







架构设计:
离线数仓
实时数仓
湖仓一体
数据治理:数据质量管理、元数据管理、安全管理(Kerberos)、
数据仓库:面向主题的、集成的、相对稳定的、反应历史数据变化的数据集合、数仓中的数据是有组织的存储数据集合、用于对管理决策过程的支持
构建数据仓库的原因:一般公司的业务数据存储在互不兼容的系统中,会存在数据孤岛的问题,还有关系型数据库一般不存储日志数据;所以需要把各个分散在各个业务系统的数据,集成到一起,通过处理做一个分类规整,有规范化的数据方便分析,从商业的角度,方便为决策侧提供帮助
数仓分层设计:目的使多业务复杂的数据通过分层处理得到清晰规范的数据结构,减少重复开发、统一数据出口、
ODS层(Operational Data Store操作数据层) --直接存放业务系统抽取过来的数据,将不同业务系统中的数据汇聚到一起,
DW层(Data Warehouse)–按照主题构建各种数据模型,该层下有3层
DWD层(Data Warehouse Detail 数据明细层)–保证数据质量、在ODS层基础上对数据加工处理,提供干净的数据,例如抽取改过来的各个订单表信息处理合并到一起
DWM层(Data Warehouse Middle 数据中间层)–以通用的维度进行轻度聚合操纵,计算相应统计指标、方便复用,例如:订单信息表,每一天可能有多个订单,需要处理按天统计或按周维度统计
