







问题描述
区间分割法求解代数方程的并行解法:给定一个函数,然后给定一个区间,使用并行程序设计方法找到该区间内的所有解。
解法描述
- 首先输入区间范围及求解精
- 按照求解精度划分区间
- 程序并行判断每个区间内是否有解
具体实现
在该部分,我使用C++和Python两种语言来实现。C++使用课程讲解的OpenMP(课程理论知识),Python使用multiprocessing库(在实际项目中用到的)。
C++ omp
#include <iostream>
#include <omp.h>
#include <time.h>
using namespace std;
double func(double x) {
return pow((x - 0.11), 2) - 3; //定义函数
}
int main(){
double a, b;
cout << "请输入求解区间(用空格隔开区间两端):";
cin >> a >> b;
double jd;
cout << "请输入区间精度要求(例如0.00001):";
cin >> jd;
//cout << "1/jd="<<1/jd << endl; //划分的小区间个数
clock_t start, end;
start = clock();
#pragma omp parallel for
for (int i = 0; i < int((b-a)*(1/jd)) ; i++) {
if (func(a+i*jd) * func(a+(i+1)*jd) < 0){
cout << "近似解:" << (a*2+(2*i+1)*jd) * 1.0 / 2 << endl;
}
}
end = clock();
cout << "并行持续时间:" << (end - start)*1.0/1000 <<"s" << endl;
start = clock();
for (int i = 0; i < int((b - a) * (1 / jd)); i++) {
if (func(a + i * jd) * func(a + (i + 1) * jd) < 0) {
cout << "近似解:" << (a * 2 + (2 * i + 1) * jd) * 1.0 / 2 << endl;
}
}
end = clock();
cout << "顺序执行持续时间:" << (end - start) * 1.0 / 1000 <<"s" << endl;
return 0;
}
Python multiprocessing.Pool
multiprocessing.Pool是Python的进程池,主要有8个函数:apply、apply_async、map、map_async、imap、imap_unordered、starmap、starmap_async。

