






基本信息
这是2024年6月被人工智能一区期刊Expert Systems With Applications接收,一篇关于多变量时间序列分类的文章,其创新在于设计了一种通过重建关键时间戳来增强多元时间序列的分类性能的网络。通过创新的高斯先验自注意力机制,并采用上下文感知位置编码来增强时间序列中时间依赖性的建模。
论文作者
Da Zhang(西北工业大学) , Junyu Gao , Xuelong Li
论文出处
Expert Systems With Applications(人工智能一区期刊)
博客创建者
徐宁
标签
多元时间序列分类、特征表示、高斯变换编码器、数据驱动重建
1. 摘要
基于 Transformer 的深度学习方法极大地促进了多元时间序列分类(MTSC)任务。 然而,由于自注意力机制的固有操作,大多数现有方法往往忽视时间序列的内部局部特征和时间不变性,可能导致对模型内表示和上下文信息的理解有限。 与全局特征相比,局部特征表现出更大的特异性和细节,从而更有利于捕获时间序列的本质纹理信息和局部结构。 为了改善这些问题,我们提出了 CTNet,这是一种通过重建关键时间戳来增强时间序列表示学习的新型网络,旨在提高解决 MTSC 任务的能力。 具体来说,我们引入了一种新颖的 Transformer 编码器,它结合了高效的高斯先验机制来准确捕获局部依赖关系。 此外,我们提出了一种数据驱动的掩码策略,通过重建关键时间戳来提高模型的表示学习能力。 在重建过程中,我们采用上下文感知位置编码来增强模型的时间不变性。 在 30 个可访问的 UEA 数据集上进行的大量实验验证了 CTNet 与之前的竞争方法相比的优越性。 此外,还进行了消融研究和可视化分析,以确认所提出模型的有效性。
- 引入了一种新颖的 Transformer 编码器,具有高效的高斯先验机制。 通过强调相邻标记,该方法可以更有效地捕获时间序列的潜在局部依赖性,从而能够更细致地表示时间序列数据。
- 提出了一种新颖的数据驱动掩模策略。 该策略利用关键时间戳的重建,通过引导网络专注于时间序列中信息最丰富的部分,促进更有效的学习过程。
- 采用上下文感知位置编码来保留关键的时间信息,这不仅保留了不同序列的位置信息,而且还增强了模型的时间不变性。
- 对 30 个公开数据集进行了广泛的实验,以证明 CTNet 相对于现有 SOTA 方法的优越性,强调其在各种 MTSC 任务中的稳健性和多功能性。
2. 方法
2.0 背景
-
多元时间序列分类(MTSC)方法
- 传统分类方法
- 基于距离的方法:但由于需要测量每对时间序列之间的距离,所以计算量较大
- 基于特征的方法:严重依赖于领域专家知识,并且需要在特征工程和预处理方面付出大量努力,使得此类方法难以转移到其他时间序列数据集。
- 深度学习方法