DWS层(Data Warehouse Service数据服务层) --按照主题业务组织主题宽表,用于OLAP分析,把主题下的表关联起来组成一个主题宽表,例如订单表有下订单时间,商家消息,地域信息,卖家维度,产品维度,关联起来
DM层(Data Mart数据集市层)–基于DW层基础上,整合汇总分析成某一主题域的报表数据
大数据架构演进:
离线数仓:,基于分布式计算框架计算读取HDFS内的数据处理加工数据,也可以使用hive sql方式分析统计HDFS内的数据,hive sql底层计算其实也是转为Mapreduce计算,如果基于Hive HDFS存储数据,也可以将数据导出的DB数据库,然后展示获取数据从DB获取
缺点:不能处理流式数据

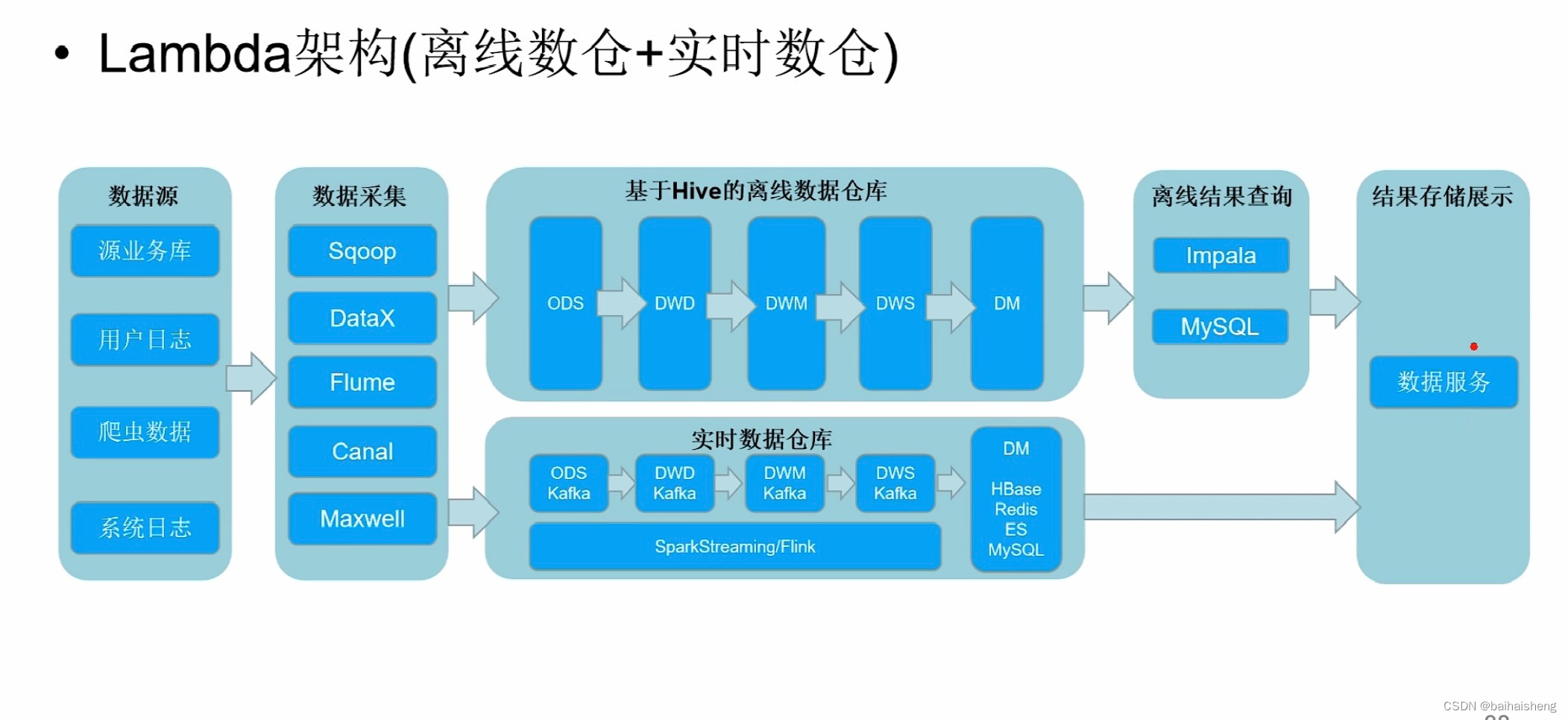
lambda架构(离线处理+实时链路):在传统离线数仓的基础上增加了使用实时采集工具采集数据,将采集的数据存储到kafka,使用flink等处理计算数据,处理后存储到Hbase等,再展示
缺点:重复开发多,数据不能被复用,

lambda架构(离线数仓+实时数仓):增加了使用实时分层处理
