






AGENTLESS : Demystifying LLM-based Software Engineering Agents
基本信息
2024年,arXiv
博客贡献人
柴进
作者
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, Lingming Zhang
标签
大语言模型,软件工程,代理
摘要
大型语言模型(LLM)的发展极大地推进了软件开发任务的自动化,包括代码合成、程序修复和测试生成。涌现了众多通过使用工具,运行命令,观察来自环境的反馈,计划未来行动的LLM代理,用于执行端到端软件开发任务。
然而,作者认为基于代理的方法具有复杂性,且当前的LLM能力有限,提出以下问题:
1)是否有必要使用复杂的自主软件代理
2)SWE-bench Lite中除了准确的ground truth补丁,还有一部分具有不充分/误导性的问题描述
基于上述问题,作者针对性地提出:
1)构建AGENTLESS——一种自动解决软件开发问题的无代理方法。
与基于代理的方法的冗长和复杂的设置相比,无代理采用了简单定位、修复和补丁验证的三阶段过程,并且不让LLM决定未来的行动或使用复杂的工具进行操作。
作者在SWE-bench Lite基准测试上的结果显示,与所有现有的开源软件代理相比,简单的无代理能够实现最高的性能(32.00%,96个正确的修复)和低成本(0.70美元)
2)作者手动对SWE-bench Lite中的问题进行了分类,并排除具有问题的问题,构建了SWE-bench Lite-S,以执行更严格的评估和比较。
问题定义
作者认为软件工程任务不仅需要深入理解包含数千行代码的文件中的信息,还需要深入理解跨文件的存储库级依赖关系。然而,现有研究中将LLMs应用于存储库级软件工程任务的研究还很少。
基于代理的方法
基于代理的方法没有固定的定义,但它们通常为LLM配备一组工具,并允许代理迭代和自主地执行操作、观察反馈并计划未来的步骤。例如,打开/写入/创建文件、搜索代码行、运行测试和执行shell命令的能力。
在每次解决问题的尝试中,基于代理的方法将有多个回合,其中每个回合包括执行一个动作。并且,之后的turns取决于先前的动作和代理从环境接收的反馈信息。
另一方面,人类和当前LLM能力之间的差异导致了基于代理的方法的以下局限性:
-
复杂工具的使用/设计