- 通过卷积神经网络(CNN)可以有效分类:但这种方法的分类性能受到无法捕捉全局上下文信息以及忽视高维序列中存在的时间关系的倾向的阻碍
- 通过Transformer进行分类可以捕获长期依赖性和交互性,但忽略了时间序列的潜在局部特征和时间不变性。
-
本文方法动机motivation
为了改善这些棘手的问题,本文提出了 CTNet,一种通过重建关键时间戳来促进时间序列表示学习的方法,旨在提高 MTSC 的性能。 具体来说,我们引入了一种新颖的 Transformer 编码器,它通过增强有效高斯先验概率来结合增强的自注意力机制。 这种设计突出了相邻标记对中心标记的贡献,从而更有效地捕获多元时间序列中的局部依赖关系。 此外,还提出了数据驱动的掩码策略,以通过重建关键时间戳来提高模型学习表示的能力。 该方案涉及分类任务和重建任务之间的交替训练,每个时期共享参数,从而简化网络,同时提高其整体性能。 为了在编码过程中保持多元时间序列的位置信息,我们提出了**上下文感知位置编码(PE)**来放大模型在整个重建过程中的时间不变性。
2.1 方法架构
CTNet 方法流程如下图所示:

MTSC CTNet总体框架。 (a) 分类模型:输入序列首先经过标准化,然后输入具有上下文感知位置编码的嵌入层,然后发送到 N 层高斯变换编码器和全连接(FC)层; (b)掩模策略:将每个时间序列数据提取的特征聚合成特征图。 根据这些分数,我们决定哪些时间戳是关键的并执行掩码策略; © 重建模型:掩蔽序列由 N 层高斯变换编码器重建。 请注意,两个 FC 层不同,并且高斯变换器编码器块是参数共享的。
2.2 方法介绍
2.2.1 Gaussian transformer encoder
原生Transformer在建模全局上下文方面表现出色,但它倾向于几乎平等地对待不同距离的标记。然而,实际上,临近的标记对中心标记的特征贡献更为显著。为了增强模型提取时间序列局部特征的能力,本文引入了一种具有高斯先验概率的改进Transformer编码器,同时保持其余结构与原生Transformer编码器一致。
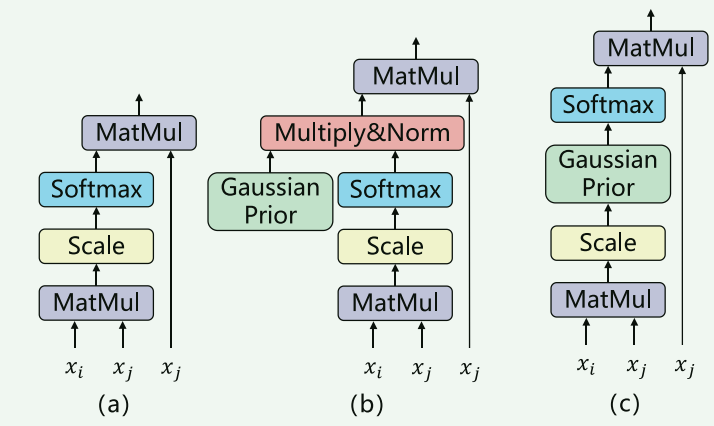
传统Transformer是通过点积的方式计算每个时间戳之间的依赖度,再通过Softmax函数去转换成不同时间戳之间的相关性。
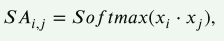
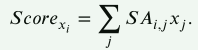
但为了增强时间序列数据中局部结构的建模能力,本文提出通过通过降低与
x
i
x_i
xi距离较远的标记的权重,来增强临近标记对其的影响。目的是让模型能够更好地捕捉时间序列中相邻时间戳之间的关联。
本文假设,在时间序列中,距离较远的标记对当前标记的语义贡献较小,而距离较近的标记有更大的贡献。为了量化这种语义重要性,本文使用了高斯分布来表示标记之间的距离影响。选择正态分布是因为它在计算时具备较好的数学性质,并且实验表明,使用高斯分布优于其他衰减机制。
