕捉了图像特定位置信息的向量,而注意力机制也是体现在这里。
并且开始对每个步骤进行介绍:
Encoder:
公式是这样的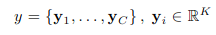
,其中k是词汇表的大小,c是标题的长度。在这个解码器中,通过公式可以通过选择所有特征向量的子集来选择性地聚焦于图像的某些部分。
在decoder部分,数学公式就推导的比较复杂了,
参考网上博主,总的来说是这样的:

而其中的soft-attention就是:调用了一个函数,这个函数可以a转换为z,并且soft的就是直接根据a中的权重对a进行甲醛就和,直接得到a,而hard attention就比较复杂了,差不多就是说 每次从a中抽取一个向量(只关注图片中的一个区域,soft时会给重点关注区域分配较高的权重,不重点关注的区域较低的权重),而抽取向量的过程做成一个从多项分布里抽样的过程,通过多次抽样来计算梯度,再通过平均梯度来更新参数














 2128
2128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









