







简介
它是一个分布式服务框架,是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
Zookeeper=文件系统+监听通知机制,可以用来设计成注册中心 ,服务端上线之后,在注册中心注册自己的服务与对应的地址,而客户端调用服务时,就去注册中心根据服务名找到对应的服务端地址
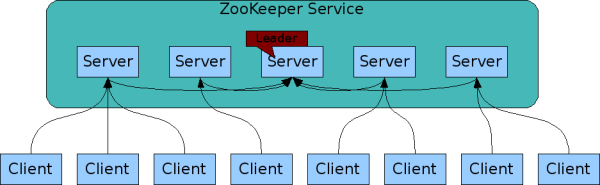
通过这个网站的介绍:https://www.cnblogs.com/aishangJava/p/12446601.html,首先要知道它的出现是为了解决单点问题
单点问题
指在系统中一旦失效就会让整个系统无法运作的部件。如果把系统只部署在机器A这一台机器上,那么A失效的话,整个系统都无法运作,而之前的解决方式就是采用冗余,也就是增加多台机器,只要多台机器不同时失效的话,系统就可以正常运作
无状态的单点问题
无状态指的是 http无状态协议,可以通过集群的方式解决。
比如弄几个消息转发服务器,其中一个(消息转发服务器X)宕机了,其他的服务器也能工作。

有状态的单点问题
如果是有状态的话,就会存在 分布式不一致的问题:(我对于分布式不一致的理解是,如果是有状态的,服务器每进行一次交互,他的状态都会发生改变,所以可以体现为“每一个服务器都是独一无二的”。这样就不能简单的用一个服务器宕机了,就换另一个服务器的做法了)
解决方法
- 去状态:将问题去除为无状态,例如将状态存储到可靠的DB中;
- 主从:由 Master 做主要的数据处理,Slaver 同步 Master 的状态,例如 MySQL 的主从复制,Master 处理写操作,Slaver 通过 binlog 同步状态。
所以可以理解为 他需要将这个“独一无二”给去掉,通过同步,使之成为一样的

Zookeeper作为注册中心
https://blog.csdn.net/weixin_44801979/article/details/90550579
原理:
简单来说就是,zookeeper充当一个服务注册表,让多个服务提供者形成一个集群,让服务消费者通过服务注册表获取具体的服务访问地址(ip+端口)去访问具体的服务提供者
而具体来说,zookeeper就是个分布式文件系统,每当一个服务提供者部署后都要把自己的服务注册到一个zookeeper的某一个路径当中。: /{service}/{version}/{ip:port},比如我们的HelloWorldService部署到两台机器,那么zookeeper上就会创建两条目录:分别为/HelloWorldService/1.0.0/100.100.0.237:16888

这里还有关于数据节点 znode的知识

进行服务注册的话,就是创建一个znode节点,该节点存储该服务的ip,端口和调用方式(协议,序列化方式),他有着最重要的职责。他server,也就是服务提供者(发布任务时)创建,以供服务消费者获取节点信息,从而定位到服务提供者 真正的网络位置,以及得知 如何调用等等信息
简述过程
- 服务提供者启动之后,会将其服务名称,ip地址注册到配置中心中
- 服务消费者,在第一次调用服务的时候,通过注册中心找到相应服务的ip地址,然后缓存到本地,并且当消费者调用服务的时候,就不去注册中心,而是通过 负载均衡算法从ip列表中取出一个服务提供者的服务器来调用服务
- 服务提供者的某台服务器宕机之后,ip就会从服务提供者ip列表中移除,并且注册中心 zookeeper会将新的服务ip地址列表发送给服务消费者机器,缓存在消费者本机中
- 当某个服务的服务器都下线了,这个服务也就下线
- 服务提供者的服务器上线,注册中心会将新的服务Ip地址列表发送到服务消费者机器,缓存在消费者本机
- 服务提供放可以根据服务消费者的数量来作为服务下线的依据
感知服务的上下线
zookeeper提供了“心跳检测”功能,它会定时向各个服务提供者发送一个请求(实际上建立的是一个 socket 长连接),如果长期没有响应,服务中心就认为该服务提供者已经“挂了”,并将其剔除。比如100.100.0.237这台机器如果宕机了,那么zookeeper上的路径就会只剩/HelloWorldService/1.0.0/100.100.0.238:16888。
服务消费者会去监听相应路径(/HelloWorldService/1.0.0),一旦路径上的数据有任务变化(增加或减少),zookeeper都会通知服务消费方、服务提供者地址列表已经发生改变,从而进行更新。
更为重要的是zookeeper 与生俱来的容错容灾能力(比如leader选举),可以确保服务注册表的高可用性。
使用 zookeeper 作为注册中心时,客户端订阅服务时会向 zookeeper 注册自身;主要是方便对调用方进行统计、管理。但订阅时是否注册 client 不是必要行为,和不同的注册中心实现有关,例如使用 consul 时便没有注册。
下载与安装
https://blog.csdn.net/zlbdmm/article/details/109669049
Zookeeper下载
Project-> Project List

2、在ProjectList页面中找点Zookeeper链接,然后点击进入Zookeeper的主页,

3.在Zookeeper主页的顶部点击菜单Project->Releases,进入Zookeeper发布版本信息页面,如下图:

4、找到一个自己觉得合适的版本,不一定是最新版,如下图:

5、我下的是 3.5.9版本,点击链接进入下载的镜像地址页面,如下图:

6、在国内直接选择清华大学的镜像下载链接进行下载就行,下载后如下图:

Zookeeper安装
单机模式部署
1、解压apache-zookeeper-3.5.9-bin.tar.gz至D:\zookeeper\apache-zookeeper-3.5.9-bin。

2、复制D:\zookeeper\apache-zookeeper-3.5.9-bin\conf\zoo-sample.cfg,粘贴为D:\zookeeper\apache-zookeeper-3.5.9-bin\conf\zoo.cfg。

3、修改D:\zookeeper\apache-zookeeper-3.5.9bin\zoo.cfg。
主要修改了 dataDir
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=D:\zookeeper3.5.9\data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
# server.N = YYY:A:B
然后新建这个data文件

配置文件关键配置项说明:
- tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
- initLimit:LF初始通信时限,集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
- syncLimit:LF同步通信时限,集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。\
- dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
- clientPort:客户端连接端口,这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
- autopurge.snapRetainCount:保留数量。
- autopurge.purgeInterval:清理时间间隔,单位:小时。
- server.N = YYY:A:B,其中N表示服务器编号,YYY表示服务器的IP地址,A为LF通信端口,表示该服务器与集群中的leader交换的信息的端口。B为选举端口,表示选举新leader时服务器间相互通信的端口(当leader挂掉时,其余服务器会相互通信,选择出新的leader)。一般来说,集群中每个服务器的A端口都是一样,每个服务器的B端口也是一样。但是当所采用的为伪集群时,IP地址都一样,只能时A端口和B端口不一样。
4、启动Zookeeper服务器。
在bin目录下执行
zkServer.cmd
5.运行结果

出现错误
https://www.cnblogs.com/dupang/p/6036357.html
首先一点是
dataDir=D:/zookeeper-3.3.6/data这样是可以的
dataDir=D:\ookeeper-3.3.6\data这样是可以的
dataDir=D:\ookeeper-3.3.6\data这样是不行的
其次是在命令行的话
zkServer.cmd是不行的
zkServer是可以的















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