高斯分布的形式为:
其中,v表示标记
x
i
和
x
j
x_i和x_j
xi和xj之间的距离。这个高斯函数表示的是,当两个时间戳之间的距离越远,其贡献值越小。
将高斯函数插入到标准的自注意力公司中:
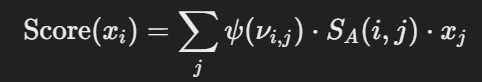
为了确保所有的时间戳得分是归一化的,公式中还添加了归一化因子。这样可以避免距离较远的标记对总得分的影响过大。此外,文章提到标准高斯分布的方差并不总是最优的。因此,提出了一个修正的高斯先验,通过引入可学习的线性因子 𝜔和偏置项 𝛽,使得高斯分布在实际任务中能够更好地适应不同的局部特征。修改后的得分公式为:
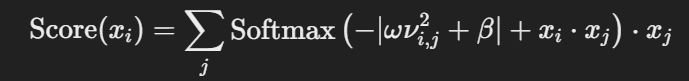
2.2.2 数据驱动的掩码与重建
传统的时间序列Transformer通常通过随机掩码时间戳进行数据重建,而这篇文章提出了一种数据驱动的掩码策略,通过考虑不同时间戳的重要性来选择性地掩码输入数据。这一策略基于自注意力机制中的注意力权重,评估每个时间戳在整个序列中的重要性,并在模型训练中动态选择掩码位置。
-
首先将每一层高斯Transformer编码器计算的所有自注意力权重进行聚合,得到输入时间序列的特征图M,其中 M i j M_{ij} Mij表示在更新 x i x_i xi时分配给 x j x_j xj的注意力权重。
-
然后通过特征图,获取到时间戳 x i x_i xi的归一化聚合注意力权重 τ i \tau_i τi,当 τ \tau τ的值越大,表示对应时间戳越重要,是选择掩码时的重要依据。
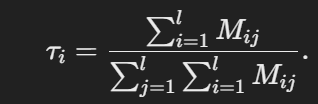
-
掩码时间戳的选择
- 正则化参数 𝜃: 为了避免模型在训练过程中仅记住某些特定时间戳而导致过拟合,引入了正则化参数 𝜃来控制哪些时间戳被视为“关键”并进行掩码。𝜃 决定了哪些时间戳会被视为重要,掩码的选择会根据 τ ′ = θ τ \tau'=\theta\tau τ′=θτ来确定。
- 掩码比例 𝛼: 基于每个时间戳的注意力权重 τ i \tau_i τi,选择那些重要的时间戳进行掩码。这些关键时间戳的掩码比例由 𝛼 控制,其中 𝛼𝑙
表示要掩码的时间戳数(𝑙是序列长度)。
因此,由图也可看出,整个CTNet的训练过程变成了一个多目标训练,在训练分类任务的同时,也需要进行掩码重建任务的训练。 其中损失函数的选择分别是采用均方误差(MSE)来衡量重建损失,使用交叉熵来衡量分类损失,并通过最小化这些损失来优化模型。在此过程中,模型旨在增强对时间序列中的关键特征的学习,以提高分类准确率。