我使用apply,apply_async,starmap,starmap_async四个函数进行实验,并进行耗时比较。
import multiprocessing
from timebudget import timebudget
import os
import time
def func(x) :
return pow(x - 0.11, 2) - 3
def find(x, a, jd) :
if func(a + x * jd)* func(a + (x + 1) * jd) < 0:
print("近似解", (2 * a + (2 * x + 1) * jd) / 2)
def main() :
print("请输入求解区间(用空格隔开区间两端):")
a, b = map(float, input().split())
print("请输入区间精度要求(例如0.00001):")
jd = float(input())
print("总划分区间数:", int((b - a) * (1 / jd)))
start = time.time()
pro_pool = multiprocessing.Pool(8)
for i in range(int((b - a) * (1 / jd))) :
pro_pool.apply(find, (i, a, jd))
print("顺序执行~~~~~~~~~~~~~~~~~~~~~~")
pro_pool.close()
pro_pool.join()
print("顺序执行耗时:{:.5f}s\n".format((time.time() - start)))
start = time.time()
pro_pool = multiprocessing.Pool(8)
for i in range(int((b - a) * (1 / jd))) :
pro_pool.apply_async(find, (i, a, jd))
print("异步执行~~~~~~~~~~~~~~~~~~~~~~")
pro_pool.close()
pro_pool.join()
print("异步执行耗时:{:.5f}s\n".format((time.time() - start)))
start = time.time()
pro_pool = multiprocessing.Pool(8)
arg = [(i, a, jd) for i in range(int((b - a) * (1 / jd)))] # 准备好数据
pro_pool.starmap(find, arg)
print("starmap并行执行~~~~~~~~~~~~~~~~~~~~~~")
pro_pool.close()
pro_pool.join()
print("starmap并行执行耗时:{:.5f}s\n".format((time.time() - start)))
start = time.time()
pro_pool = multiprocessing.Pool(8)
arg = [(i, a, jd) for i in range(int((b - a) * (1 / jd)))] # 准备好数据
pro_pool.starmap_async(find, arg)
print("starmap_async 并行执行~~~~~~~~~~~~~~~~~~~~~~")
pro_pool.close()
pro_pool.join()
print("starmap_async 并行执行耗时:{:.5f}s\n".format((time.time() - start)))
if __name__ == '__main__':
print('Number of CPUs in the system: {}'.format(os.cpu_count()))
main()
结果分析
我统计了
(
x
−
0.11
)
2
−
3
=
0
(x-0.11)^2-3=0
(x−0.11)2−3=0在区间[-10,10]上,子区间精度为0.01,0.001,0.0001的近似解及耗时情,如表1所示。
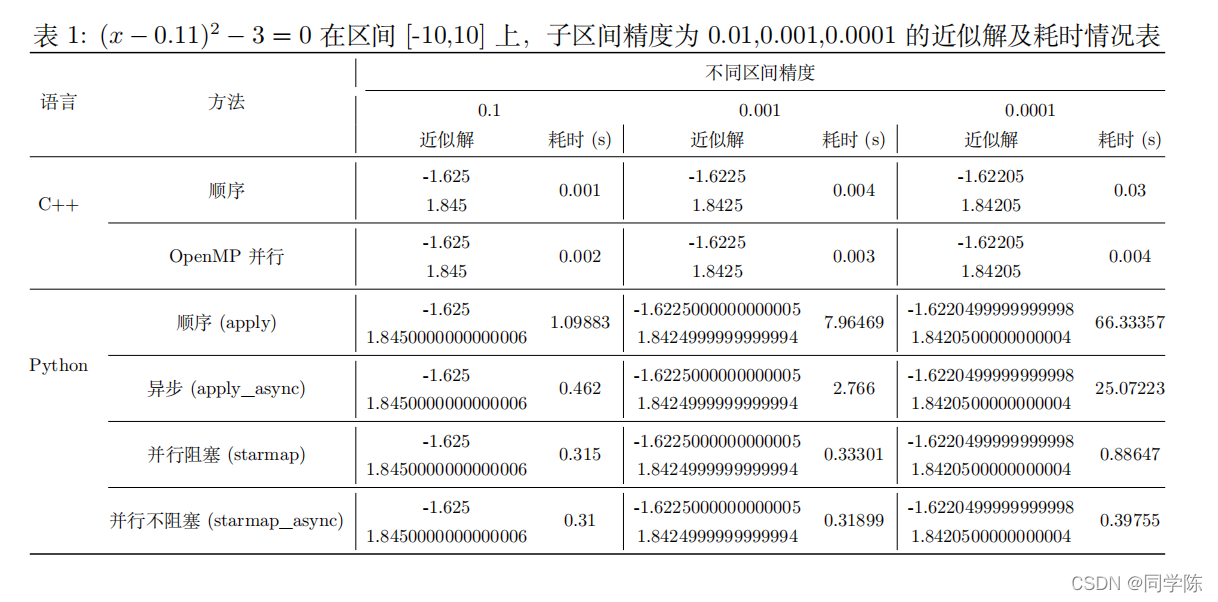
从表中的近似解结果看出, 区间精度越高,我们得到的近似解的精度也越高,距离准确解越近。此外,C++与Python的结果精度不一致,但是近似之后二者是一致的(这是由于高级语言内部原因造成的,我们不予分析)。
从表中的耗时看,C++不论是顺序执行还是并行执行,耗时都是要小于Python的。此外,我们发现,当需要计算的数据量足够大时,并行算法才能显示出其优越性。在Python的四种方法中,顺序执行耗时最多,而异步顺序执行能缓解该问题,但是不如并行执行;而并行方法中,并行且不阻塞的方式要更好一些。四种方法中,按耗时从小到大排序:starmao_async<starmap<apply_asynv<apply。
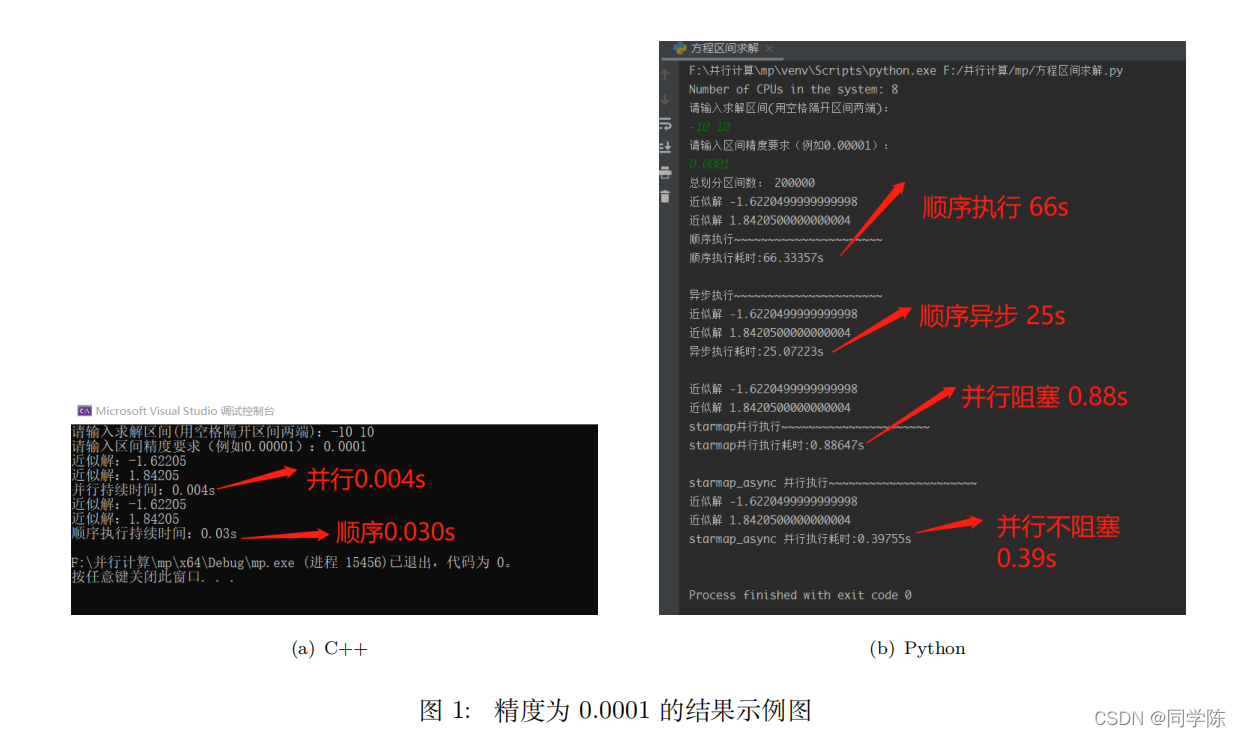
我们给出精度为0.0001的执行示例,见图1。















 1701
1701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











