




感谢学习视频来源:https://www.bilibili.com/video/BV1Y7411d7Ys?p=4&vd_source=2314316d319741d0a2bc13b4ca76fae6
反向传播
在深度学习算法中,可以在图上进行梯度传播来帮助我们检录更具有弹性的模型结构。
简单的模型,可以推导解析式去做,但对于复杂的模型每个节点之间有很多权重,如下图:
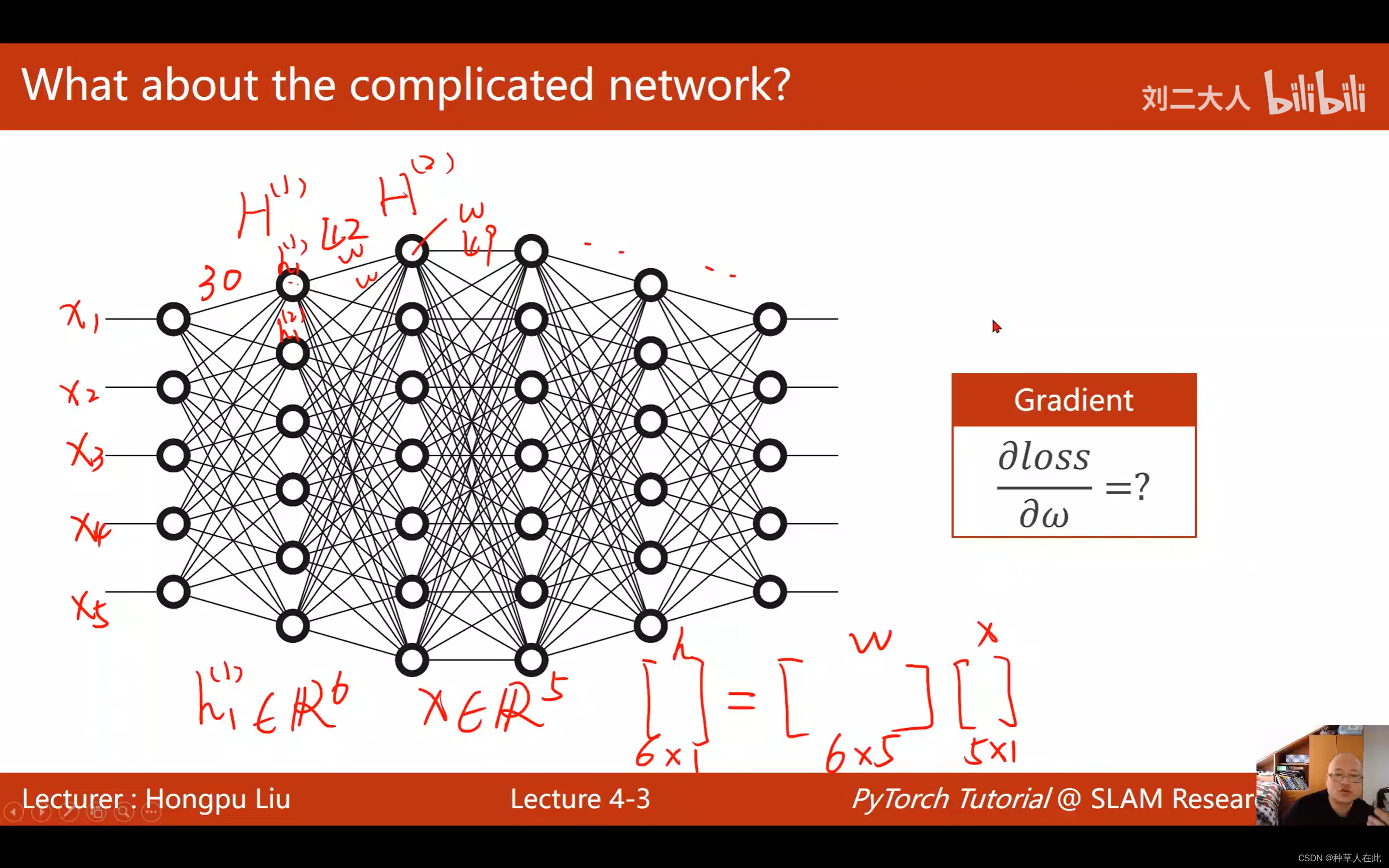
