









文章目录
1. Tensors, Functions and Computational graph
torch.autograd 可以实现计算图中每一个单元的导数的自动计算,比如下面的计算图中w 和 b的导数计算按:
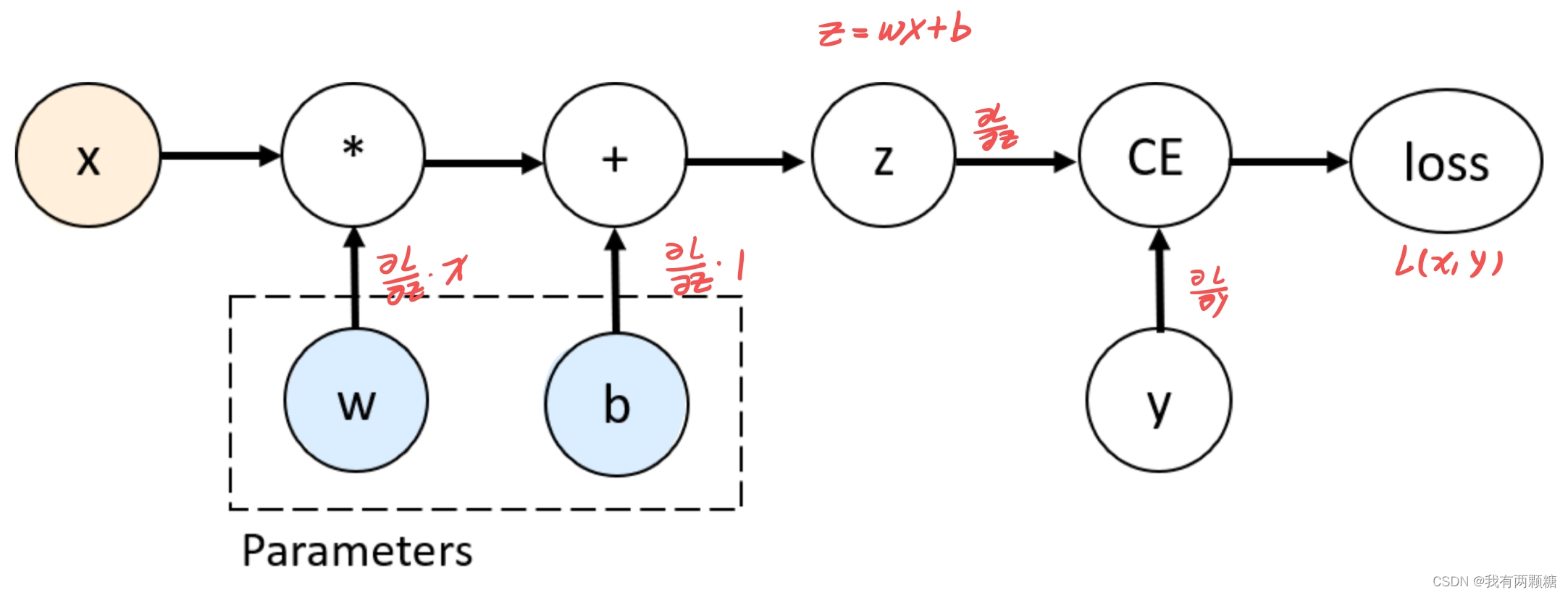
可以这样实现:
import torch
x = torch.ones(5)
y = torch.zeros(3)
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w) + b
# or (z = x.matmul(w) + b)
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
参数 requires_grad=True 指定在进行前向计算时自动差分求导,计算完 Z 和 loss 后,tensor z 和 loss 会自动创建一个属性 grad_fn,它是一个 Function 对象,用于计算前向前向传播和 back propagation 求导。
print(f'Gradient function for z = {z.grad_fn}')
print(f'Gradient function for loss = {loss.grad_fn}')
2. Computing Gradients
通过调用 loss.backward() 可以做一次 BP,可以自动计算
∂
l
o
s
s
∂
w
\frac{\partial{loss}}{\partial{w}}
∂w∂loss 和
∂
l
o
s
s
∂
w
\frac{\partial{loss}}{\partial{w}}
∂w∂loss,通过 w.grad 和 b.grad 获取
loss 对 w 和 b 的微分:
loss.backward()
print(w.grad)
print(b.grad)
# tensor([[0.1814, 0.0460, 0.3266],
# [0.1814, 0.0460, 0.3266],
# [0.1814, 0.0460, 0.3266],
# [0.1814, 0.0460, 0.3266],
# [0.1814, 0.0460, 0.3266]])
# tensor([0.1814, 0.0460, 0.3266])
注意
1 . We can only obtain the grad properties for the leaf nodes of the computational graph, which have requires_grad property set to True. For all other nodes in our graph, gradients will not be available.
2 . We can only perform gradient calculations using backward once on a given graph, for performance reasons. If we need to do several backward calls on the same graph, we need to pass retain_graph=True to the backward call.
3. Disabling Gradient Tracking
所有具有 requires_grad=True 的 tensors 都会记录计算过程并支持梯度计算,但有时我们不希望计算梯度信息,比如当我们指向让模型预测一些样本时,此时可以使用 torch.no_grad() 来停止所有梯度计算:
z = torch.matmul(x, w) + b
print(z.requires_grad) # True
with torch.no_grad():
z = torch.matmul(x, w) + b
print(z.requires_grad) # False
此外,也可以使用 z.detach() :
z = torch.matmul(x, w) + b
print(z.detach().requires_grad) # False
判断模型性能时,需要在 with torch.no_grad() 条件下进行!
其他场景:frozen 网络中的一部分、模型微调、加速前向传播
4. forward & backward
前向传播
1 . 计算前向传播的结果,保存每一个 operation 的 grad_fn
后向传播
1 . 计算每一个 .grad_fn 对应的梯度值
2 . 将梯度值累加到对应 tensor 的 .grad 属性上
3 . 使用链式法则计算叶节点的梯度
REFERENCE:
1 . https://pytorch.org/tutorials/beginner/basics/autogradqs_tutorial.html#disabling-gradient-tracking
更多内容参考:PyTorch 学习笔记















 2664
2664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