当前基于代理的方法在代理和环境之间应用抽象层(例如,调用API)。然而,这种抽象和API调用规范需要仔细设计输入/输出格式,并且容易导致不正确或不精确的工具设计/使用,进而降低性能,又会在浪费的LLM查询中招致额外的成本。
-
决策规划时缺乏控制
当前基于代理的方法将决策过程委托给代理,允许他们决定何时执行什么动作。由于可能的行动空间和反馈响应很大,自主代理很容易变得困惑并执行次优探索。此外,为了解决一个问题,代理可以进行30或40次以上的转弯,这使得理解代理做出的决策变得困难,也使得调试做出不正确决策的确切转弯变得困难。
-
自我反省能力有限
现有的代理方法倾向于获取所有信息/反馈,并且不知道如何过滤或纠正不相关、不正确或误导性的信息。
因此,本文作者的贡献如下:
1. 提出了一种更简单、经济高效的AGENTLESS:
-
定位阶段
AGENTLESS采用分层过程,首先将故障本地化到特定的文件,然后是相关的类或函数,最后是细粒度的编辑位置。定位过程融合了基于LLM的定位思想,和经典的基于信息检索的定位思想。
-
修复阶段
AGENTLESS基于定位出的编辑位置,以简单的diff格式生成多个候选补丁。
-
补丁验证阶段
AGENTLESS生成可以再现原始错误并帮助选择候选补丁的测试,对所有剩余的修补程序进行重新排序,并选择一个要提交的修补程序来解决问题。
2. 在SWE-bench Lite上广泛评估AGENTLESS
实验结果显示,AGENTLESS实现了比所有开源方法更高的性能(32.00%,96个正确修复),并且成本相对较低。作者进一步进行了严格的消融研究,以了解AGENTLESS不同组件对最终性能的有效性。
3. 构建了新的SWE-bench Lite-S基准
方法
方法架构
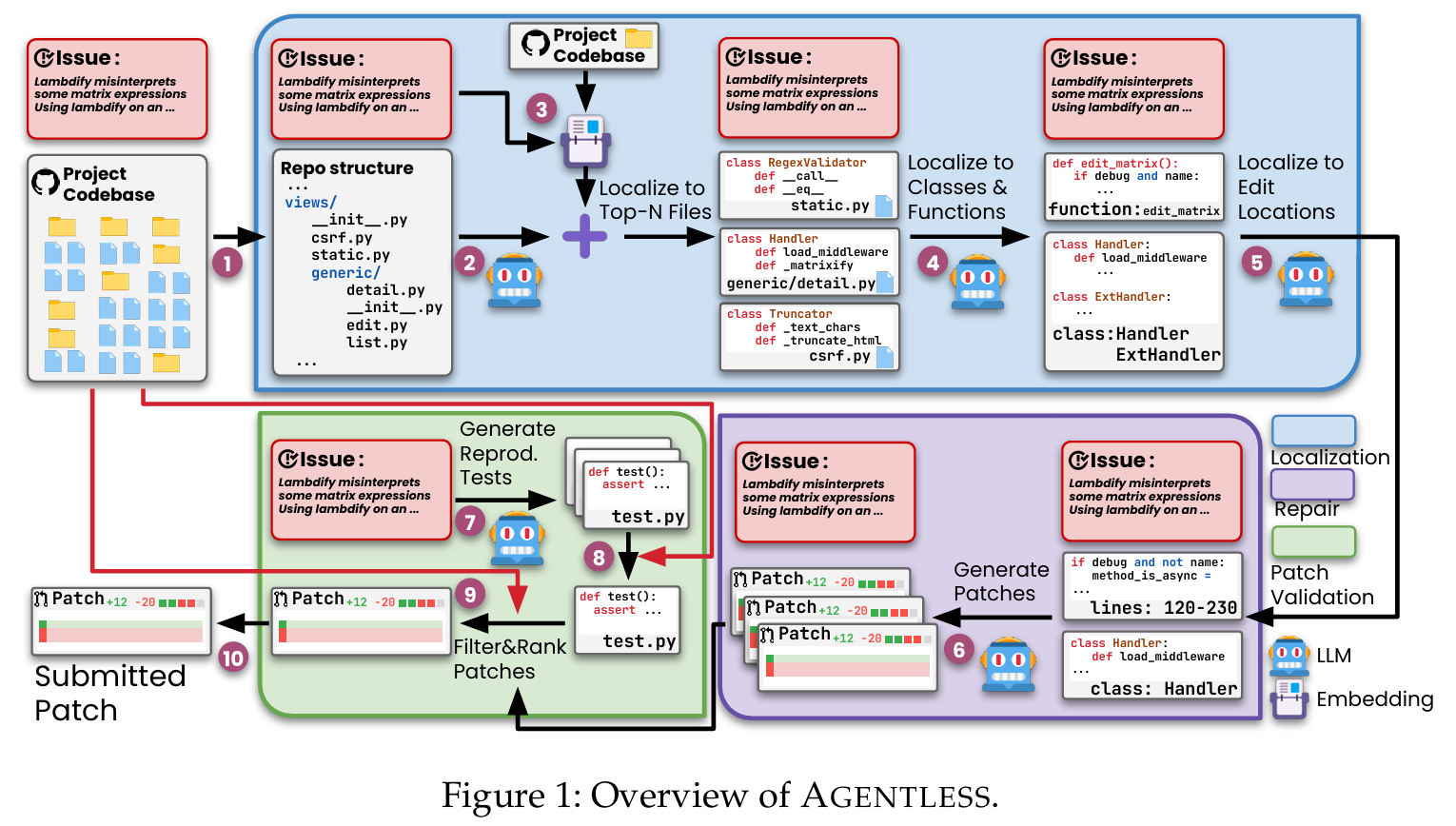
图1显示了AGENTLESS的架构图,包括三个阶段:定位、修复和补丁验证。
定位阶段:
① 将问题描述和现有的项目代码库作为输入,并且为了实现分层定位过程,将代码库投影到一个树状结构,该结构可以说明项目中每个文件的相对位置;
② 根据这个存储库结构以及原始问题描述,提示LLM定位并排列可能需要编辑以解决问题的前N个最可疑的文件;
③ 使用嵌入来检索包含问题描述最相关代码片段的文件;
④ 将检索到的文件与LLM定位出的文件组合起来,以获得可疑文件的最终列表;具体地,为每个文件提供了一个框架(即类和函数的声明头列表),并要求LLM输出一个特定的类和函数列表,可以更细粒度地检查这些列表;
