







 本文介绍了使用Python进行百度新闻爬取的实战过程,包括构造URL,获取网页源代码,编写正则表达式提取新闻标题、链接、日期等信息,并进行了数据清洗与打印输出。
本文介绍了使用Python进行百度新闻爬取的实战过程,包括构造URL,获取网页源代码,编写正则表达式提取新闻标题、链接、日期等信息,并进行了数据清洗与打印输出。
百度新闻信息爬取
序言
通过对百度新闻标题、链接、日期及来源的爬取,了解使用python语言爬取少量数据的基本方法。
获取在百度新闻中搜索“阿里巴巴”的网页源代码
为了获得请求头,我们可以在谷歌浏览器中的地址栏中输入about:version,即可获得headers。
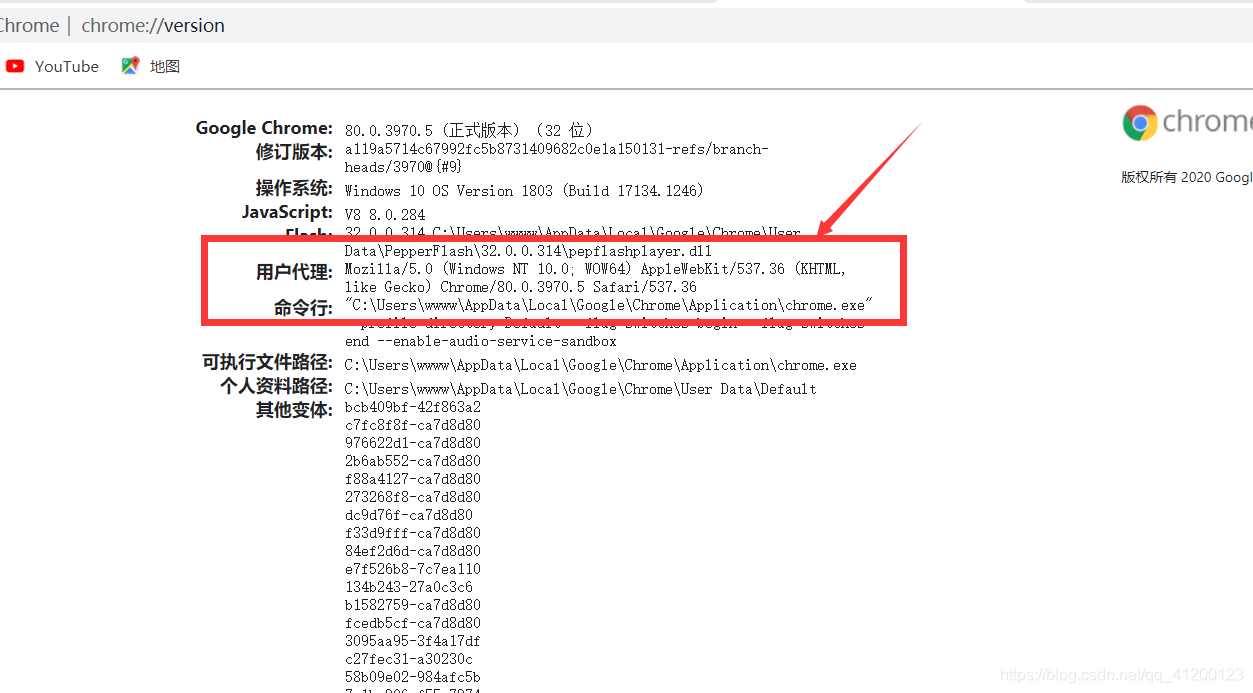
除了要请求头,我们还要构造url。
在网页输入阿里巴巴,然后找到地址栏的url,通过简化url,得到这样一个url---->https://www.baidu.com/s?tn=news&rtt=1&bsst=1&cl=2&wd=阿里巴巴。
有了请求头,我们可以编写基本的爬虫代码了,嘻嘻嘻。
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s?tn=news&rtt=1&bsst=1&cl=2&wd=阿里巴巴'
res = requests.get(url, headers=headers).text
print(res)
得到部分结果如下所示:
// 意见反馈
setTimeout(function(){
var s = document.createElement(“script”);
s.charset=“utf-8”;
s.src=“https://dss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/news/static/protocol/https/global/js/feedback_4acd551.js”;
document.body.appendChild(s);
},0);
编写正则表达式提取新闻信息
有了源代码,下面我们要提取新闻的来源和日期必须要分析一下这个源代码。

发现该新闻的标题、链接、日期,全都在 《p class=“c-author”》下面,这样我就知道怎么提取了。
import requests
import re
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s?tn=news&rtt=1&bsst=1&cl=2&wd=阿里巴巴'
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)</p>'
info = re.findall(p_info, res, re.S)
print(info)
代码结果含有\n、\t、  ;

同理,我们使用同样的方法利用正则表达式获得具体的标题、链接。
import requests
import re
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s?tn=news&rtt=1&bsst=1&cl=2&wd=阿里巴巴'
res = requests.get(url, headers=headers).text
p_href = '<h3 class="c-title">.*?<a href="(.*?)"'
href = re.findall(p_href, res, re.S)
p_title = '<h3 class="c-title">.*?>(.*?)</a>'
title = re.findall(p_title, res, re.S)
print("链接是:", '\n', href)
print< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