缺点:同一业务需求,需要两套同样的代码逻辑,增加了开发的困难,维护增加了困难,两套逻辑计算处理集群资源使用增多;离线和实时最终计算的结果不一致;T+1计算的数据是昨天产生的,当数据量特别大的时候,计算不完的情况也有可能发生;相同的数据存储两份,带来存储的成本增加
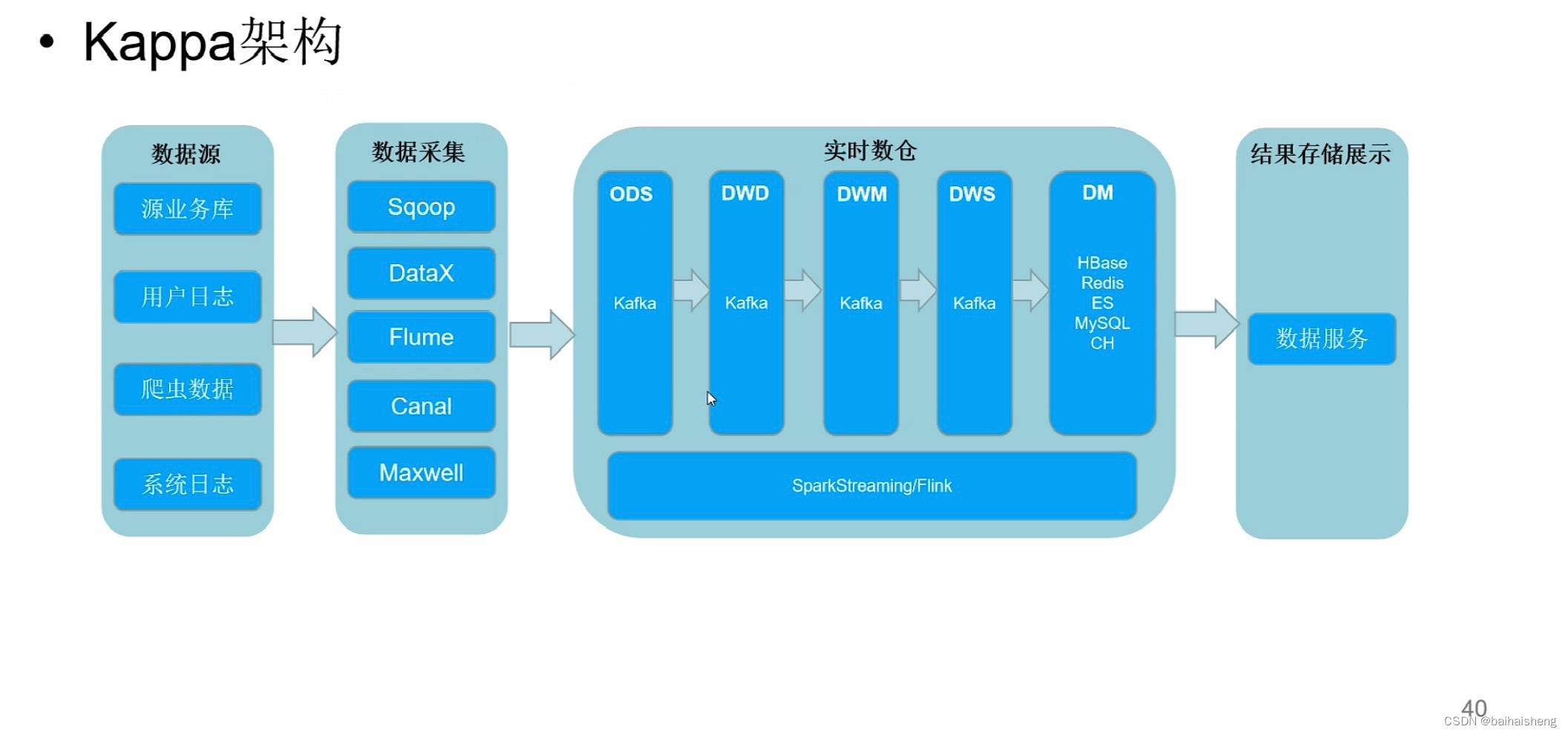
Kappa架构:去掉离线数仓处理,不管离线及实时数据,都采集到实时数仓内,经过计算处理最终展示数据结果
缺点:kafka存储数据特点是分布式的,写入数据是顺序apend追加的方式写入的,存储数据是有一点的期限,过一定的周期会清空,数仓的数据数据量大的时候,所以不能支撑海量数据的存储;构建实时数仓的时候,一般是从DM层获取查询数据,有可能从ODS层读取数据的场景,由于kafka不支持sql,所以一般只能通过引一条flink流去处理,比较麻烦;a-b-c-d四张表 有相同的字段q,d字段q数据有错误,需要追溯的时候不太方便;kafka不支持数据的更新,实时数仓处理有些场景需要更新数据,实时数仓有窗口的计算的概念(每隔多少时间计算一次),有些因为网络的原因数据来晚了,需要将数据更新,更新时候保证数仓的一致性
批流一体:计算框架spark、flink都可以计算流及批处理
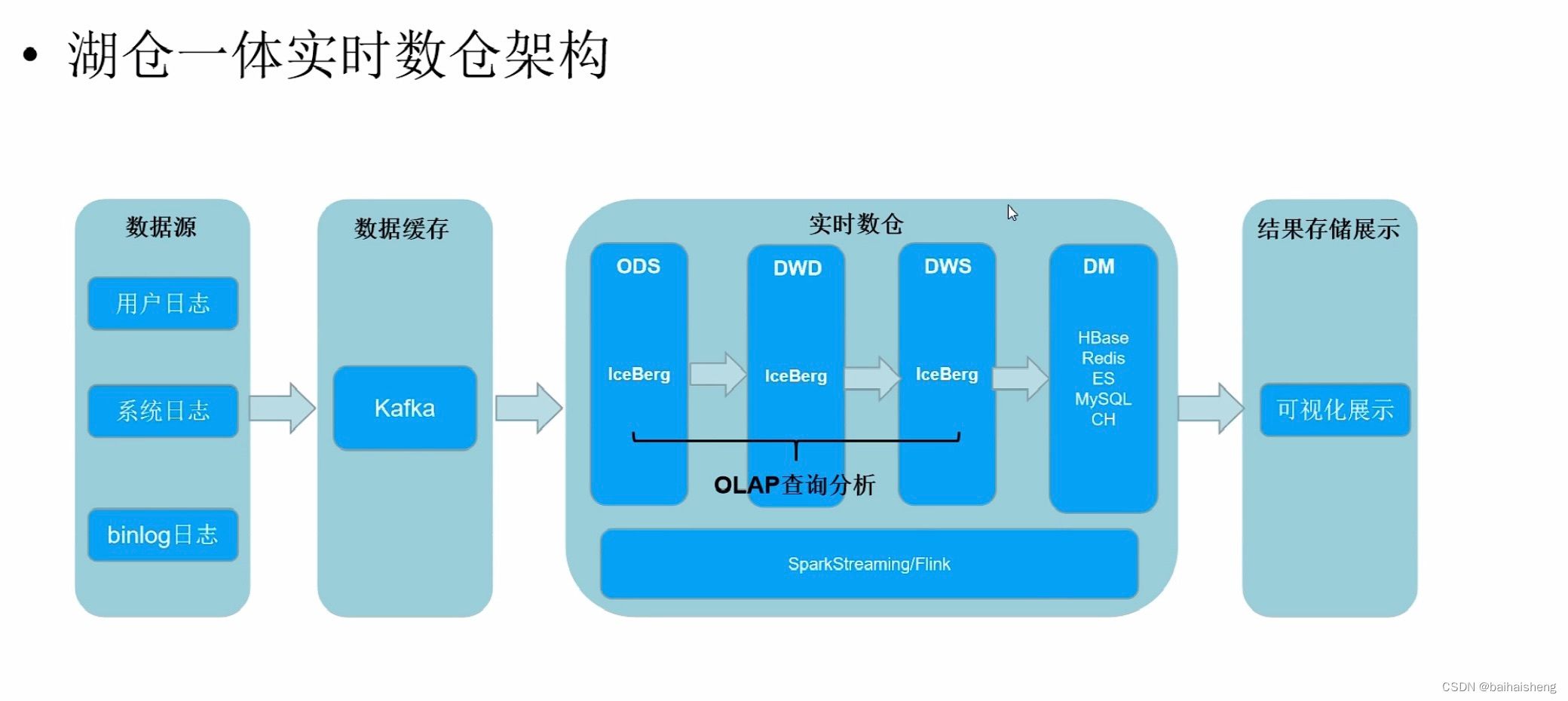
湖仓一体实时架构(按照数据湖的方式构建数仓):由于lambda,Kappa架构的缺点不支持sql、海量数据存储、任意一层支持sql、存储层面(lambda的离线和实时数据是不一致的)等问题,引入数据湖解决方案,数据湖集中式数据存储库,可以存储各种格式的结构化、非结构化的数据
目前数据湖技术主要是IceBerg、Hudi、Data Lake,发展比较完善的是Hudi,离线及实时数据都可以存储到数据湖,IceBerg、Hudi底层依赖HDFS,数据湖支持sql及数据更新,数据湖有schema概念,方便数据硕源
缺点:数据湖存储数据的速度不如kafka快
数据库与数据仓库的区别:
数据库是OLTP、数据仓库是OLAP
数据范围:数据库;当前状态数据、数据仓库:存储完整、反应历史数据变化的数据
数据变化:数据库:支持频繁的增删改、数据仓库:可增加、查询、无更新、删除操作,一般是T+1的数据,
应用场景:数据库:面向业务交易 数据仓库:面向分析、侧重决赛分析
处理数据量:数据库:频繁、小批次、高并发、低延迟;数据仓库:非频繁、大批量、高吞吐、有延迟















 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