⑤ 提供前面位置的完整代码内容,并要求LLM最终确定一组较小的编辑位置(即类、函数甚至特定行);
修复阶段:
⑥ 提供编辑位置的代码片段以及问题描述,并提示LLM对多个补丁进行采样以解决问题;
补丁验证阶段:
⑦ 要求LLM对旨在复现原始问题的多个再现测试进行采样;
⑧ 根据在原代码库上的实际执行结果选择最优的测试;
⑨ 使用再现测试以及现有的回归测试来进行补丁排序/选择;
⑩ 选择排名靠前的修补程序作为提交的最终修补程序;
定位
AGENTLESS使用简单的三步分层定位过程来解决定位难得问题:1)定位到可疑文件;2)将每个选定的文件定位到相关的类、函数和变量中;3)定位到代码编辑位置。
定位到可疑文件
首先构造树形的存储库文件和目录结构表示(repository structure format, 存储库结构格式),它从存储库的根文件夹开始,组织代码文件或文件夹名。同一目录级别的文件和文件夹垂直对齐,子目录中的文件/文件夹缩进。通过递归遍历获得整个存储库的结构,该结构将与原始问题描述一起用作LLM的输入。利用提示指令,请求LLM识别出需要进一步检查或修改以解决问题的前N个可疑文件的列表。
另外,AGENTLESS还使用简单的基于嵌入的检索方法来识别其他可疑文件。利用LLM确定出不相关的文件夹列表,并删掉所有不相关文件后,AGENTLESS将每个剩余文件分成代码段块,并使用嵌入模型计算每个块的嵌入。然后,AGENTLESS嵌入原始问题描述(即查询),并计算问题嵌入和每个块嵌入之间的余弦相似性,以检索包含与查询具有最高相似性的代码段的相关文件列表。最后,选择都位于两者top N的文件作为最终的可疑文件列表。
定位到相关元素
AGENTLESS为包含类、函数或变量声明列表的每个文件构建压缩格式(skeleton format, 骨架格式)。该格式中,只提供文件中类和函数的头,类中还包括所有的类字段和方法(仅签名),而且还在类和模块级别保留注释,以提供进一步的信息。

给到LLM的单个提示中包含了所有可疑文件的骨架,使模型能够全面分析相关信息并决定最相关的元素,并提供一个相关类和函数的列表,应该检查这些类和函数来修复所提供的问题。
定位到编辑位置
前面的定位步骤提供了相关代码元素的列表,而这些定位出的相关代码元素可能来自不同的文件。
因此,通过将这些元素的代码内容提供给LLM,并要求它定位出特定的编辑位置。