整个训练过程迭代进行,每个时间戳的得分计算、注意力权重聚合和关键时间戳选择都会在每个epoch中更新,并通过掩码和重建策略不断优化模型。两个任务中的高斯Transformer Encoder参数共享,FC layer是独立的。
2.2.3 上下文感知位置编码
在传统的Transformer中一般采用绝对位置编码或者相对位置编码为输入数据提供位置信息
- 对位置编码为每个时间戳分配唯一的编码,它虽然提供了全局的时间序列上下文,但在时间序列分析中可能存在一个问题,即时间不变性的丧失。
- 相对位置编码可以解决绝对位置编码的部分问题,通过关注时间戳之间的相对关系,而非其绝对位置。这样,即使时间戳的绝对位置发生了变化,模型仍然能够捕捉到时间戳之间的相对顺序。然而,相对位置编码也有其缺点,它忽略了序列中某些时间戳的绝对时间信息,这对于某些任务是至关重要的。
- 时间不变性指的是模型应当能够识别和分类时间序列中的模式,而不受时间点发生偏移或扩展的影响。对于时间序列分析,尤其是在面对具有时间平移或扩展的数据时,模型需要能够“忽视”这些变化,专注于时间序列中的关键模式。
上下文感知位置编码是一种旨在克服绝对位置编码和相对位置编码局限性的策略。通过使用1D卷积操作和零填充,模型能够同时考虑每个时间戳的上下文信息和绝对位置信息,从而在处理时间序列数据时,既保留了时间序列的顺序信息,也增强了模型的泛化能力和预测准确性。
- 1D卷积是一种滑动窗口操作,用于对序列的局部上下文进行建模:
捕捉相对关系:通过卷积核的局部感受野,模型可以在每个时间戳的邻域内捕捉相对位置信息(例如,相邻时间戳之间的变化模式)。- 零填充(Zero Padding)是在序列两端补零,以确保卷积操作不会丢失边界信息:
保留绝对位置信息:零填充在边界处引入了显式的“位置标记”,帮助模型捕捉到序列的起点和终点信息。
增强顺序建模能力:结合1D卷积后,序列的开始和结束位置可以通过零填充显式编码,这解决了相对位置编码丢失绝对位置信息的问题。
3. 实验
3.1 数据集和 Baselines
数据集:
UEA 多元时间序列分类档案中选择了 30 个公共数据集来执行 MTSC 任务。
Baselines:
对比了8种方法,包括:
TS2Vec,TapNet,MICOS,TNC,DKN,Formertime,FEAT,TS-TCC,TST
3.2 指标
实验采用ACC 分数作为评价指标。
3.3 实验结果及分析
3.3.1 分类表现评估
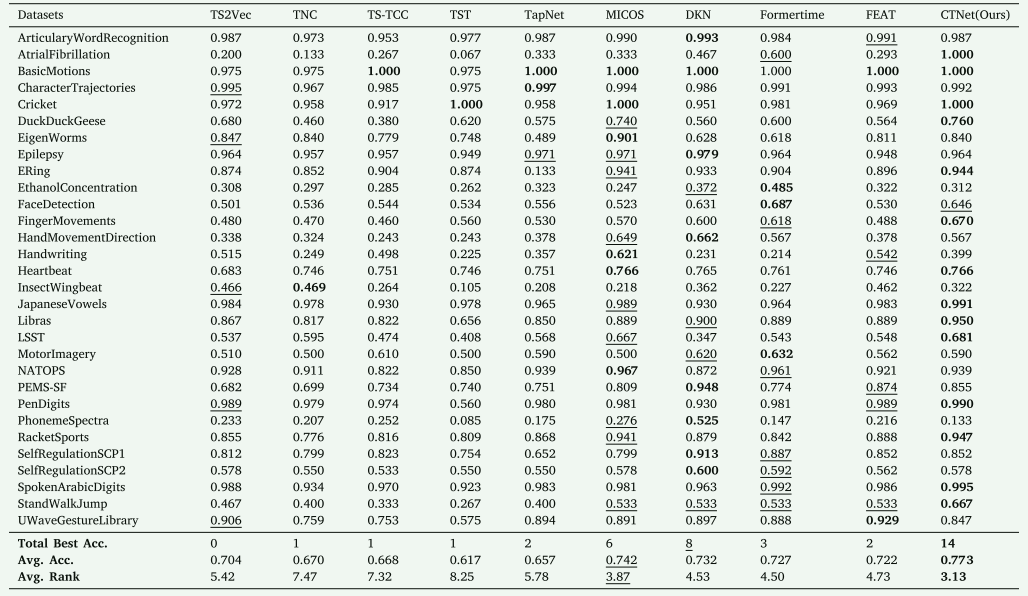
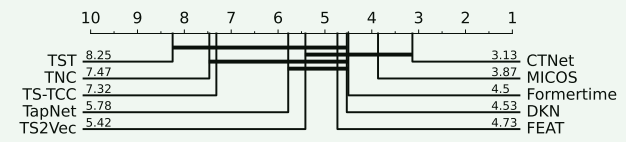
实验结果表明,CTNet 在多个时间序列数据集上的表现优异,平均准确率为 0.773,比次优模型 MICOS 高出 3.1 个百分点,并在 14 个数据集上取得最佳结果,领先于其他对比方法(如 DKN 和 MICOS)。尽管没有在所有数据集上都占据绝对优势,但 CTNet 的整体表现最稳定,即使在弱势数据集上也优于大多数模型。同时,统计分析表明 CTNet 的排名在大多数情况下具有显著性优势,进一步证明其在时间序列分类任务中的泛化能力和稳健性。
