







基本信息
这是24年4月发表在arxiv上的一篇文章
博客创建者
武松
作者
Junjielong Xu, Ying Fu, Shin Hwei Tan, Pinjia He
From:The Chinese University of Hong Kong, Shenzhen (CUHK-Shenzhen)
标签
大语言模型、程序自动修复、软件错误定位
1. 摘要
大型语言模型( large language models,LLMs )在自动程序修复( automatic program repair,APR )方面取得了不错的效果。然而,Decoder-only的LLMs (如 GPT-4 )的next token prediction训练目标与当前填充式方法(infilling-style)的掩码连续词预测(masked span prediction)目标不一致,这阻碍了LLMs充分利用预训练知识进行程序修复。此外,当使用相关artifacts(例如,测试用例)作为输入时,虽然一些LLMs能够端到端的定位和修复缺陷,但现有的方法将其视为单独的任务,需要先进行错误定位再用LLMs在定位位置生成补丁。这种限制阻碍了LLM的灵活性。
在本文中,本文研究了一种新的方法来使LLM适应APR。本文的核心见解是,LLM的APR能力可以通过简单地将输出与它们的训练目标对齐,并允许它们在不首先执行错误定位的情况下对整个程序进行优化(refinement)来大大提高性能。基于这一认识,本文设计了D4C,用于直接使用LLM进行APR。D4C可以正确修复Defects4J中的180个缺陷,每个补丁只需采样10次。该方法优于SOTA APR方法10%的完美错误定位,并减少了90%的补丁采样数量。文章主要贡献在于:
- 认为基于任务进行目标对齐对于充分挖掘LLM的预训练能力至关重要,于是将程序修复问题重定义为程序增强问题;
- 验证了直接优化整个代码比先定位后修复的方法效果更好;
- 提出D4C程序修复框架,将LLM直接用于APR,且效果比现有流程更好。
2. 方法
2.1 方法架构图
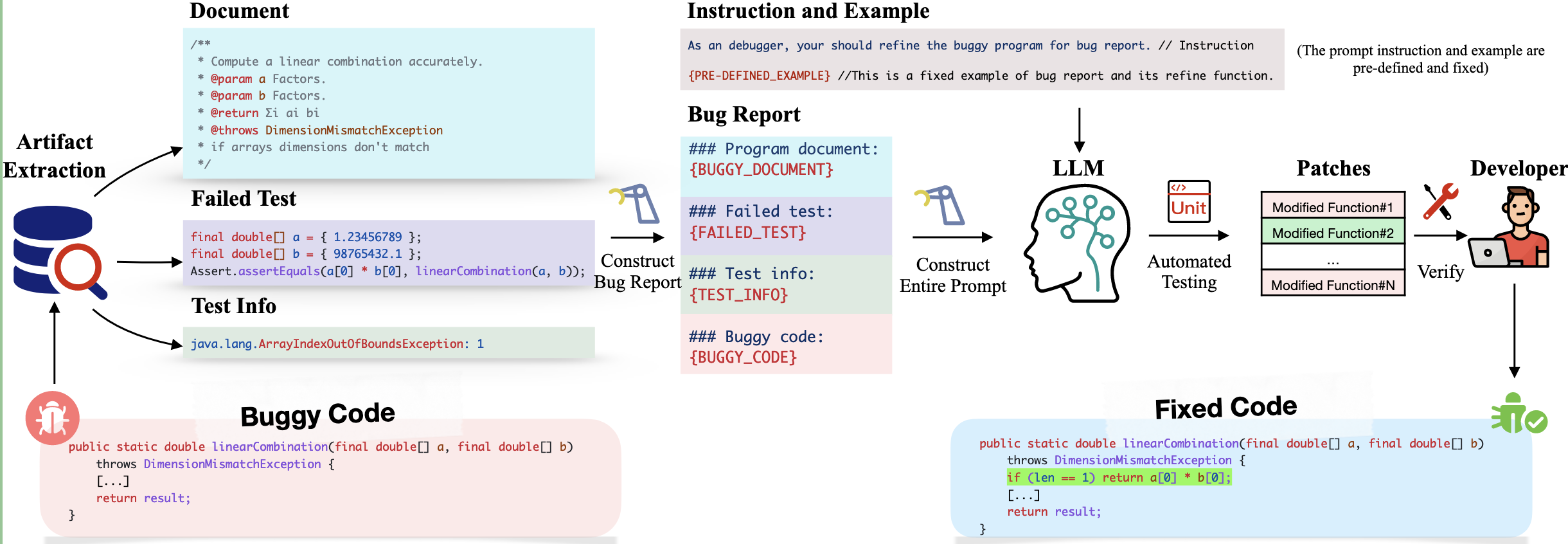
方法架构图
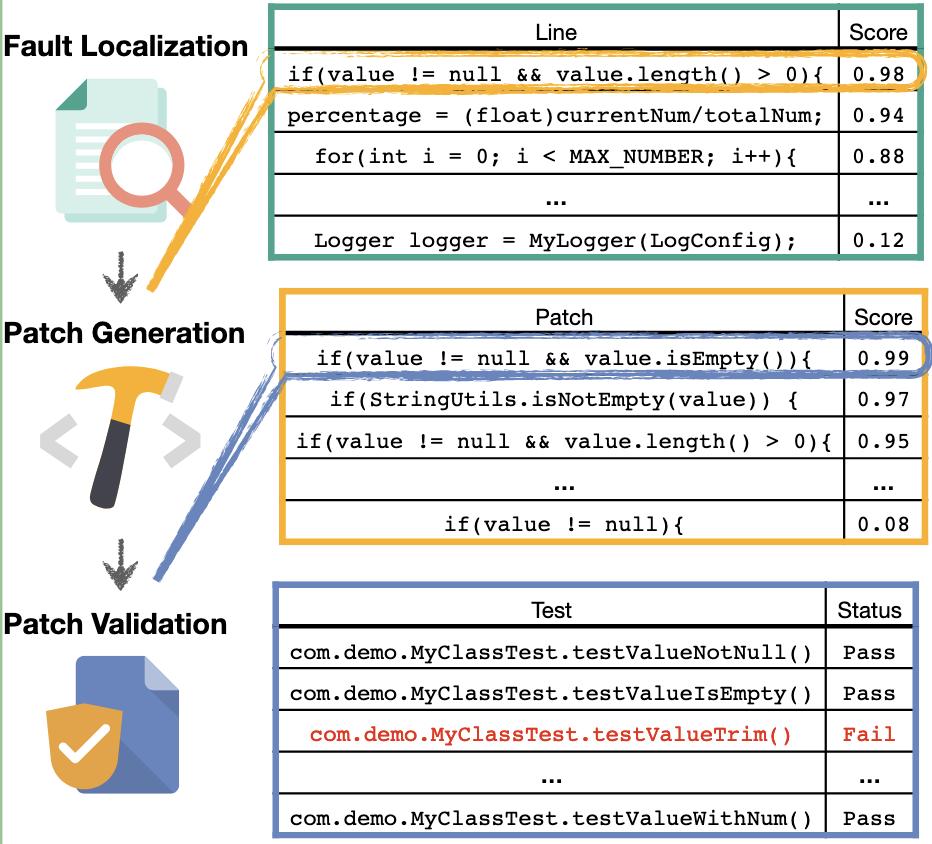
传统流程
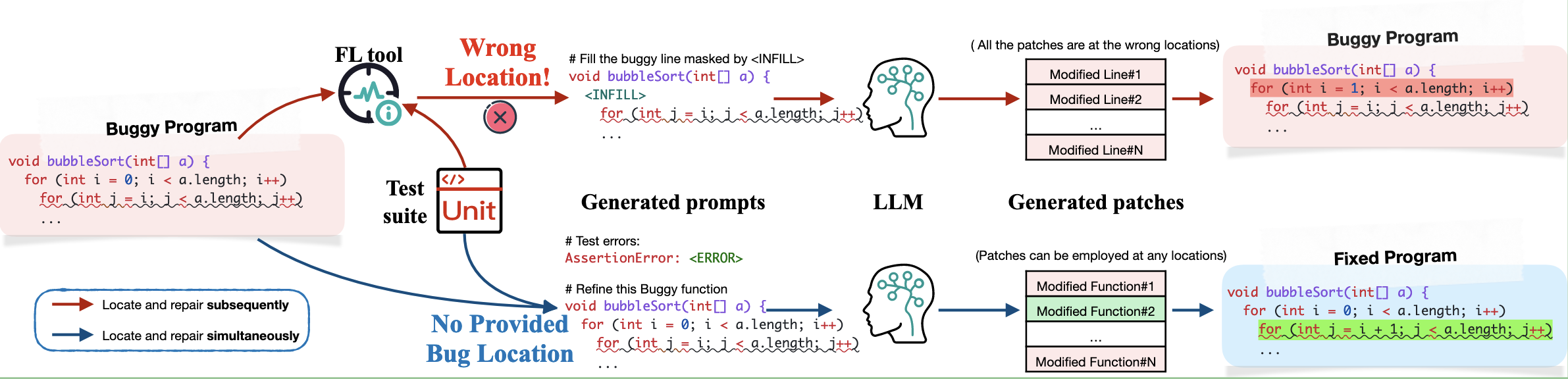
与传统流程对比
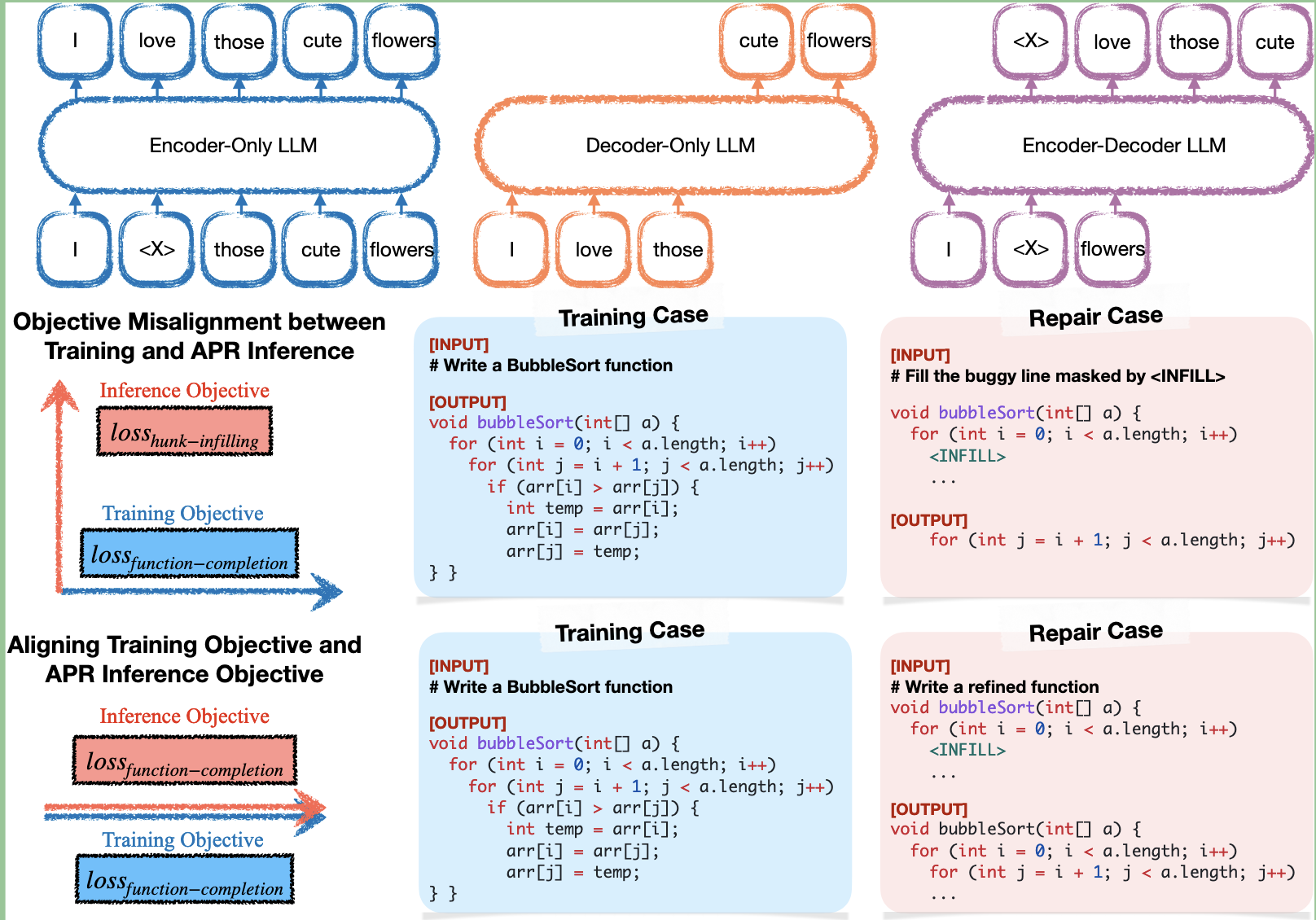
预训练目标
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