修复
利用识别的编辑位置并构建代码片段的上下文窗口,以提供给LLM进行修复。这里的窗口指,在定位出的编辑位置前、后再多选取几行代码,可以为LLM提供相关的上下文信息,以便更好地修复程序。如果识别出多个编辑位置,会用“…”将这些上下文窗口连接在一起,表示中间缺少上下文。
基于这些代码片段,可以要求LLM生成补丁来解决问题。
与以往方法不同,AGENTLESS不是直接生成整个代码片段来替换整个给定的上下文,而是要求LLM生成一个搜索/替换编辑:一个简单的diff格式来有效地创建每个补丁
例如,图3显示了包含两个主要部分的搜索/替换格式示例:
1)搜索:想要替换的原始代码片段
2)替换:想要替换的替换代码片段
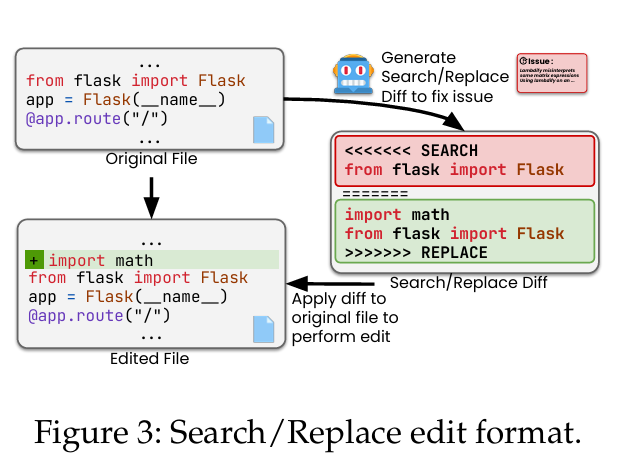
然后应用生成的搜索/替换diff到源文件中,简单地匹配搜索代码片段,并用replacement替换它。对于每个问题,AGENTLESS会使用LLM生成多个潜在补丁。
补丁验证
再现测试生成
现有的SWE-bench设置下,原始项目代码库只能提供回归测试,而不能提供任何再现测试(即bug触发测试)。AGENTLESS生成额外的复现测试,以帮助选择补丁。
具体地,AGENTLESS利用LLM来合成一个完整的测试文件,该文件试图重现问题描述中描述的原始问题,并验证问题是否已被修复。图4显示了一个模型合成的再现测试的示例。

如果问题重现,测试结果应打印Issue reproduced;如果问题已经修复,测试应该输出Issue resolved;如果测试遇到任何意外问题,应该输出Other issues。
生成再现测试时,AGENTLESS在原始问题描述中提供了一个示例再现测试来演示测试格式。与修复类似,对多个候选再现测试进行采样,然后在原始存储库上执行每个测试,以过滤任何不输出问题再现的测试。最后,再对每个测试进行规范化(删除注释、额外空格和规范化测试名称),然后选择出现次数最多的测试作为每个问题的最终再现测试。
补丁选择
-
回归测试确定
AGENTLESS首先运行存储库中的所有现有测试,以标识一组在原始代码库中成功通过的通过测试。然而,并非所有通过测试的测试都能被视为回归测试,因为解决问题可能需要更改一些现有功能,因此这部分测试需要被移除。
-
运行回归测试
基于上一阶段生成的多个候选修复,需要对所有生成的补丁运行回归测试集。然后,AGENTLESS会保留回归失败次数最少的修补程序。