嵌套了非常多的符合函数,解析式是几乎不可能得到的,面对这样的复杂网络,能否有一种算法它能把这网络堪称 一个图,可以在图上来传播梯度,最终根据链式法则,把梯度求出来。这种算法叫反向传播算法。
第一层有6个元素,属于6维向量,x是5维的,根据运算,他们之间的权重有30个。
看一个两层的神经网络,w是weight权重;MM是matric multiplication 矩阵乘法;ADD是加和;b是bias偏置【通常定义为向量形式】。
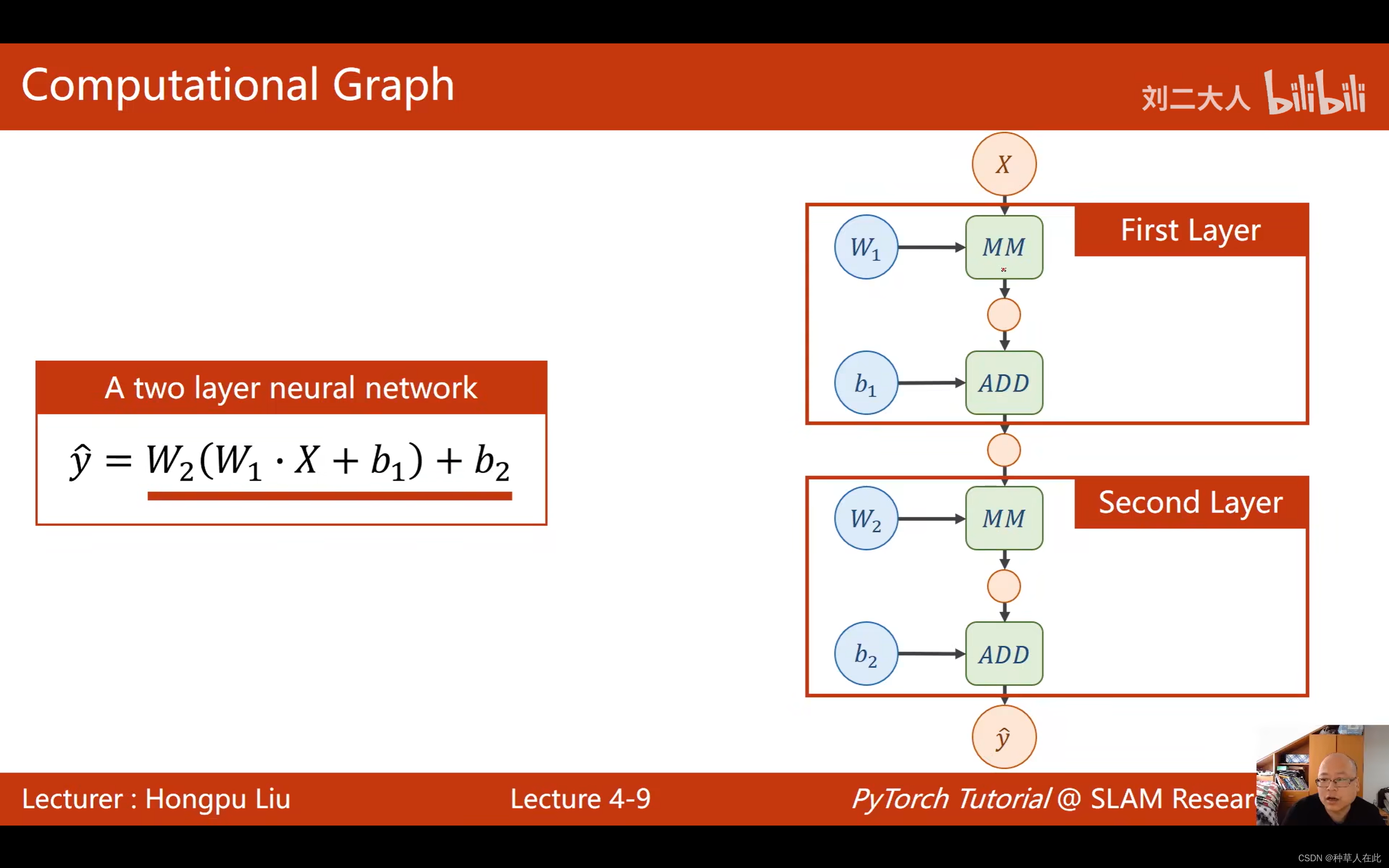