3.3.2 组件讨论
高斯先验假设
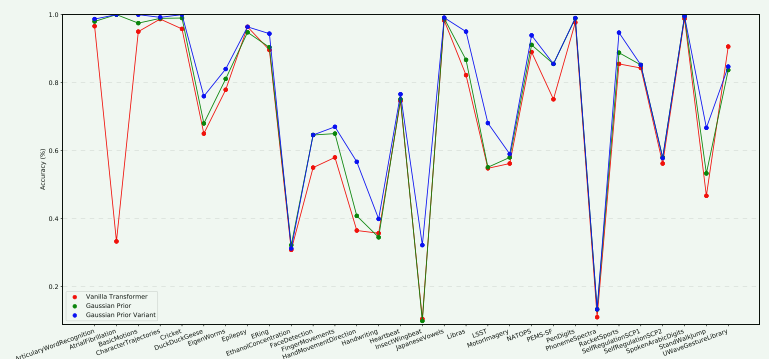
传统Transformer通过正弦位置编码获取相对位置信息,但高斯先验假设通过调整自注意力机制,强调局部特征可以更精准地理解时间序列动态。实验结果表明,高斯先验整体上显著提升了分类准确率,特别是在AtrialFibrillation和StandWalkJump等数据集上表现突出。然而,这种改进并非普遍适用于所有数据集,例如在UWaveGestureLibrary数据集上并未超越原始Transformer的表现,反映出高斯先验的效果依赖于数据集的内在特性。进一步通过引入线性因子和偏置调整优化高斯先验,显著提升了CTNet框架在多样数据集上的表现,展现了其强大的鲁棒性和适应性。研究结果不仅验证了高斯先验假设的有效性,还揭示了在时间序列分类中平衡全局上下文与局部特征建模的重要性。
掩码重建
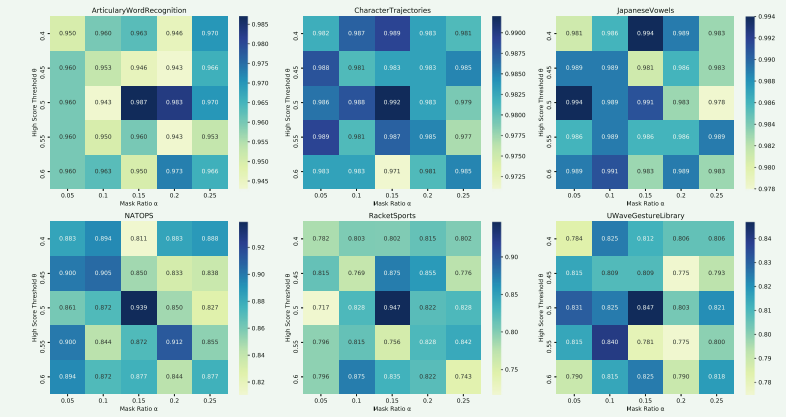
这两项因素对模型的泛化能力均有显著影响,其中遮掩比例反映了基本语义元素的重要性,高分区间则体现了恢复任务的复杂性。在RacketSports和UWaveGestureLibrary数据集中,CTNet对遮掩比例的敏感度高于高分区间,而在ArticularyWordRecognition数据集中,当遮掩比例为0.05时,高分区间的变化对准确率几乎没有影响。这表明不同数据集对超参数变化的敏感性存在较大差异。
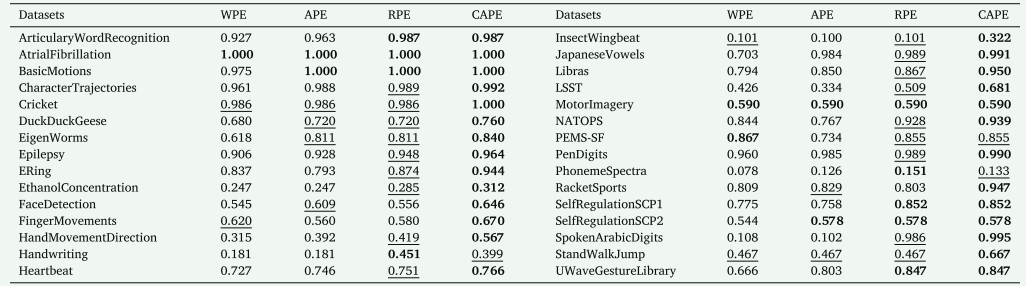
上下文感知位置编码
4. 总结
4.1 亮点
- 通过重构自注意力机制来强调了局部时间戳对时间序列的重要性,符合时间序列的特征。
- 采用多任务训练的方式来提高分类效果比单一训练更有效;
4.3 启发
- 对局部时间戳的关注在程序变量序列上也符合直觉,应该也有帮助;
5. 相关知识链接
BibTex
title={Multivariate time series classification with crucial timestamps guidance},
author={Zhang, Da and Gao, Junyu and Li, Xuelong},
journal={Expert Systems with Applications},
volume={255},
pages={124591},
year={2024},
publisher={Elsevier}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