-
运行再现测试
对于上一步过滤后的修补程序,AGENTLESS将运行选定的再现测试,并仅保留输出Issue resolved的修补程序。同时,因为再现测试由LLM生成,并且可能是不正确/不精确的,所以可能没有补丁可以通过再现测试,这种情况,AGENTLESS将仅依靠使用回归测试结果进行选择。
-
多数投票的重新排序方法
对每个补丁进行规范化,以忽略表面级别的差异(例如,额外的空格、换行符和注释),然后选择出现次数最多的补丁作为提交的最终补丁。
实验
实验设置
数据集
SWE-bench、SWE-bench Lite版本,包含300个质量更好的自包含问题
此外,作者还对SWE-bench Lite进行了人工分析
问题分类
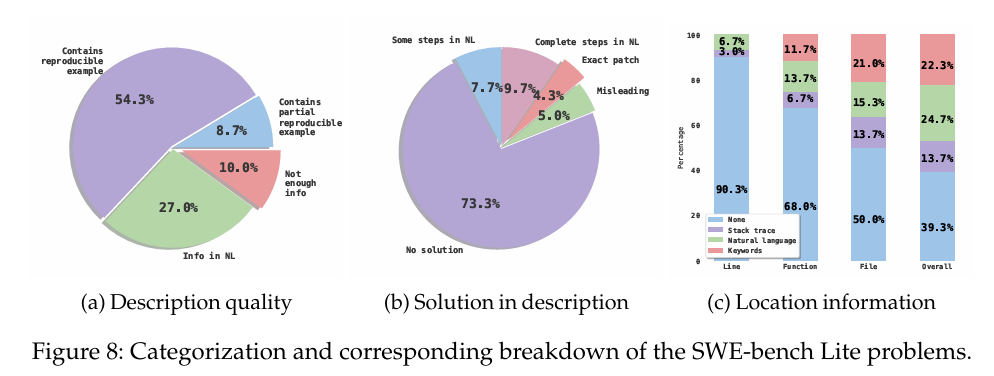
作者对SWE-bench Lite中现有的问题进行手动分类,以更好地理解AGENTLESS和先验方法可以解决哪些类型的问题。分类维度及其类别如下:
-
描述的质量
作者首先检查每个问题描述是否包含足够的信息来执行所需的任务,根据信息完整性可以分为:(i)包含足够的自然语言信息,(ii)包含可再现的故障示例,(iii)包含部分可再现的示例,(iv)不包含足够的信息
-
描述中的解决方案
作者还检查问题描述中是否已经提供了解决问题的解决方案或步骤,具体可细分为:(i)没有提供解决方案或步骤,(ii)提供了部分解决方案(例如,一些自然语言的步骤),(iii)提供了完整的解决方案(例如,完整的自然语言步骤),(iv)提供准确的补丁,(v)误导性的解决方案或步骤
-
位置信息
作者进一步检查问题描述是否包含正确的位置信息。具体类别是:(i)自然语言中的确切位置,(ii)故障堆栈跟踪中提供的确切位置,(iii)问题描述中可用于搜索位置的相关关键字,(iv)未提供。
构建SWE-bench Lite-S
基于上述的问题分类,作者删除了问题描述中包含确切补丁、误导性解决方案或在原始问题描述中没有提供足够信息的问题后,重点关注SWE-bench Lite中问题的子集(共计249个问题)。
实现工具
AGENTLESS:GPT-4o (gpt-4o-2024-05-13)
基于嵌入的检索方法:LlamaIndex
代码块的嵌入:text-embedding-3-small
规范化补丁:AST
