






HashMap是由由数组和链表组合构成的数据结构。
数组里面每个地方都存了Key-Value这样的实例,如下所示:

HashMap本身所有的位置都为null,在put插入的时候会根据key的hash值去计算一个index值,index值即表示在HashMap中存放的位置。
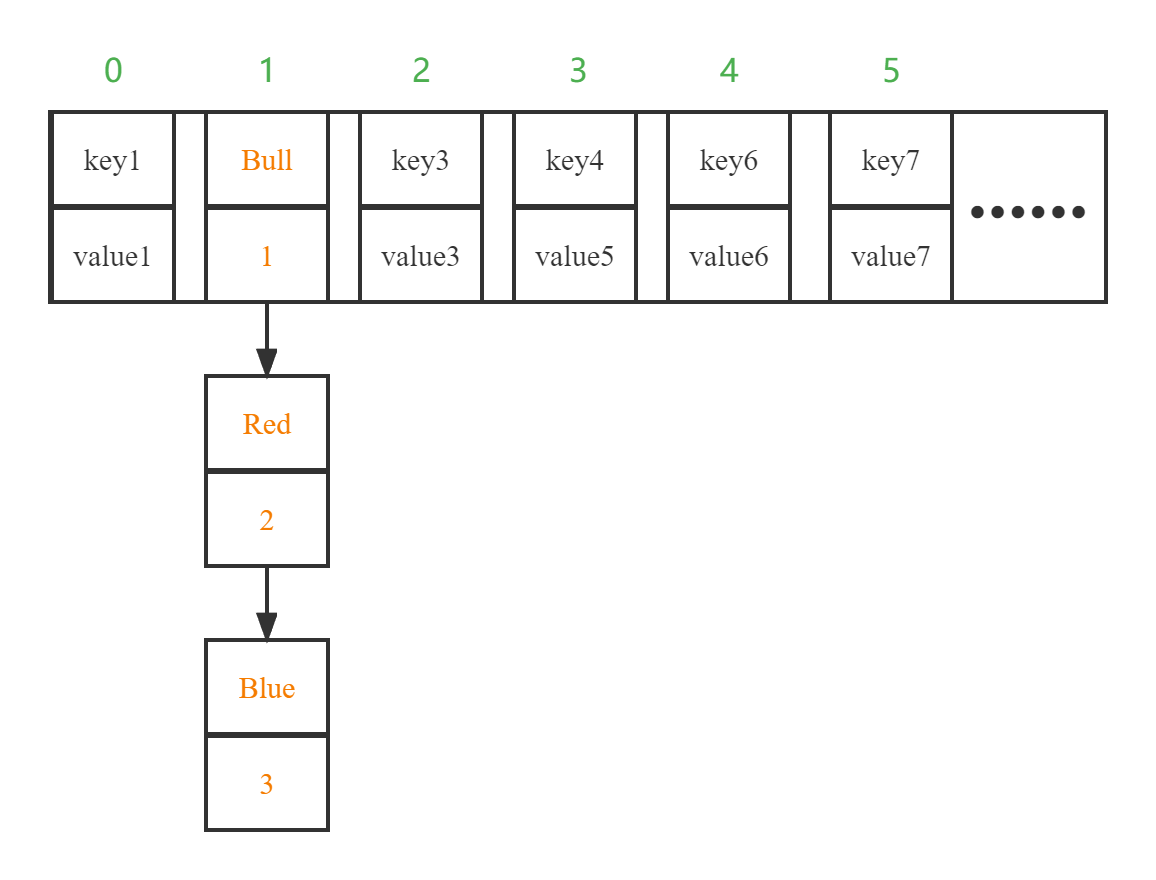
如:将为了将键值对("Bull", 1)存入HashMap中,所计算得到的index值为1:

同时,如果再次将一个键值对("Red", 2)存入当前HashMap中,若计算得到的index值仍为1,则回以如下形式存入HashMap中:

上述情况即为以链表的形式进行存储。
每一个节点都会保存自身的hash、key、value、以及下个节点。源码如下。

同时,需要注意的是,新的Entry节点在插入链表的时候,插入方法在不同的java版本有不同。java8之前是头插法,就是说新来的值会取代原有的值,原有的值就顺推到链表中去,就像上面的例子一样。
但是,在java8之后,都是所用尾部插入了(使用头插法在多线程的情况下会产生循环链表的问题)。
产生死循环的原因如下:
首先,看一下HashMap的扩容机制:
HashMap扩容主要设计两个因素:
- Capacity:HashMap当前长度。
- LoadFactor:负载因子,默认值0.75f。
HashMap在容量达到设定的阈值时(0.75f)就会进行扩容。比如当前的容量大小为100,当你存进第76个的时候,判断发现需要进行resize了,那就需要进行扩容。
扩容具体步骤如下:
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
这里进行ReHash的原因是,当长度扩大以后,Hash的规则也随之改变,即ReHash得到的index值因为数组长度的不同变得不同。
单线程扩容前:
单线程扩容后(index不同):