绿色模块是计算模块,不同计算模块,求局部偏导的计算方法不同,通过矩阵求导,局部梯度包含在这些矩阵乘法等模块里。
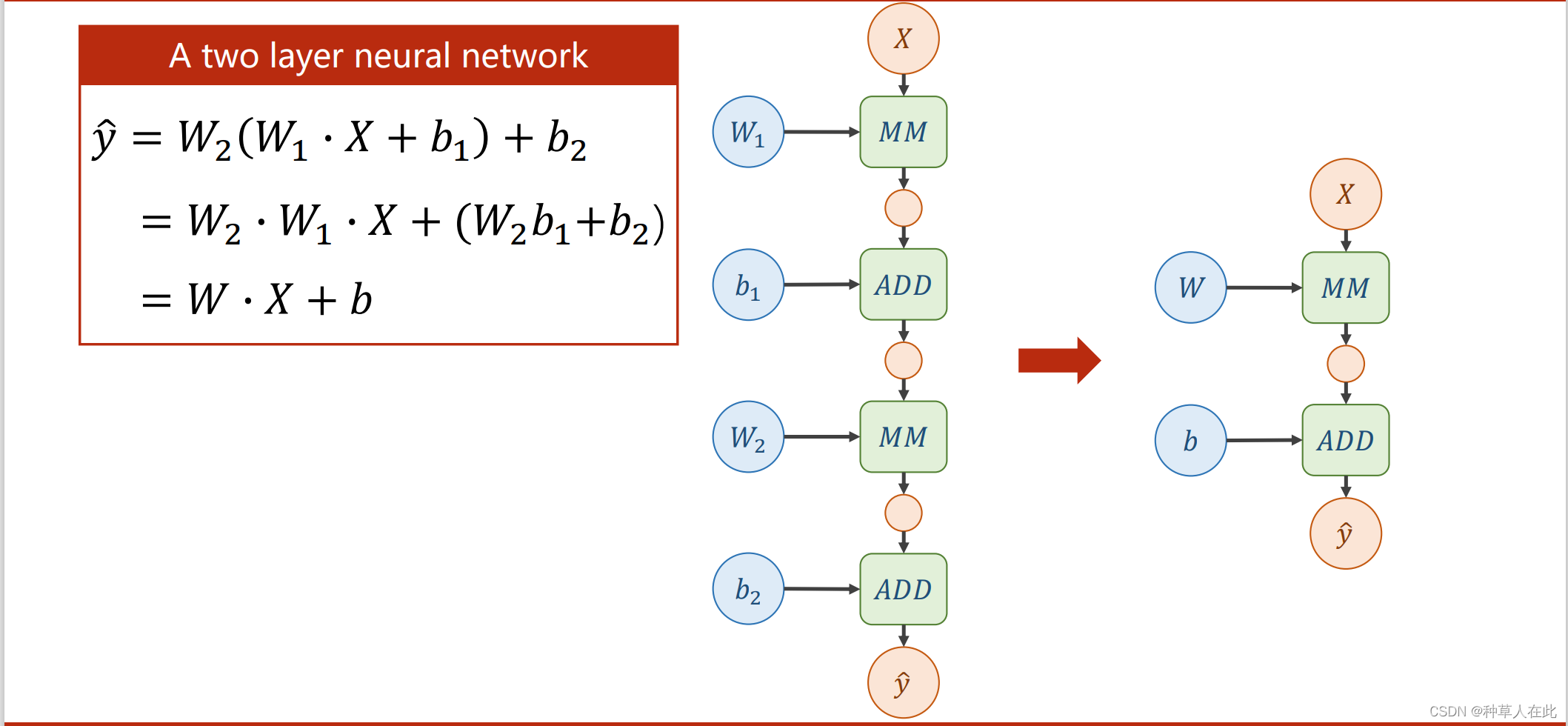
这时出现一个问题,现在给出的神经网络,不断的进行线性的变换,化简,不论你有多少层都会统一成这一种形式。【不能化简,因为化简后增加那些权重就没有任何意义了】
为了解决这个问题,提高模型的复杂程度,要对每一层最后的输出加一个非线性变化函数,对输出的向量的每一个值都应用一个非线