一个问题,定位三个可疑文件,定位不受限制数量的可疑类和函数,定位出四个编辑位置,对每个编辑位置采用10行的上下文窗口,生成10个补丁。即一个bug对应了40个补丁
Baseline
与基于代理的方法,和无代理的方法共26种baseline对比
评价指标
作者在三个粒度上计算以下评价指标:文件、函数和行。
1)%Resolved:基准中已解决问题的百分比
2)Avg.$Cost:运行工具的平均推理成本
3)Avg.#Tokens:用于查询LLM的输入和输出token的平均数
4)%Correct Location:工具生成的修补程序覆盖ground truth developer修补程序的编辑位置的问题百分比
实验结果
SWE-bench Lite上的性能
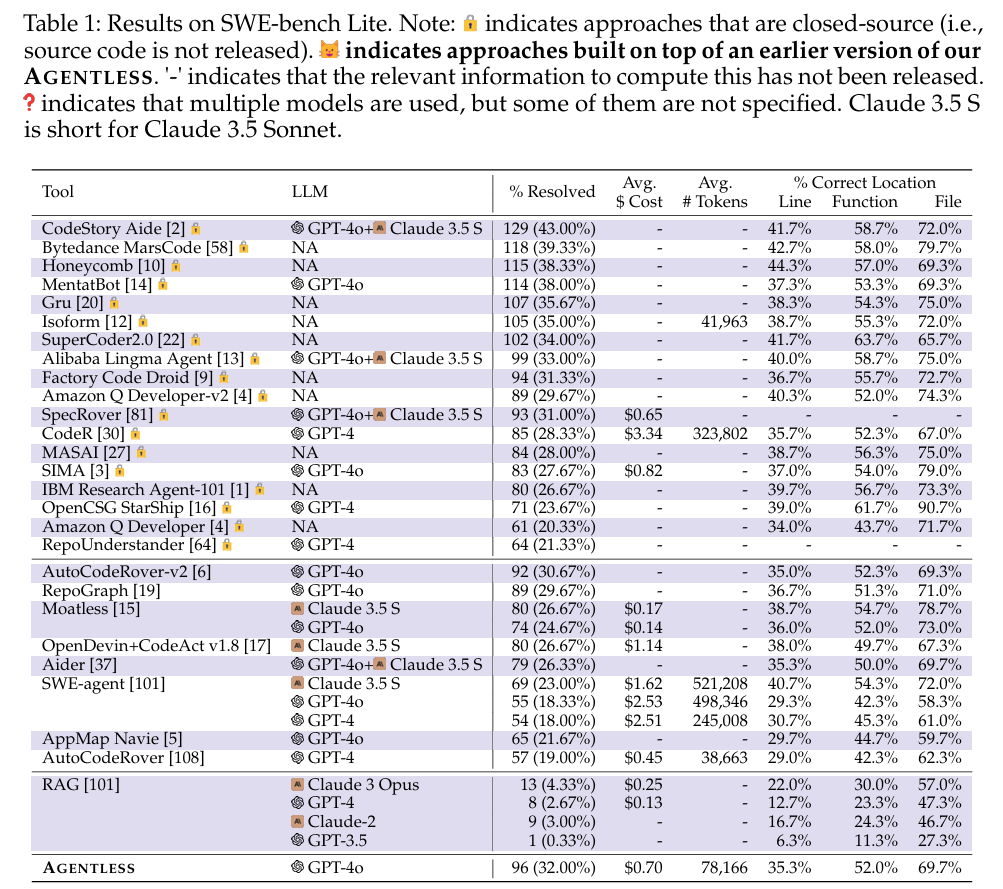
如表一所示,AGENTLESS能够解决300个问题中的96个(32.00%)。虽然这不是SWE-bench Lite上解决的问题的最高百分比,但与以前基于代理的方法相比,AGENTLESS使用了更简单的设计和整体技术,而且具有极强的竞争力。此外,AGENTLESS的平均成本仅为0.70美元,低于大多数先前基于代理的方法。与RAG的无代理baseline相比,虽然AGENTLESS的成本略高,但AGENTLESS也能够解决更多的问题。
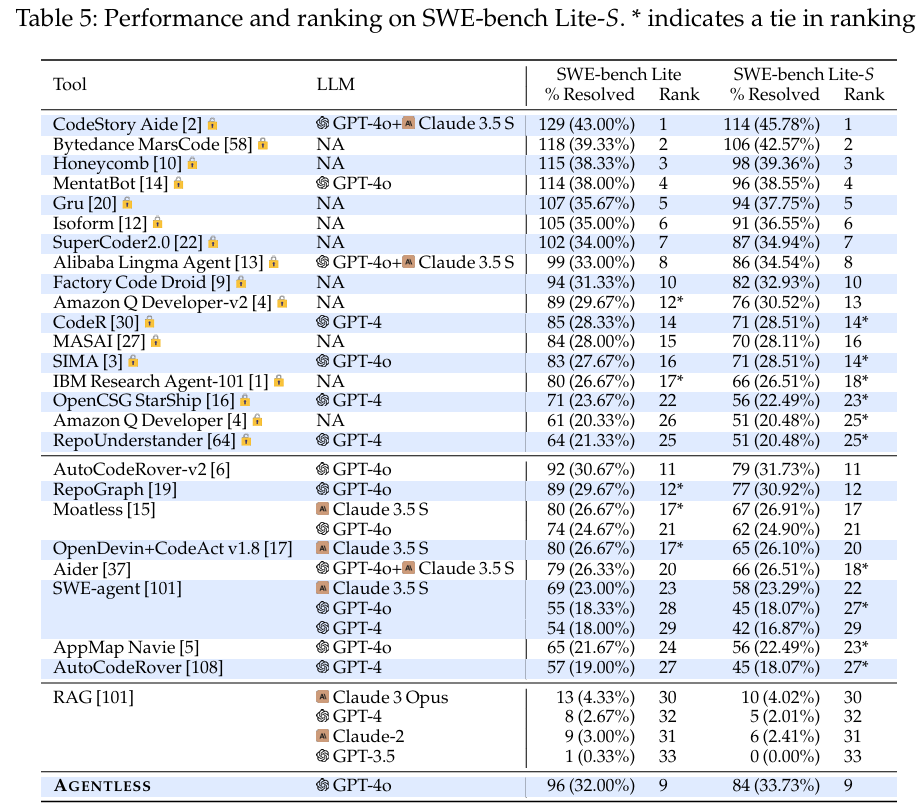
另外,表5显示了SWE-bench Lite-S基准测试的结果和每种方法的相应排名。与最初的SWE-bench Lite相比,有一些小的排名变化,说明作者构建的SWE-bench Lite-S过滤基准更准确地反映了自主软件开发工具的真实能力。
独特问题的修复

如图所示,与开源的基于代理的工具相比,AGENTLESS能够解决其他工具无法解决的2个问题,显示了使用简单的无代理方法解决困难问题的成功。此外,即使与高性能的商业方法相比,AGENTLESS仍然能够提供独特的解决方案。
定位的性能
表1还显示了每个工具在行、函数和文件级别上具有正确位置的提交补丁的百分比。可以观察到,具有正确位置的补丁的百分比与解决率密切相关。在定位性能方面,通过使用AGENTLESS简单的分层方法,与以前基于代理的方法相比,无代理仍然非常有竞争力。
AGENTLESS各组件的消融实验
评估定位、修复和补丁验证阶段中的每个组件如何为最终的AGENTLESS性能做出贡献