单线程扩容后(极端情况下所得到的index值相同):

在多线程情况下进行扩容:
现在假设线程T1与T2均指向第一个(“Bull“, 1)键值对,T1.next与T2.next均指向第二个("Red",2)键值对:

现在两个线程两个线程均开始扩容,且此时线程T2的时间片恰好用完,则线程T1进行扩容,结果为:
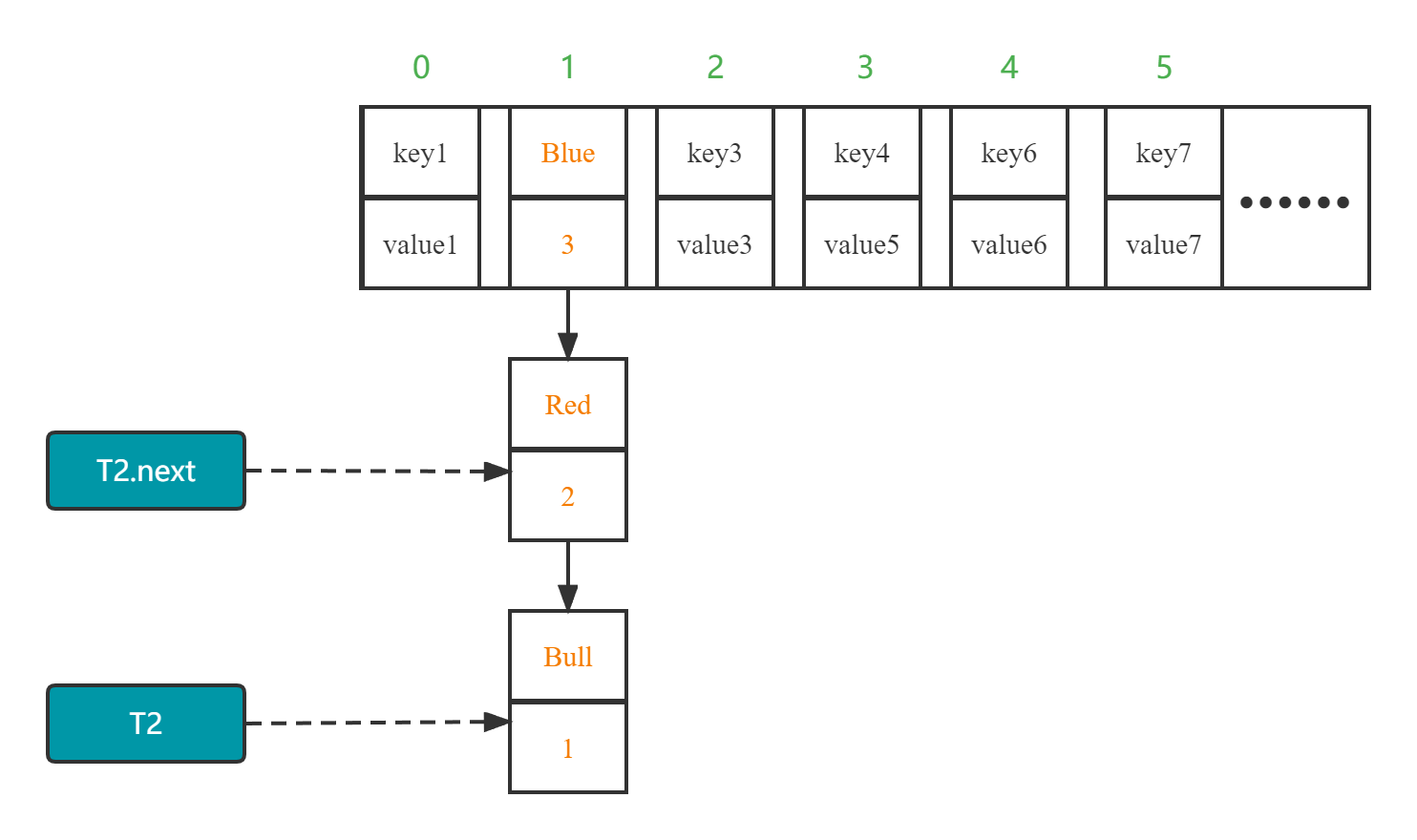
此时,线程T2所指向的键值对均没有改变(对线程T1的ReHash操作不知情),则此时对于线程T2就达成了一个死循环:

如果线程T2此时去取值,则出现无限循环。














 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