性函数比如说:sigmoid,这样通过中间计算结果加一个非线性函数做变换,就没办法做展开了。即无法得到统一的式子了。才能做成一个真正的神经网络。
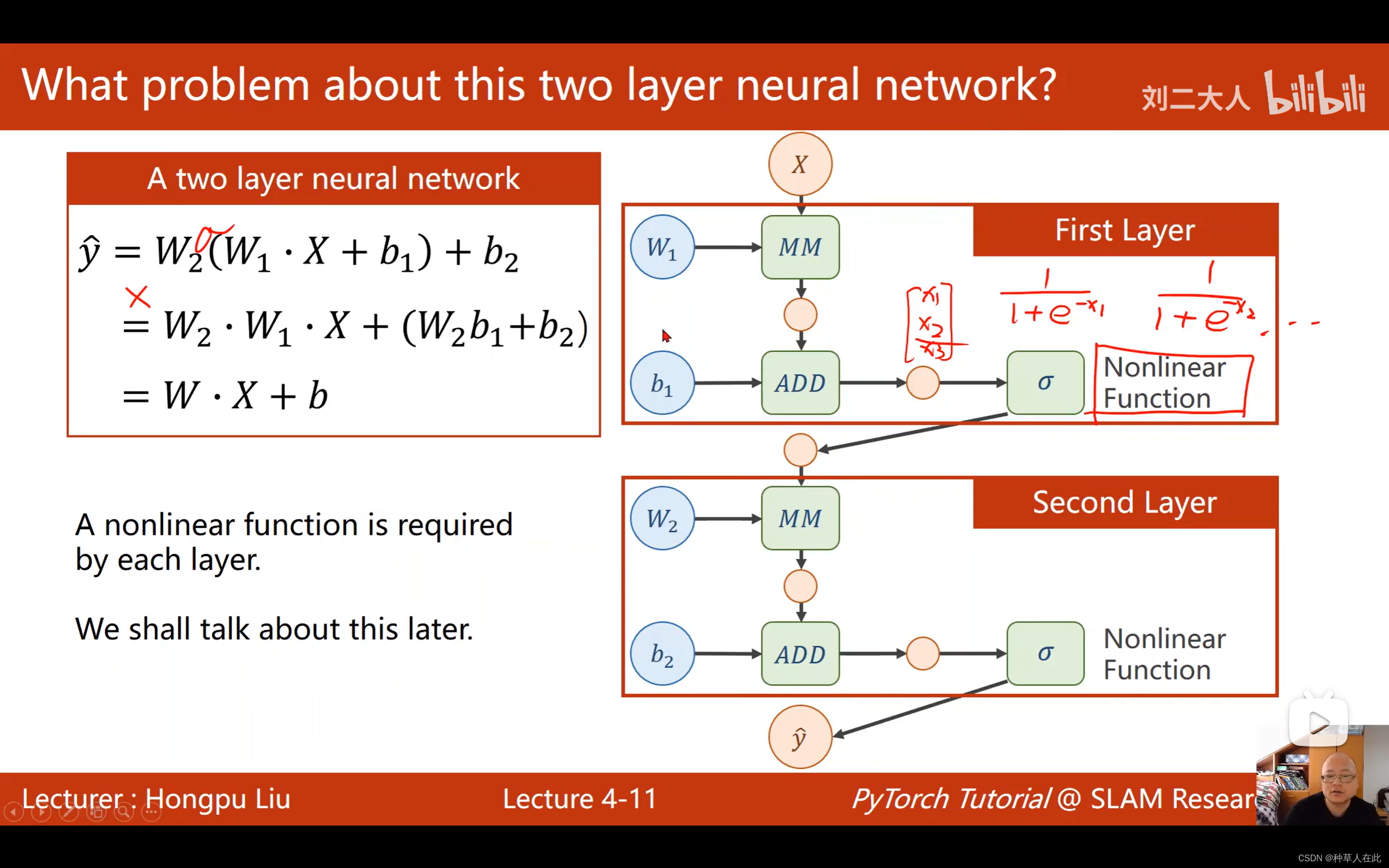

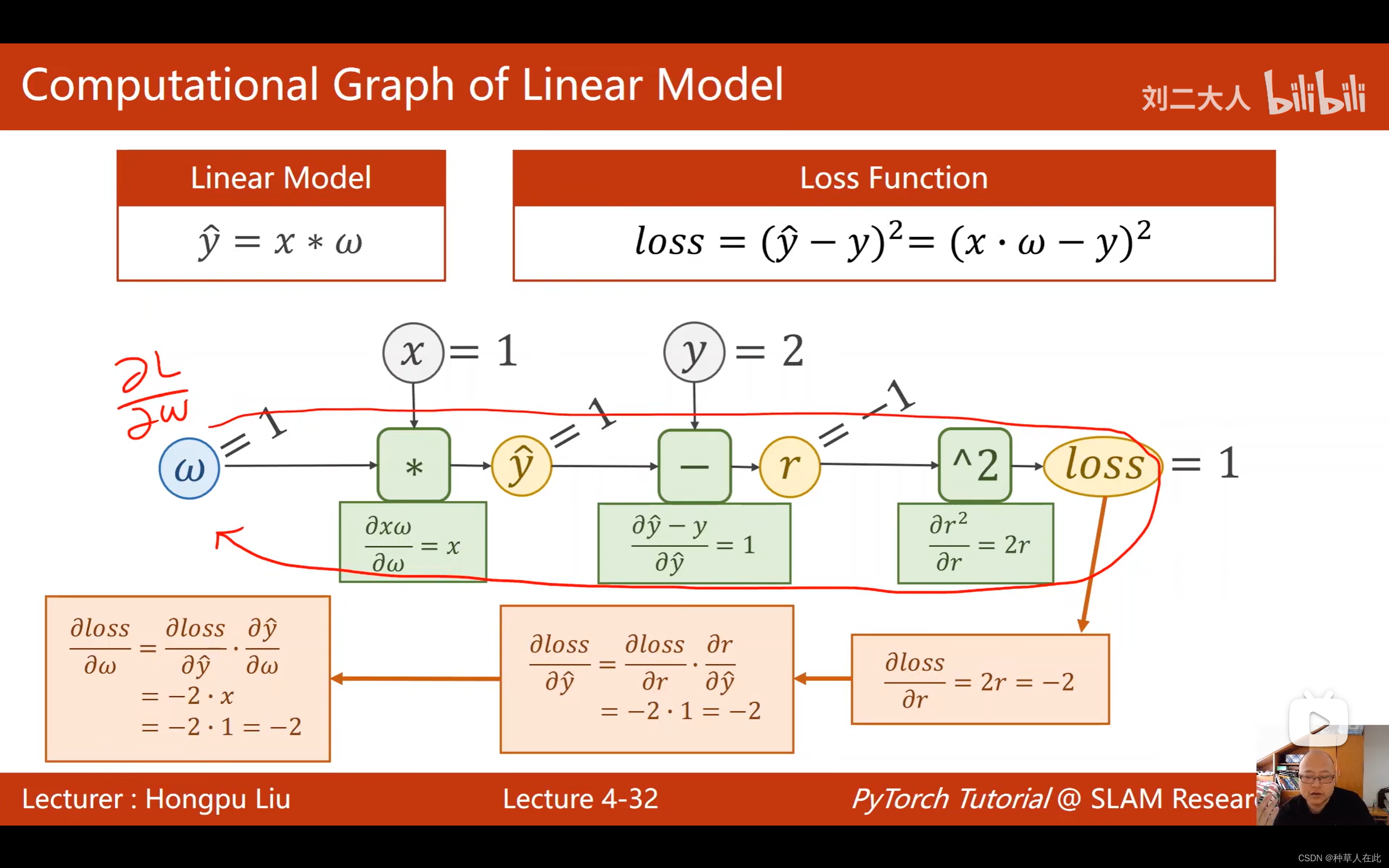
yhat - y 表示残差项,经过前馈、反向传播后,梯度求出来了,一般loss也要保存以下。
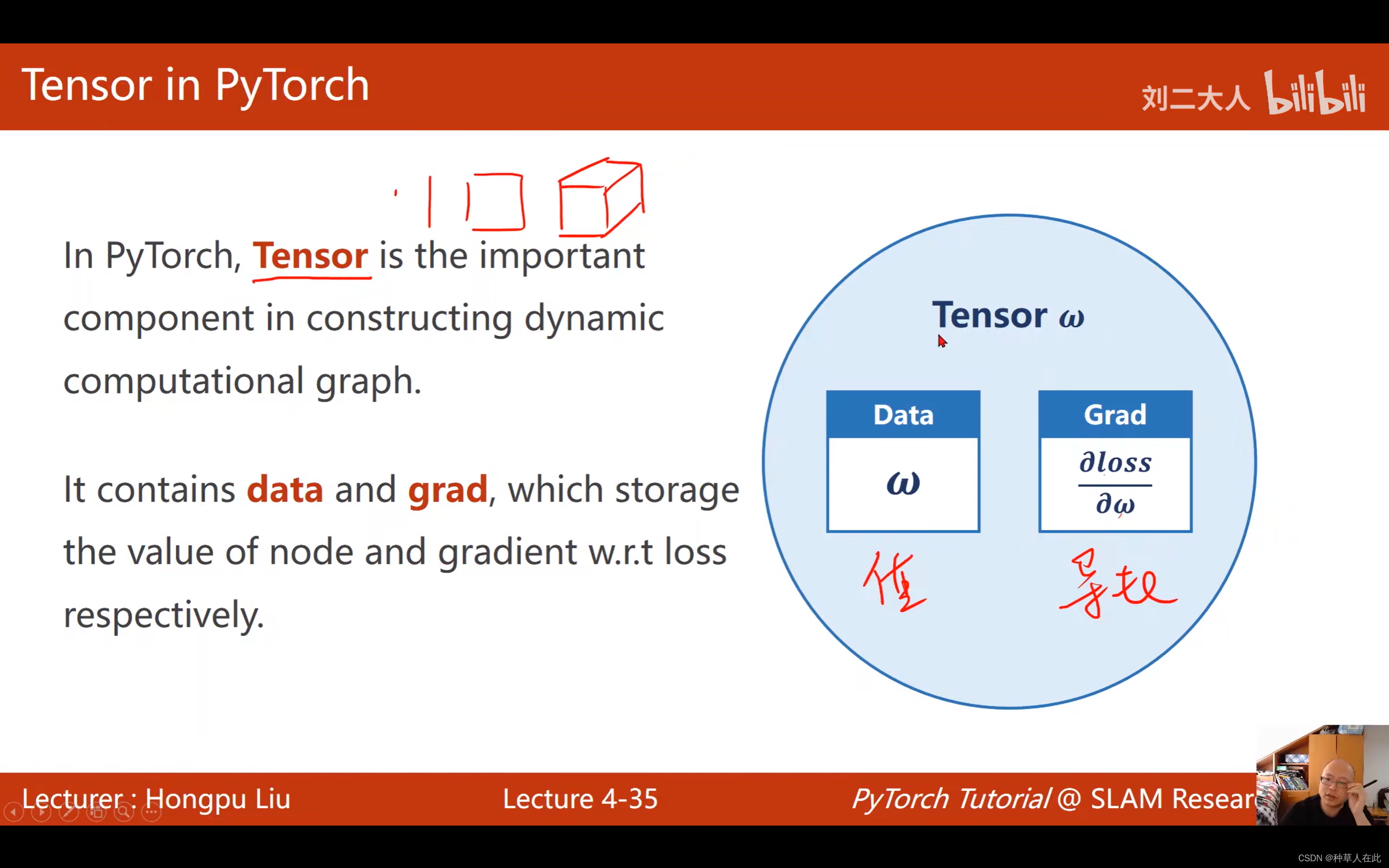
pytorch中 tensor 是存数据的,标量、向量、矩阵、高维tensor都行。tensor 有两个重要成员:data 【保存权重】、 gard 【保存损失函数对权重的导数】
定义了tensor,就可以建立计算图,实际用pytorch写神经网络,构建模型时,就是在构建计算图。
下面看一下,要构建这样计算图需要做哪些工作:
要实现刚才讲的线性模型
import torch
x_data = [1.0, 2.0, 3.0] # 构建数据集
y_data = [2.0, 4.0, 6.0]
w = torch.Tensor([1.0]) #选择权重,创建一个tensor变量 ,注意一定用中括号括起来
w.requires_grad = True #重要一步,需要计算梯度 。默认的tensor,创建之后是不需要计算梯度的。
def forward(x): # 前馈,定义模型:linear
return x * w  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