定位消融
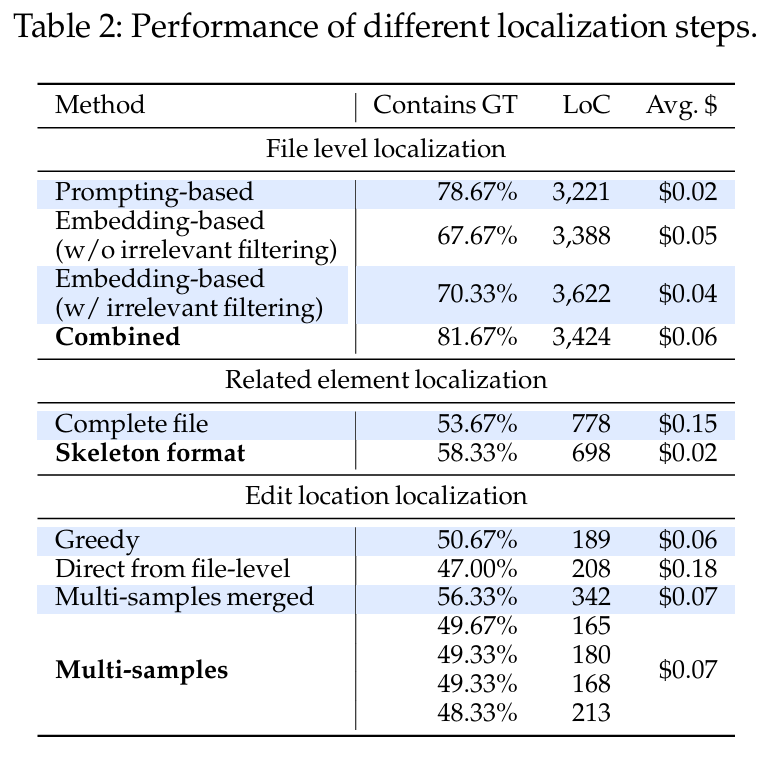
表2显示了AGENTLESS定位阶段3个步骤中每个步骤的性能和成本。在每个定位步骤之后评估以下指标,对比指标有:
Contains GT:ground truth编辑位置保留在位置集当中的问题的百分比
LoC:每个位置集的平均代码行数
Avg.$:每个步骤的平均美元成本
-
文件级定位
如果不包括“不相关文件夹过滤”来删除不相关文件夹进行嵌入(在3.1.1节中描述),性能和成本都会变得更差。
单独使用基于提示或基于嵌入的检索方法可以分别在78.7%和67.7%的情况下定位ground truth文件。组合两者后,可获得81.7%的正确文件定位,表明基于提示和基于嵌入的检索方法可以在识别不同的相关文件集方面相互补充。
-
类和函数级定位
使用完整的文件内容,不仅成本高得多,而且定位出的ground truth问题的数量也减少了,原因来自LLM不能很好的处理长上下文。
-
编辑位置行级定位
从以下方面进行了对比:“贪婪”:使用贪婪解码获得一组编辑位置;“直接从文件级”:直接从文件级定位到编辑位置;“多样本合并”:对多组编辑位置进行采样并合并为一组;“多采样”:对多组编辑位置进行采样。
结果显示,直接从文件级到编辑位置,成本和性能都更差。另外,当将多个样本合并在一起时,定位的ground truth量更高,但代价是在修复阶段必须添加更多上下文作为输入。
修复消融
表3显示了修复阶段的不同设置和输入及其性能和成本。
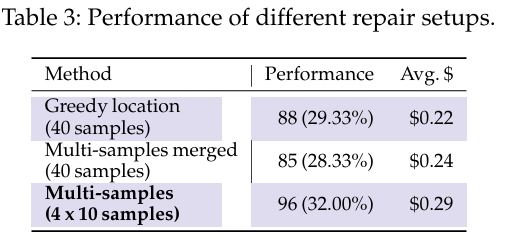
作者还研究了使用不同数量的采样候选补丁对AGENTLESS性能的影响。
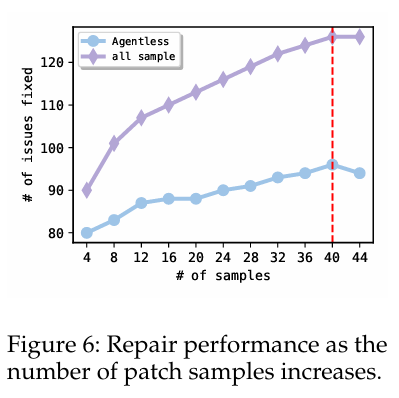
图6显示了随着增加样本数量而修复的问题数量。这里的样本间隔为4。首先,可以看到,通过对每个位置集使用1个贪婪样本,无代理已经可以实现80个正确修复。然后,可以通过添加更多样本来继续提高修复性能。然而,在大约40个样本中,性能稳定,其中添加额外的候选补丁不会提高性能。
有趣的是,还可以从图中看到,如果考虑每个问题的所有补丁样本(而不是只选择一个补丁),那么AGENTLESS可以解决的可能问题总数为126个(42.0%)。这显示了无代理潜力的高上限,未来的工作是更好的补丁重新排序和选择技术,以进一步提高整体性能。
