 C++中Vector与String详解
C++中Vector与String详解





 本文详细介绍了C++中Vector容器与String处理库的使用方法,包括如何定义与操作字符串数组,通过示例代码展示了如何输入和访问多行字符串,适用于初学者和进阶者。
本文详细介绍了C++中Vector容器与String处理库的使用方法,包括如何定义与操作字符串数组,通过示例代码展示了如何输入和访问多行字符串,适用于初学者和进阶者。
vector为c++中获取动态数组的容器,详解见https://blog.csdn.net/c20182030/article/details/69667965
string为c++中字符串处理库函数
vector M 用来处理多个string(这里的string可以理解为字符串数组,也即char[size]),字符数组可动态获取。
定义变量:vector<string> v_str;
输入多个字符串,每个字符串以回车结束后继续输入下一个串,此时若输入有换行符,换行符不作为字符保存到数组,字符赋值到v_str采用:v_str.push_back(string s);
<敲黑板>接下来是重点!!!
输入多行字符串后,我们想知道怎样调用需要的字符,因为vector以数组的形式来存储值,这时可以通过下标来调用和输出。
1、vector的行值
vector中一行字符串视为vector的一个值,类似数组中的array[i]。比如:
输入:
a
abc
abcd
那么对每一行数据的索引关系对应为:
v_str[0]:a
v_str[1]:abc
v_str[2]:abcd
2、vector的行+列值
那如果要获取v_str[1]:abc中的“b”,又要怎么办呢?
在v_str[i]中,对某一个值的索引关系对应如下:
输入:
a
abc
abcd
那么对每一行中数据的索引关系对应为:
第一行:v_str[0]:a 有:
v_str[0][0]:a
第二行:v_str[1]:abc 有:
v_str[1][0]:a;
v_str[1][1]:b;
v_str[1][2]:c;
第三行:v_str[2]:abcd有:
v_str[2][0]:a;
v_str[2][1]:b;
v_str[2][2]:c;
v_str[2][3]:d;
代码示例:
#include<iostream>
#include<vector>
#include<string>
using namespace std;
int main()
{
vector<string> v_str;
string _str;
while (cin >> _str)
{
v_str.push_back(_str);
}
for (int i = 0; i < v_str.size(); i++)
{
cout << "v_str[" << i << "]:" <<v_str[i]<< endl;
for (int j = 0; j < v_str[i].size(); j++)
{
cout << "v_str[" << i << "]["<<j<<"]="<< v_str[i][j]<<" ";
}
cout << endl;
}
system("pause");
}
上述代码运行结果如下图:
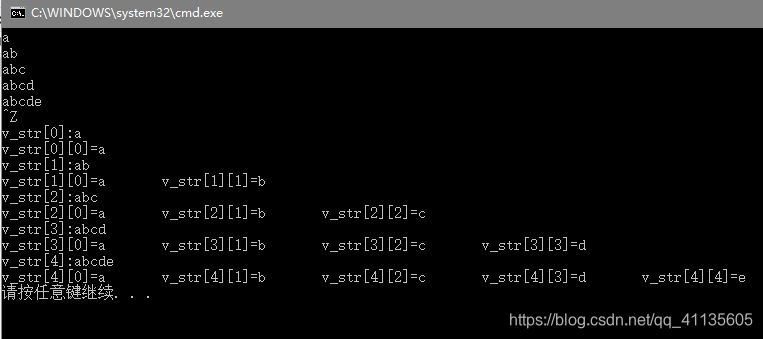


















 270
270




 到【灌水乐园】发言
到【灌水乐园】发言