补丁验证消融
作者研究了不同的测试生成和补丁选择配置对性能的影响。表4显示了不同方法的结果和额外成本。
图7显示了当增加每个问题生成的候选再现测试的数量时修复性能(条形,左轴),以及选择的与合理的再现测试的总数(线,右轴)的情况。
相关知识链接
总结
作者提出了AGENTLESS——一种自动解决软件开发问题的无代理方法。AGENTLESS使用简单的定位、修复和补丁验证三阶段方法。与先前基于代理的方法相比,AGENTLESS故意不允许LLM用于自主工具使用或规划。通过对流行的SWE-bench Lite基准测试的评估表明,与其他开源技术相比,AGENTLESS可以实现最高的性能,同时最大限度地降低成本。此外,作者还对SWE-bench Lite中的问题进行了详细的分类,不仅可以提供新的见解,还可以在删除有问题的问题后构建更严格的SWE-bench Lite-S基准。
[亮点]
- AGENTLESS单独使用的技术没有一个是革命性的,而是巧妙地结合现有技术,构建一个比较新颖且易于理解的方法,解决了现有基于代理的方法过于复杂的环境交互问题,不依赖代理进行决策
[启发]
- 这种分层级定位编辑位置的方法,适用于学生代码的错误定位,出错的文件能够直接确定,还需要确定出错的代码块,最后再确定出错的行
- 文中生成补丁的方式,表示为一个含有检索和替换的简单的diff格式。迁移到分析学生代码的迭代,可以理解为学生的每次迭代是一个生成补丁的过程,可以用同样的格式来表示此处的补丁
Bib Tex
@misc{xia2024agentlessdemystifyingllmbasedsoftware,
title={Agentless: Demystifying LLM-based Software Engineering Agents},
author={Chunqiu Steven Xia and Yinlin Deng and Soren Dunn and Lingming Zhang},
year={2024},
eprint={2407.01489},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2407.01489},
}

















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









